







从url输入到页面展示的过程
小白第一次发布文章,我就发最近写的一个常考面试题吧
当我们在web浏览器的地址栏中输入: www.baidu.com,然后回车,到底发生了什么
过程概览
- 对www.baidu.com这个网址进行DNS域名解析,得到对应IP地址
- 根据这个IP,找到对应的服务器,发起TCP的三次握手
- 建立TCP连接之后发送HTTP协议
- 服务器响应HTML代码,浏览器得到HTML代码
- 浏览器解析html代码,并且将请求HTML代码的资源(如js、png等)(先得到html代码,才能找到这些资源)
- 浏览器对页面进行渲染呈现给用户
- 断开连接:TCP四次挥手
PS:
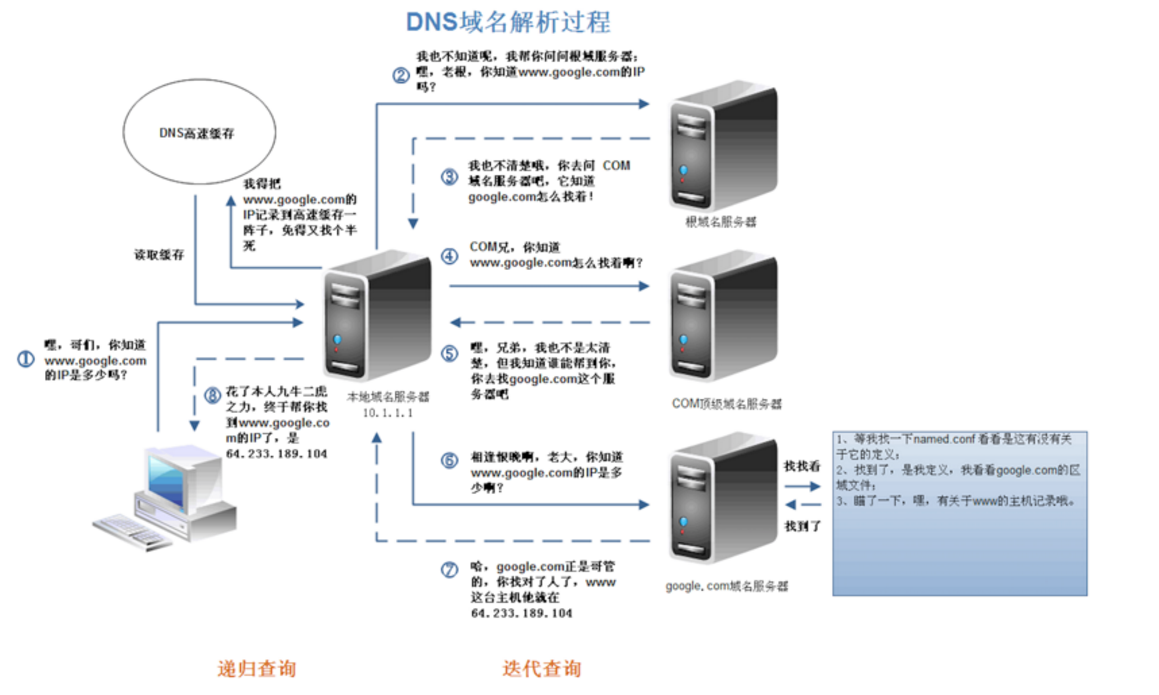
- DNS域名解析采用的是 ***递归查询***的方式,过程是,先去本机DNS缓存(host文件)-》找不到就去根域名服务器找-》下一级-》下一级-》…-》直到找到,找到了就返回web浏览器
- 为什么HTTP协议要基于TCP实现?TCP是一个端到端的可靠的面向连接的协议,HTTP基于传输层TCP协议不用担心数据传输的各种问题(当发生错误时,会重传)
- 最后一步浏览器是如何对页面进行渲染的?
- 解析html文件构成DOM树
- 解析css文件构成渲染树
- 边解析,变渲染
- JS单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载都是没必要的,所以JS是单线程,会阻塞后续资源下载
域名解析
在浏览器输入网址之后,首先要解析域名,因为浏览器并不能直接通过域名找到对应的服务器,而是要通过IP地址,那就有一个问题 — 计算机既然可以被赋予IP地址,也可以赋予主机名和域名。那为什么不一开始赋予个IP地址?这样就可以省去解析的麻烦。(因为IP地址很难记住)
IP地址
IP地址是指互联网协议地址,是IP Address的缩写。IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机 分配一个逻辑地址,***以此来屏蔽物理地址的差异,***IP地址是一个32位的二进制数,比如127.0.0.1为本机IP。
***域名就相等于IP地址的乔装打扮的伪装者,带着一副面具。它的作用就是便于记忆和沟通一组服务器的地址。***以此域名比IP地址更好记,因此DNS服务器应运而生。
什么域名解析
DNS协议提供域名查找IP地址,或逆向从IP地址反查域名的访问。 *DNS是一个网络服务器,我们的域名解析简单来说就是在DNS上记录一条信息记录。
例如 baidu.com 220.114.23.56(服务器外网IP地址)80(服务器端口号)
浏览器如何通过域名来查询URL对应IP呢
- 浏览器缓存:浏览器会按照一定的频率缓存DNS记录
- 操作系统缓存:如果浏览器缓存找不到需要的DNS记录,那就去操作系统找
- 路由缓存:路由器也有DNS缓存。
- ISP的DNS服务器:ISP是互联网服务提供商的建成,ISP有专门的DNS服务器对应DNS查询请求。
- 根服务器:ISP的DNS服务器还找不到的话,它就会向根域名发去请求,进行递归查询(DNS服务器先问域名服务器.com域名服务器的IP地址,然后再问.baidu域名服务器,以此类推)
小结
浏览器通过向DNS服务器发送域名,DNS服务器查询到与域名对应的IP地址,然后返回给浏览器,浏览器再将IP地址打在协议上,同时请求参数也会在协议搭载,然后一并发送给对应的服务器。接下来介绍向服务器发送HTTP请求阶段,HTTP请求分为三个部分:HTTP三次握手、http请求响应信息、关闭TCP连接。
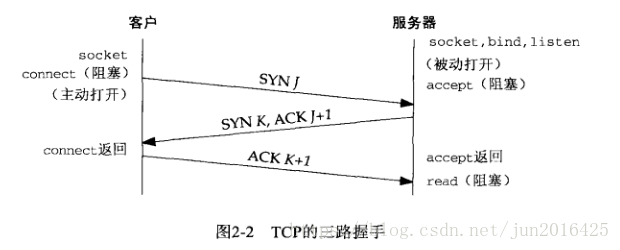
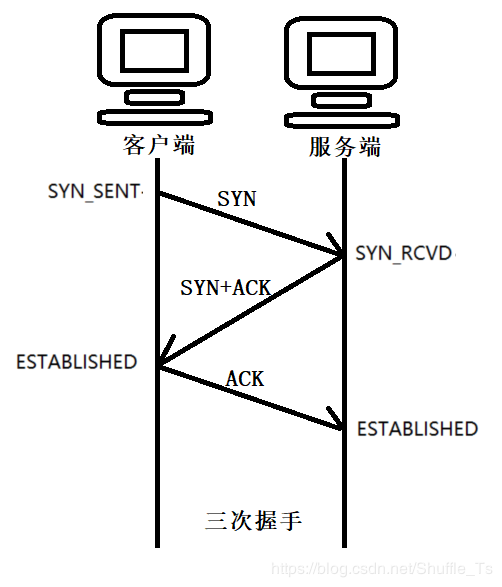
TCP三次握手(面试高频)
在客户端发送数据之前会发送TCP三次握手以同步客户端和服务端的序列号和确认号,并交换TCP窗口大小信息。
流程图如下:
为什么要三次握手
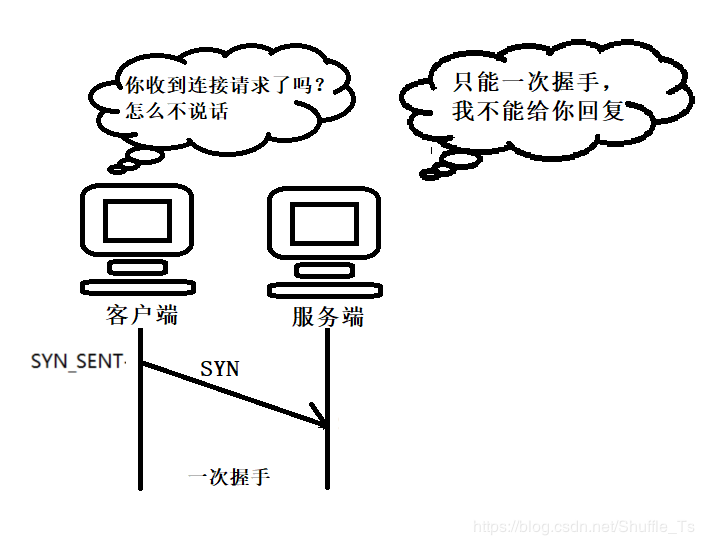
- 一次握手情况
由于TCP是面向连接的,一次很明显时不可能的,因为客户端发出连接消息后,却没有接收到来自服务端的回应,客户端就无法确定服务端接是否收到了连接请求,当然也就不能确定是否连接成功。
- 两次握手情况
如果客户端想建立连接,给服务器发送了一个连接请求(SYN),但是由于网络中种种情况,导致没有及时到达服务器,这就导致客户端在很长一段时间中没有收到回复消息(ACK),这时客户端又给服务端发送一个SYN,这次发送和接受很顺利,很快就收到了ACK,但是这时之前的SYN终于到了服务端,服务端规规矩矩的为这个SYN申请资源,然后返回ACK。由于之前的SYN已经失效了,所以客户端也不会去理会这个ACK,但是服务端不知道这个SYN已经失效了,一直为他委托着资源,这就造成了资源的浪费。
三次握手的情况:
一发一收的两次握手既然不行,那么三次握手就可以了吗?
- 在两次握手中服务端不知道当前这个SYN是不是有效的,三次握手就很好的解决了这个问题
- 第三次握手就是给服务端来回复第二次握手,这也就是说服务端会等第三次握手的到来,如果第三次握手迟迟不来,服务端就可以识别这个SYN是无效的,就会将他的资源释放了。
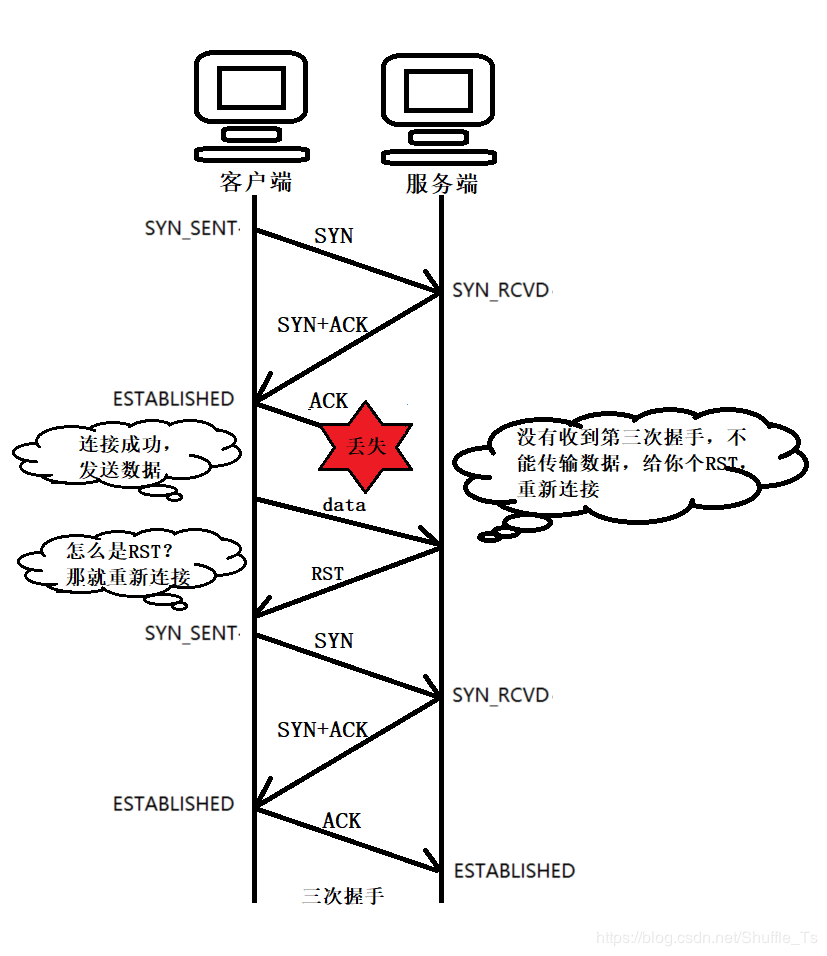
- 还有一种情况就是第三次握手由于网络中的种种原因失败了,这时候客户端认为自己已经连接好了,就会给服务端发送数据,***服务端由于没有收到第三次握手,***就会以RST包对客户端响应,收到RST的客户端就知道第三次握手没有成功,就会重新链接,在谢希尔著《计算机网络》第四部中将“三次握手”的目的是 为了防止已失效的连接请求报文突然又传送到了服务端,因而产生错误。
小结:
四次握手和两次握手的情况一样,五次握手和三次握手的情况一样,以此类推,奇数次握手的情况与三次握手相同,同理偶数次握手与两次握手一样,所以为了更快的连接,就使用三次握手最合适。
每次握手失败对应的措施:
第一次握手失败:
如果第一次的SYN传输失败,两段都不会申请资源。如果一段时间后之前的SYN发送成功了,这时客户端只会接受他最后的SYN的SYN+ACK回应,其他的一概忽略,服务端也是如此,会将之前多申请的资源释放了。
第二次握手失败:
如果服务端发送的SYN+ACK传输失败,客户端由于没有收到这条响应,不会申请资源,虽然服务端申请了资源,但是迟迟收不到来自客户端的ACK,也会将该资源释放。
第三次握手失败:
如果第三次握手的ACK传输事变,导致服务端迟迟没有收到ACK,就会释放资源,这时候客户端认为自己已经连接好了,就会给服务端发送数据,服务端由于没有收到第三次握手,就会以RST包对客户端响应。但是实际上服务端会因为没有收到客户端的ACK多次发送SYN+ACK,次数是可以设置的,如果最后还是没有收到客户端的ACK,则释放资源。
三次握手过程详解
TCP数据包结构
首先让我们来看一下TCP数据包的结构图

其中:
- 数据序号SEQ 32位,TCP为发送的每一个字节都编一个号码,这里存储当前数据包数据第一个字节的序号,如果将字节流看作在两个应用程序间的单向流动,则TCP用顺序号对每个字节进行计数。序号是32bit的无符号数,序号达到2^32-1后又从0开始。在建立一个新的连接时,SYN标志变为1,顺序号字段包含由这个主机选择的该连接的初始顺序号ISN.
- 确认号 ACK( 32 位), 包含发送确认的一端所期望收到的下一个顺序号。因此,确认序号应当是上次已成功收到数据字节顺序号加 1 。只有 ACK 标志为 1 时确认序号字段才有效。 TCP 为应用层提供全双工服务,这意味数据能在两个方向上独立地进行传输。因此,连接的每一端必须保持每个方向上的传输数据顺序号。
- TCP 报头长度( 4 位):给出报头中 32bit 字的数目,它实际上指明数据从哪里开始。需要这个值是因为任选字段的长度是可变的。这个字段占4bit ,因此 TCP 最多有 60 字节的首部。然而,没有任选字段,正常的长度是 20 字节
- 窗口大小( 16 位):数据字节数,表示从确认号开始,本报文的源方可以接收的字节数,即源方接收窗口大小。窗口大小是一个 16bit 字段,因而窗口大小最大为 65535字节
- SYN:同步序列编号(*Synchronize Sequence Numbers*)。是TCP/IP建立连接时使用的握手信号。在客户机和服务器之间建立正常的TCP网络连接时,客户机首先发出一个SYN消息,服务器使用SYN+ACK应答表示接收到了这个消息,最后客户机再以ACK消息响应。
我们介绍了大概的结构图,因此我们来讲解一下TCP三次握手的过程:
第一次握手
客户主动(active open)去connect服务器,并且SYN(同步序列编号)假设序列化为J,服务器是被动打开(passive open)
第二次握手
服务器在收到SYN后(同步序列编号),它会发送一个SYN以及一个ACK(确认号)给客户,ACK(确认号)的序列化是J+1表示是给SYN J的应答,新发送SYN(同步序列编号) K序列化为K
第三次握手
- 客户端在收到信SYN(同步序列化) K,ACK(确认码) J+1后,也回应ACK K+1以表示收到了。此包发送完毕,客户端和服务器进入TCP连接状态,完成三次握手。
- 完成三次握手之后,两边可以进行数据发送数据了。
HTTP请求
首先我们要明确,HTTP请求是怎么组成的?
HTTP请求组成结构
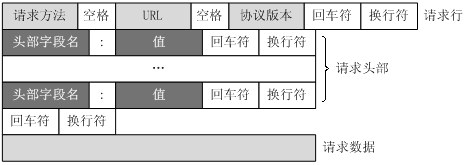
HTTP请求由四部分组成:请求行(request line)、请求头部(headers)、空行(blank line)和请求数据(request body)4个部分组成。
结构如下:
请求行
请求行由三个部分组成:
- 请求方法(GET/POST …)
- 请求地址URL(如/index.html)
- 协议版本
例如: GET /index.html HTTP/1.1
注意:它们之间都用空格分隔
资料:请求方法

url:

请求头部
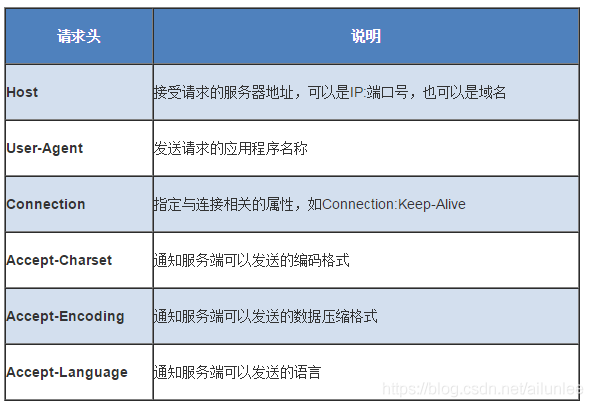
请求头部为请求报文添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
请求头部最后会有一个空行,表示请求头部结束,接下来为请求数据。
PS:
以键值对存在 但是要注意符号“:”后面有一个空格如 ***Host: localhost:8080 ***
请求数据
请求数据不在GET方法中使用,而在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的最长使用的请求头部是Cntent-Type和Content-Length。下面是一个POST方法的请求报文:例如
POST /index.php HTTP/1.1 请求行
Host: localhost
User-Agent: Mozilla/5.0 (
Windows NT 5.1; rv:10.0.2) Gecko/20100101 Firefox/10.0.2 请求头
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8
Accept-Language: zh-cn,zh;q=0.5
Accept-Encoding: gzip, deflate
Connection: keep-alive
Referer: http://localhost/
Content-Length:25
Content-Type:application/x-www-form-urlencoded
空行
username=aa&password=1234 请求数据
HTTP响应
结构图如下图所示

HTTP响应报文由
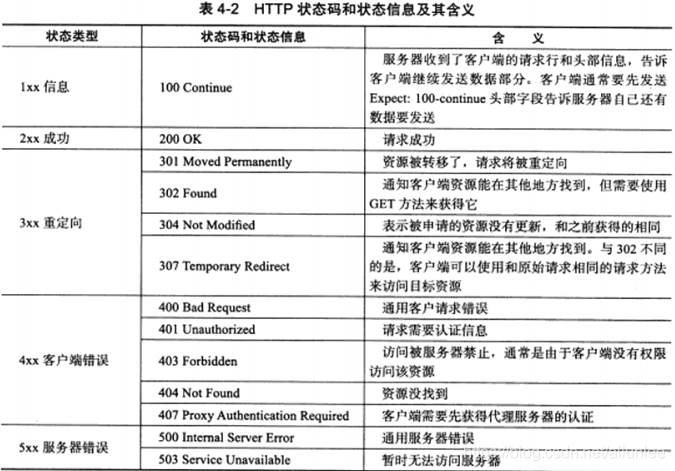
- 状态行(status line)
- 响应头部(headers)
- 空行(blank line)
- 响应数据
状态行
状态行由3部分组成,分别为:协议版本、状态码、状态码扫描。其中协议版本与请求报文一致,状态码描述是对状态码的简单描述。
响应头部
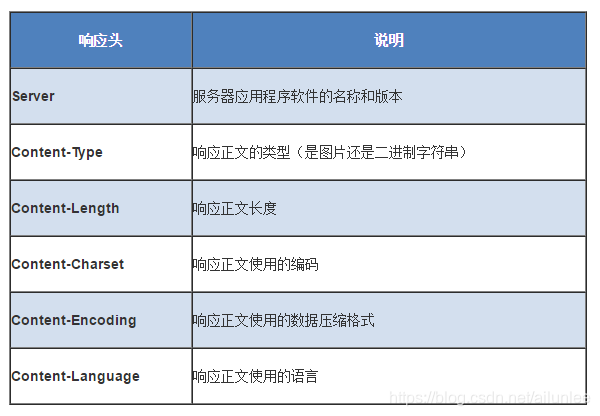
响应数据
用于存放需要返回给客户端的数据信息。
例子:
HTTP/1.1 200 OK 状态行
Date: Sun, 17 Mar 2013 08:12:54 GMT 响应头部
Server: Apache/2.2.8 (Win32) PHP/5.2.5
X-Powered-By: PHP/5.2.5
Set-Cookie: PHPSESSID=c0huq7pdkmm5gg6osoe3mgjmm3; path=/
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Content-Length: 4393
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Content-Type: text/html; charset=utf-8
空行
<html> 响应数据
<head>
<title>HTTP响应示例<title>
</head>
<body>
Hello HTTP!
</body>
</html>
浏览器解析HTML代码,并请求HTML代码中的资源
浏览器拿到html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这是时候就用上 ***keep-alive***特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里面的顺序,但是由于每个资源大小不一样,而浏览器又是多线程请求请求资源,所以这里显示的顺序并不一定是代码里面的顺序。
关闭TCP连接,浏览器对页面进行渲染呈现给用户
浏最后,浏览器利用自己内部的工作机制,把请求的静态资源和html代码进行渲染,渲染之后呈现给用户
浏览器是一个边解析边渲染的过程。首先浏览器解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
JS的解析是由浏览器中的JS解析引擎完成的。JS是单线程运行,JS有可能修改DOM结构,意味着JS执行完成前,后续所有资源的下载是没有必要的,所以JS是单线程,会阻塞后续资源下载
总结
域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









