






目录
一、Mysql体系结构:
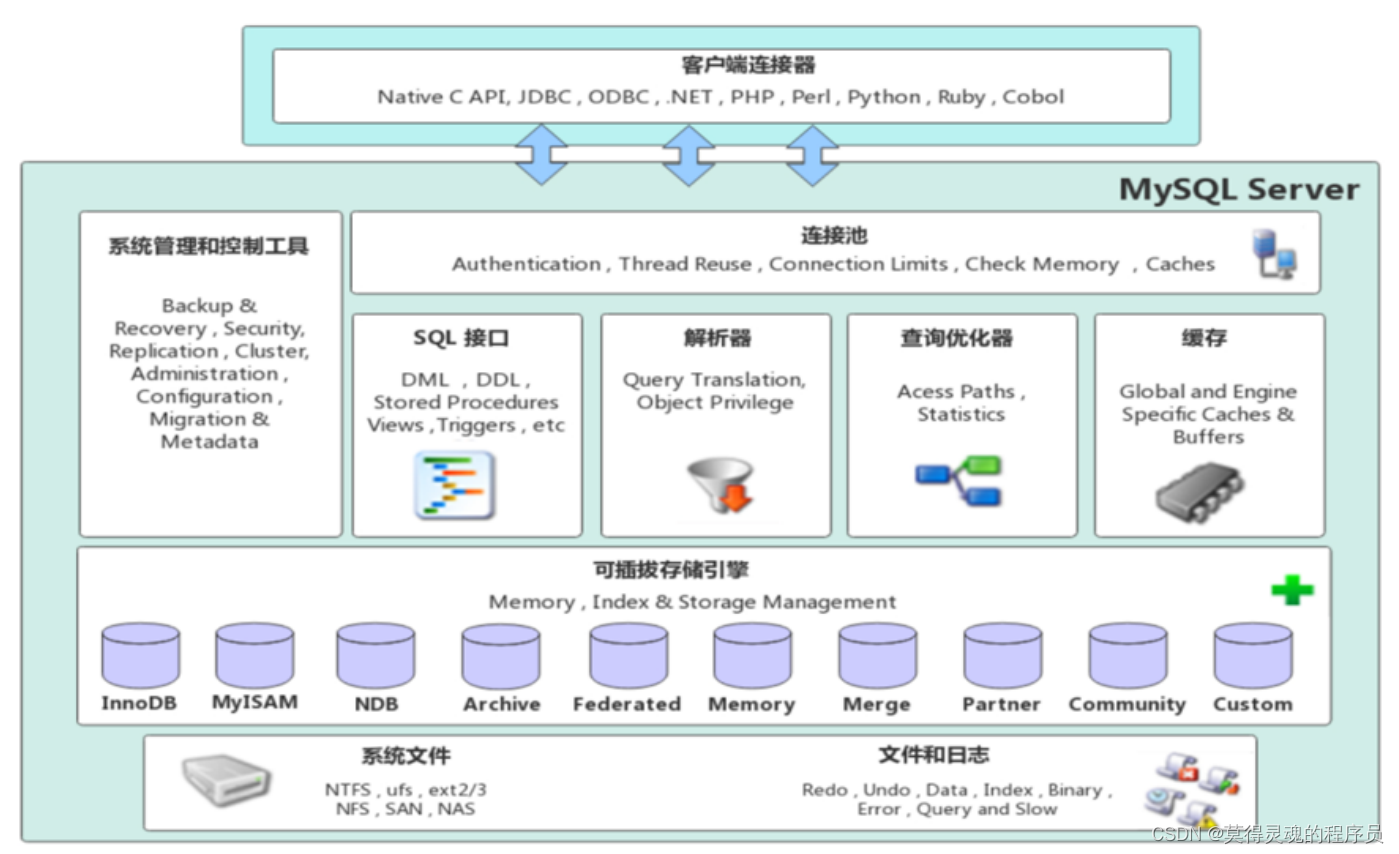
(1)连接层:
最上层是一些客户端和链接服务,包含本地sock通信和大多数基于客户端、服务端工具实现的类似于TCP/IP的通信。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以基于SSL安全链接。服务器会为安全接入的每个客户端验证他所具有的操作权限
(2)服务层:
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化,部 分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如 过程、函数等。在该层,服务器会解 析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利用索引等, 最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存,如果缓存空间足够大, 这样在解决大量读操作的环境中能够很好的提升系统的性能。
(3)引擎层:
存储引擎层, 存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进行通 信。不同的存储引擎具有不同的功能,这样我们可以根据自己的需要,来选取合适的存储引擎。数据库 中的索引是在存储引擎层实现的。
(4)存储层:
数据存储层, 主要是将数据(如: redolog、undolog、数据、索引、二进制日志、错误日志、查询 日志、慢查询日志等)存储在文件系统之上,并完成与存储引擎的交互。
二、存储引擎:
存储引擎:存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式 。存储引擎是基于表的,而不是 基于库的,所以存储引擎也可被称为表类型
查询建表语句: show create table 表名
1、InnoDB:
注意:mysql5.6以后InnoDB支持全文索引
(1)概念:
InnoDB是一种兼顾高可靠性与高性能的通用存储引擎,在Mysql5.5之后默认为InnoDB
(2)特点:
(1)DML遵循ACID模型,支持事务
(2)行级锁
(3)支持外键,保证数据的完整性与正确性
(3)表文件(ibd):
xxx.ibd:xxx代表的是表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结 构(frm-早期的 、sdi-新版的)、数据和索引。可以使用 ibd2sdi 命令提取sdi表结构信息进行查看
(4)逻辑存储结构:
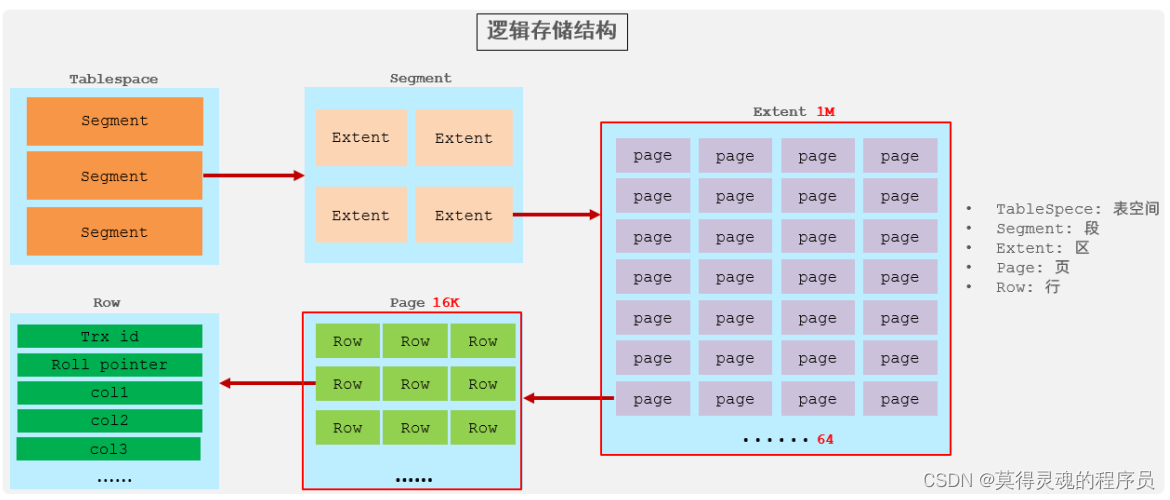
表空间 : InnoDB存储引擎逻辑结构的最高层,ibd文件其实就是表空间文件,在表空间中可以包含多个Segment段。
段 : 表空间是由各个段组成的, 常见的段有数据段、索引段、回滚段等。InnoDB中对于段的管理,都是引擎自身完成,不需要人为对其控制,一个段中包含多个区。
区 : 区是表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
页 : 页是组成区的最小单元,页也是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。
行 : InnoDB 存储引擎是面向行的,也就是说数据是按行进行存放的,在每一行中除了定义表时所指定的字段以外,还包含两个隐藏字段
2、MyISAM:
(1)概念:
不支持事务
不支持外键
支持表锁,不支持行锁
(2)文件:
xxx.sdi:存储表结构信息
xxx.MYD: 存储数据
xxx.MYI: 存储索引
3、Memory:
概念:Memory引擎的表数据存储在内存中,由于收到硬件或断电的影响,只能将这些表作为临时表或缓存使用
默认使用Hash索引
4、总结:
MyISAM可以被MongoDB代替、Memory可以被Redis代替
三、索引:
创建索引的语句:
create [unique、fulltext] index 索引名称 on 表名(字段名,字段名,...)
查询索引语句:
show index from 表名
删除索引:
drop index 索引名 on 表名
1、概念:
索引是帮助Mysql高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
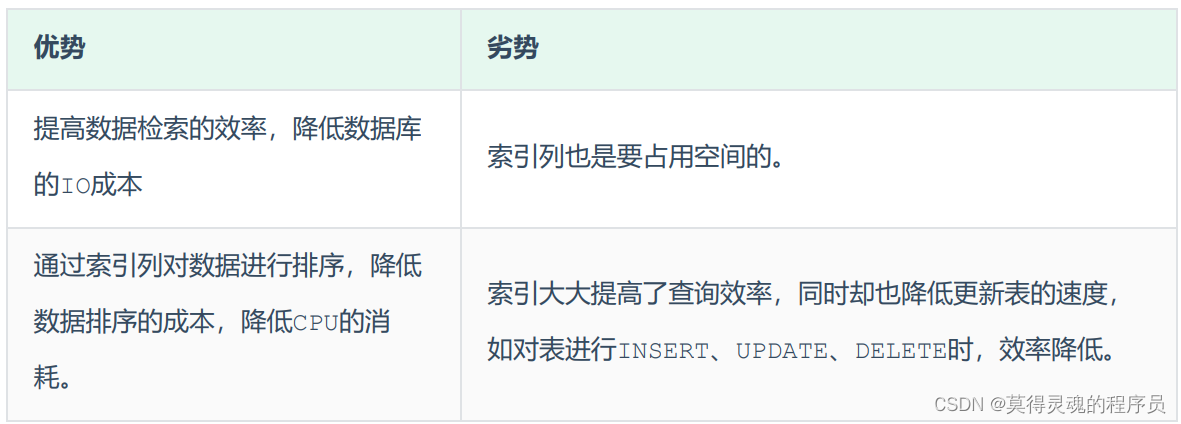
2、索引结构:
Mysql的索引是在引擎层实现的,因此不同的引擎会有不同的索引结构
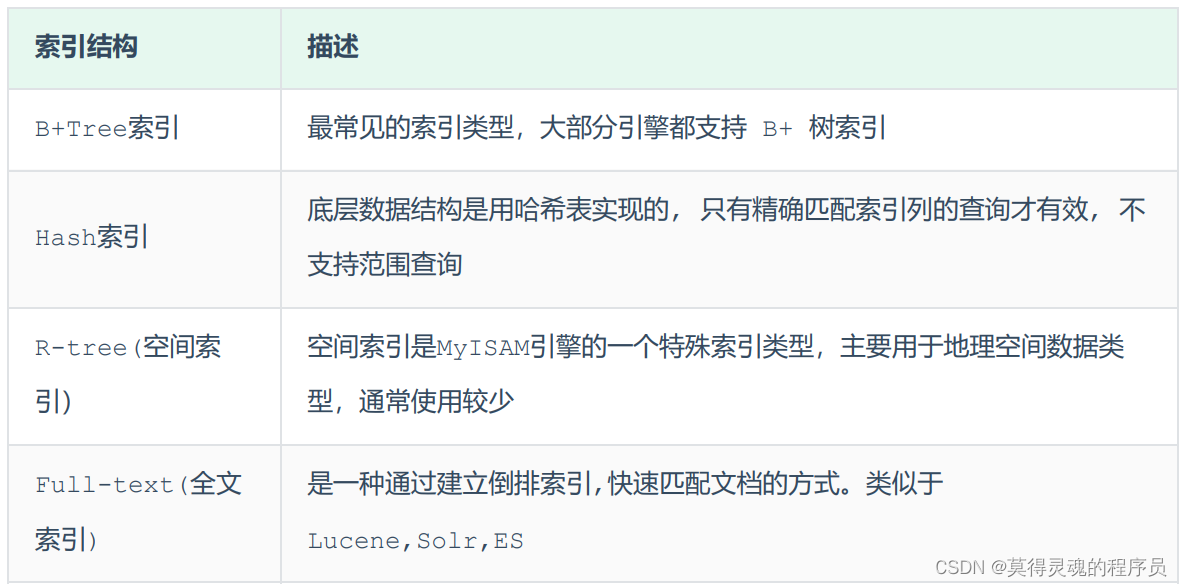
3、B+树:
红黑树的问题: 如果数据过大就会出现层级较深的情况,如果顺序插入又会出现树不平衡的情况
红黑树问题: 红黑树解决了树不平衡的情况,但是由于其本质还是二叉树,因此数据过大时会出现层级较深的情况
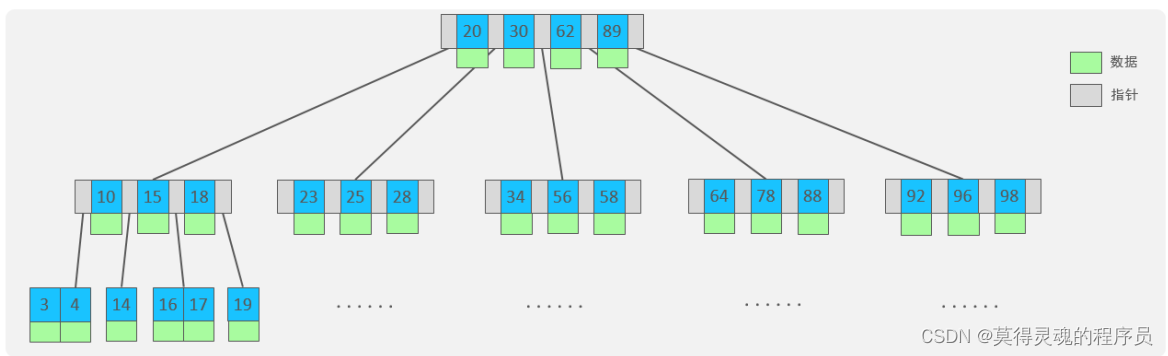
B树: B-Tree,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉
注意:该图为5阶B树,因此最多存储四个Key,五个指针
B+树:
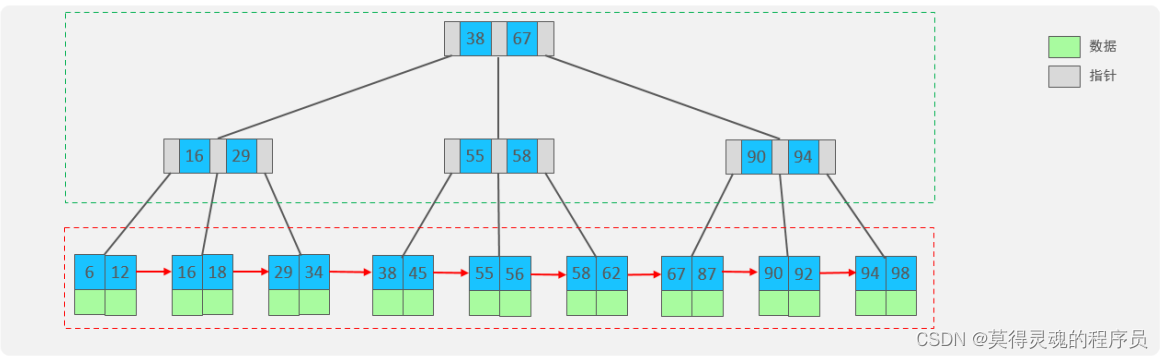
绿色框框起来的部分,是索引部分,仅仅起到了索引数据的作用,不存储数据
红色框框起来的部分,是数据存储部分,在其叶子结点中要存储具体的数据
4、B树与B+树的区别:
(1)B+树所有的数据都会出现字叶子结点
(2)叶子结点形成一个单向链表
(3)非叶子结点仅仅起到索引数据作用,具体的数据都是在叶子结点存放的
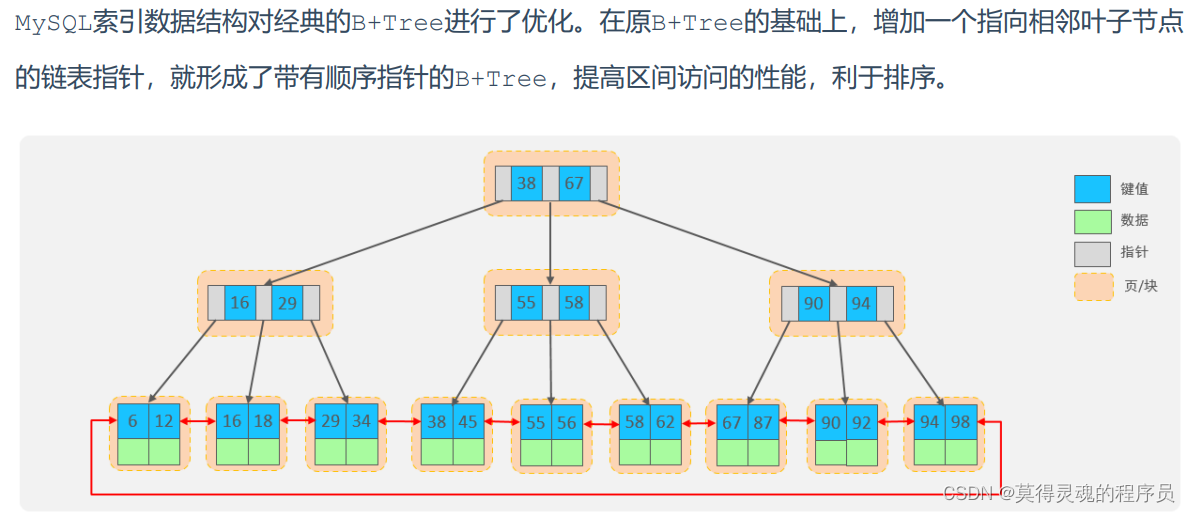
5、Mysql中对B树的优化:
6、Hash索引结构:
只支持精确匹配,不支持范围查询
不发生Hash冲突的情况下只需要检索一次
四、索引分类:
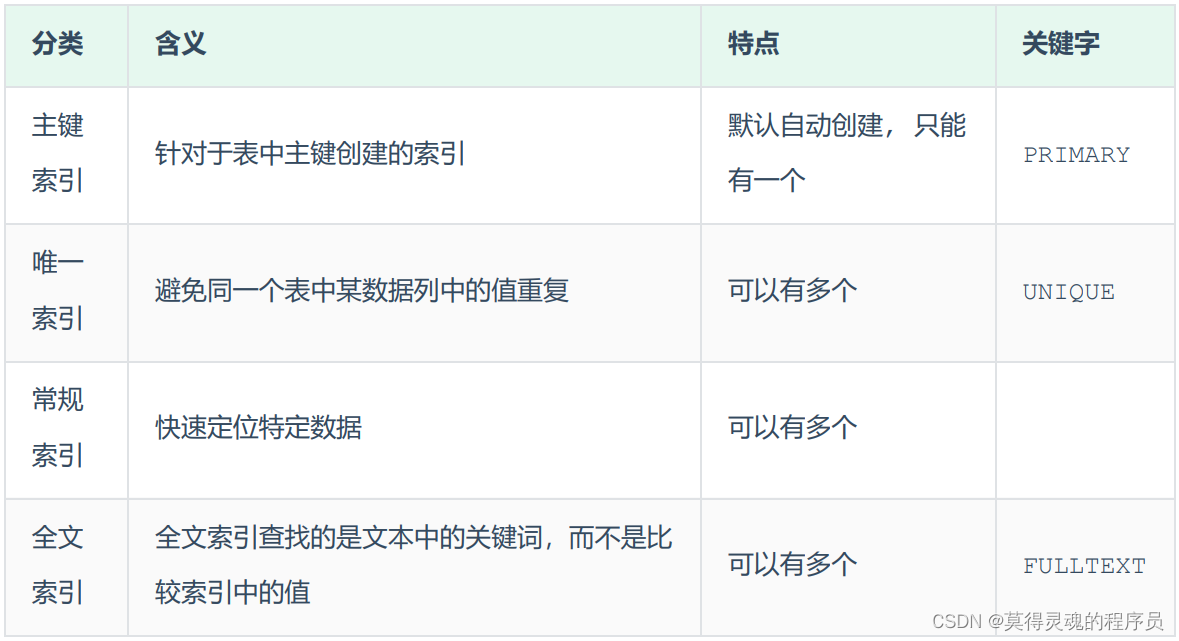
1、Mysql中索引分类:
2、InnoDB中索引分类:

(1)聚集索引选取规则:
如果存在主键,主键索引就是聚集索引。
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索 引。
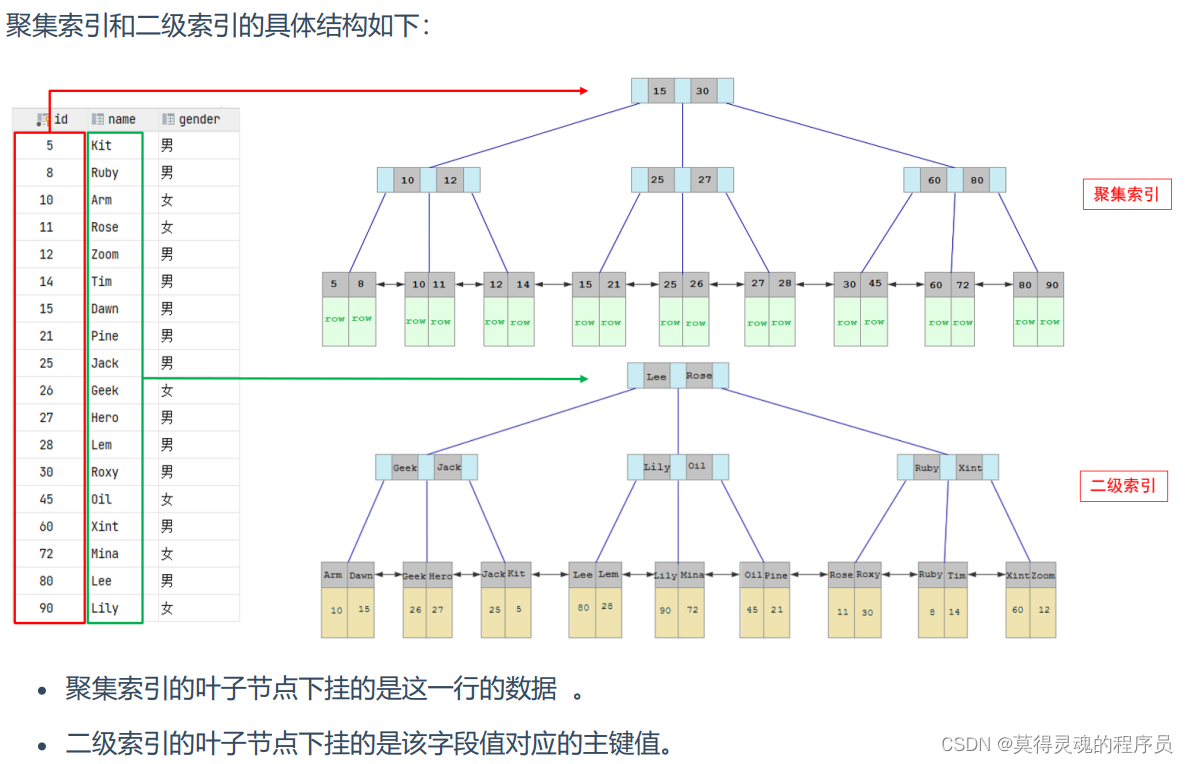
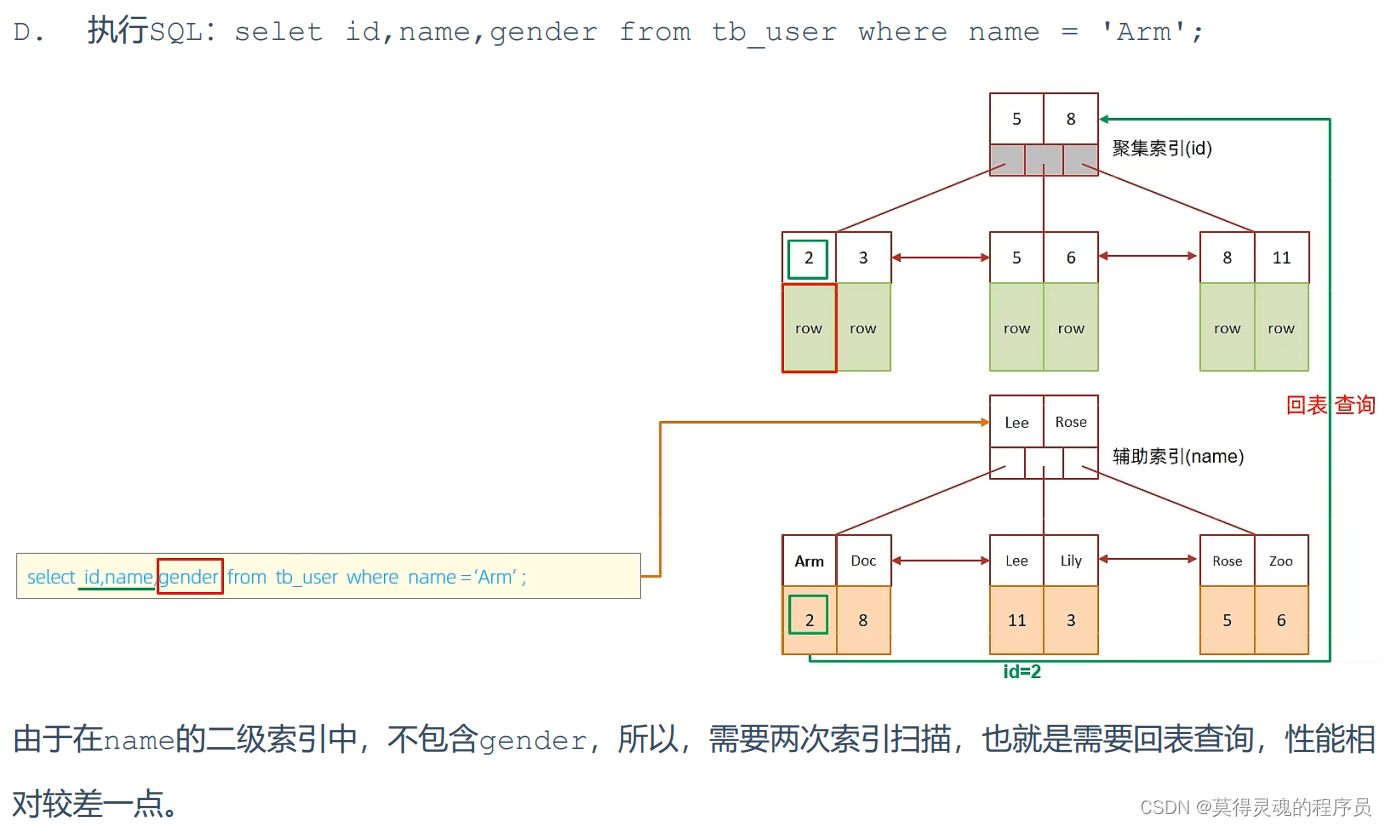
(2)回表查询:
先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取 数据的方式,就称之为回表查询















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









