






一、Elasticsearch介绍
1、什么是Elasticsearch?
Elasticsearch是基于lucene的全文检索服务器,对外提供restful接口,ElasticSearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。根据DB-Engines的排名显示,ElasticSearch是最受欢迎的企业搜索引擎,其次是Apache Solr(也是基Lucene)。
总结:
1、elasticsearch是一个基于Lucene的分布式全文检索服务器。
2、elasticsearch隐藏了Lucene的复杂性,对外提供Restful 接口来操作索引、搜索。
2、Elasticsearch原理
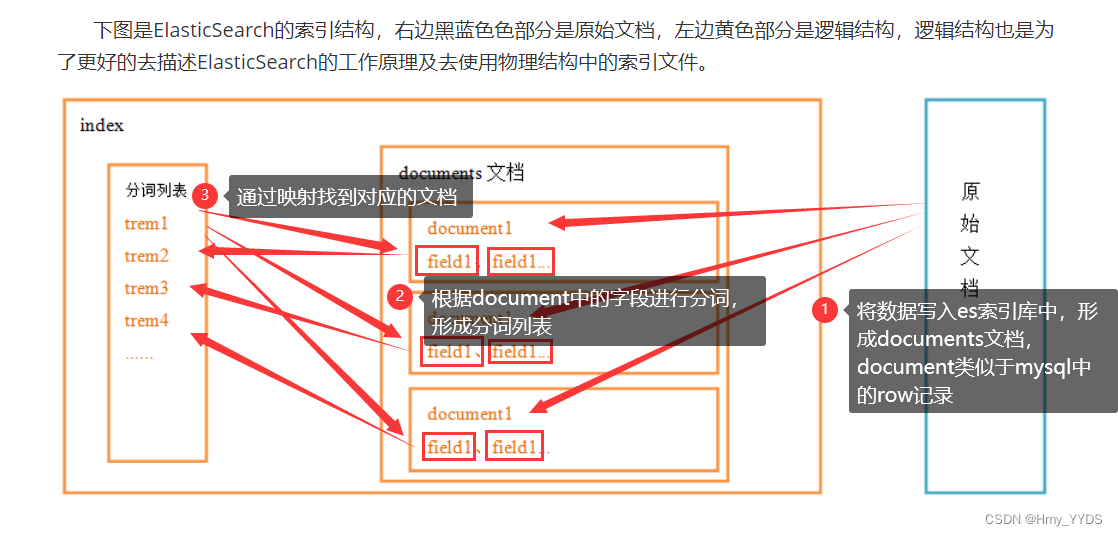
正排索引:相当于查字典从第一页开始找,直到找到位置(文档----->关键字)
倒排索引:相当于查字典时通过目录查询(关键字---->文档的映射)
倒排索引由三部分组成:
term[分词](根据document的字段进行分词)
term----------------->document[链接]
document[文档](写入es索引库的数据)
分词列表的特点:
1、分词不会重复
2、“的 得 地” 语气词不参加分词
3、不进行搜索的field不参加分词
3、Elasticsearch的java客户端
TransportClient://官方计划8.0版本删除
RestHignLevelClient://官方推荐4、Elasticsearch的启动器
elasticsearch-rest-high-level-client
二、es安装和启动
1、安装
1)设置虚拟机内存>2G
2)创建admin,并把upload和local目录的拥有者设置为admin
//从5.0开始,ElasticSearch 安全级别提高了,不允许采用root帐号启动,所以我们要添加一个用户。
创建elk 用户组:groupadd elk
将admin用户添加到elk组:usermod -G elk admin
查看admin分组:groups admin
为用户分配权限:
chown -R admin:elk /usr/upload
chown -R admin:elk /usr/local3)切换账户
su admin4)解压安装包
cd /usr/upload
//ES是Java开发的应用,解压即安装:
tar -zxvf elasticsearch-6.2.3.tar.gz -C /usr/local5)修改elasticsearch.yml和jvm.options配置文件
ES安装目录config中配置文件如下:
elasticsearch.yml:用于配置Elasticsearch运行参数
jvm.options:用于配置Elasticsearch JVM设置
log4j2.properties:用于配置Elasticsearch日志修改elasticsearch.yml:
cluster.name: power_shop //配置elasticsearch的集群名称,默认是elasticsearch。建议见名知意
node.name: power_shop_node_1 //节点名
network.host: 0.0.0.0
http.port: 9200 //设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300 //集群结点之间通信端口
discovery.zen.ping.unicast.hosts: ["192.168.21.133:9300", "192.168.21.134:9300"] //设置集群中master节点的初始列表
path.data: /usr/local/elasticsearch-6.2.3/data
path.logs: /usr/local/elasticsearch-6.2.3/logs
http.cors.enabled: true
http.cors.allow-origin: /.*/修改jvm.options:
//默认内存占用太多了,我们调小一些
-Xms512m
-Xmx512m6)解决文件创建权限、虚拟内存的问题【root】
[1]: max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
//Linux 默认来说,一般限制应用最多创建的文件是 4096个。但是 ES 至少需要 65536 的文件创建权限。我们用的是admin用户,而不是root,所以文件权限不足。解决文件创建权限:
使用root用户修改配置文件:
vim /etc/security/limits.conf
追加下面的内容:
* soft nofile 65536
* hard nofile 65536解决虚拟内存:
[3]: max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
//ES 需要开辟一个 262144字节以上空间的虚拟内存。Linux 默认不允许任何用户和应用直接开辟虚拟内存。
vim /etc/sysctl.conf
追加下面内容:
vm.max_map_count=655360 //限制一个进程可以拥有的VMA(虚拟内存区域)的数量
然后执行命令,让sysctl.conf配置生效:
sysctl -p2、启动和关闭
启动:
./bin/elasticsearch 或 ./bin/elasticsearch -d关闭:
ps -ef | grep elasticsearch
kill -9 pid //pid是es的进程id三、es入门
1、index管理
1)创建index
PUT /java2203
{
"settings":{
"number_of_shards":2 #主分片的数量,提高处理能力
"number_of_replicas":0 #备份分配的数量,提高可用性
}
}
注意:一台服务器时,备份分配的数量必须设置为0,因为主备在同一台服务器上没有意义
2)修改index
PUT /java2203/_setting
{
"number_of_replicas":0
}
注意:index一旦创建,主分片数量不可修改,因为:GET时--->hash(id)%number_of_shards
3)删除index
DELETE /java2203
2、mapping管理
1)创建mapping
POST /java2203/course/_mapping
{
"properties":{
"name":{
"type":"text"
}
}
}
3、document管理
1)新增document
POST /java2203/course/1
{
"name":".net从入门到放弃",
"description":".net程序员谁都不服",
"studymodel":"201003"
}
2)修改document
put /java2203/course/1
{
"name":"php从入门到放弃",
"description":"php程序员谁都不服",
"studymodel":"201003"
}
3)查询document
GET /java2203/course/1
4)删除document
DELETE /java2203/course/1四、ik分词器
1、安装
解压到plugins目录下,并重命名为ik
2、配置自定义词库
IKAnalyzer.cfg.xml:配置扩展词典和停用词典
main.dic:扩展词库,例如:奥利给
stopword.dic:停用词库,例如:a、an、the、的、地、得
注意:必须另存为UTF-8
3、分词模式
ik_max_word:细粒度,往索引库写时使用
ik_smart:粗粒度,搜索时使用五、field的详细介绍
1、filed的数据类型
文本:text、keyword(特殊的varchar,不分词)
数字:integer、long、float、double
2、field的属性
type:数据类型,如:text、integer
analyzer:分词模式,如:analyzer=ik_max_word,search_analyzer=ik_smart
index:是否往索引目录写,如:true,false
_source:document中是否存储,如:includes、excludes
3、field属性设置的标准
属性 标准
type 分词是否有意义
index 是否搜索
_source 是否展示
六、集群的健康状况
绿色:正常
黄色:备份分配不可用【数据完整】
红色:主分片不可用【数据不完整】















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









