







字符串算法
模式匹配(Pattern Matching):在一篇长度为 𝑛 的文本 𝑆 中,找某个长度为 𝑚 的关键词 𝑃。𝑃 可能多次出现,都需要找到。
最优的模式匹配算法复杂度:
𝑂(𝑚+𝑛),因为至少需要检索文本 𝑆 的 𝑛 个字符和关键词 𝑃 的 𝑚 个字符。
一、暴力的模式匹配算法(暴力法)
1. 思路
从 𝑆 的第一个字符开始,逐个匹配 𝑃 的每个字符。例如 𝑆 = “𝑎𝑏𝑐𝑥𝑦𝑧123”,𝑃 = “123”。第 1 轮匹配的两个字符就不同,𝑃[0]≠𝑆[0],称为“失配”,后面的 𝑃[1]、𝑃[2] 不用再比较了。一共比较 6+3=9 次:前 6 轮比较 𝑃 的第 1 个字符,第 7 轮比较 𝑃 的 3 个字符。
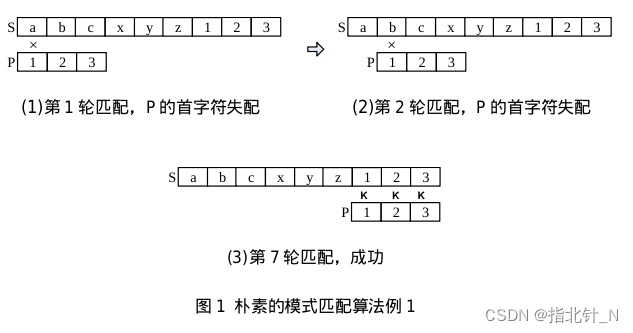
2. 理想情况
这个匹配的过程,可以做个形象的比喻:把 𝑃 看成一个滑块,在轨道 𝑆 上滑动,直到完全匹配。但是举得这个例子比较特殊,𝑃 和 𝑆 的字符基本都不一样。在每轮匹配时,往往第 1 个字符就对不上,用不着继续匹配 𝑃 后面的字符。所以此时,计算复杂度差不多是 𝑂(𝑛) 的,这已经是字符串匹配能达到的最优复杂度了。所以,如果字符串 𝑆、𝑃 符合上述的特征,暴力法是很好的算法。
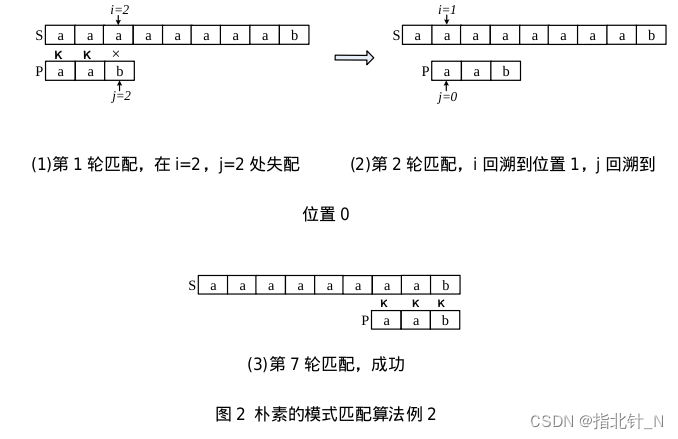
3. 糟糕情况
例如 𝑃 的前 𝑚−1 个都容易找到匹配,只有最后一个不匹配,那么复杂度就退化成 𝑂(𝑛𝑚)。例如 𝑆 = “𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑎𝑏”,𝑃 = “𝑎𝑎𝑏”。下图中 𝑖 指向 𝑆[𝑖],𝑗 指向 𝑃[𝑗](0≤𝑖<𝑛,0≤𝑗<𝑚)。第 1 轮匹配后,在 𝑖=2,𝑗=2 的位置失配。第 2 轮让 𝑖 回溯到 1,𝑗 回溯到 0,重新开始匹配。最后经过 7 轮,共匹配 7×3=21 次,远远超过上面例子中的 9 次。
二、KMP算法
1. 优势
KMP 是一种在任何情况下都能达到 𝑂(𝑛+𝑚) 复杂度的算法。
用 KMP 算法时,指向 𝑆 的 𝑖 指针不会回溯,而是一直往后走到底。与朴素方法比较,这大大加快了匹配速度。
在朴素方法中,每次新的匹配都需要对比 𝑆 和 𝑃 的全部 𝑚 个字符,这实际上做了重复操作。例如第一轮匹配 𝑆 的前 3 个字符 “𝑎𝑎𝑎” 和 𝑃 的 “𝑎𝑎𝑏”,第二轮从 𝑆 的第 2 个字符 ‘𝑎’ 开始,与和 𝑃 的第一个字符 ‘𝑎’ 比较,这其实不必要,因为在第一轮比较时已经检查过这两个字符,知道它们相同。如果能记住每次的比较,用于指导下一次比较,使得 𝑆 的 𝑖 指针不用回溯,就能提高效率。
2. 不回溯的指针
分为两种情况:
(1)P 在失配点之前的每个字符都不同
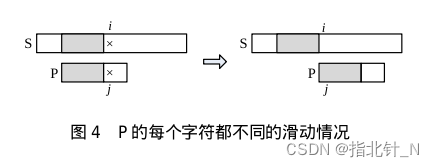
例如 𝑆 = “𝑎𝑏𝑐𝑎𝑏𝑐𝑑”,𝑃 = “𝑎𝑏𝑐𝑑”,第一次匹配的失配点是 𝑖=3,𝑗=3。失配点之前的 𝑃 的每个字符都不同,𝑃[0]≠𝑃[1]≠𝑃[2];而失配点之前的 𝑆 与 𝑃 相同,即 𝑃[0]=𝑆[0]、𝑃[1]=𝑆[1]、𝑃[2]=𝑆[2]。下一步如果按朴素方法,𝑗 要回到位置 0,𝑖 要回到 1,去比较 𝑃[0] 和 𝑆[1]。但 𝑖 的回溯是不必要的。由 𝑃[0]≠𝑃[1]、𝑃[1]=𝑆[1] 推出 𝑃[0]≠𝑆[1],所以 𝑖 没有必要回到位置 1。同理,𝑃[0]≠𝑆[2],𝑖 也没有必要回溯到位置 2。所以 𝑖 不用回溯,继续从 𝑖=3、𝑗=0 开始下一轮的匹配。

看下面的示意图可以更好的理解。当 𝑃 滑动到左图位置时,𝑖 和 𝑗 所处的位置是失配点, 𝑆 与 𝑃 的阴影部分相同,且阴影内部的 𝑃 的字符都不同。下一步直接把 𝑃 滑到 𝑆 的 𝑖 位置,此时 𝑖 不变、𝑗 回到 0,然后开始下一轮的匹配。
(2)P 在失配点之前的字符有部分相同
这种情况要再细分为两种情况。
1> 相同的部分是前缀(位于 𝑃 的最前面)和后缀(在 𝑃 中位于 𝑗 前面的部分字符)。
前缀和后缀的定义:
字符串 𝐴和 𝐵,若存在 𝐴=𝐵𝐶,其中 𝐶 是任意的非空字符串,称 𝐵 为 𝐴 的前缀;
同理可定义后缀,若存在 𝐴=𝐶𝐵, 𝐶 是任意非空字符串,称 𝐵 为 𝐴 的后缀。
从定义可知,一个字符串的前缀和后缀不包括自己。
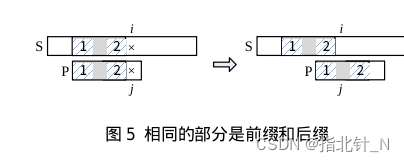
当 𝑃 滑动到下面左图位置时,𝑖 和 𝑗 所处的位置是失配点,𝑗 之前的部分与 𝑆 匹配,且子串 1(前缀)和子串 2(后缀)相同,设子串长度为 𝐿。下一步把 𝑃 滑到右图位置,让 𝑃 的子串 1 和 𝑆 的子串 2 对齐,此时 𝑖 不变、𝑗=𝐿,然后开始下一轮的匹配。注意,前缀和后缀可以部分重合。
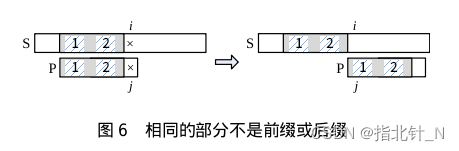
2> 相同部分不是前缀或后缀。 下面左图,𝑃 滑动到失配点 𝑖 和 𝑗,前面的阴影部分是匹配的,且子串 1 和 2 相同,但是 1 不是前缀(或者 2 不是后缀),这种情况与“1>. 𝑃 在失配点之前的每个字符都不同”类似,下一步滑动到右图位置,即 𝑖 不变,𝑗 回溯到 0。请你自己分析其正确性。
3. Next[] 数组
根据前面的分析,会发现不回溯 𝑖 完全可行的。
KMP 算法的关键在于模式 𝑃 的前缀和后缀,计算每个 𝑃[𝑗] 的前缀、后缀,记录在 Next[] 数组中,Next[𝑗] 的值等于 𝑃[0]∼𝑃[𝑗−1] 这部分子串的前缀集合和后缀集合的最长交集的长度,我们把这个最长交集称为“最长公共前后缀”。在有的资料中,也有把 Next[] 命名为 shift[] 或者 fail[] 的。
例如 𝑃 = “𝑎𝑏𝑐𝑎𝑎𝑏”,计算过程如下表,每一行的带下划线的子串是最长公共前后缀。
| j | P[0] ~ P[j-1] | 前缀 | 后缀 | Next[j] |
|---|---|---|---|---|
| 1 | a | 空 | 空 | 0 |
| 2 | ab | a | b | 0 |
| 3 | abc | a, ab | bc, c | 0 |
| 4 | abca | a, ab, abc | bca, ca, a | 1 |
| 5 | abcaa | a, ab, abc, abca | bcaa, caa, aa, a | 1 |
| 6 | abcaab | a, ab, abc, abca, abcaa | bcaab, caab, aab, ab, b | 2 |
所以,Next[] 只和 𝑃 有关,我们应该可以通过预处理 𝑃 得到 Next[]。
下面介绍一种复杂度只有 𝑂(𝑚) 的极快的计算 Next[] 的方法,它巧妙地利用了前缀和后缀的关系,从 Next[i] 递推到 Next[i+1]。
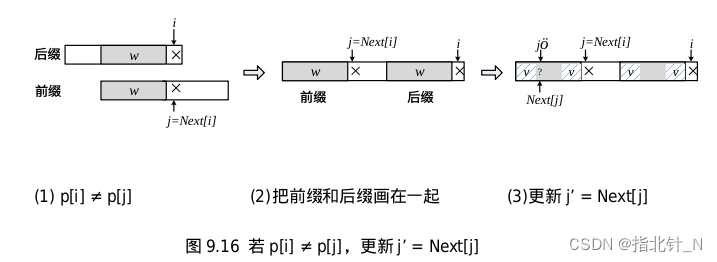
就假设当前我们已经计算出了 Next[i],它对应 𝑃[0]∼𝑃[𝑖−1] 这部分子串的后缀和前缀,见下面图(1)所示。后缀的最后一个字符是 𝑃[𝑖−1]。阴影部分 𝑤 是最长交集,交集 𝑤 的长度为Next[i],这个交集必须包括后缀的最后一个字符 𝑃[𝑖−1] 和前缀的第一个字符 𝑃[0]。前缀中阴影的最后一个字符是 𝑃[𝑗],𝑗 = Next[i]-1。

图(2) 推广到求 Next[i+1],它对应 𝑃[0]∼𝑃[𝑖] 的后缀和前缀。此时后缀的最后一个字符是 𝑃[𝑖],与这个字符相对应,把前缀的 𝑗 也往后移一个字符,𝑗 = Next[i]。我们要判断两种情况:
1> 若 𝑃[𝑖]=𝑃[𝑗],则新的交集等于“阴影 𝑤+𝑃[𝑖]”,交集的长度 Next[i+1] = Next[i]+1。如图(2)所示。
2> 若 𝑃[𝑖]≠𝑃[𝑗],说明后缀的“阴影 𝑤+𝑃[𝑖] ”与前缀的“阴影 𝑤+𝑃[𝑗] ”不匹配,只能缩小范围找新的交集。把前缀往后滑动,也就是通过减小 𝑗 来缩小前缀的范围,直到找到一个匹配的 𝑃[𝑖]=𝑃[𝑗] 为止。
减小 𝑗?要如何减小 𝑗 呢?
减小 𝑗 只能在 𝑤上继续找最大交集,这个新的最大交集是 Next[j],所以更新 j’ = Next[j]。下图(2)画出了完整的子串 𝑃[0]∼𝑃[𝑖],最后的字符 𝑃[𝑖] 和 𝑃[𝑗] 不等。斜线阴影 𝑣 是 𝑤上的最大交集,下一步判断:若 𝑃[𝑖]=𝑃[𝑗’],则 Next[i+1] 等于 𝑣 的长度加 1,即Next[j’]+1;若 𝑃[𝑖]≠𝑃[𝑗’],继续更新 𝑗’。
所以我们只要重复以上操作,逐步扩展 𝑖,就可以求得所有的Next[i]。有了 Next[] 数组,就能在失配的时候,直接跳到 Next[] 所指向的下一个位置啦!
4. KMP 模板代码
题目描述:请你在 𝑆 中找到所有的 𝑃。
输入描述:两行,第一行是字符串 𝑆,第二行是模式串 𝑃。
输出描述:输出每个 𝑃 在 𝑆 中的位置。
下面给出 KMP 的模板代码,包括 getNext()、kmp() 两个函数。getNext() 预计算 Next[]数组,是前面图解思路的完全实现。kmp() 函数在 𝑆 中匹配所有的 𝑃,注意每次匹配到的起始位置是 𝑠[𝑖+1−𝑝𝑙𝑒𝑛],末尾是 𝑠[𝑖]。
#include <stdio.h>
#include <string>
using namespace std;
const int N = 1005;
char str[N], pattern[N];
int Next[N];
// 计算Next[1]~Next[plen]
void getNext(char* p, int plen) {
Next[0] = 0; Next[1] = 0;
for (int i = 1; i < plen; i++) { //把i的增加看成后缀的逐步扩展
int j = Next[i]; //j的后移:j指向前缀阴影w的后一个字符
while (j && p[i] != p[j]) //阴影的后一个字符不相同
j = Next[j]; //更新j
if (p[i] == p[j]) Next[i + 1] = j + 1;
else Next[i + 1] = 0;
}
}
// 在s中找p
void kmp(char* s, char* p) {
int last = -1;
int slen = strlen(s), plen = strlen(p);
getNext(p, plen); //预计算Next[]数组
int j = 0;
for (int i = 0; i < slen; i++) { //匹配S和P的每个字符
while (j && s[i] != p[j]) //失配了。注意j==0是情况(1)
j = Next[j]; //j滑动到Next[j]位置
if (s[i] == p[j]) j++; //当前位置的字符匹配,继续
if (j == plen) { //j到了P的末尾,找到了一个匹配
//匹配了一个,在S中的起点是i+1-plen,末尾是i。如有需要可以打印:
printf("Location=%d, %s\n", i + 1 - plen, &s[i + 1 - plen]);
}
}
}
int main() {
scanf("%s", str); //读串S
scanf("%s", pattern); //读模式串P
kmp(str, pattern);
return 0;
}三、小结
前面解析了KMP算法的思想,并给出了模板代码,KMP 确实是一个很烧脑的算法,代码短却逻辑复杂。
KMP 非常好用,我们经常在网页或文档中搜关键词,这就是 KMP 的应用场合。还有,由于 KMP 算法只需要预处理模式串(关键词)𝑃,而不需要预处理 𝑆。所以使用上述代码的 kmp() 函数时,𝑆 可以是一个很长的、动态增加的文本串,使得我们可以从头到尾逐个匹配 𝑆 的所有字符,从中找到关键词 P。KMP 的效率也极高,例如在 100 万字的一篇文章中,找出一个关键词出现的所有位置,计算次数 100 万次,不到 0.1 秒。















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









