






SQL
概述
Structured Query Language 结构化查询语言,是对数据库进行操作的一种语言。
SQL语句的分类
Data Definition Language 数据定义语言(定义数据库、表、列等,命令create drop alter等)
Data Manipulation Language 数据操作语言(增删改数据库中的数据,命令:insert delete update等)
Data Query Language 查询语言(查询数据库中数据表的数据,命令:select where等)
Data Control Language 控制语言(定义数据库的访问权限和安全等级以及创建用户,命令:grant revoke等)
Transaction Control Language 事务控制语言(对数据库进行控制型事务性操作,命令:commit rollback等 )
添加约束详情操作:mysql数据库约束的使用方法_MySQL数据库约束与列操作_曼仔呀的博客-CSDN博客
数据定义语言 DDL
Data Definition Language
命令:create alter drop
创建数据库并进行调整
create database xxxxx; -- 创建数据库 create database xxxx character set xxx; -- 创建指定字符集数据库 alter database xxxx character set xxx; -- 修改某一数据库字符集 drop database xxxx;-- 删除某一数据库 use xxxx; -- 使用某一数据库 select database(); -- 查询正在使用的数据库 show databases; -- 展示数据库 show create database xxxx; -- 展示创建的某一数据库
数据类型
| 数据类型 | 说明 |
|---|---|
| int | 整数, |
| double | 小数,double(3,1) 可输入 :12.1 |
| date | 日期,年月日 |
| datetime | 精准日期,年月日时分秒 |
| timestamp | 时间戳 |
| varchar | 可改变字符,varchar(10)十个长度内改动 |
| char | 不可改变字符,char(10) 无论怎么填写内容都只有十个长度 |
创建数据表
创建create
改动 alter
剔除 drop
-- 在数据库中创建名为 exmple 的数据表并进行如下定义 create table exmple( num int, name varchar(10), sex char(1), birthday date, point double(4,2) ); -- 增加一列 alter table 表名 add 新增列名和类型 alter table exmple add age varchar(4); -- 修改某一列的类型 alter table 表名 modify 该列名和新类型 alter table exmple modify sex char(2); -- 修改某列的名称与类型 alter table 表名 change 旧列名 新列名和新类型 alter table exmple change point id char(18); -- 删除某一列 alter table 表名 drop 要删除的列名 alter table exmple drop sex; -- 修改数据表的字符集 alter table 表名 charset 编码方式 alter table exmple charset gbk; -- 修改数据表的名称 rename table 旧表名 to 新表名 rename table exmple to exmple2;--易错 -- 删除数据表 drop table 表名(if exists 表名) drop table exmple; drop table if exists exmple; -- if exists -- 展示数据表 包含字符集 show create table 表名 show create table exmple; --易混淆 -- 查询数据表的结构 desc 表名 desc exmple; --易混淆
施加约束
添加规则以用来规定,限制。限制表中列的内容,确保数据库满足业务规则。
约束类型
| 约束命令 | 内容 |
|---|---|
| primary key | 添加主键约束,使内容在表中唯一且非空 |
| not null | 使内容非空 |
| unique | 使内容唯一,不能重复,但可为空 |
| auto_increment | 逐渐递增,每次增加1 ,设置属性的列必须为主键 |
| foreign key | 设置外键,只能引用外表中的列的值或使用空值。 |
示例:
-- 自增器起始值为1,可以手动指定 alter table 表名 auto_increment=起始值;-- 创建完表后,添加主键 alter TABLE 表名 add primary key(id);create table exmple( id int primary key auto_increment comment '设置id 为整数列 添加主键元素,并自动增长', name varchar(10) unique comment '设置name 添加唯一约束', gender char(1) not null comment '设置gender 不能为空' ); -- 取消表的主键和自增长 ALTER TABLE exmple MODIFY id int; --取消自增 必须先进行 ALTER TABLE exmple DROP PRIMARY key; --取消主键 在这之前必须先取消自增,因为自增是主键才能有的属性 ALTER TABLE exmple MODIFY id int NOT NULL FIRST,DROP PRIMARY key; -- 或者一次性全部取消
创建表添加注释
comment'xxxxxx' -- 添加注释
create table employee(
id int primary key auto_increment comment '编号',
name varchar(20) not null unique comment '姓名',
gender varchar(10) comment '性别',
birthday date comment '生日',
entry_date date comment '入职日期',
job varchar(30) comment '工作',
salary double not null comment '薪水'
);
复合主键
在设置一列为一个键时,如果无法确定为唯一一行,就用两列或者更多列组合,确定唯一一行
create table `student` (
`id` int(11) not null auto_increment,
`name` varchar(20) not null,
`age` int(11) default null,
primary key (`id`,`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;数据操作语言 DML
Data Manipulation Language
命令:insert、delete、update等
添加数据 insert
语法:
-- 公式
insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);
-- 一一对应
insert into xxx (id,name,gender,salary) values(1,'tom','男',2000);
-- 省略主键
insert into xxx (name,gender,salary) values('jerry','男',3000);
-- 指定字段
insert into xxx (name,salary) values('rose',6000);
-- 省略字段时,类型里的数据必须全写
insert into xxx values (null,'jack','男',7000);
-- varchar、char等 添加字符串需加引号
-- 批量添加数据
insert into xxx values
(1,'aaa','男',5000),
(2,'bbb','女',6000),
(null,'ccc','男',null); -- 数据组用逗号隔开
-- 将一个查询的结果数据插入到一个表 ,大数据中,基本只使用这种方式进行数据的插入
insert into xxx
select * from xxx;
删除数据 delete
删除 行
语法:
delete from xxx (where 条件); -- 公式 delete from xxx where id=1; -- 删除id为1 的一行数据 delete from xxx where gender = '男'; -- 删除性别为 “男” 的若干行数据
注:
-- 不添加指定条件,则删除表中所有数据 delete from xxx;
truncate 删除
delete from xxx; -- 对每一条数据都执行一次删除操作 truncate table xxx; -- 先删除整张表,然后再创建一张新的、相同的表 (效率较高)
修改数据 update
update xxx set 列名1 = 值1 , 列名2 = 值2 , …… (where 条件);-- 公式 update xxx set gender = '女' where name ='tom'; -- 修改tom的性别为女 update xxx set gender = '女' ,salary = 10000 where name = 'tom'; -- 修改tom的性别为女,并工资改为10000 update xxx set gender = '女'; -- 修改所有人的性别为女 update xxx set salary = salary + 2000 where name = 'tom'; -- 把tom的薪水在原有基础上+2000
注: 如果不加任何条件,则会将表中所有记录全部修改。
数据查询语言 DQL
Data Query Language
查询完整语法
select
字段列表
from
表名列表
where
条件列表
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
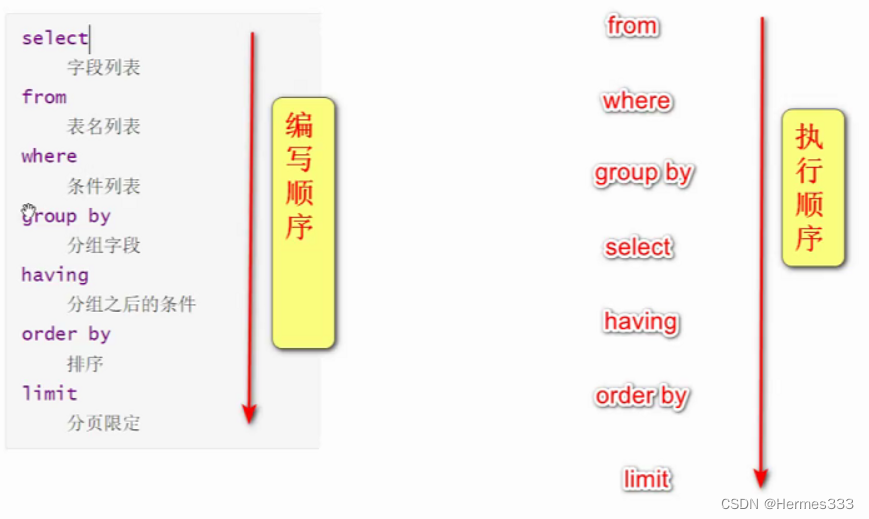
select特点
* select 可以查询 表中的字段 表达式 常量值 函数 * 查询出的结果是一个虚拟表 不影响实际表中的数据
简单查询
==查询所有记录==
语法:
SELECT * FROM 表名; 如果用cmd查询出来的数据为乱码,使用 set names GBK
示例:
-- 创建表
create table stu(
id int,
name varchar(20),
chinese double,
english double,
math double
);
-- 插入记录
insert into stu(id,name,chinese,english,math) values(1,'tom',89,78,90);
insert into stu(id,name,chinese,english,math) values(2,'jack',67,98,56);
insert into stu(id,name,chinese,english,math) values(3,'jerry',87,78,77);
insert into stu(id,name,chinese,english,math) values(4,'lucy',88,NULL,90);
insert into stu(id,name,chinese,english,math) values(5,'james',82,84,77);
insert into stu(id,name,chinese,english,math) values(6,'jack',55,85,45);
insert into stu(id,name,chinese,english,math) values(7,'tom',89,65,30);
==查询表中所有学生的姓名和对应的语文成绩==
语法:
SELECT 字段名1,字段名2... FROM 表名;
举例:
-- 查询所有
select * from stu;
-- 查看班里有哪些人的名字
select name from stu;
select math from stu;
-- 查看表中学生对应的数学成绩
select name,math from stu;
-- 查看jack的所有成绩
select * from stu where name = 'jack'
-- 查看english为78 学生姓名
select id,name,english from stu where english = 78
-- 给所有学生数据成绩加10分
select id , name , math + 10 from stu;去重复
语法: select distinct 字段名1,字段名2... FROM 表名; 举例: -- 去重复 SELECT distinct name FROM stu; -- 可以去重复多个字段, 但两个字段都重复才会去重复 SELECT distinct name, chinese FROM stu;
Ifnull
==统计每个学生的总分==
SELECT name, chinese + english + math FROM stu;注: 在做行运算时,null参与的运算,计算结果都为null
使用ifnull(参数1,参数2) 如果参数1有值,就走参数1 ,如果参数1为null,就走参数2 SELECT name, chinese + ifnull(english,0) + math FROM stu;
总结
* 在做行运算时,null参与的运算,计算结果都为null SELECT '123' + 100; -- 223 如果能转换成整数就跟后面的数值进行相加 SELECT 'abc' + 100; -- 100 如果不能转换成整数 转换为0 在跟后面的数值进行相加
别名
关键字 as
as : as可以省略 ,引号也可省略,给表取别名时不可用引号 1. 可以用在某个字段上 name as 姓名 2. 可以用在函数上 min(sarlay) as 最低工资 3. 可以用在表上 from sutdent as s
注意事项: 如果给表起了别名,后面在使用的时候,必须要用别名
条件查询
语法
SELECT 字段名 FROM 表名 [WHERE 条件];
运算符
| 运算符 | 说明 |
|---|---|
| > 、< 、<= 、>= 、= 、<> != | <>在 SQL 中表示不等于,在 mysql 中也可以使用!= 没有== |
| BETWEEN...AND | 在一个范围之内 |
| IN( 集合) | 集合表示多个值,使用逗号分隔 |
| IS NULL 不为空 is not null | 查询某一列为 NULL 的值,注:不能写=NULL |
| LIKE | 模糊查询 占位符: _:单个任意字符 %:多个任意字符 |
| AND 或 && | 与,SQL 中建议使用前者,后者并不通用。 |
| OR 或 || | 或 |
| NOT 或 ! | 非 |
示例:
-- 创建表
CREATE TABLE stu1 (
id int,
name varchar(20),
age int,
sex varchar(5),
address varchar(100),
math int,
english int
);
-- 插入记录
INSERT INTO stu1(id,NAME,age,sex,address,math,english) VALUES
(1,'马云',55,'男','杭州',66,78),
(2,'马化腾',45,'女','深圳',98,87),
(3,'马景涛',55,'男','香港',56,77),
(4,'柳岩',20,'女','湖南',76,65),
(5,'柳青',20,'男','湖南',86,NULL),
(6,'刘德华',57,'男','香港',99,99),
(7,'马德',22,'女','香港',99,99),
(8,'德玛西亚',18,'男','南京',56,65);
-- 查询math分数大于80分的学生
SELECT * FROM student2 WHERE math > 80;
-- 查询english分数小于或等于80分的学生
SELECT * FROM student2 WHERE english <= 80;
-- 查询age等于20岁的学生
SELECT * FROM student2 WHERE age = 20;
-- 查询age不等于20岁的学生
SELECT * FROM student2 WHERE age != 20;
--查询age大于35且性别为男的学生(两个条件同时满足)
SELECT * FROM student2 WHERE age > 35 AND sex = '男';
--查询age大于35或性别为男的学生(两个条件其中一个满足)
SELECT * FROM student2 WHERE age > 35 OR sex = '男';
--查询id是1或3或5的学生
SELECT * FROM student2 WHERE id = 1 OR id =3 OR id = 5;
SELECT * FROM student2 WHERE id IN(1,3,5); -- in关键字 ,查询id是1或3或5的学生
--查询id不是1或3或5的学生
SELECT * FROM student2 WHERE id NOT IN(1,3,5);
--查询english成绩大于等于77,且小于等于87的学生
SELECT * FROM student2 WHERE english >=77 AND english <=87;
SELECT * FROM student2 WHERE english BETWEEN 77 AND 87;
--查询英语成绩为null或不为null的学生
SELECT * FROM student2 WHERE english IS NULL;
SELECT * FROM student2 WHERE english IS NOT NULL;
--查询姓马的学生
SELECT * FROM student2 WHERE name LIKE '马%'; -- %表示任意长度的字符
--查询姓不为马,但名中包含'马'字的学生
SELECT * FROM student2 WHERE name LIKE '_%马%';
--查询姓马,且姓名有三个字的学生
SELECT * FROM student2 WHERE name LIKE '马__'; -- _表示1个字符
--where 1 = 1 为了拼接后面要过滤的条件,如果没有条件就查询所有,如果有条件就依据条件查询
select * from stu1 where 1=1 ;
select * from stu1 where 1=1 and address = '杭州';高级查询
排序查询
SELECT 字段名 FROM 表名 [WHERE条件] ORDER BY 字段名 [ASC|DESC];
ASC: 升序,默认值
DESC: 降序
注: 如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
聚合(集)函数
概述
在sql中函数主要要对数据进行处理。函数可以把经常使用的代码封装起来,需要的时候直接调用即可。这样既提高了编写代码的效率,又提高了可维护性。
常用函数类型
-
算术函数
-
字符串函数
-
日期函数
-
转换函数
-
聚合函数/聚集函数
函数sql语法
SELECT 聚合函数(列名) FROM 表名;
常见聚合函数
| 聚合函数 | 说明 |
|---|---|
| count(*) | count(主键) | 计算表中的总记录数 |
| max | 计算最大值 |
| min | 计算最小值 |
| sum | 计算和 |
| avg | 计算平均值 |
-
注意:==聚合函数的计算,排除null值。==
-
解决方案:
-
==选择不包含非空的列进行计算==
-
==IFNULL函数==
-
示例:
-- 查询学生总数
SELECT COUNT(*) FROM stu;
select count(1) from stu;-- sql优化方案 count(1)效率高
-- 查询年龄大于40的总数
SELECT COUNT(*) FROM stu WHERE age >40;
-- 查询数学成绩总分 平均分
SELECT SUM(math) FROM stu;
SELECT AVG(math) FROM stu;
-- 查询数学成绩最高分 最低分
SELECT MAX(math) FROM stu;
SELECT MIN(math) FROM stu;
-- 查看最高分的人, 通过子条件查询(把一个sql的结果当作另一个sql的条件来用)
select id ,name ,math from stu where math = (select max(math) from stu);其它函数
| 函数名 | 说明 | 作用 |
|---|---|---|
| length(str) | 字符函数 | 获取字符的字节个数 |
| upper(str) | 字符函数 | 将字符转换为大写字符 |
| lower(str) | 字符函数 | 将字符转换为小写字符 |
| substring(str,pos) | 字符函数 | 截取从指定索引处后面所有的字符 |
| substring(str,pos,len) | 字符函数 | 截取从pos索引开始截取len个字符 |
| substring_index(str, delimiter, count) | 字符函数 | 从字符串中提取指定分隔符的子字符串,delimiter:用于分隔的字符串。 count:要提取的子字符串的个数,正数,从左侧开始提取,负数,从右侧开始 |
| replace(str,from_str,to_str) | 字符函数 | 将str中的字符 from_str字符替换成to_str字符 |
| round(x) | 数学函数 | 四舍五入 |
| round(x,d) | 数学函数 | 四舍五入 d:代表的是保留小数点后几位 |
| ceil(x) | 数学函数 | 向上取整 |
| floor(x) | 数学函数 | 向下取整 |
| mod(n,m) | 数学函数 | 取余数 mod(10,3) 相当于: select 10 % 3 |
| sqrt(x) | 数学函数 | 求平方根 |
| POWER(a,b) | 数学函数 | 求a的b次幂 |
| LOG(x) | 数学函数 | 求以e为底的自然对数 |
| LOG(x, base) | 数学函数 | 求以指定底数为底的对数 |
| EXP(x) | 数学函数 | 求e的x次方。 |
SIN(角度值)、COS()、TAN() | 数学函数 | 三角函数 |
| str_to_date(str,format) | 日期函数 | 将日期字符转换成指定格式的日期 str_to_date('1990-11-11','%Y-%m-%d'); |
| date_format(date,format) | 日期函数 | 将日期转换成字符串 date_format(now(),'%Y/%m/%d'); |
format格式
| DATE_FORMAT字符串格式 | 格式化日期 |
|---|---|
%Y/%m/%d | 2022/04/26 |
%Y-%m-%d | 2022-04-26 |
%e/%c/%Y | 4/8/2022 |
%d/%m/%Y %H:%i | 26/04/2022 17:27 |
%b %d %Y %h:%i %p | Apr 26 2022 05:28 PM |
%Y-%m-%d %T:%f | 2022-04-26 17:29:30:000000 |
%W %D %M %Y %T | Tuesday 26th April 2022 17:31:34 |
format样式整理:
年:%Y 显示四位 : 2015 %y 只显示后两位 :15
月: %M 月份的英文显示:October %m 月份的阿拉伯显示:01-12 %b 月份的英文缩略显示:Oct
%c 月份的阿拉伯显示:1-12
日: %d 阿拉伯显示:00-31 %D 带有英文后缀:1st-31th %e 阿拉伯显示:1-31
%j 年的天:001-366
时: %H :00-23 %h:01-12 %I:01-12 %k:0-23 %l:1-12
分: %i:00-59
秒: %S:00-59 %s:00-59
微秒: %f
AM/PM: %p
12小时制时间: %r: 02:02:44 PM
24小时制时间: %T: 14:02:44
周: %W:周的英文显示 %w 周的阿拉伯显示 :0(星期日)-6(星期六)
%a 周的英文缩略显示:Mon-
-- 在GBK 编码下,1个中文字符占2个字节,所以总字节长度2
-- 在UTF-8 编码下,1个中文字符占3个字节,所以总字节长度3
select length('码农'); -- 获取长度
select length('abc');
select upper('abc');
select lower('ABC');
select ceil(3.4);
select floor(3.4);
select round(5.5);
select md5('123abc');
select str_to_date('2022/01/02', '%Y/%m/%d'); -- 2022-01-02分组查询
对一列数据进行分组,相同的内容分为一组,通常与聚合函数一起使用,完成统计工作
SELECT 字段 1,字段 2... FROM 表名 [where条件] GROUP BY 分组字段 [HAVING 条件] [order by];
-
==注意事项==
-
分组之后查询的字段:分组字段、聚合函数
-
where和having的区别?-
where在分组之前进行过滤。having在分组之后进行过滤。 -
where后不可以跟聚合函数,having可以进行聚合函数。 -
having 不能脱离 group by ,如果脱离group by 不能直接使用,一般与group by 一块使用
-
换句话说,
WHERE子句用于过滤行,而HAVING子句用于过滤组
-
-
where:操作的数据源: 原始表 -
having:操作的数据源: 结果集
-
分页查询
SELECT * 字段列表 [as 别名] FROM 表名 [WHERE 子句] [GROUP BY 子句][HAVING 子句][ORDER BY 子句][LIMIT 子句];
LIMIT offset,length;
-
offset:起始行数,从 0 开始计数,如果省略,默认就是 0 -
length:显示的条数
开始的索引 = (当前的页码 - 1) * 每页显示的条数
-- 每页查询显示3条数据 -- 开始行数 = (当前页 - 1) * 要显示的条数 -- 0 = (1 - 1)* 3 -- 3 = (2 - 1)* 3 -- 6 = (3 - 1)* 3 SELECT * FROM stu LIMIT 0,3; -- 第1页 SELECT * FROM stu LIMIT 3,3; -- 第2页 SELECT * FROM stu LIMIT 6,3; -- 第3页
多表操作
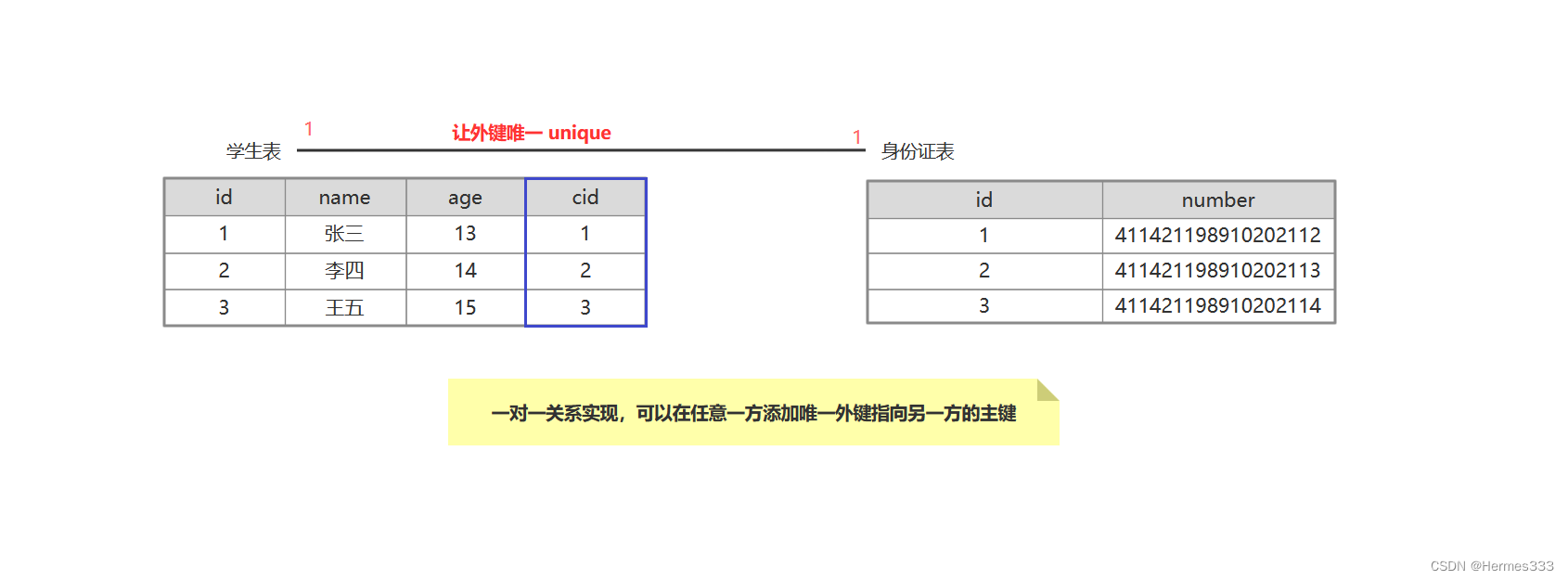
一对一
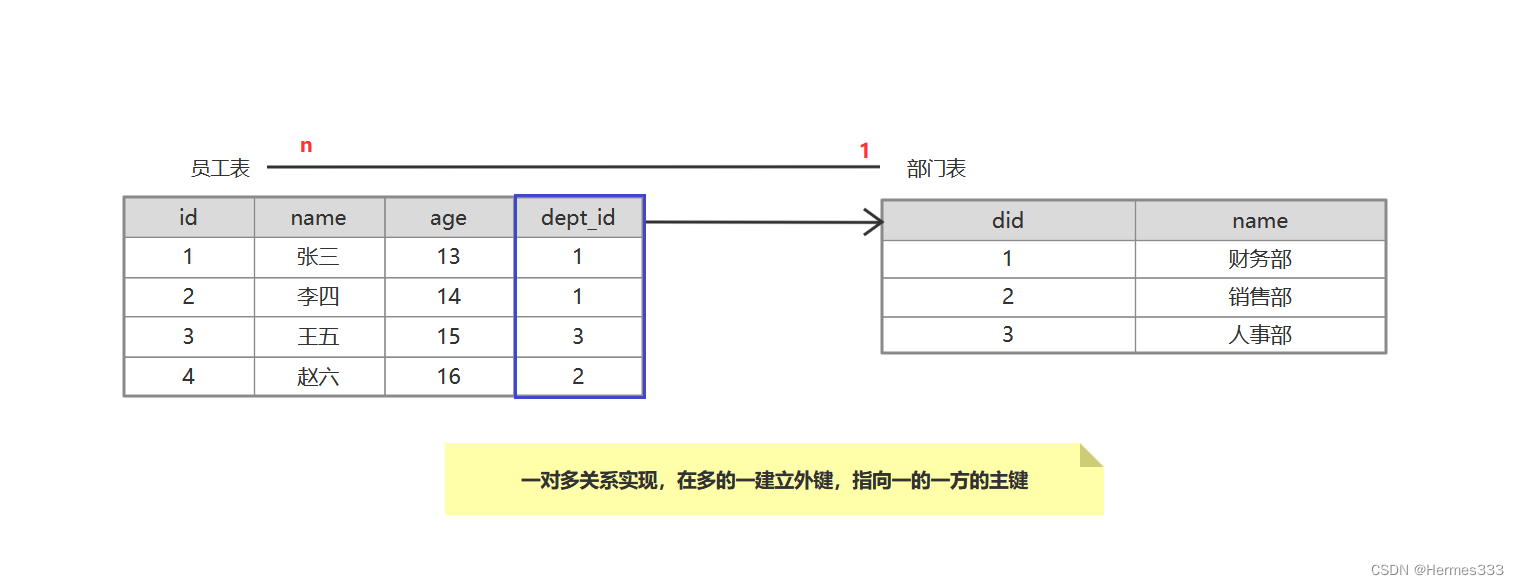
一对多
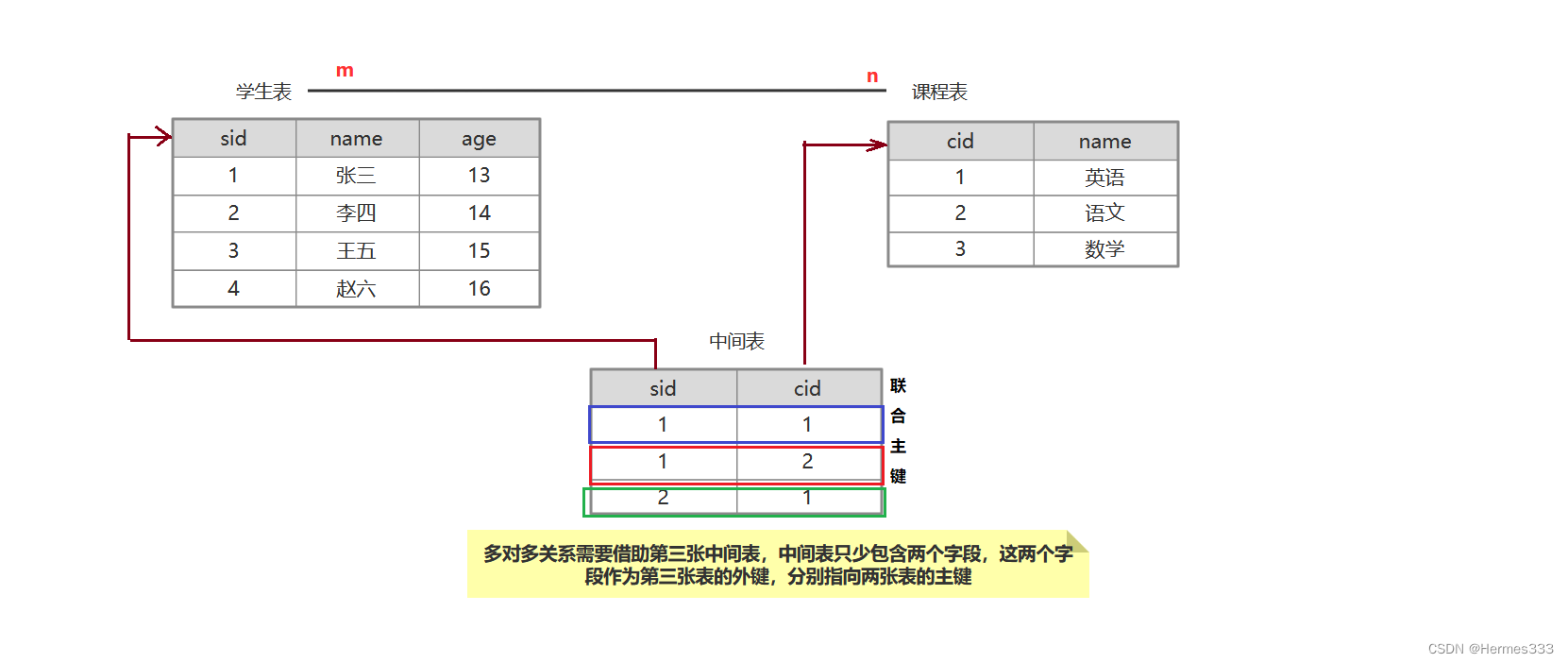
多对多
外键约束
限定二张表有关系的数据,保证数据的正确性、有效性和完整性
create table 表名(
列名 数据类型 约束名,
列名 数据类型 约束名,
[constraint] [约束名] foreign key(外键列) references 主表(主键)
);
已有表添加外键
alter table 表名 add [constraint] [约束名] foreign key(外键列) references 主表(主键);
删除外键约束
alter table 表名 drop foreign key 约束名;
sql查看外键约束
SELECT
CONSTRAINT_NAME
FROM
INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE
REFERENCED_TABLE_NAME = '被引用表名'
AND TABLE_NAME = '引用表名'
AND REFERENCED_COLUMN_NAME = '被引用表的列名';
示例
-- 创建部门表
-- 一方,主表
CREATE TABLE dept(
d_id INT PRIMARY KEY AUTO_INCREMENT,
d_name VARCHAR(20),
d_location VARCHAR(20)
);
-- 创建员工表
-- 多方,从表
CREATE TABLE emp(
e_id INT PRIMARY KEY AUTO_INCREMENT,
e_name VARCHAR(20),
e_age INT,
d_id INT, -- 外键对应主表的主键
-- CONSTRAINT emp_ibfk_1 可以省略不写
-- CONSTRAINT `emp_ibfk_1` FOREIGN KEY (`d_id`) REFERENCES `dept` (`d_id`)
FOREIGN KEY (`d_id`) REFERENCES `dept` (`d_id`)
);造成笛卡尔积的情况
如果不加过滤条件,a表中的每一条记录,都和b表中的每一条进行匹配连接。 会造数据量级的增长,如果在大数据中,这种情况是灾难性的,避免该情况发生。
SELECT * FROM emp ,dept; -- 如果要得到正确的数据,需要添加过滤条件 select * from a,b where a.a_id = b.a_id;
注:
1) 主表不能删除从表已引用的数据 2) 从表不能添加主表未拥有的数据 3) 先添加主表数据再添加从表数据 4) 先删除从表数据再删除主表数据 5) 外键约束允许为空但不能是错的 == 主外键关系: 注意事项 == -- 前者:建立【实际的主外键关系】 和 后者:建立【逻辑主外键关系】 的区别? -- 前者有约束,必须按照外键约束来写 -- 后者没有外键约束,但你不能写主键不存在 -- 前者删除受主外键约束,后者删除不再受主外键约束 -- 前者可能会造成级联删除, 后者不会造成级联删除
在实际开发中,一般不建立实际的外键关系,而是建立逻辑外键关系 在互联网公司中,不建立实际的外键关系,在实际传统行业中,需要建立实际的外键关系
多表查询
笛卡尔积,是指集合A中元素与B中元素所有的两两组合。
内链接查询
必须表与表之间的关系一一对应
隐式内连接查询
Implicit Inner Join
select * from a,b where a.a_id = b.a_id;
没有INNER JOIN,形成的中间表为两个表的笛卡尔积,需要使用条件保留有意义的数据
-- 查询老师对应的课程 结果:必须主外键一一对应
select * from teacher , course where teacher.t_id = course.t_id;显式内连接查询
Explicit Inner Join
-- 查询老师对应的课程 结果:必须主外键一一对应
select * from a inner join b on a.a_id = b.a_id
显示的内连接,一般称为内连接,有INNER JOIN,形成的中间表为两个表经过ON条件过滤后的笛卡尔积,可以省略INNER
-- 查询老师对应的课程
select * from teacher inner join course on teacher.t_id = course.t_id;外链接查询
左外连接
select * from a left [outer] join b on a.a_id = b.b_id
把left 关键字之前的表,是定义为左侧。 left关键字之后的表,定义右侧。
当两个表连接的时候,如果左侧表有数据,右侧的表没有对应的数据。会把左侧的表中的数据显示出来。
示例:
select * from teacher left join course on teacher.t_id = course.t_id;右外连接
select * from a right [outer] join b on a.a_id = b.b_id
right之前的是左侧,right之后的是右侧。
当两个表连接的时候,如果右侧表有数据,左侧的表没有对应的数据。会把右侧的表中的数据显示出来
select * from teacher right join course on teacher.t_id = course.t_id;全外连接
把两侧的内容都显示出来
-- union 是把两个查询的结果进行合并。 去掉重复的合并
select * from teacher left join course on teacher.t_id = course.t_id
union
select * from teacher right join course on teacher.t_id = course.t_id;
-- union all 把两个结果集都显示出来,不会合并去重复
select * from teacher left join course on teacher.t_id = course.t_id
union all
select * from teacher right join course on teacher.t_id = course.t_id;
-- mysql 不支持 full 关键字 全外连接。
select * from a full join b on a.a_id = b.a_id 关联子查询
关联子查询:将一个查询结果当作另一个查询的条件部分(可以是表,也可以是过滤元素)
数据控制语言 DCL
用户权限
创建用户
create user '用户名'@'主机名' identified by '密码';
主机名:限定客户端登录ip 指定ip:127.0.0.1 (localhost) 任意ip:%
例如:
create user 'temp'@'%' identified by '123';删除用户
drop user '用户名'@'主机名'
查看权限
show grants for '用户名'@'主机名';
例如:
show grants for 'temp'@'%';授于权限
grant 权限1, 权限2 ,…… on 数据库名.表名 to '用户名'@'主机名' ;
例如:
grant select , update , … on test.temp to 'temp'@'%' ;
-- 授予权限后,需刷新权限
flush privileges;授于全部-指定的库和表
-- 授于整个test 库的权限
-- jack 这个用户对所有库下的所有表有操作权限
grant all on *.* to 'jack'@'%' ;
-- 刷新权限
flush privileges;撤销授权
revoke 权限1 , 权限2 , …… on 数据库名.表名 from '用户名'@'主机名';
例如:
-- 撤销删除权限
revoke delete on test.temp from 'temp'@'%' ;
-- 撤销全部权限
revoke all on *.* from 'temp'@'%' ;密码管理
普通用户
set password = password('密码')
-- 加密函数
SELECT PASSWORD('123');
select md5('123')管理员
-- 登录mysql
mysql -uroot -proot
-- 切换mysql默认的数据库【mysql】
use mysql;
-- 修改mysql服务器中自带的mysql数据库的user表下有一个authentication_string修改即可
update user set authentication_string =password('abc') where user='root';
-- 或者使用 set 命令修改密码
set password for 'temp'@'%' = password('132'); -- 修改之后需要重启服务器三大范式
数据库第一范式
指设计数据表时,要实现功能详尽,即必须明确字段
数据库第二范式
指设计数据表时,数据表要功能集聚,一张表只负责一块内容,即在第一范式的基础上,明确每一张表
数据库第三范式
指设计数据表时,尽可能在减少表之间依赖 ,减少耦合 的情况下建立连接,即在第一范式和第二范式的基础上,让表与表之间建立关系
索引
提高查询的效率
-- 创建索引
create index 索引名 on 表名(字段名)
--查看索引
show index from 表名
-- 删除索引
drop index from 表名横表/纵表(重要)
横表就是普通的建表方式,表结构为:主键、字段1、字段2、字段3... 纵表表结构为: 主键、字段代码、字段值。字段代码为字段1、字段2、字段3...。
横表
优点:一行表示了一个实体记录,清晰可见,一目了然。 缺点:如果现在要给这个表加一个字段,那么就必须重建表结构。
纵表
优点:如果现在要给这个表加一个字段,只需要添加一些记录。 缺点:数据描述不是很清晰,而且会造成数据库数据很多。另如果需要分组统计,要先group by,较繁琐。
总结:把不容易改动表结构的设计成横表, 把容易经常改动不确定的表结构设计成纵表。
横表转纵表
把字段变内容
先创建横表
create table school_report (
student_name varchar(20),
chinese varchar(20),
math varchar(20),
english varchar(20)
);
INSERT INTO `school_report`(`student_name`, `chinese`, `math`, `english`) VALUES ('张三', '67', '78', NULL);
INSERT INTO `school_report`(`student_name`, `chinese`, `math`, `english`) VALUES ('李四', '90', NULL, '89');
横表转为纵表
select s.student_name,'chinese' as 科目,s.chinese as 成绩 from school_report s
union all
select s.student_name,'math' as 科目,s.math as 成绩 from school_report s
union all
select s.student_name,'english' as 科目,s.english as 成绩 from school_report s;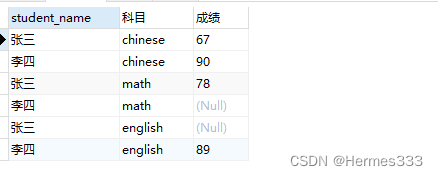
纵表转横表
把内容变字段
先创建纵表
create table proper(
student_name varchar(20),
course_name varchar(20),
score double
);
INSERT INTO `proper`(`student_name`, `course_name`, `score`) VALUES ('张三', '语文', 67);
INSERT INTO `proper`(`student_name`, `course_name`, `score`) VALUES ('张三', '数学', 78);
INSERT INTO `proper`(`student_name`, `course_name`, `score`) VALUES ('李四', '语文', 90);
INSERT INTO `proper`(`student_name`, `course_name`, `score`) VALUES ('李四', '英语', 89);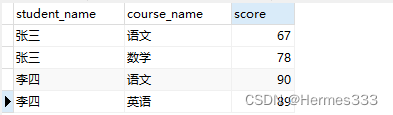
纵表转为横表
select
-- 第一列显示的字段
p.student_name,
-- 当course_name的名字是‘语文’,把对应的成绩显示 sum (case 键 when 字段值 then 字段值关系字段 end)
sum(case p.course_name when '语文' then p.score end ) as 语文,
sum(case p.course_name when '数学' then p.score end ) as 数学,
sum(case p.course_name when '英语' then p.score end ) as 英语
from proper p
-- 对名字进行分组
group by p.student_name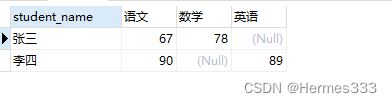
数据库备份
把数据库里面的内容进行备份放到硬盘或者其他位置。如果数据库出现问题之后,可以进行数据的恢复
备份数据库 在命令行中 mysqldump -u 用户名 -p 数据库名 > 文件名.sql
-- 进行数据库备份,注:备份命令最后不能加分号 结束
mysqldump -u root -p abc > D://abc.sql恢复数据库
需要查看备份的sql脚本中没有创建数据库的sql,如果没有该sql,只有表相关的sql,则数据库必须提前存在
第一种恢复: -- 继续用windows窗口 mysql -u root -p 数据库名 < D://数据库名.sql -- 示例 -- 创建一个数据库 create database abc; -- 切换数据库 use abc; -- 进行恢复 注意事项:恢复命令不能以 分号结尾 mysql -u root -p abc < D://abc.sql 第二种恢复: -- 创建一个数据库 create database abc; -- 切换数据库 use abc; -- 进行恢复 注意事项:恢复命令不能以分号结尾 source D://abc.sql -- 查看当前使用的数据库 select database(); -- 查看当前数据库下的所有表 show tables;
记录最后修改时间
添加字段 lasttime 使用timestamp 类型 选择 is not null
悲观锁与乐观锁
如果并发量大,冲突几率高,使用悲观锁,否则使用乐观锁
悲观锁
总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,当前线程用完后再把资源转让给其它线程。
乐观锁
总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(具体方法可以使用版本号机制或 CAS 算法)。
悲观锁施加
-- 悲观锁施加
在数据查询的时候,加上 for update。 -- + where条件就是行级锁 不+就是表级锁
具体步骤:
1.开启事务
begin; / begin work; / start transaction; (三者选一即可)
2.查询某表数据(id为主键)
select * from 表名 where id = 1 for update;
3.修改表数据
update 表名 set 表字段 = xxx;
4.提交事务
commit; / commit work; (二选一即可)关于for update的注意事项:
如果不开启事务,for update是不会锁任何东西的。
开启事务后,where条件字段是索引字段的话,该锁为行锁,如果不是索引字段,则为表锁。
for update 是写锁,该操作不会影响读操作。
两个常见问题
mysql使用事务前,需要关闭自动提交(set autocommit=0;)吗?
不需要。mysql 使用事务功能是不需要手动关闭自动提交的,只要 start transaction 开启了事务,自动提交就会被自动关闭,然后在使用 commit 之后,又会被重新打开。
for update 会锁住读操作?
正常的读操作是不会受到影响。当执行 select * from 表名 where id=1 for update; 后,在另外的事务中如果再次执行select * from 表名 where id=1 for update; 则第二个事务会一直等待第一个事务的提交,此时第二个查询处于阻塞的状态。如果 是在第二个事务中执行select * from 表名 where id=1;则能正常查询出数据,不会受第一个事务的影响。
mysql引擎
Innodb引擎
事务:逻辑上一组操作,要么同时成功,要么同时失败
InnoDB是MySQL5.5.x开始默认的事务型引擎,也是使用最广泛的存储引擎。被设计用来处理大量短期事务的。 InnoDB所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),表的大小只受限于操作系统文件的大小。表的结构定义存在.frm后缀文件中,数据和索引集中存放在.idb后缀文件中。因为表数据和索引是在同一个文件,InnoDB的索引是聚簇索引。 InnoDB采用MVCC支持高并发,并且实现了四种标准的隔离级别(读未提交,读已提交,可重复读,可串行化),其默认级别是REPEATABLE-READ(可重复读),并且通过间隙锁(next-key locking)策略防止幻读的出现。间隙锁不仅仅锁定查询涉及的行,还会对索引中的间隙行进行锁定,以防止幻影行的插入。 InnoDB表是基于聚簇索引建立的,聚簇索引对主键的查询有很高的性能。但是InnoDB的非主键索引中必须包含主键列,所以如果主键列很大的话,非主键索引也会很大。如果一张表的索引较多,主键应该尽可能的小。关于索引,后面会详细讲解。 InnoDB的内部优化,包括磁盘预读(从磁盘读取数据时采用可预测性读取),自适应哈希(自动在内存中创建hash索引以加速读操作)以及能够加速插入操作的插入缓冲区。
MyIASM引擎
在MySQL5.1及之前的版本,MyISAM是默认的存储引擎。提供了大量的特性,包括全文索引,压缩,空间函数等,但是不支持事务和行级锁,而且有一个严重的问题是奔溃后无法安全恢复。 MyISAM的数据表存储在磁盘上是3个文件,表结构定义存在.frm后缀文件中,表数据存储在.MYD后缀文件中,表索引存储在.MYI后缀文件中。表数据和表索引在不同的文件中,所以MyISAM索引是非聚簇索引。而且MyISAM可以存储表数据的总行数。 MyISAM表支持数据压缩,对于表创建后并导入数据以后,不需要修改操作,可以采用MyISAM压缩表。压缩命令:myisampack,压缩表可以极大的减少磁盘空间占用,因此也可以减少磁盘I/O,提高查询性能。而且压缩表中的数据是单行压缩,所以单行读取是不需要解压整个表。
二者区别
1. InnoDB 支持事务,MyISAM 不支持,对于 InnoDB 每一条 SQL 语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条 SQL 语言放在begin 和 commit 之间,组成一个事务; 2. InnoDB 是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。 MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。 3. InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而 MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快; 4. Innodb 不支持全文索引,而 MyISAM 支持全文索引,查询效率上 MyISAM要高;
主要的区别:
1、MyIASM是非事务安全的,而InnoDB是事务安全的 2、MyIASM仅支持表级锁,而InnoDB支持行级锁 3. MyISAM 不支持外键,而InnoDB 支持外键 4、MyIASM支持全文类型索引,而InnoDB不支持全文索引 5、MyIASM相对简单,效率上要优于InnoDB,小型应用可以考虑使用MyIASM 6、MyIASM表保存成文件形式,跨平台使用更加方便
主要选择:
1、如果需要支持事务,选择InnoDB,不需要事务则选择MyISAM。 2、如果大部分表操作都是查询,选择MyISAM,如果读写频繁选InnoDB。 3、如果系统崩溃导致数据难以恢复,MyISAM 恢复起来更困难,且成本高。 4.如果不知道用什么,那就用 InnoDB (MySQL5.5 版本开始 Innodb 已经成为 Mysql 的默认引擎(之前是MyISAM),说明其优势是有目共睹的)















 3657
3657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









