







 一项研究发现,非正式的弱智吧段子数据在中文AI训练中表现出色,挑战了传统高质量数据的观念。这提示我们在AI系统构建时应重视数据的多样性和代表性,而非仅依赖高质量标准。
一项研究发现,非正式的弱智吧段子数据在中文AI训练中表现出色,挑战了传统高质量数据的观念。这提示我们在AI系统构建时应重视数据的多样性和代表性,而非仅依赖高质量标准。
在 AI 的研究领域中,语言模型的训练数据选择一直是一个关键问题。传统的智慧告诉我们,高质量的数据集应该是由专家精心挑选和校对的文本组成,以确保模型学习到的语言是规范、准确、有文化内涵的。
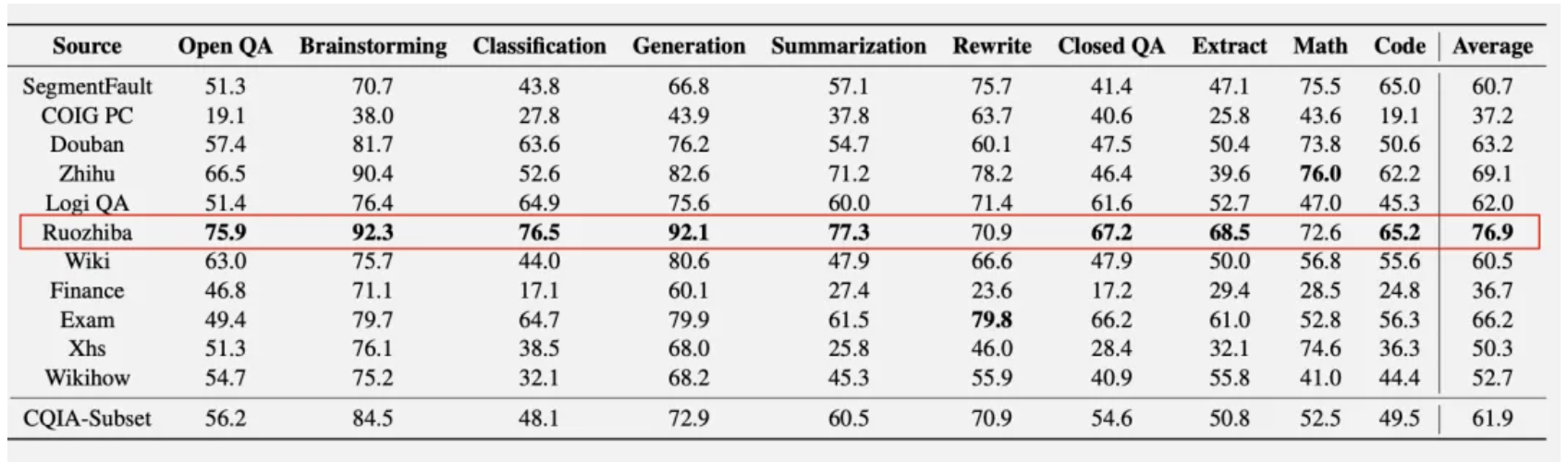
然而,最近的一项研究颠覆了这一观点,让整个AI界都大跌眼镜——弱智吧的数据竟然在中科院的在问答、头脑风暴、分类、生成、总结、提取等8项测试中取得最高分,成为了最佳的中文AI训练数据源之一,跑分超过百科、知乎、豆瓣、小红书等平台。
弱智吧段子集合了各种以冷笑话,谐音梗,词意混用等为基础构造的中文特色逻辑陷阱,用来训练中文 AI 的确是个好材料,我们也先乐一下。
我买了一斤藕,为什么半斤都是空的?
午餐肉,我可以晚上吃吗?
我想配个6000多的电脑,大概要多少钱?
香菇掉厕所了还能叫香菇吗?
玉皇大帝住的是平流层还是对流层?
变形金刚买保险是买车险还是人险?
陨石为什么每次都能精准砸到陨石坑?
为什么岳飞让岳母给他刺而不是让自己母亲给刺?
既然台上一分钟,台下十年功,那为什么不直接在台上练功?
为什么两个字是三个字?因为四个字也是三个字。
生鱼片是死鱼片。
等红灯是在等绿灯。
救火是在灭火。
这听起来是不是有些诙谐?这些数据的特点通常是非正式、包含大量网络用语、俚语、甚至是错别字和语法错误。这样的数据源,按理说,应该是AI训练中需要避免的“噪音”。
这项研究起初为解决中文大模型训练中的诸多问题:
- 中文数据集很多是从英文翻译过来的,没有很好地契合中文的语言习惯和文化背景。
- 不少数据集是用AI生成的,质量难以保证,容易出现事实性错误
- 即使是人工标注的数据集,也存在数据量小、覆盖领域不全面等问题
中科院的研究者们在对多种中文数据集进行深入分析和比较后,发现弱智吧数据在多样性、覆盖面以及反映真实语言使用情况等方面表现出色。在8项不同的语言模型测试中,包括语义理解、情感分析、自然语言生成等,以弱智吧数据为基础训练出的模型性能竟然领先于其他传统认为更为“高质量”的数据集。
当然,这并不意味着我们可以完全放弃对数据质量的追求。相反,这一发现提醒我们,在构建AI系统时,应该更加注重数据的多样性和代表性,同时也要关注数据的质量。未来的AI训练可能会采用更加多元化的数据源,结合专家知识进行筛选和优化,以达到最佳的训练效果。
总之,弱智吧成为最佳中文AI训练数据的事实,不仅为我们提供了一个关于AI训练数据选择的新视角,也为AI的发展和应用打开了新的可能性。在这个充满惊喜的AI时代,我们期待着更多这样颠覆性的研究,引领我们走向一个更加智能的未来。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









