







最近入坑python爬虫…简单记录一下我的爬虫经历。一开始是因为经常在知乎上看到各种关于爬虫的资料,于是自己也想尝试一下,既然这个念头是在知乎上产生的,那么我的爬虫之旅就从爬取知乎开始吧。:)
要开始写爬虫首先需要掌握以下几点:
① 网站的请求,响应等基本知识。
② 学会分析网站,各种抓包工具的使用,方便我们分析网站的交互。
由于我们是要登录知乎,自然需要知道请求的参数以及该向哪个url发送请求,我是通过chrone浏览器自带的开发者工具查看的,你也可以使用其他的抓包工具。
在输入账号密码登录之后,这里可以获取到所有的请求,其中就包括了我们的登录请求,稍微找一下就发现了。在这里我们可以看到我们需要请求的url,以及需要发送的数据,也可以获得我们的请求头。
在我们浏览网页的时候,浏览器向url所在的服务器发出请求,服务器通过识别请求报文中的请求头来判断访问者的身份,通常在爬虫中,我们经常需要做的就是伪造请求头伪装成浏览器,防止被识别出爬虫身份。如下面代码,就是我们构造的请求头(可以通过抓包工具获取),在发出请求的时候带上这个请求头,我们的爬虫就不会被轻易地拦截了~
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate,sdch, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Host': 'www.zhihu.com',
'Origin': 'https://www.zhihu.com',
'Referer': 'https://www.zhihu.com/',
'User-Agent': 'Mozilla/5.0 (X11;Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'x-hd-token': 'hello',
}
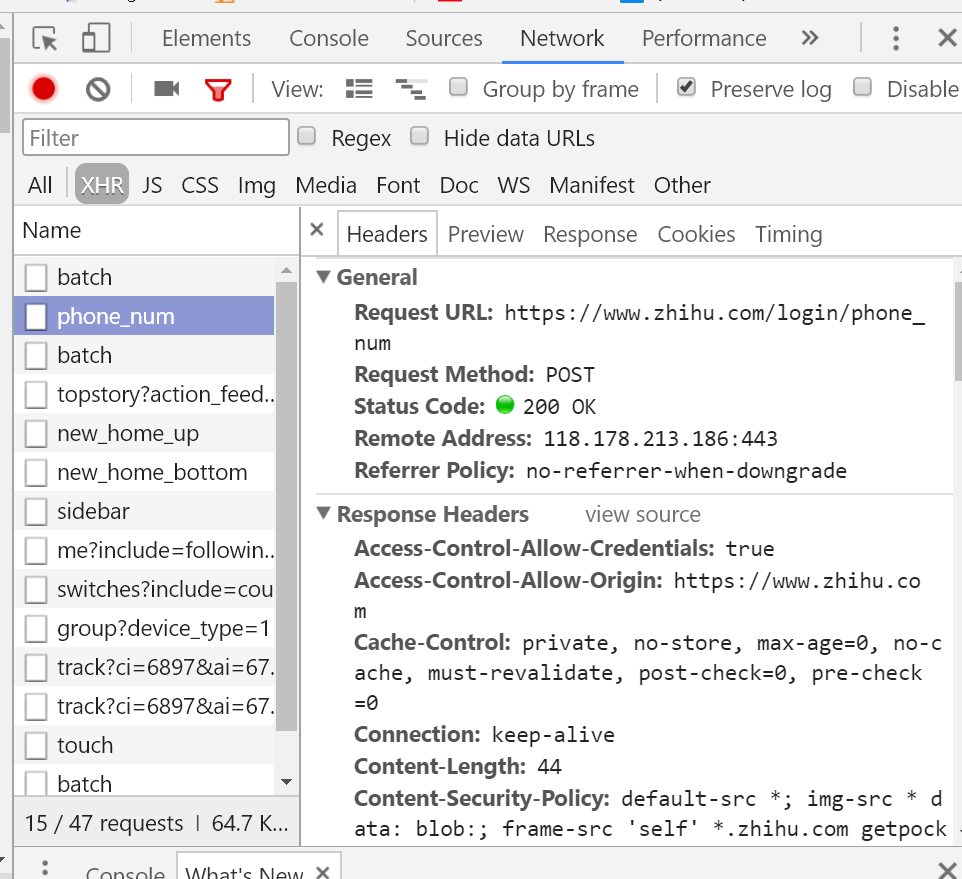
一番分析之后发现使用手机号登陆的话是向https://www.zhihu.com/login/phone_num这个链接发出请求,并且需要的参数是_xsrf,password,phone_num,captcha_type。然而这里我构造之后发现并不能登陆成功,查看了别人的代码之后才发现如果爬虫的话captcha_type要换成captcha,也就是说会有一个验证码…实际所需参数是_xsrf,password,phone_num,cpatcha。(原因我也不清楚..他们是如何发现需要带一个captcha的呢??)
post_data = {
'_xsrf': '***',
'password': password,
'captcha': '***',
'phone_num': username,
}
这就是我们需要构造提交的参数,那个_xsrf是什么呢?主要是为了防止跨站脚本攻击用的,通常在网页可以获得。验证码我采用的是手动输入的方法,需要将验证码图片下载下来,人工识别后再手动输入。具体代码如下
# 下载验证码
with open("../code.jpg", 'wb') as w:
p=self.__session.get(url="https://www.zhihu.com/captcha.gif?r=1495546872530&type=login",headers=self.headers)
w.write(p.content)
code = input("请输入验证码:")
请求成功之后我们会得到一串json数据,告诉我们登录成功或者失败
"""
验证码错误返回:
{'errcode': 1991829, 'r': 1, 'data': {'captcha': '请提交正确的验证码 :('}, 'msg': '请提交正确的验证码 :('}
登录成功返回:
{'r': 0, 'msg': '登陆成功'}
"""为了不想每次都登录,我们可以把cookie存下来,下次登录的时候就不用再重复一遍登录操作了。
def __saveCookie(self):
"""cookies 序列化到文件
即把dict对象转化成字符串保存
"""
with open(self.cookieFile, "w")as output:
cookies = self.__session.cookies.get_dict()
json.dump(cookies, output)
print("已在同目录下生成cookie文件:", self.cookieFile)
登录成功之后,我们的session就保留了登录信息,我们利用session就可以进行登录后的各种操作。通过输出我们发现已经成功抓取到了知乎首页
具体代码:
# -*- coding: utf-8 -*-
import requests
import re
import json
import sys
import os
import time
class ZhiHuClient(object):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Host': 'www.zhihu.com',
'Origin': 'https://www.zhihu.com',
'Referer': 'https://www.zhihu.com/',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'x-hd-token': 'hello',
}
cookieFile = os.path.join(sys.path[0], "cookie")
def __init__(self):
os.chdir(sys.path[0]) # 设置脚本所在目录为当前工作目录
self.__session = requests.Session()
# 若已经有 cookie 则直接登录
self.__cookie = self.__loadCookie()
print(self.__cookie)
if self.__cookie:
print("检测到cookie文件,直接使用cookie登录")
self.__session.cookies.update(self.__cookie)
else:
print("没有找到cookie文件,请调用login方法登录一次!")
def __saveCookie(self):
"""cookies 序列化到文件
即把dict对象转化成字符串保存
"""
with open(self.cookieFile, "w") as output:
cookies = self.__session.cookies.get_dict()
json.dump(cookies, output)
print("已在同目录下生成cookie文件:", self.cookieFile)
def __loadCookie(self):
if os.path.exists(self.cookieFile):
with open(self.cookieFile, "r") as f:
cookie = json.load(f)
return cookie
return None
def getSession(self):
return self.__session
def open(self, url, delay=0, timeout=10):
if delay:
time.sleep(delay)
return self.__session.get(url,headers=self.headers, timeout=timeout)
def login(self, username, password):
"""
验证码错误返回:
{'errcode': 1991829, 'r': 1, 'data': {'captcha': '请提交正确的验证码 :('}, 'msg': '请提交正确的验证码 :('}
登录成功返回:
{'r': 0, 'msg': '登陆成功'}
"""
# 下面写入账号密码
post_data = {
'_xsrf': '***',
'password': password,
'captcha': '***',
'phone_num': username,
}
self.__username = username
self.__password = password
page = self.__session.get(url="https://www.zhihu.com/#signin", headers=self.headers)
parser = re.compile(u'<input type="hidden" name="_xsrf" value="(.*?)"/>', re.S)
xsrf = re.findall(parser, page.text)[0]
self.headers['X-Xsrftoken'] = xsrf
post_data['_xsrf'] = xsrf
print(post_data)
# 下载验证码
with open("../code.jpg", 'wb') as w:
p = self.__session.get(url="https://www.zhihu.com/captcha.gif?r=1495546872530&type=login", headers=self.headers)
w.write(p.content)
code = input("请输入验证码:")
if not code:
sys.exit(1)
post_data['captcha'] = code
# 发送POST请求
res = self.__session.post(url='https://www.zhihu.com/login/phone_num',data=post_data,headers=self.headers)
# print(res.text) # 输出脚本信息,调试用
if res.json()["r"] == 0:
print("登录成功")
self.__saveCookie()
else:
print("登录失败")
print("错误信息 --->", res.json()["msg"])
#cookie=login().cookies.get_dict()
client = ZhiHuClient()
#如果没有cookie需要在这里先调用client.login(),出现cookie过期的情况可能登陆不上,可以手动将cookie删掉重新登陆
print(client.open("https://www.zhihu.com").content.decode("utf8"))















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









