






#语音识别的概念:
from aip import AipSpeech
# 你的APPID AK SK
APP_ID = '62579522'
API_KEY = 'NRhHWJTVZvV5LIH63EWWs85B'
SECRET_KEY = 'GLfLqgmHCeZ9j8ouYG65ppuzabtRv0im'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
Text = '你好,世界。'
filePath = "MyVoice.mp3 "
result = client.synthesis(Text, 'zh', 1, {'vol': 5})
print(result)
if not isinstance(result, dict):
with open(filePath, 'wb') as f: # 以写的方式打开MyVoice.mp3文件
f.write(result) # 将result内容写入MyVoice.mp3文件
else:
print("错误")
语音识别技术主要涉及到以下几个步骤:
- 信号处理:将原始的语音信号进行数字化和预处理,去除噪声和其他干扰因素。
- 特征提取:从处理后的信号中提取出代表语音信息的特征,如音高、音强、时长等。
- 声学模型:使用机器学习或深度学习技术建立模型,以识别出语音中的音素、单词或短语。
- 语言模型:根据语法规则和词汇库,确定最可能的词序列。
- 解码:结合声学模型和语言模型,将语音信号解码为文本。
语音识别技术在实际应用中具有广泛的应用领域,如:
- 智能助手:如苹果的Siri、谷歌助手等,用户可以通过语音与设备进行交互。
- 智能家居:通过语音控制智能家居设备,如灯光、空调等。
- 语音输入:在手机、电脑等设备上,用户可以通过语音输入文字,提高输入效率。
- 医疗领域:用于辅助医生诊断疾病,或帮助残障人士进行交流。
语音识别系统的基本构成
语音识别系统的模型通常由声学模型和语言模型两部分组成,分别对应于语音到音节概率的计算和音节到字概率的计算。一个连续语音识别系统大致可分为五个部分:预处理模块(信号处理)、声学特征提取、声学模型训练、语言模型训练和解码器,如下图所示:
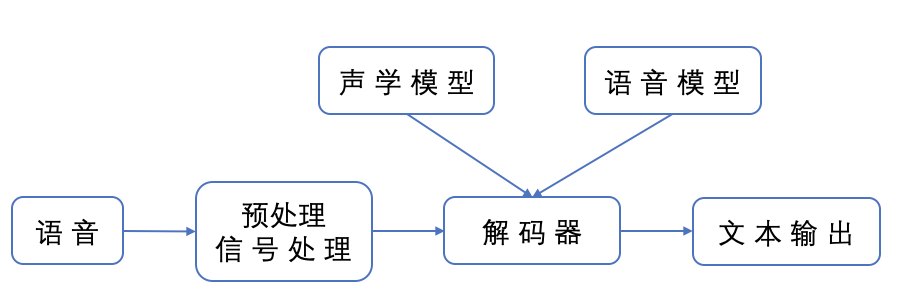
语言识别基本流程
一套完整的语音识别系统,工作过程分为 7 步:
- 对语音信号进行分析和处理,除去冗余信息;
- 提取影响语音识别的关键信息和表达语言含义的特征信息;
- 紧扣特征信息,用最小单元识别字词;
- 按照不同语言的各自语法,依照先后次序识别字词;
- 把前后意思当作辅助识别条件,有利于分析和识别;
- 按照语义分析,给关键信息划分段落,取出所识别出的字词并连接起来,同时根据语句意思调整句子构成;
- 结合语义,仔细分析上下文的相互联系,对当前正在处理的语句进行适当修正。
总结与扩展
语音识别算法一般有编码器和解码器两部分组成,其中编码器包括信号处理与特征提取模块,解码器包括声学模块、语言模型、搜索算法等 3 个模块,整体框架如下图所示:
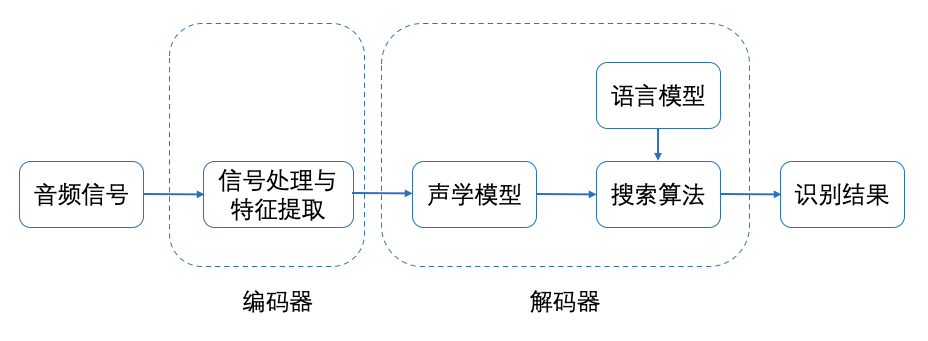
语音合成:
语音合成是通过机械的、电子的方法产生人造语音的技术。其中,TTS技术(又称文语转换技术)是语音合成的一个关键组成部分。它可以将计算机自己产生的或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出。
语音合成技术在实际应用中有非常广泛的用途。例如,在教育领域,大型教育机构使用语音合成技术替代人工视频,提高制作效率和质量;智能教学平台则将教师讲解与学生提问转为语音,实现智能辅导和自主学习。在娱乐领域,语音合成技术为在线阅读平台提供语音听书功能,同时为游戏厂商提供角色语音的生动表现。此外,语音合成还在医疗、商业、智能家居等多个领域得到广泛应用,如医疗咨询、订单播报、智能客服、资讯播报等。
真正实现“让机器像人一样开口说话”。
总的来说,语音合成的原理是通过文本分析确定发音信息,利用声学模型和语音库生成语音信号,并最终通过语音输出设备播放出来。这一过程使得计算机能够像人类一样进行语音交流,为人们提供了更加便捷和自然的交互方式。
案例实训:
(1)环境准备:安装Spyder等Python编程环境。
(2) SDK准备:安装百度AI开放平台的SDK。
(3)账号准备:注册百度AI开放平台的账号。
一:(baidu.com)https://ai.baidu.com/



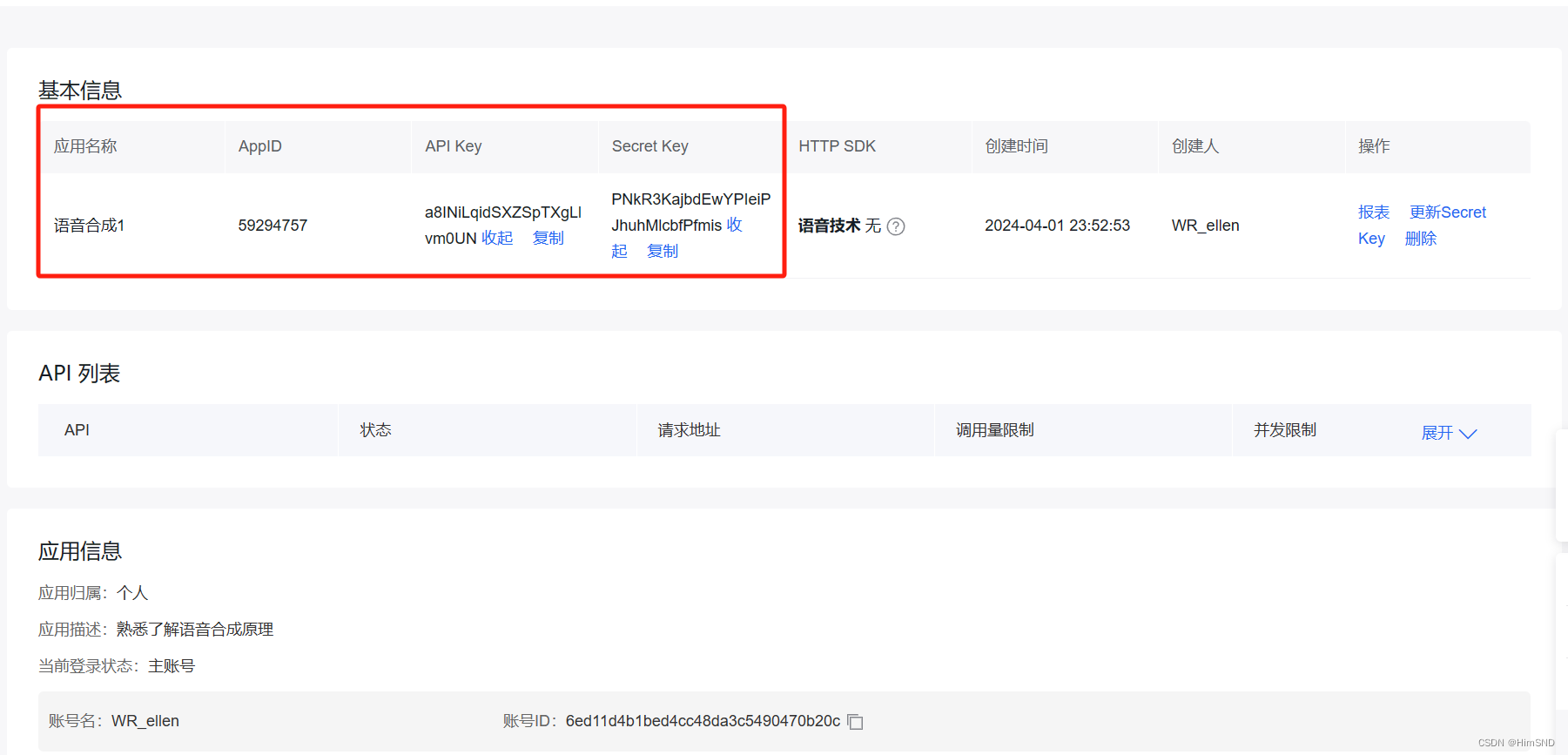
记录以上信息,APPID,APIKEY,SECRET KEY 在代码中修改为自己的KEY
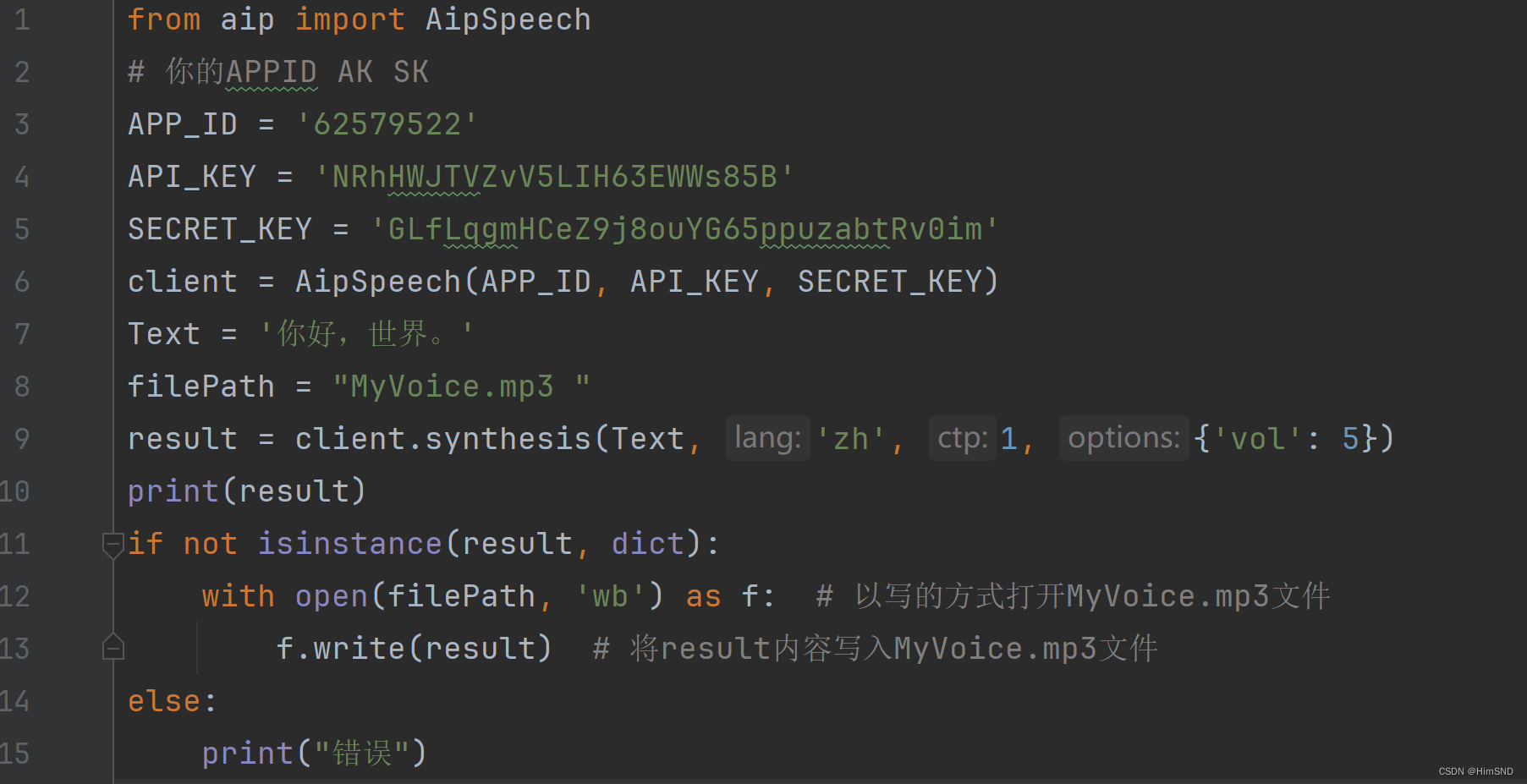
代码:
从AIP中导入相应的语音模块AipSpeech
from aip import AipSpeech
复制粘贴APPID、AK、SK这3个值并以此初始化对象
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









