







使用Scrapy框架爬取拉勾网招聘信息
最近接触了Scrapy爬虫框架,简单写了个爬虫爬取拉钩网的招聘信息,加深对Scrapy框架的理解,不得不说Scrapy框架其实还是蛮方便的,就像爬虫流水线一样,如果是大项目的话使用Scrapy会变得更加容易管理,废话不多说,下面就看看如何使用Scrapy爬取拉勾网招聘消息吧。
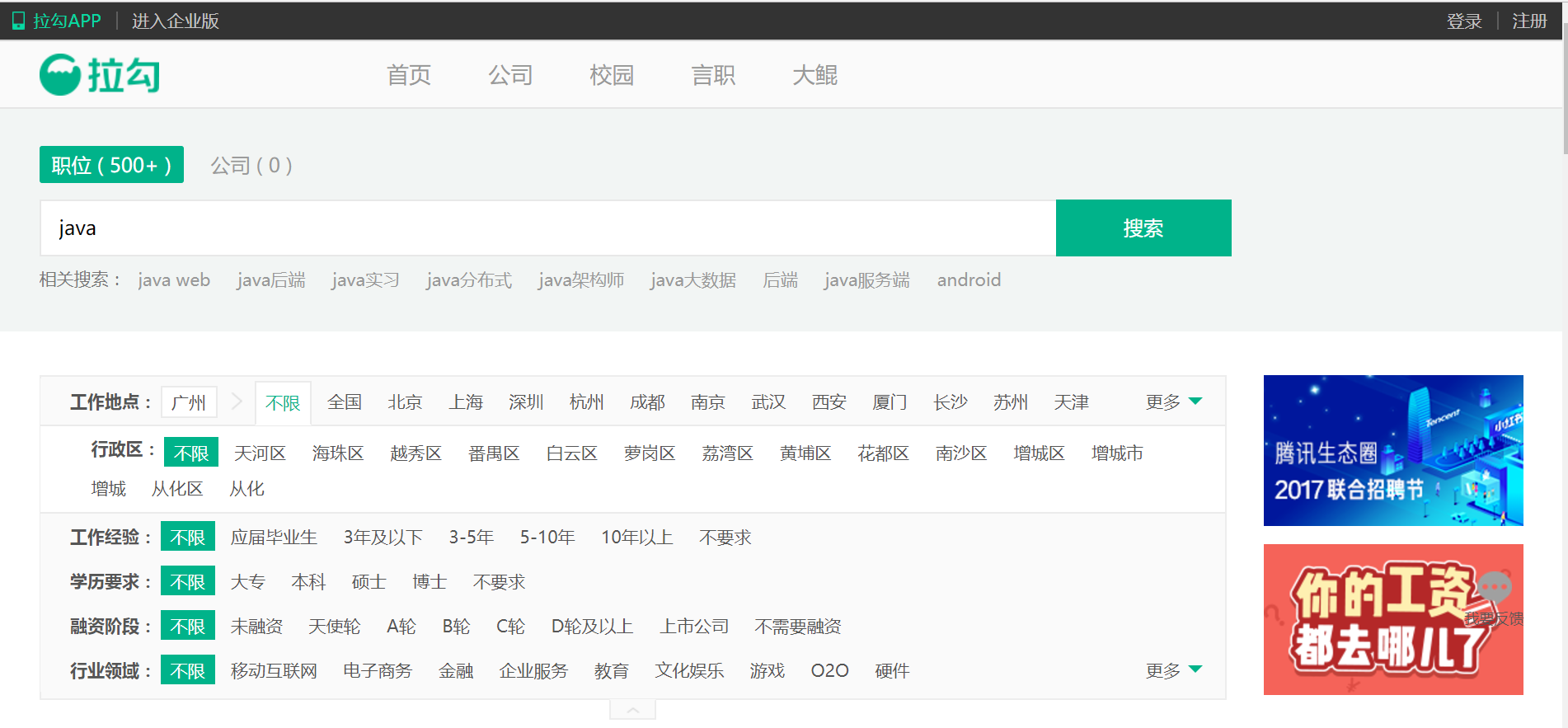
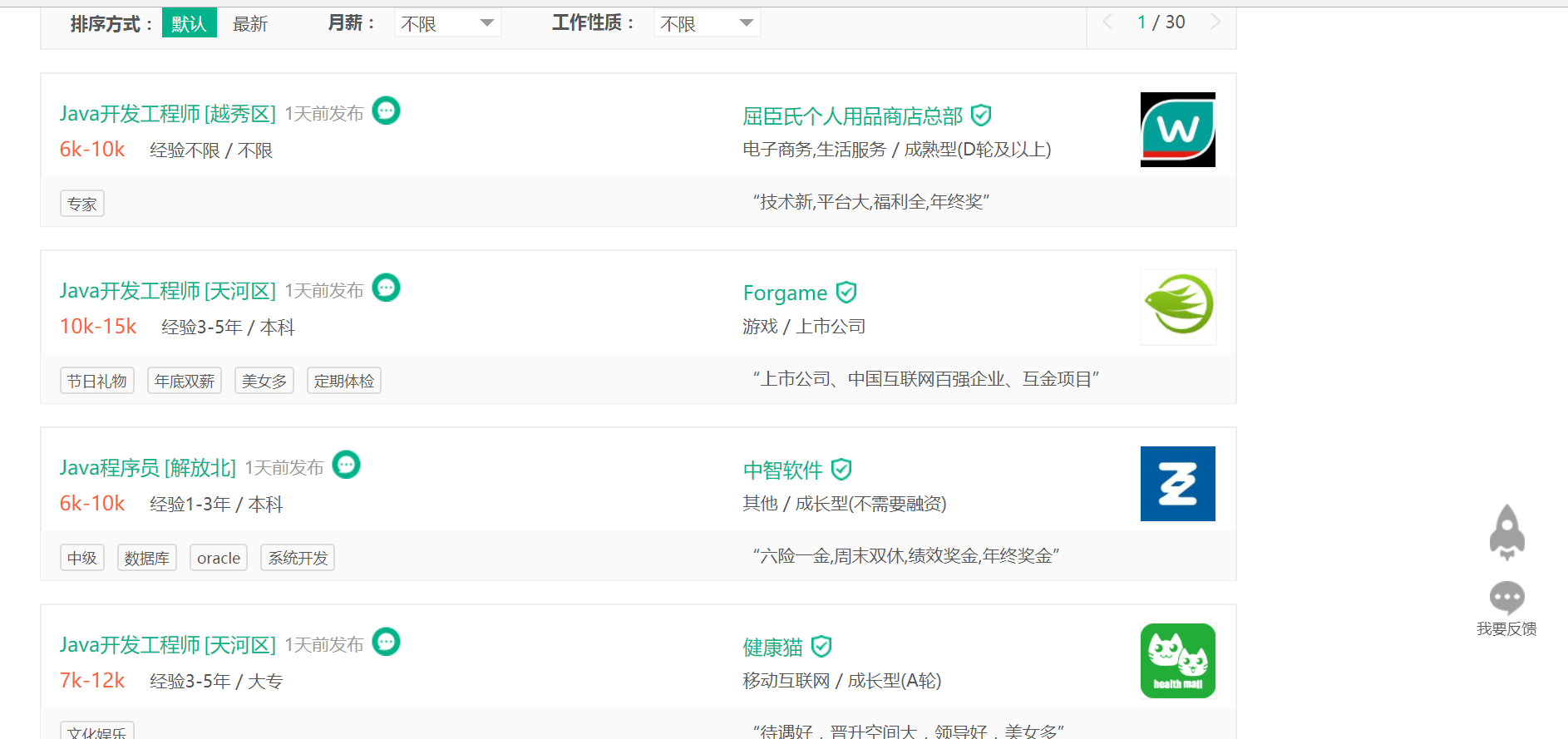
我们发现由于数据是分页显示的,如果想要获取每一页的内容,自然需要获取每一页的链接。
我们点击下一页,发现页面回到了顶端,并且url栏没有任何变化!为什么呢?当前页的参数去哪里了?我们需要这里又用到了chrone浏览器强大的开发者工具了。在点击“3”之后,出现了下面的请求。
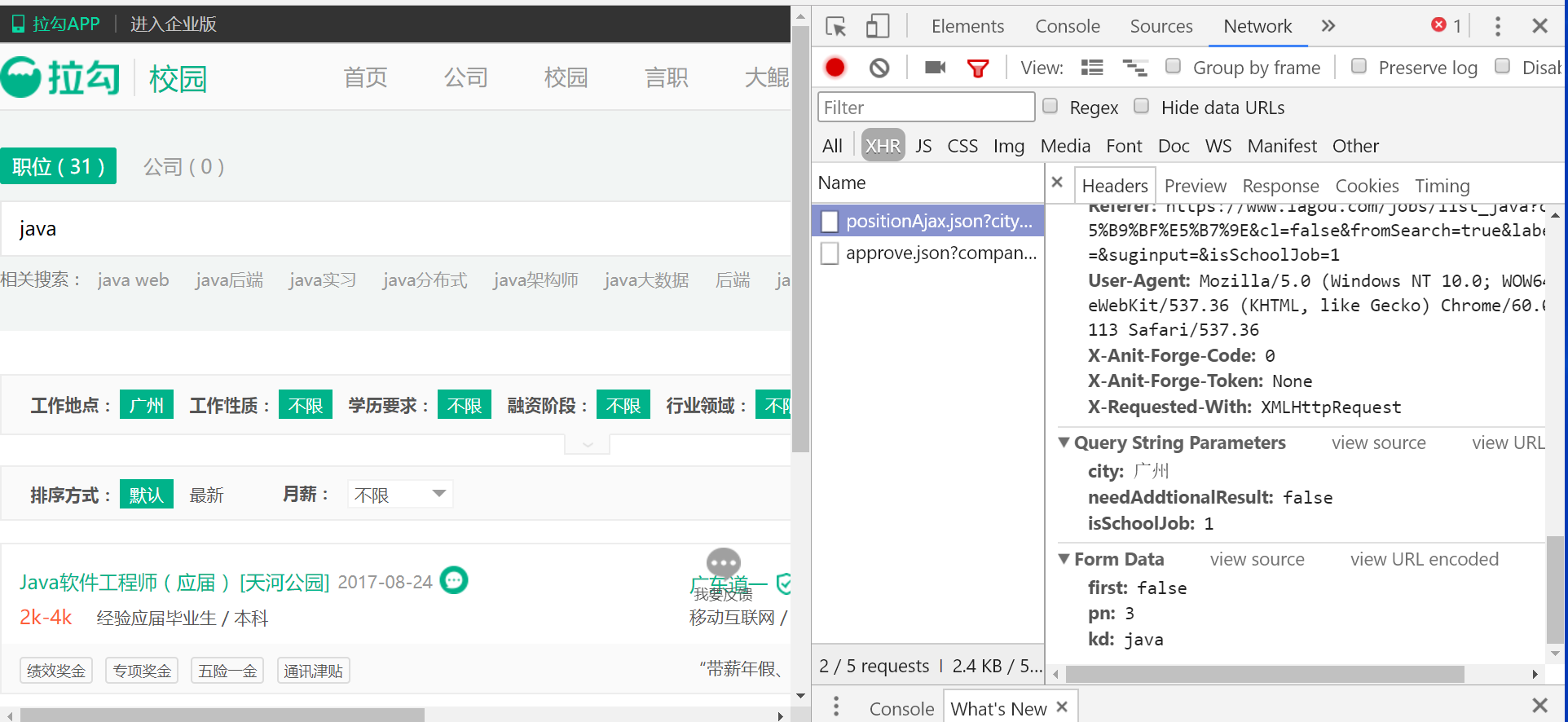
可以看到,传到后台的页码参数正安静地躺在那里呢,也就是图中的pn,而kd就是我们传入的关键字keyword。在这里我们也可以得到请求的url。但是,如何爬取ajax请求返回的数据呢?在scrapy中,我们可以通过start_requests这个函数返回一个请求列表,框架会按照这个请求列表去请求,然后将得到的response交给我们写好的回调函数,json数据就包含在response中。代码如下:
def start_requests(self):
#修改city参数更换城市
url= "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&isSchoolJob=0&city=广州"
requests = []
#range是查询的页码范围
for i in range(1, 60):
#修改kd参数更换关键字
formdata = {'first':'false', 'pn':str(i),'kd':'java'}
request = FormRequest(url, callback=self.parse_model,formdata=formdata)
requests.append(request)
print(request)
return requests这里我们同样需要构造我们的请求头,scrapy框架会自动去读取的。
custom_settings = {
"DEFAULT_REQUEST_HEADERS": {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_java?',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
},
"ITEM_PIPELINES": {
'lagou.pipelines.LagouPipeline': 300
}
}分析传回来的json数据的结构,可以得到我们的处理函数如下:
def parse_model(self, response):
print(response.body.decode())
jsonBody =json.loads(response.body.decode())
results = jsonBody['content']['positionResult']['result']
items=[]
for result in results:
item=LagouItem()
item['name']=result['positionName']
item['workLocation']=result['city']
if result['district']:
item['workLocation']+=result['district']
if result['businessZones']:
for zone in result['businessZones']:
item['workLocation'] +=zone
#item['catalog']
item['money']=result['salary']
item['demand']=result['workYear']+"/"+result['education']
item['skillLabel']=",".join(result['positionLables'])
item['positionAdvantage']=result['positionAdvantage']
item['publishTime']=result['formatCreateTime']
item['company']=result['companyFullName']
item['companyField']=result['industryField']
item['companyLabelList']=",".join(result['companyLabelList'])
item['detailLink']="https://www.lagou.com/jobs/"+str(result['positionId'])+".html"
item['detailCompany']="https://www.lagou.com/gongsi/"+str(+result['companyId'])+".html"
items.append(item)
return itemsItem具体如下:
class LagouItem(Item):
name = Field() # 职位名称
workLocation = Field() # 工作地点
catalog = Field() # 职位类别
money= Field() # 薪资水平
demand=Field() # 要求
skillLabel=Field() # 技能标签
publishTime = Field() # 发布时间
company = Field() # 公司名称
companyField=Field() # 公司服务领域
companyLabelList=Field() # 公司简介
positionAdvantage=Field() # 职位福利
detailLink = Field() # 职位详情页链接
detailCompany=Field() # 公司详情页链接数据提取完之后,由Pine来处理并进行后续操作,如储存在excel/数据库中。这里我将爬到的数据存到xlsx中。代码如下:
class LagouPipeline(object):
def __init__(self):
self.workbook = Workbook()
self.ws = self.workbook.active
self.ws.append(['职位名称', '工作地点', '薪资水平', '要求', '技能标签', '发布时间','公司名称','公司服务领域','公司简介','职位福利','职位详情页链接','公司详情页链接']) # 设置表头
#self.file = codecs.open('tencent.json','w', encoding='utf-8')
def process_item(self, item, spider):
line = [item['name'], item['workLocation'],item['money'], item['demand'], item['skillLabel'],
item['publishTime'],item['company'],item['companyField'],item['companyLabelList'],item['positionAdvantage'],item['detailLink'],item['detailCompany']] # 把数据中每一项整理出来
self.ws.append(line)
self.workbook.save('lagou.xlsx') # 保存xlsx文件
#line = json.dumps(dict(item), ensure_ascii=False)+ "\n"
#self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()最后为了防止拉勾网的反爬虫机制,在setting里设置拒绝遵守robot协议,并且设置爬取时延,防止被认为是爬虫。
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 10
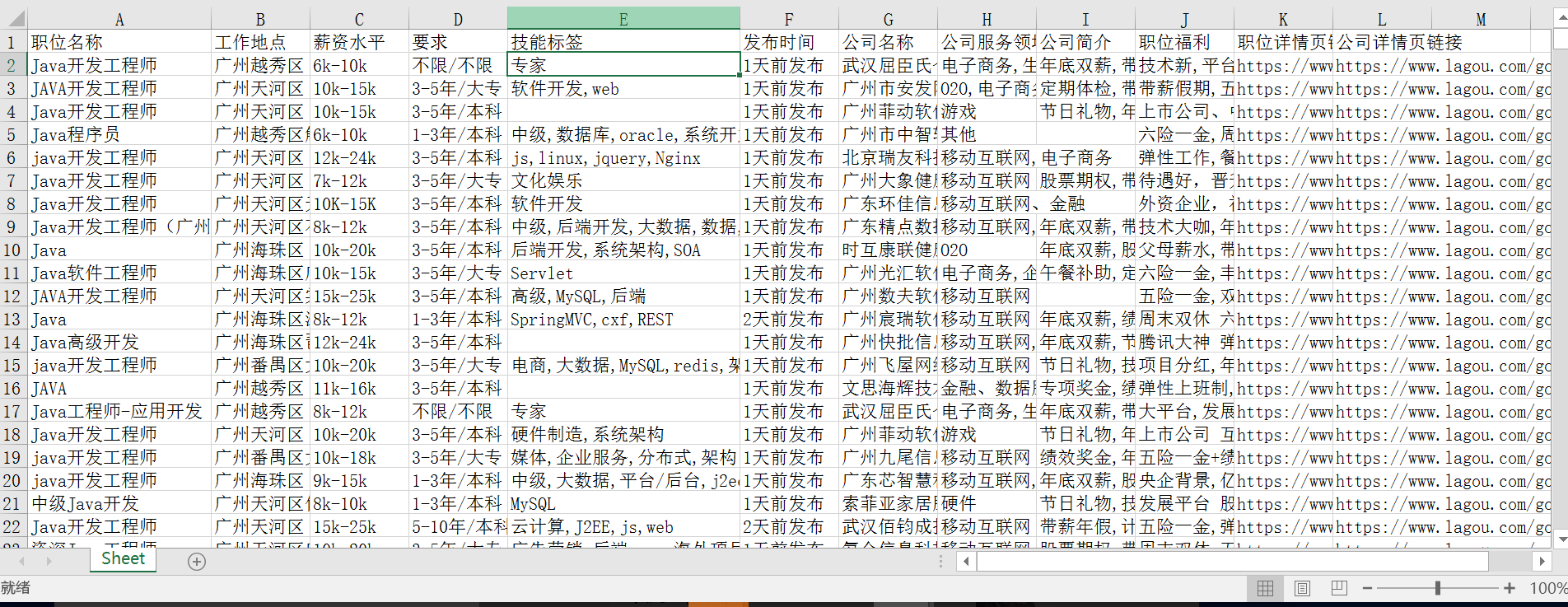
最终效果如下:

















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









