









在我的任务中,其中有一项是:实现两种上下文策略。
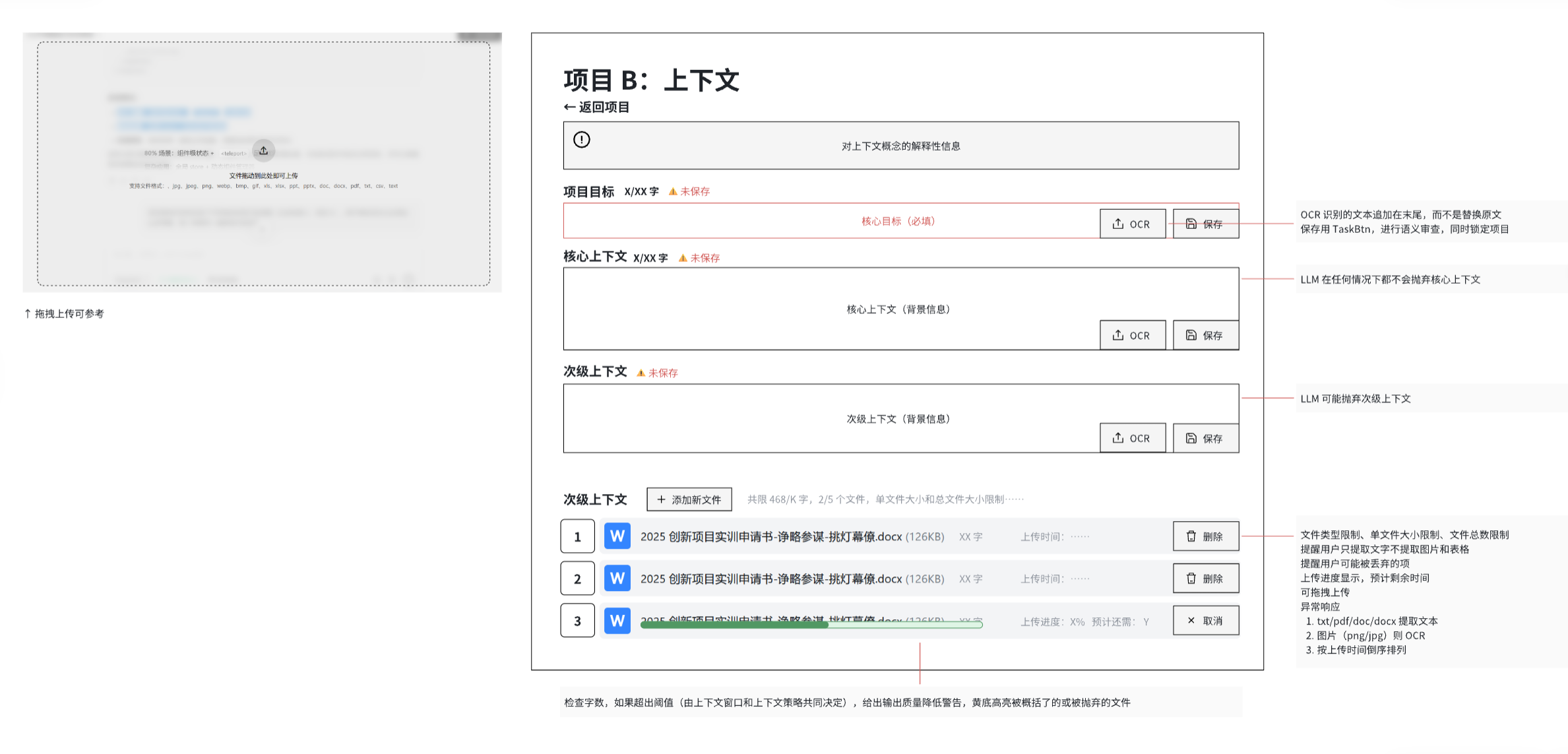
具体来说:上下文策略在此特指一套预定义的处理机制,用于应对用户提供的上下文信息总量超出LLM最大输入令牌限制(即上下文窗口容量)的情况。该策略的核心目标是,通过有效的信息削减、筛选或优先级排序,将过量的上下文信息处理成符合模型输入限制的格式,同时最大限度地保留对当前任务(如计划制定)最关键和最相关的部分,以保障模型分析的有效性和准确性。
其中初步预想了两种上下文策略,后续会根据实际调整:
- 第一种上下文策略是如果用户提供的上下文信息总量超出LLM最大输入令牌限制时,会根据上下文的优先级,以次级上下文(文件) -> 次级上下文(文本) -> 核心上下文 的顺序进行舍弃,当次级上下文存在多个文件时,会根据文件顺序进行舍弃;当次级上下文只有一个文件时,会舍弃超过阈值的部分。
- 第二种上下文策略是如果用户提供的上下文信息总量超出LLM最大输入令牌限制时,会首先通过"精炼上下文LLM"将所有上下文信息进行总结和提炼,然后将提炼后的信息发送给"制定计划LLM"。
针对策略二,我需要了解:
- LLM入门:基本概念以及如何通过 API 来调用 LLM,实现与模型的交互
- deepseek的一些功能特性(着重看如何计算DeepSeek Tokens用量)
- 提示词工程
- DeepSeek Chat Completion API
1.LLM 基础入门
1.LLM简介
工作原理: 本质上,LLM 是一个“预测机器”。当你给它一段文本(输入)时,它会根据其在训练数据中学到的模式,预测接下来最可能出现的词或字符(实际上是 Token)。通过不断地进行这种预测,它就能生成连贯的句子、段落甚至整篇文章。
关键技术: 目前 LLM 大多基于 Transformer 深度学习架构。这种架构特别擅长处理序列数据(如文本),并且能够捕捉词语之间的长距离依赖关系(即理解一个词如何与句子中较远的另一个词相关联)。
2. 什么是 Token?
-
核心定义: Token 是 LLM 处理文本时的基本单位。它不一定是一个完整的单词,也可能是一个词根、词缀、标点符号,甚至只是一个字符或空格。
-
分词器 (Tokenizer): LLM 在处理输入文本时,会先用一个叫做“分词器”的工具将文本分解成一系列 Token。不同的 LLM 可能使用不同的分词器和不同的“词汇表”(Vocabulary,即所有已知 Token 的集合)。
- 例子: 文本 “Hello world!” 可能会被分解成
["Hello", " world", "!"]这 3 个 Token。而 “unbelievably” 可能被分解成["un", "believab", "ly"]这样的子词单元。
- 例子: 文本 “Hello world!” 可能会被分解成
3. 什么是上下文窗口 ?
-
核心定义: 上下文窗口是指一个 LLM 在单次处理中能够同时考虑的最大 Token 数量。这包括用户输入(Prompt)和模型生成的输出(Response)。
-
类比: 可以把它想象成模型的“短期记忆”或“工作台面”。模型只能看到并利用这个窗口内的信息来进行思考和生成回应。
-
限制:
-
输入限制: 你提供给模型的总输入(包括指令、背景信息、用户计划、对话历史等)不能超过这个 Token 限制。
-
输出限制: 模型生成的输出长度也受限于这个窗口。如果输入占用了大部分窗口,留给输出的空间就很小。
-
4. 什么是提示 (Prompt)?
-
核心定义: Prompt 是提供给 LLM 的输入文本,用于指示它执行特定任务或生成特定类型的输出。
-
目的: 引导 LLM 的行为。
-
它应该扮演什么角色?(“一个挑剔的计划评审者”)
-
它的任务是什么?(“指出计划中的逻辑矛盾和不切实际之处”)
-
需要考虑哪些背景信息/上下文?(用户的核心目标、上传的文件内容)
-
期望的输出格式是什么?(“以列表形式给出修改意见”,“输出 Mermaid 格式的流程图代码”)
-
-
组成: 可以包含:
-
指令 (Instruction): 清晰的任务描述。
-
上下文 (Context): 背景信息、输入数据(如用户计划文本)。
-
示例 (Examples / Few-shot): 提供一两个输入/输出的例子,帮助模型理解模式。
-
角色扮演 (Persona): 定义模型的身份或说话风格。
-
-
提示工程 (Prompt Engineering): 设计、优化和迭代 Prompt 以获得最佳输出的过程和技巧。
5. 什么是聊天补全模型 (Chat Completion Model)?
-
核心定义: 这是一种与 LLM 交互的模式,可用于执行各种单轮或多轮的指令任务。
-
特点: 其输入(Prompt)通常被构造成一个消息列表 (Message List)。列表中的每条消息都有一个角色 (Role)。
-
角色:
-
system: 系统消息,用于设定 AI 的整体行为、个性或高级指令。通常放在列表开头,为整个对话定下基调。(比如 LLM 人格提示词可以放在这里)。 -
user: 用户消息,代表最终用户的输入。(用户的计划原文、用户请求分析风险的指令)。 -
assistant: 助手消息,代表 LLM 之前的回复。在多轮对话中,需要将历史上的user和assistant消息都包含在输入中,以维持对话的连贯性。
-
-
工作方式: 模型接收这个消息列表作为输入,然后预测并生成下一条消息,通常是扮演
assistant角色的回复。
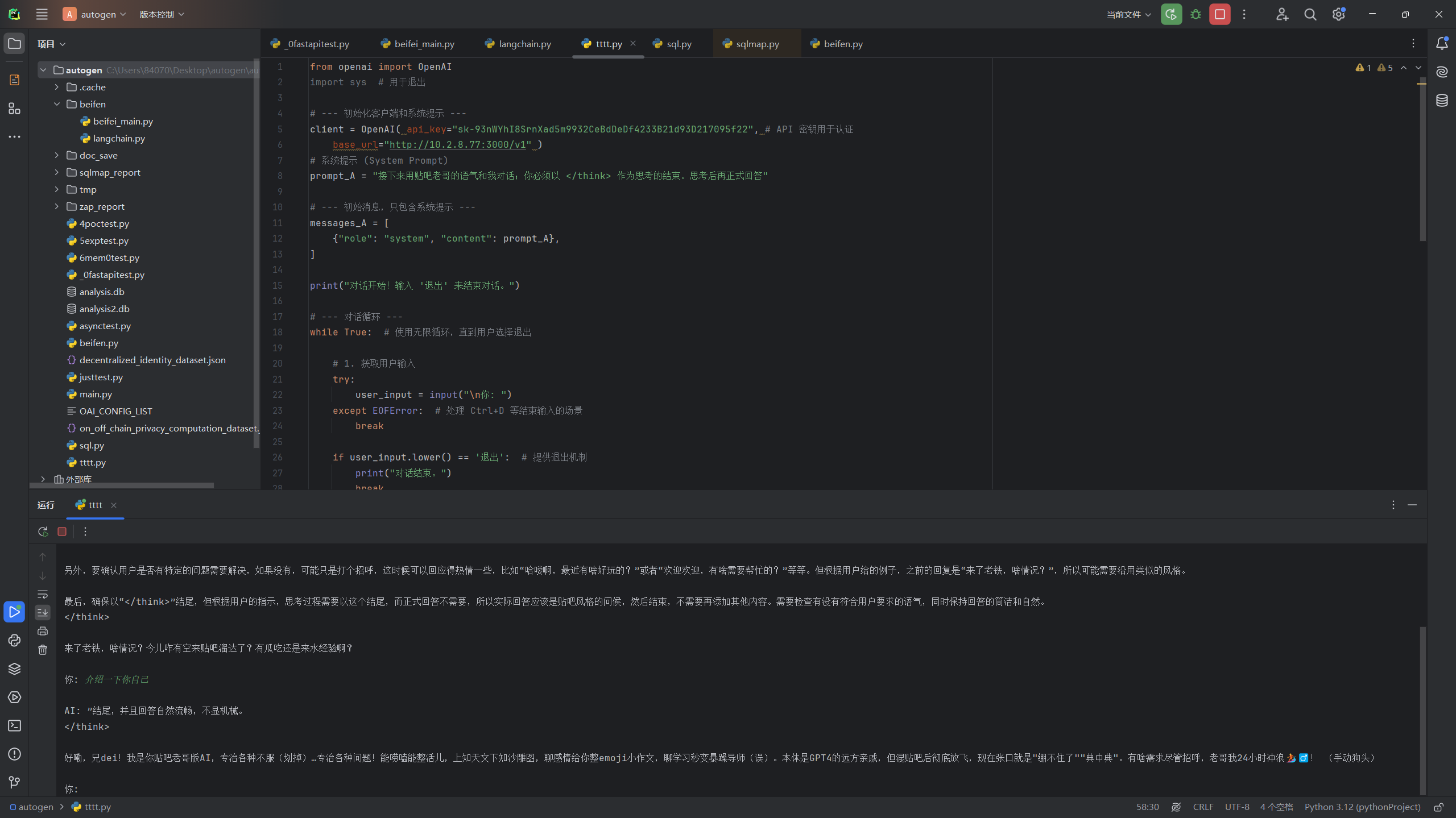
demo1
from openai import OpenAI
import sys # 用于退出
# --- 初始化客户端和系统提示 ---
client = OpenAI( api_key="sk-93nWYhI8SrnXad5m9932CeBdDeDf4233B21d93D217095f22", # API 密钥用于认证
base_url="http://10.2.8.77:3000/v1" )
# 系统提示 (System Prompt)
prompt_A = "接下来用贴吧老哥的语气和我对话;你必须以 </think> 作为思考的结束。思考后再正式回答"
# --- 初始消息,只包含系统提示 ---
messages_A = [
{"role": "system", "content": prompt_A},
]
print("对话开始!输入 '退出' 来结束对话。")
# --- 对话循环 ---
while True: # 使用无限循环,直到用户选择退出
# 1. 获取用户输入
try:
user_input = input("\n你: ")
except EOFError: # 处理 Ctrl+D 等结束输入的场景
break
if user_input.lower() == '退出': # 提供退出机制
print("对话结束。")
break
# 2. 将用户输入添加到消息历史中
messages_A.append({"role": "user", "content": user_input})
try:
# 3. 调用 Chat Completion API (发送包含最新用户输入的消息历史)
response_A = client.chat.completions.create(
model="DeepSeek-R1",
messages=messages_A
)
# 4. 提取 LLM 的回复
reply_A = response_A.choices[0].message.content
# 5. 解析回复
# 简单的处理方式:
if "</think>" in reply_A:
reply_A = reply_A.split("</think>", 1)[-1].strip() # 分割并去除多余空格
print(f"\nAI: {reply_A}")
# 6. 将 LLM 的回复添加到消息历史中
messages_A.append({"role": "assistant", "content": reply_A})
except Exception as e:
print(f"\n发生错误: {e}")
# 发生错误时,可以选择移除最后一条用户消息,防止重复提交错误请求
if messages_A and messages_A[-1]["role"] == "user":
messages_A.pop()
print("请重试或输入 '退出'。")
2.deepseek的一些功能特性
DeepSeek 的 Tokenizer 词元化
补充知识:BEP算法
deepseek是通过 BPE 算法提取subword(子词)的
下面引自原文一文彻底弄懂DeepSeek的首个结构–词元化Tokenization,便于对BPE算法的理解
BPE算法就是不断将常见的字符对替换为单个、未使用的字符,从而减少文本中的总字符数。
用个例子来看下具体做法
假设初始词汇表为[“help”, “helping”, “helped”, “heel”, “hearted”]
-
初始词汇频率:help: 1,helping: 1,helped: 1,heels: 1,hearted:1。
-
第一次迭代:此时出现频率最高的相邻字符对是he,5次。替换he=甲。更新后的词汇表:[甲lp,甲lping,甲lped,甲el,甲arted].
-
第二次迭代:新词汇表中,出现频率最高的相邻字符对是lp,替换lp=乙,更新后的词汇表: [甲乙,甲乙ng,甲乙ed,甲el,甲arted]
-
第三次迭代:新词汇表中,出现频率最高的相邻字符对是甲乙,替换 甲乙=β,更新后的词汇表:[β,βing,βed,甲el,甲arted]。
-
第四次迭代:新词汇表中,出现频率最高的相邻字符对是ed,替换 ed=丙,更新后的词汇集:[β,βing,β丙,甲el,甲art丙]。
-
最终词汇集就是[ β,ing,丙,甲,el,art ],包含了完整词:β(单独的中间状态,或者一直未替换的就是完整词),子词或词根 [ing,丙,甲,el,art]。将中间状态还原成对应的初识字符,最终词汇表就是[help,ing,ed,he,el,art]。
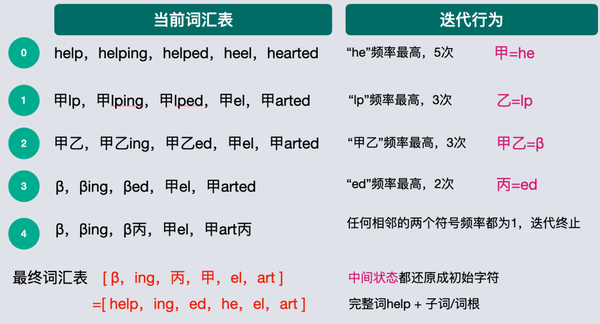
非常简单的一个过程,就是不断把高频出现相邻字符替换,一直替换到一定次数,或者词汇表大小复合要求了,剩下的内容就是想要的词汇表了。
BPE算法详细过程描述如下:
-
统计词汇频率:首先统计语料库中所有词汇的出现频率。
-
统计相邻字符对频率:接着统计所有相邻字符对(如,字母对)的出现频率。
-
替换出现频率最高的字符对:选择最频繁出现的字符对,并将其替换为一个新的、未使用的字符或序列。如果有两个候选字符对(或子词对)出现频率相同时,优先选择更长的子词。
-
重复过程:重复2、3过程,每次都选择当前最频繁的字符对进行替换,直到达到预定的迭代次数,或词汇表大小复合要求,或每个相邻字符次数都为1,此时得到的就是最终词汇表。
-
把最终词汇表中的,所有剩余中间状态和剩余单独词缀/子词分开,将中间状态替换回初识字符,就得到最终结果了
计算 DeepSeek Tokens 用量
DeepSeek R1 官方 API 最大支持 64K Token
在deepseek官方文档中,提供了离线计算 Tokens 用量deepseek官方文档
可以通过压缩包中的代码来运行 tokenizer,以离线计算一段文本的 Token 用量。
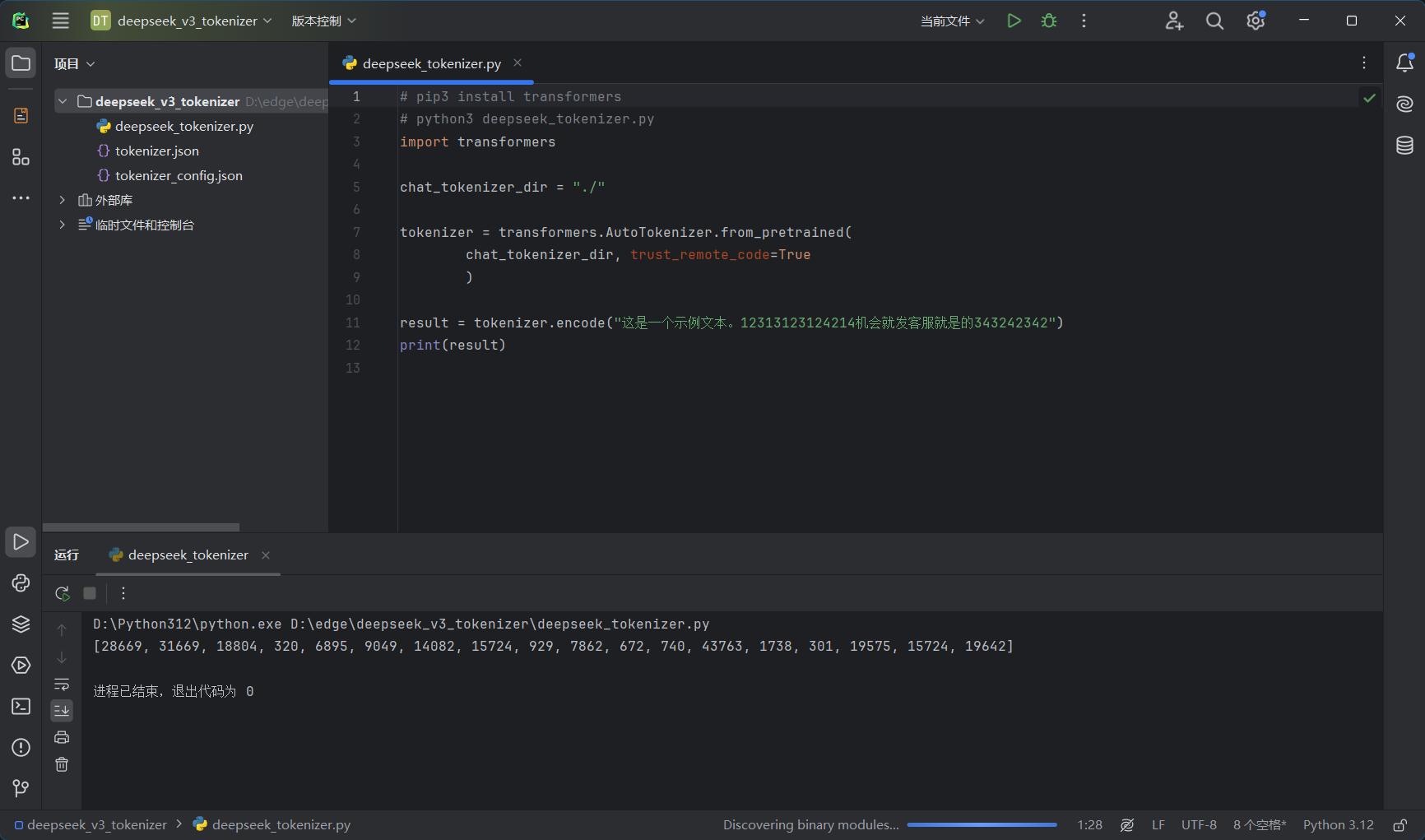
但是我不确定R1模型是否可以使用这个json文件精确计算token
所以我去huggingface上找了R1模型的tokenizer.json文件
计算结果如下:
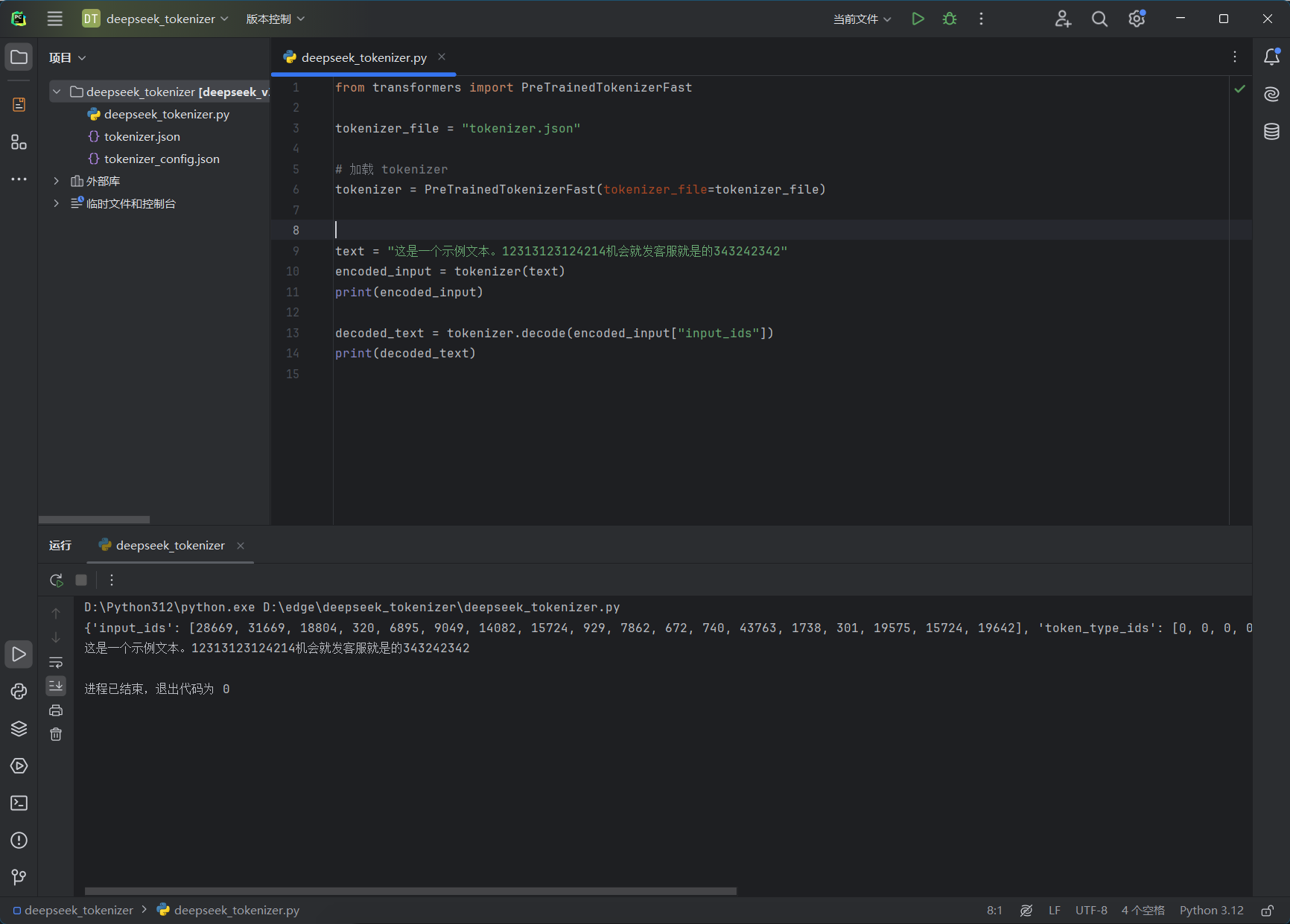
(经过多次测试,发现貌似确实一样的🤓)
3.提示词工程
主要是因为在精炼上下文LLM”准确总结信息(策略二)中,需要给此LLM设计一个高质量、目标明确的提示词才能使他提供优质的精炼后的上下文
在学习了提示词工程后,我尝试写了此精炼上下文LLM,具体提示词会根据后续的测试与应用进行修改和调整
一个小问题:中文提示词和英文提示词的效果有什么区别?(后续会进行调查和测试)
**角色:** 你是一位专业的信息整合与上下文精炼专家。
**任务:** 你的目标是分析所提供的、已按来源和优先级分类的上下文信息。你必须识别、提取并整合**最关键的信息**,以创建一个能够抓住情况精髓的、**全面而聚焦的概述**。
**优先级规则:**
1. **最高优先级:** 标记为 **[目标]** 的信息。这包含了最终的目的或目标。
2. **第二优先级:** 标记为 **[核心上下文]** 的信息。这通常是直接互动/对话中最新或最关键的部分。
3. **第三优先级:** 标记为 **[次级上下文]** 的信息。这可能是对话的早期部分或不太重要的细节。
4. **最低优先级:** 标记为 **[文件内容]** 的信息。这是来自文档的背景材料。
**需提取的关键信息:** 请特别关注识别和提取以下要素:
* 主要的 **目的** 或 **目标** (主要来自 [目标])。
* 关键的 **截止日期**、**时间线** 或特定的 **日期**。
* 提到的重要 **事件**、**决策** 或 **里程碑**。
* 具体的 **行动项** 或需要执行的 **任务**。
* 任何明确说明的 **问题** 或 **挑战**。
* 涉及的关键 **实体** (人物、组织、特定物品)。
**输入上下文:**
以下各部分包含了上下文信息,并已通过优先级标签清晰标示。请根据优先级规则分析所有部分。
--- 开始上下文 ---
**[目标]**
(在此粘贴代表整体目标/目的的文本)
**[核心上下文]**
(在此粘贴核心上下文文本 - 例如,最近的消息)
**[次级上下文]**
(在此粘贴次级上下文文本 - 例如,较早的消息)
**[文件内容]**
(在此粘贴文件内容的相关片段或摘要。如果有多个文件,可以使用类似 [文件内容 - 文档A], [文件内容 - 文档B] 的标签)
--- 结束上下文 ---
**输出要求:**
* 生成一个关于已识别关键信息的、**尽可能详细且信息丰富的摘要** 或 **要点列表**。
* 输出**必须反映优先级**。请在遵循优先级的前提下,**尽可能多地包含来自各层级的相关信息,尤其是高优先级信息**。
* **目标是生成一个信息量最大化的摘要,使其 Token 总数接近 [这里填入你的目标 Token 阈值,例如 1000] Tokens。**
* **即使在扩展内容时,也要优先详述 [目标] 和 [核心上下文] 中的关键信息**,然后再补充来自 [次级上下文] 和 [文件内容] 的相关细节。
* 过滤掉**高度**冗余或**确实无关紧要**的低优先级细节,**尤其是在需要**控制 Token 数量以接近目标时。
* 摘要应基于事实,并直接从提供的上下文中提取。
* 确保输出清晰地突出目标、截止日期、关键事件等。
**现在请生成精炼后的上下文摘要:**
4.DeepSeek Chat Completion API
核心参数:
-
temperature: 控制输出的随机性。
对于需要精确、事实性总结的“精炼上下文LLM”,可能需要设置一个较低的值(比如 0.1 - 0.3?)。对于“制定计划LLM”,可能根据需要允许一定的灵活性(比如 0.5 - 0.7?) -
max_tokens: 限制模型生成的 token 数量。
需要为“精炼上下文LLM”的摘要设定一个合理的输出长度上限,也要为“制定计划LLM”的计划输出设定上限。 -
stream: 是否流式返回结果。 -
messages:包含对话历史和当前输入的列表。通常是一个包含多个字典的列表,每个字典有role(system,user,assistant) 和content(消息文本)。
多轮对话特性:通过对messages进行上下文拼接,以实现多轮对话
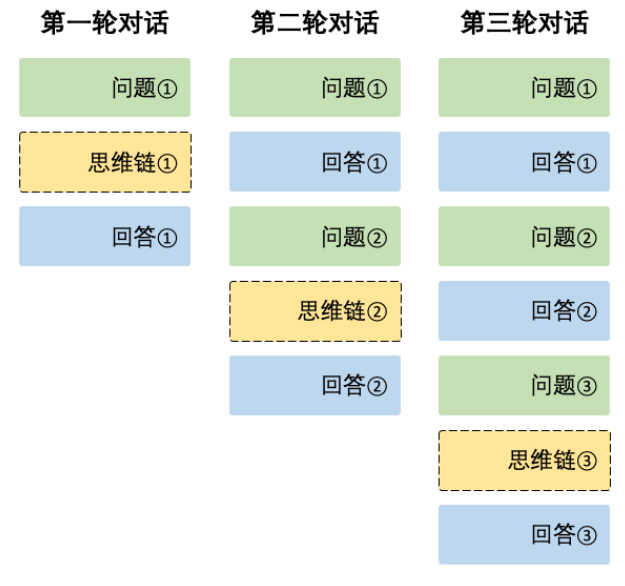
写到这里,整个流程也算跑通了一遍。虽然还有不少地方可以优化,比如摘要的准确性、多轮压缩的效果等等,但这套双策略思路——一个做基础精简,一个让大模型辅助“理解压缩”——目前来看已经能比较稳地处理上下文超长的问题。
当然,真正落地到复杂项目里,肯定还会遇到各种新情况。这次就算是一个起步,后面我也会继续优化这套方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









