







0. 缘起
前段实践接到一个做语料库的朋友的消息,说要帮忙找英文新闻数据,仗着自己会一丢丢丢丢丢丢爬虫,我欣然答应下来。然而,在爬取 The Washington Post 网站新闻网址时,我发现一个很奇怪的现象。
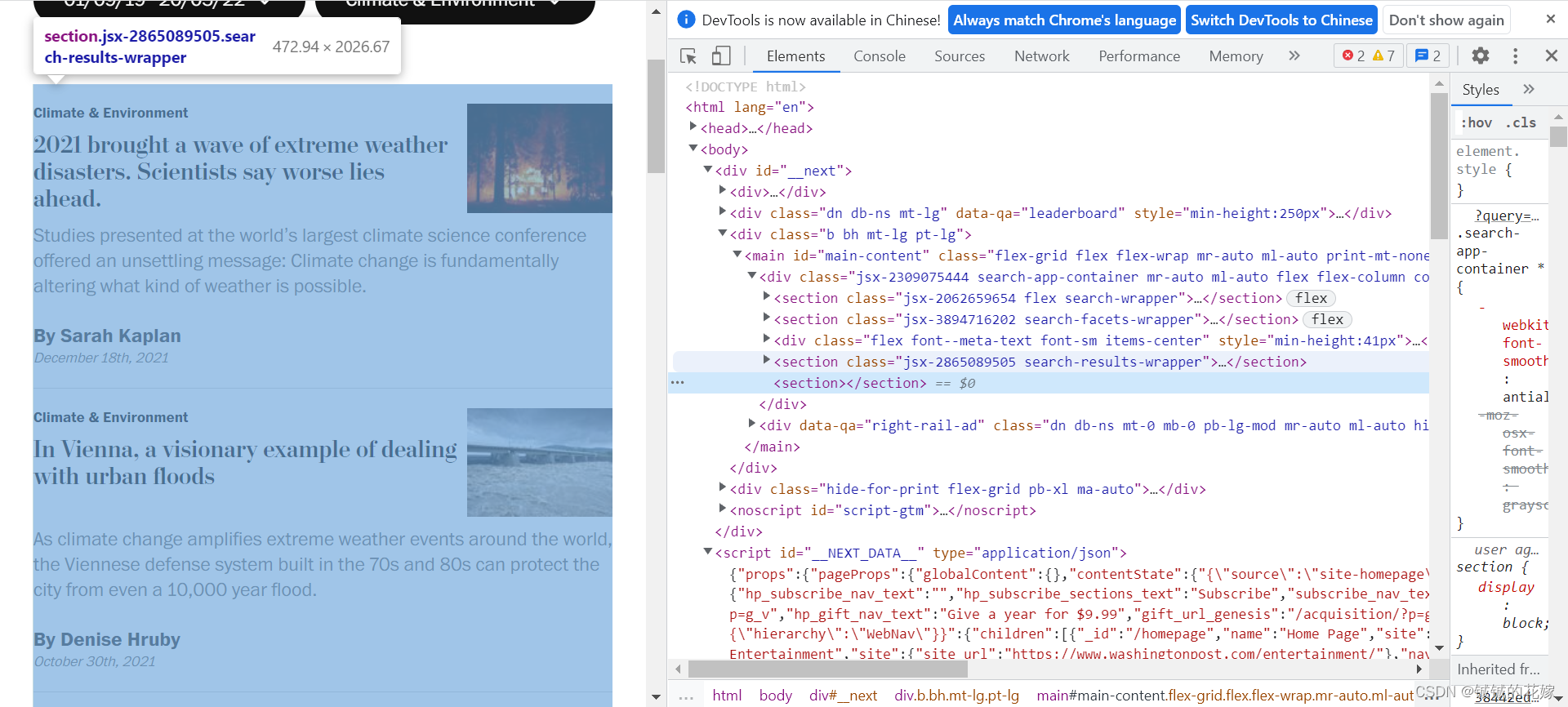
可以看到,我们要的信息就在 highlight 的 section 部分,然而我爬下来的源代码却是这样子的,跟F12里显示的信息有些出入。
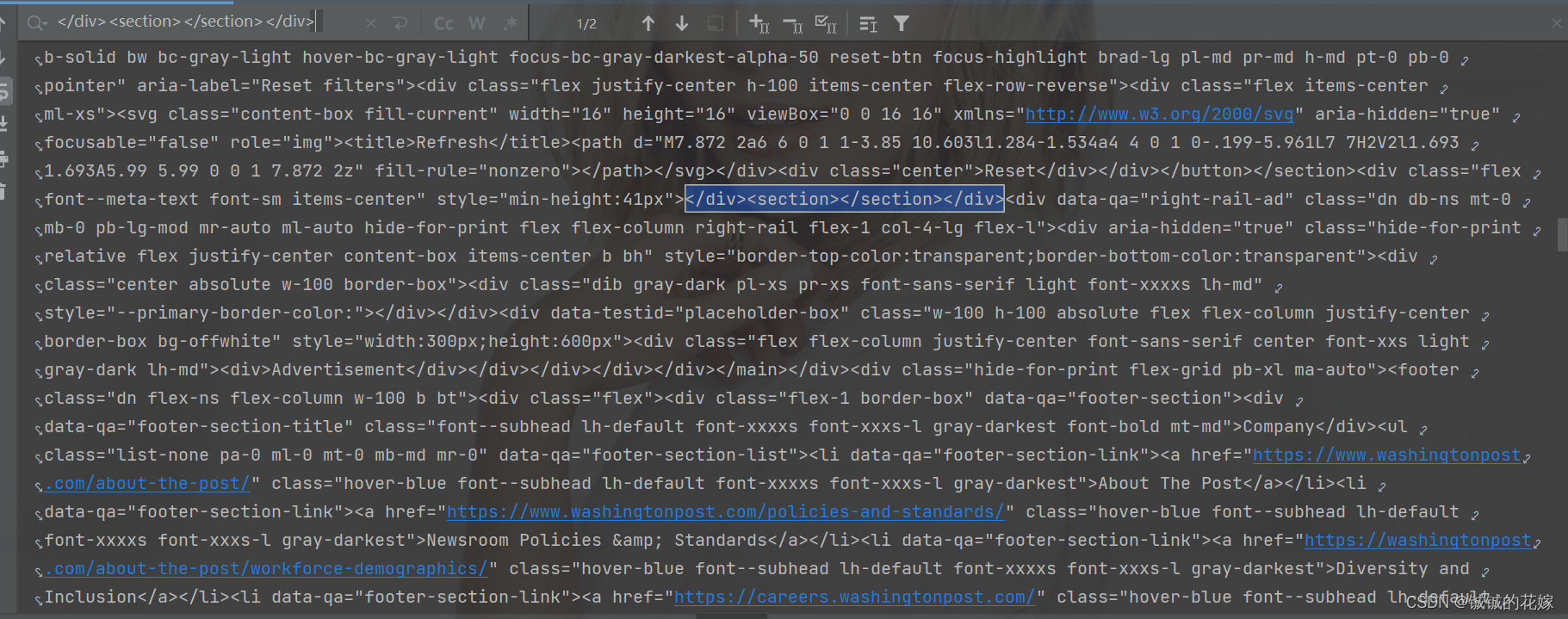
仔细一看表示人麻了,好巧不巧最重要的一块没了。
搜索资料后推测,大概率是因为这部分内容是由 js 渲染出来的,意思就是这部分代码是由 JavaScript 操控写出来的,不是由人直接编写 html 代码完成的,所以简单的 request 命令没有办法直接读出来,仅仅只能得到非渲染部分的源代码。既然有了方向,那我们就大胆尝试。
1. 分析网站
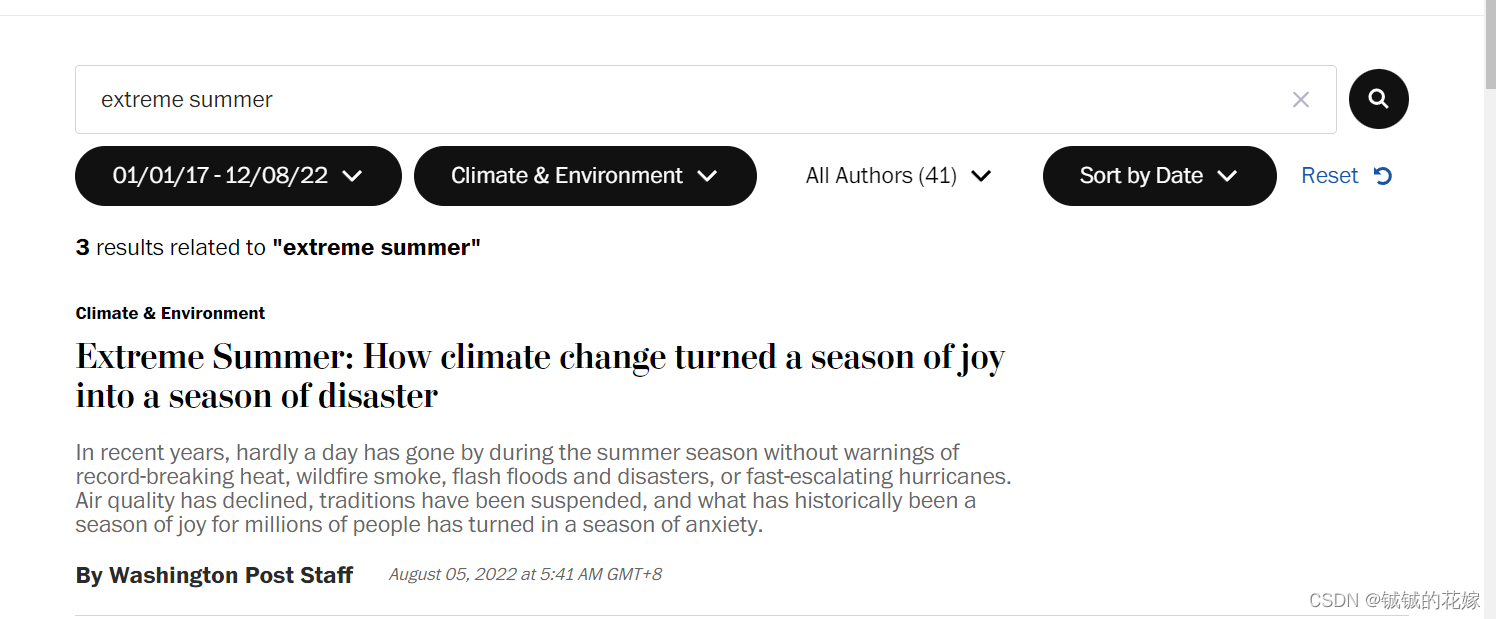
随便搜索一个关键词,我们发现这个网站为我们提供了多个搜索的选项,包括日期筛选,类别筛选,作者筛选,是否按照日期排序。对应的网址如下:
https://www.washingtonpost.com/search/?query=extreme+summer&btn-search=&facets=%7B%22time%22%3A%5B1483200000000%2C1660291242104%5D%2C%22sort%22%3A%22date%22%2C%22section%22%3A%5B%22Climate+%26+Environment%22%5D%2C%22author%22%3A%5B%5D%7D
一般来说,我们每次搜索改变的只有搜索的内容,检索的条件是不变的,这意味着,我们在多次发出请求的时候,只需要改变网址加粗部分就完事了,剩下的我们照搬。
我们先用Climate & Environment和deluge作为这次实验的关键词。日期等筛选条件暂时按照上图的来。先跑通整体流程,再考虑其他问题。
搜索并F12检查之后,我们发现这部分数据都以json格式存放在这个文件中:
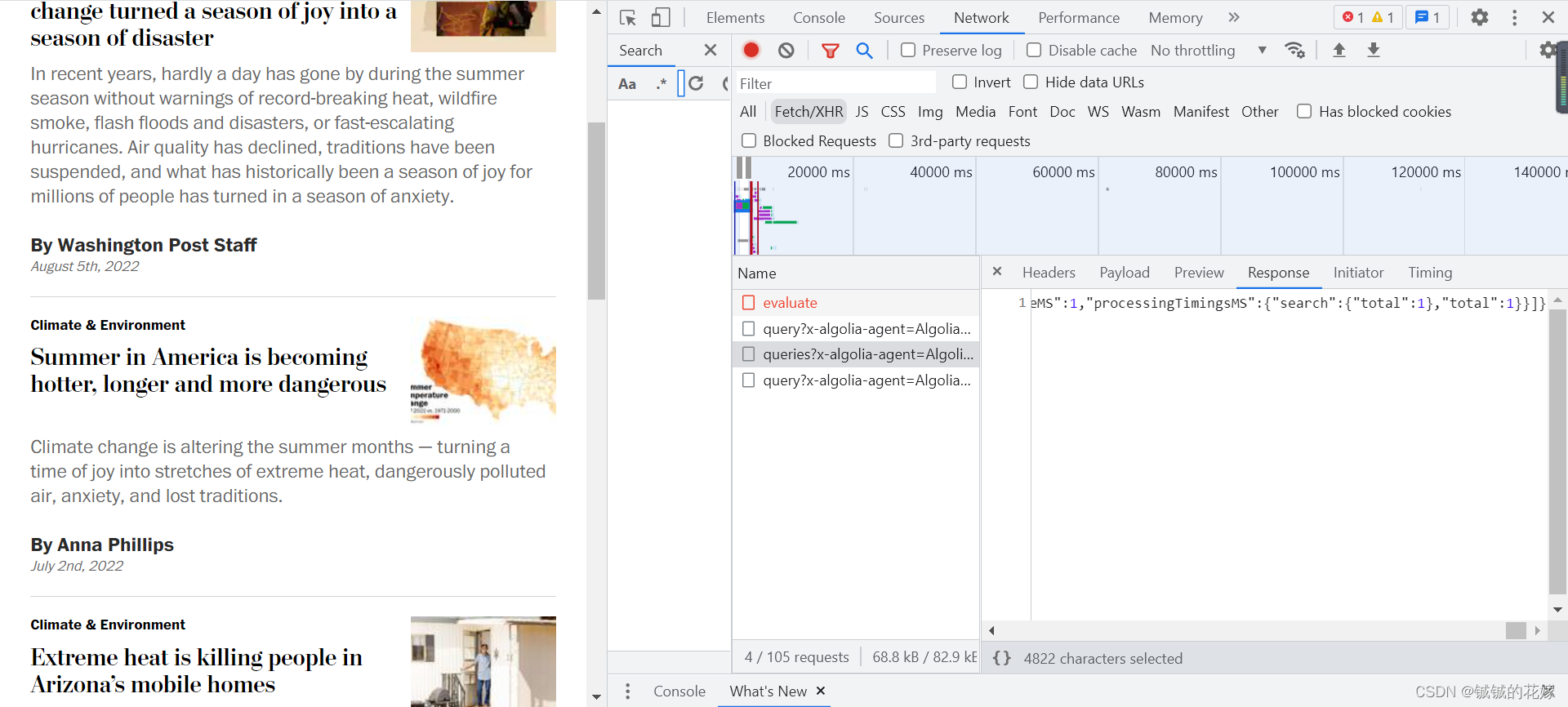
如果觉得直接看json格式的数据不方便,粘贴到网站中看,当然也可以直接在Preview里面查看。
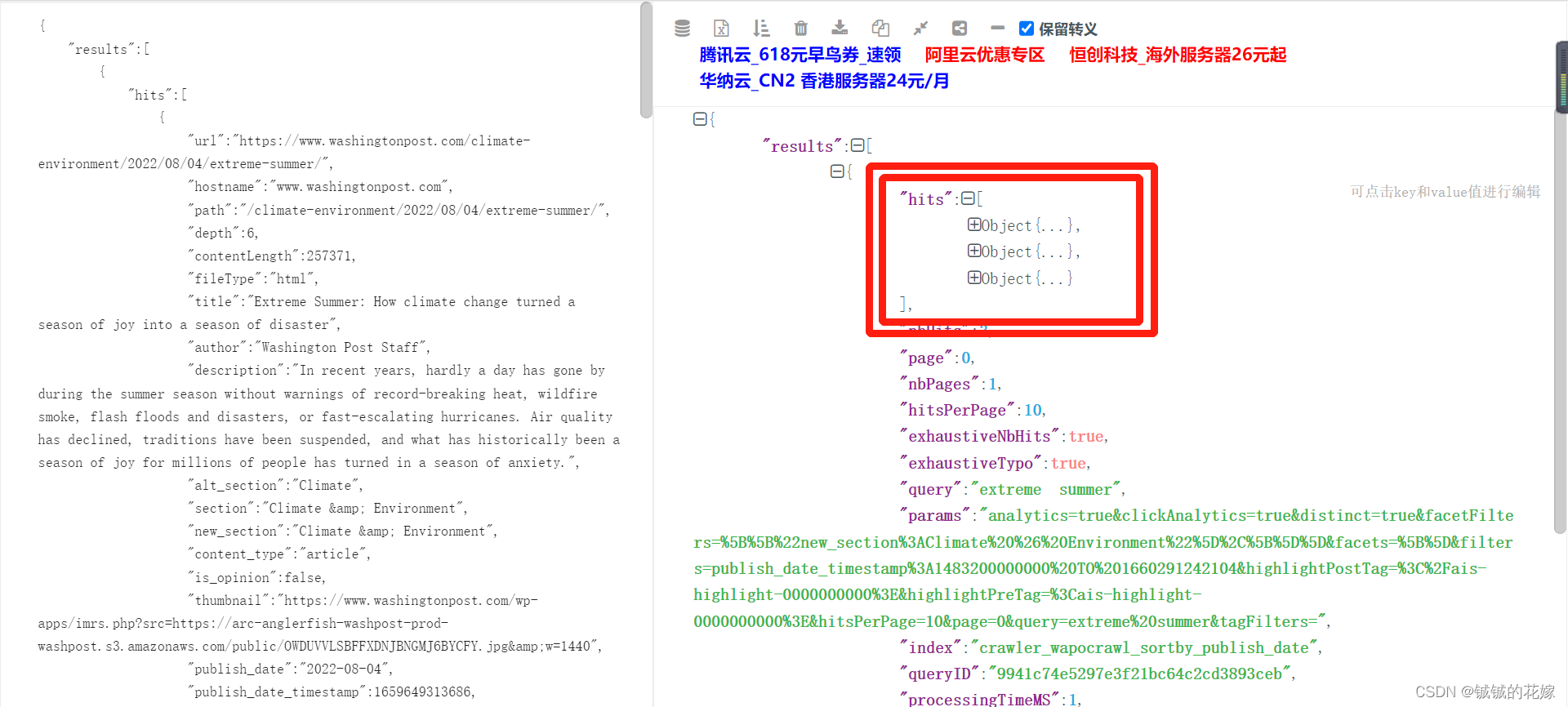
经过检查,这三个Object中就含有我们需要的信息。至此,我们完成了数据的定位。这意味着华盛顿邮报的网址本身对于我们来说意义并不大了,因为我们获取信息主要都依靠上图的Request URL。
这里要注意辨析我们的目标,我们发现这里有三个文件比较符合我们的要求。仔细辨析结果之后不难发现(数量和结果都对不上),queries那个文件是加了筛选条件后的结果,query是未加筛选条件的结果。
query
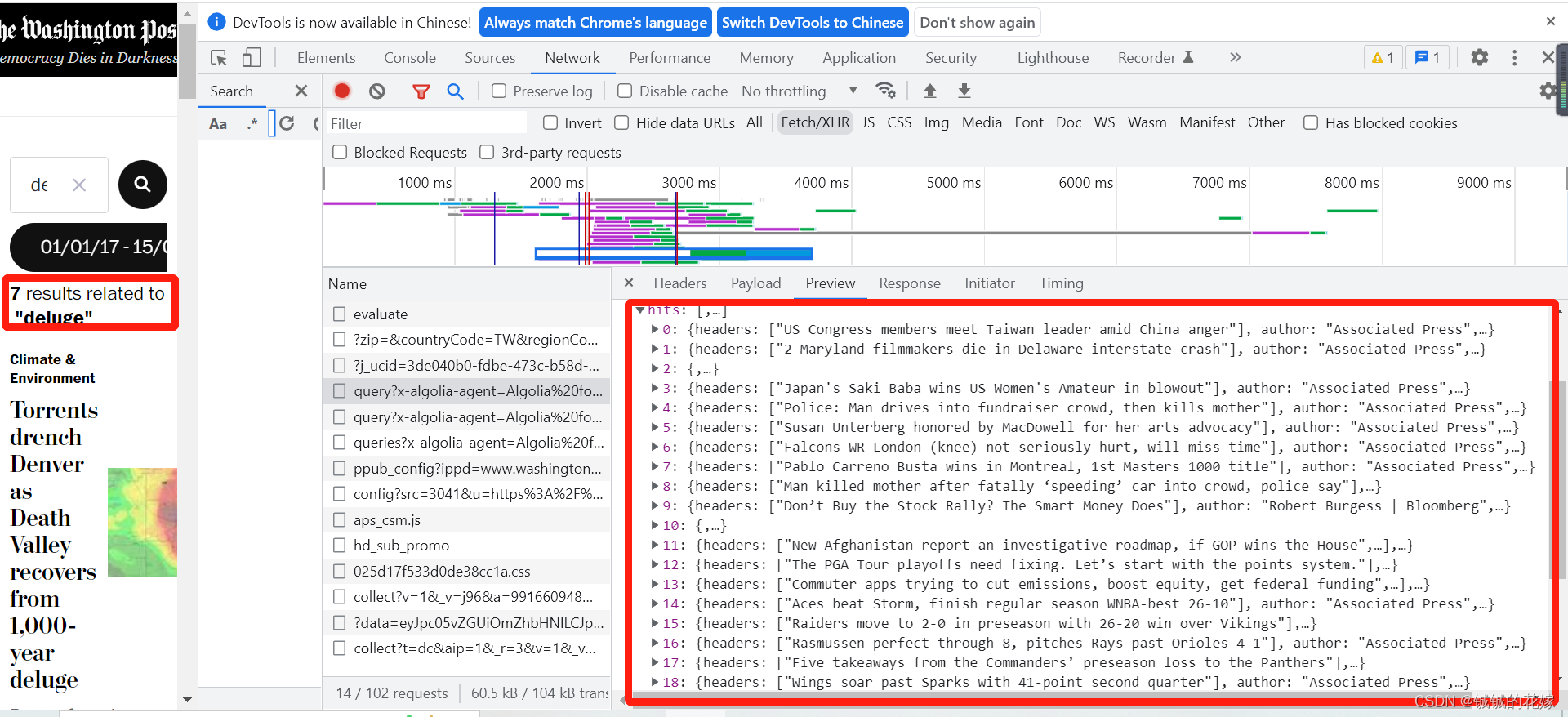
queries
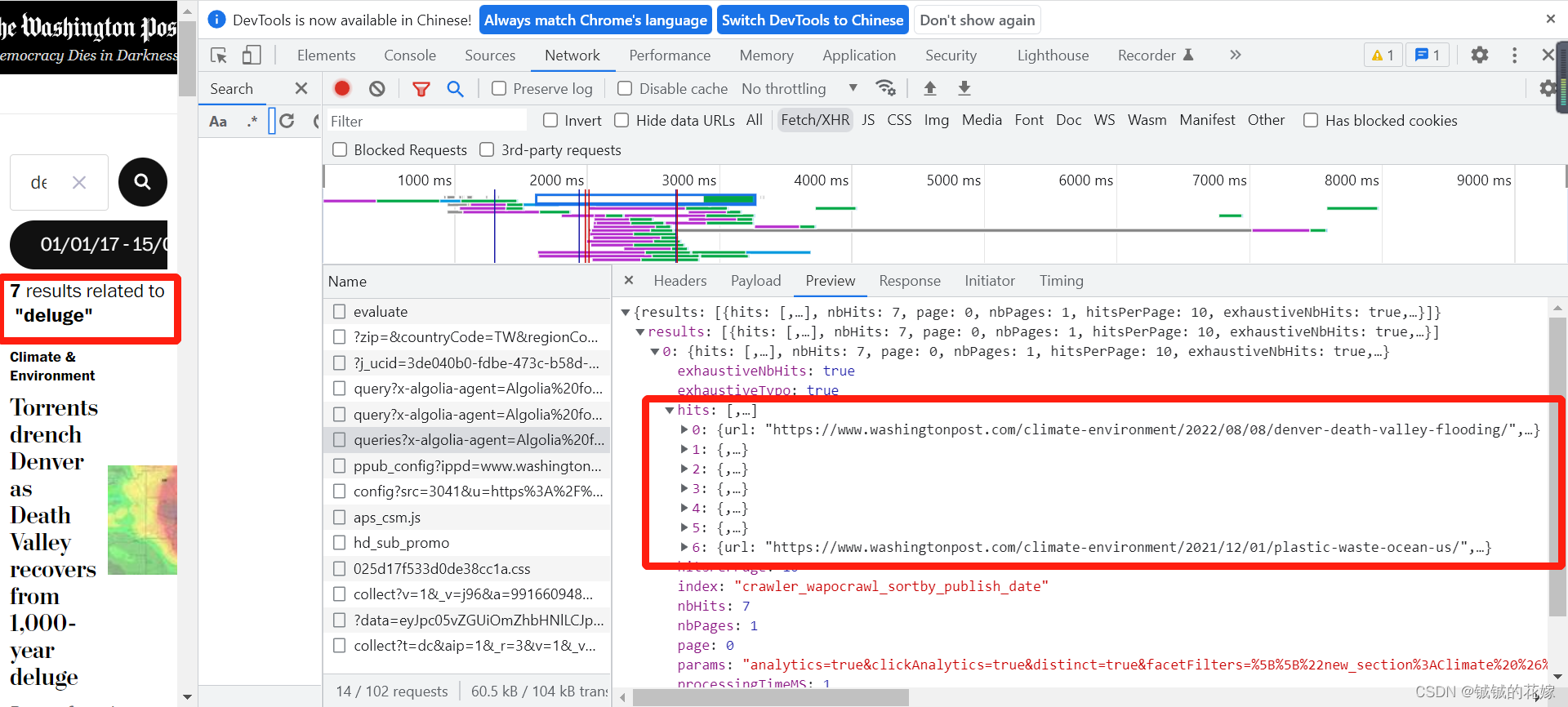
因此,我们接下来只用把queries这个文件弄下来就好了。
2. 数据获取
找到我们的目标文件,从文件的Header中复制我们所需的url信息。对比之后发现,每次搜索的url是一样的,不一样的是data。
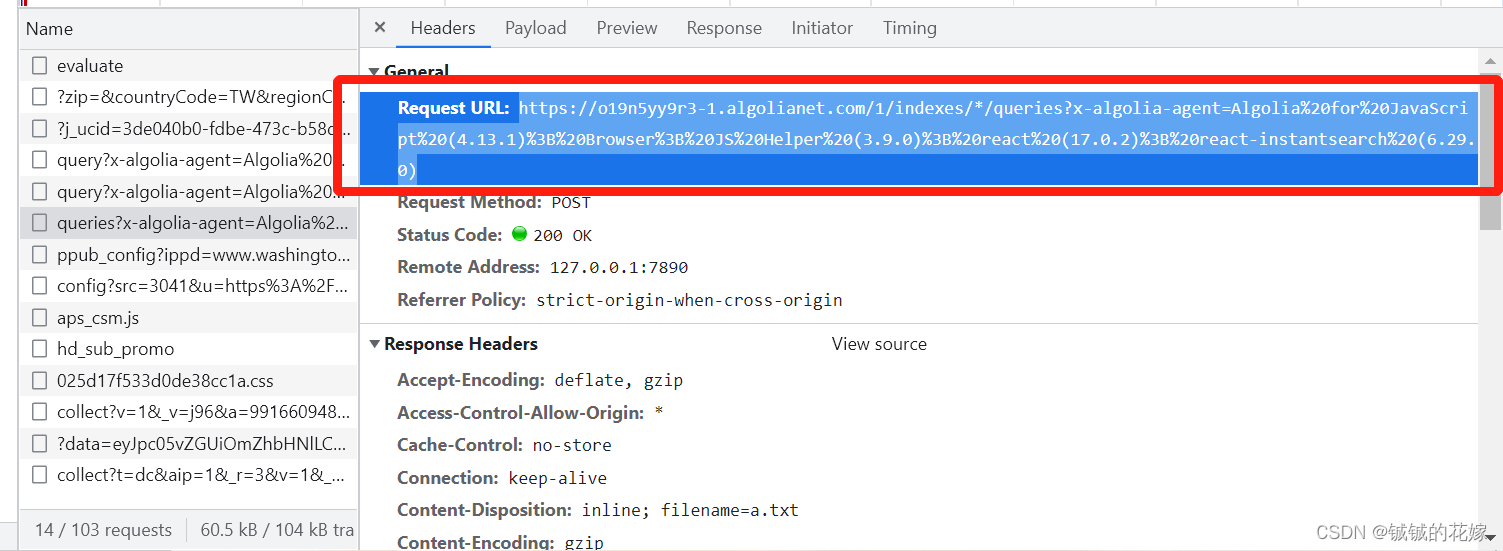
再到header中把整个header拽下来。当然也可以直接挑几个比较重要的参数截。
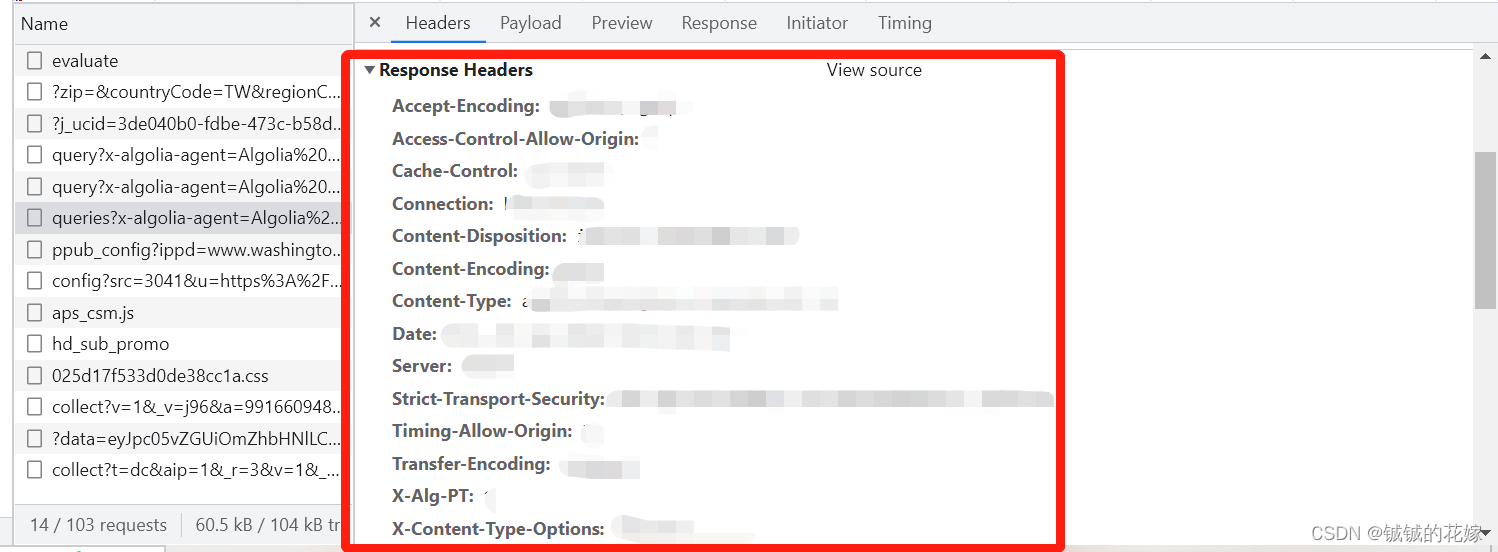
最后复制将data数据拿下来。每次搜索时的传参都是通过这个来的,注意我们这里用到是源代码,转码转来转去太麻烦了,而且容易出错。
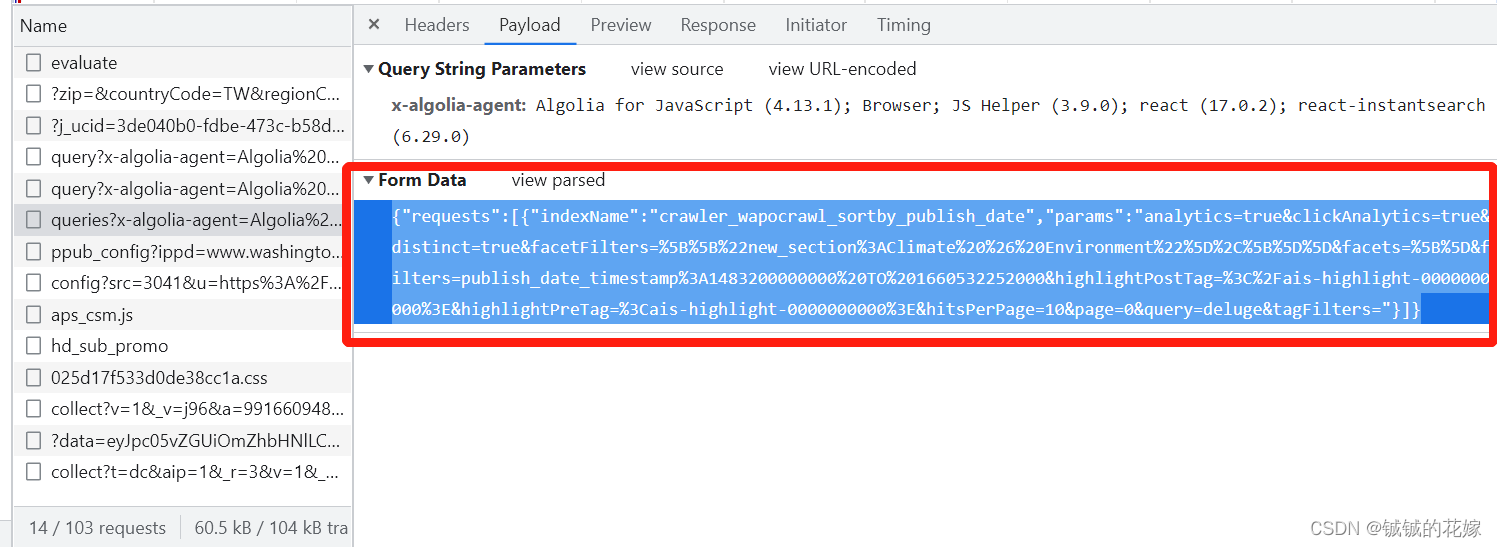
直接上代码:
# -*- coding:utf-8 -*-
import json
import requests
# 负责取出数据
def getdata(keyword):
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
# 字典格式,信息看着放
}
url = r'https://o19n5yy9r3-dsn.algolia.net/1/indexes/*/queries?x-algolia-agent=Algolia%20for%20JavaScript%20(4.13.1)%3B%20Browser%3B%20JS%20Helper%20(3.9.0)%3B%20react%20(17.0.2)%3B%20react-instantsearch%20(6.29.0)'
# 记得修改data,把keyword嵌进去
data = {"requests":[{"indexName":"crawler_wapocrawl_sortby_publish_date","params":"analytics=true&clickAnalytics=true&distinct=true&facetFilters=%5B%5B%5D%2C%5B%5D%5D&facets=%5B%5D&filters=publish_date_timestamp%3A1483200000000%20TO%201660532252000&highlightPostTag=%3C%2Fais-highlight-0000000000%3E&highlightPreTag=%3Cais-highlight-0000000000%3E&hitsPerPage=10&page=0&query="+keyword+"&tagFilters="}]}
# 这里的json.dumps非常非常重要,因为我们的参数是以json的格式传入的,不用这个首先在数据类型上个过不去,其次直接转码的时候会把{}等符号当成字符串处理掉。
req = requests.post(url, headers=headers, data=json.dumps(data))
print(req.text)

输出结果如上,看到这串杂乱无章的结果,还是得处理一下的。
浏览下华盛顿邮报的数据,我们先要明确,我们想要的数据有哪些。根据要求,我们在这个页面的爬取任务主要包括5类数据。
# 正标题,副标题,发布时间,section,新闻网址
["title", "sub-title", "date", "section", "website"]
我们直接在json格式的数据中摘取。
# -*- coding:utf-8 -*-
import json
import requests
# 负责取出数据
def getdata(keyword, url_set):
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
# 字典格式,信息看着放
}
url = r'https://o19n5yy9r3-dsn.algolia.net/1/indexes/*/queries?x-algolia-agent=Algolia%20for%20JavaScript%20(4.13.1)%3B%20Browser%3B%20JS%20Helper%20(3.9.0)%3B%20react%20(17.0.2)%3B%20react-instantsearch%20(6.29.0)'
# 记得修改data,把keyword嵌进去
data = {"requests":[{"indexName":"crawler_wapocrawl_sortby_publish_date","params":"analytics=true&clickAnalytics=true&distinct=true&facetFilters=%5B%5B%5D%2C%5B%5D%5D&facets=%5B%5D&filters=publish_date_timestamp%3A1483200000000%20TO%201660532252000&highlightPostTag=%3C%2Fais-highlight-0000000000%3E&highlightPreTag=%3Cais-highlight-0000000000%3E&hitsPerPage=10&page=0&query="+keyword+"&tagFilters="}]}
# 这里的json.dumps非常非常重要,因为我们的参数是以json的格式传入的,不用这个首先在数据类型上个过不去,其次直接转码的时候会把{}等符号当成字符串处理掉。
req = json.loads(requests.post(url, headers=headers, data=json.dumps(data)).text)
return data_process(req, url_set)
3. 数据处理
我们已经通过请求数据的方法获得了想要的,接下来就是从这个里摘出我们的目标数据。
为了方便统计,我们加入id列,作为新闻的主键。同时,以每个新闻独有的url作为辨识,防止新闻重复。因为我们的新闻是以关键词检索的,不同的关键词检索到同一篇新闻的可能性完全存在。
# 摘取数据
def data_process(req, url_set):
data_list = list()
useful_data = req["results"][0]["hits"]
for i in useful_data:
if i["url"] not in url_set:
news_id = len(url_set)
title = i['title']
sub_title = i['description']
date = i['publish_date']
section = i['section']
website = i["url"]
data_list.append([news_id, keyword.replace("%20", ' '), section, title, sub_title, date, website])
url_set.append(website)
return data_list, url_set
4. 保存数据
因为下游任务是由语言学方向的朋友完成的,这里就舍弃csv, tsv等格式的保存了,可能这些格式对外专业的人不是很友好。对接之后,对方倾向于比较常用的Excel保存数据。此外,对方希望根据关键词检索的结果分别保存新闻数据。
def save_data(index, keyword, data):
data_columns = ['index', 'keywords', 'section', 'title', 'sub-title', 'date', 'website']
data = pd.DataFrame(data)
data.columns = data_columns
data.to_excel('../data/' + str(index).zfill(3) + '_' + keyword.replace("%20", ' ') + '.xlsx', sheet_name='Sheet1', index=False)
效果如下:

5. 数据统计
因为最后的文章数量可能超过2k,为了方便对方对数据有较直观的认识,我们在这里浅浅做一个数据统计。主要包括关键词概览,section概览,新闻时间概览。
# 统计数据
def review_data(path):
print("数据统计中......")
filenames = os.listdir(path)
dataset = list()
for file in filenames:
file = pd.read_excel(path+file)
file = file[['index', 'keywords', 'section', 'date']]
file.date = file.date.map(lambda x: x[:4])
dataset.append(file)
all_data = pd.concat(dataset, axis=0, ignore_index=True)
with pd.ExcelWriter(r'result.xlsx') as writer:
for index, word in enumerate(['keywords', 'section', 'date']):
df = all_data.value_counts(word)
df.to_excel(writer, sheet_name='Sheet_name_'+str(index))

6. 全部代码
# -*- coding:utf-8 -*-
import json
import os
import pandas as pd
import requests
def get_target(keywords):
print("数据爬取中......")
url_set = list()
for index, keyword in enumerate(keywords):
if index % 10 == 9:
print('Epoch [{}/{}]\n'.format(index + 1, len(keywords)+1))
datalist, url_set = getdata(keyword, url_set)
save_data(index, keyword, datalist)
# 获取数据
def getdata(keyword, url_set):
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
# 字典格式,信息看着放
}
url = r'https://o19n5yy9r3-1.algolianet.com/1/indexes/*/queries?x-algolia-agent=Algolia%20for%20JavaScript%20(4.13.1)%3B%20Browser%3B%20JS%20Helper%20(3.9.0)%3B%20react%20(17.0.2)%3B%20react-instantsearch%20(6.29.0)'
data = {"requests":[{"indexName":"crawler_wapocrawl_sortby_publish_date","params":"analytics=true&clickAnalytics=true&distinct=true&facetFilters=%5B%5B%22new_section%3AClimate%20%26%20Environment%22%5D%2C%5B%5D%5D&facets=%5B%5D&filters=publish_date_timestamp%3A1483200000000%20TO%201660532252000&highlightPostTag=%3C%2Fais-highlight-0000000000%3E&highlightPreTag=%3Cais-highlight-0000000000%3E&hitsPerPage=10&page=0&query="+keyword+"&tagFilters="}]}
req = json.loads(requests.post(url, headers=headers, data=json.dumps(data)).text)
return data_process(req, url_set, keyword)
# 摘取数据
def data_process(req, url_set, keyword):
data_list = list()
useful_data = req["results"][0]["hits"]
for i in useful_data:
if i["url"] not in url_set:
news_id = len(url_set)
title = i['title']
sub_title = i['description']
date = i['publish_date']
section = i['section']
website = i["url"]
data_list.append([news_id, keyword.replace("%20", ' '), section, title, sub_title, date, website])
url_set.append(website)
return data_list, url_set
# 保存数据
def save_data(index, keyword, data):
data_columns = ['index', 'keywords', 'section', 'title', 'sub-title', 'date', 'website']
data = pd.DataFrame(data)
data.columns = data_columns
data.to_excel('../data/' + str(index).zfill(3) + '_' + keyword.replace("%20", ' ') + '.xlsx', sheet_name='Sheet1', index=False)
# 统计数据
def review_data(path):
print("数据统计中......")
filenames = os.listdir(path)
dataset = list()
for file in filenames:
file = pd.read_excel(path+file)
file = file[['index', 'keywords', 'section', 'date']]
file.date = file.date.map(lambda x: x[:4])
dataset.append(file)
all_data = pd.concat(dataset, axis=0, ignore_index=True)
with pd.ExcelWriter(r'result.xlsx') as writer:
for index, word in enumerate(['keywords', 'section', 'date']):
df = all_data.value_counts(word)
df.to_excel(writer, sheet_name='Sheet_name_'+str(index))
if __name__ == '__main__':
head = r"https://www.washingtonpost.com/search/?query="
# 2017-01-01 -> 2022-08-12 不限作者 时间排序 环境气候section
tail = r'&btn-search=&facets=%7B"time"%3A%5B1483200000000%2C1660291242104%5D%2C"sort"%3A"date"%2C"section"%3A%5B"Climate+%26+Environment"%5D%2C"author"%3A%5B%5D%7D'
# 注意没有空格只有+
keywords = ["deluge", "extreme%20summer"]
get_target(keywords)
review_data("../data/")
7. 总结
至此我们完成了一整个简单的爬虫的的框架,包括动态数据的获取,数据处理,数据保存,数据统计几个部分。后期会从不同角度去完善整个小项目,包括使用更高级的selenium爬取网页;使用过程中的一些bug的解决;较大规模爬取的注意事项之类的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











