










Kafka简介
1Kafka定义
Apache Kafka是一个高吞吐的集发布与订阅与一体的分布式消息系统
流式处理的数据源是kafka,批处理的数据源是hive,也就是hdfs;
2消息队列常见的场景
1.系统之间的解耦合
-queue模型
-publish-subscribe模型
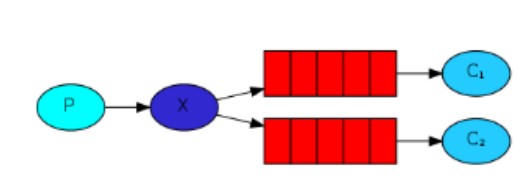
2.峰值压力缓冲,如果高峰期日志大量到SparkSreaming,那么会造成计算时间超过BatchInterval),可以在日志服务器和SparkStreaming中间加入Kafka,起到缓冲的作用
3.异步通信

3 Kafka的架构
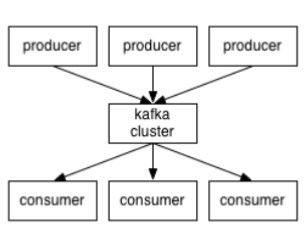

消费者的消费偏移量存储在zookeeper中,生产者生产数据,消费者消费数据,kafka并不会生产数据,但kafka默认一周删除一次数据。
broker就是代理,在kafka cluster这一层这里,其实里面是有很多个broker
topic就相当于Queue,Queue里面有生产者消费者模型
4 Kafka的消息存储和生产消费模型

topic:一个kafka集群中可以划分n多的topic,一个topic可以分成多个partition(这个是为了做并行的), 每个partition内部消息强有序,其中的每个消息都有一个序号叫offset,一个partition对应一个broker,一个broker可以管多个partition,这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念
生产者自己决定往哪个partition写消息(轮循的负载均衡或者是基于hash的partition策略)
消费者可以订阅某一个topic,这个topic一旦有数据,会将数据推送给消费者
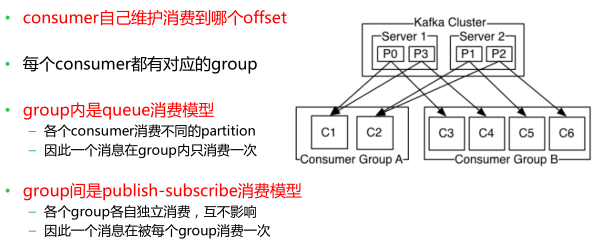
5 kafka 组内queue消费模型 || 组间publish-subscribe消费模型
6 kafka有哪些特点

7为什么Kafka的吞吐量高?
7.1 什么是Zero Copy?
零拷贝"是指计算机操作的过程中,CPU不需要为数据在内存之间的拷贝消耗资源。而它通常是指计算机在网络上发送文件时,不需要将文件内容拷贝到用户空间(User Space)而直接在内核空间(Kernel Space)中传输到网络的方式
7.2 kafka采用零拷贝Zero Copy的方式
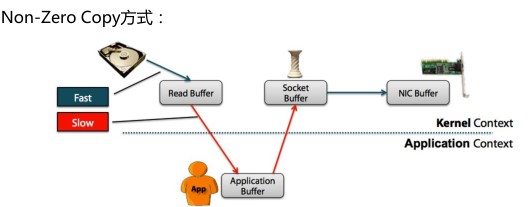
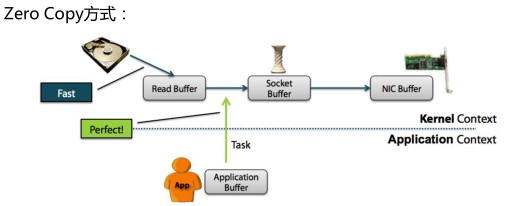
从上图中可以清楚的看到,Zero Copy的模式中,避免了数据在内存空间和用户空间之间的拷贝,从而提高了系统的整体性能。Linux中的sendfile()以及Java NIO中
的FileChannel.transferTo()方法都实现了零拷贝的功能,而在Netty中也通过在
FileRegion中包装了NIO的FileChannel.transferTo()方法实现了零拷贝
8搭建Kafka集群--leader的均衡机制


Kafka中leader的均衡机制
Kafka中一个topic有多个partition,如上图,kfk有0,1,2共三个partition,每个partition都有对应的leader来进行管理,对于leader1来说它来管理partition0,当leader1挂掉之后,因为partition0配置了副本数(在broker0,broker2还存在partition0的副本),那么此时会在broker0,broker2上选出一台当做leader继续管理partition0(比如说选取了broker2当做partition0的leader),这时候如果我们配置了leader均衡机制,重新恢复了broker1,那么partition0的leader就会从broker2转移到broker1,减轻了broker2的读取压力,实现了负载均衡。当然如果不开启leader均衡机制的话,重新恢复broker1,那么partition0的leader仍就是broker2。
Kafka中leader的均衡机制在哪里配置?

在server.properties添加如下一句话
auto.leader.rebalance.enable=true
9 Kafka_code注意事项
注意一:
向kafka中写数据的时候我们必须要指定所配置kafka的所有brokers节点,而不能只配置一个节点,因为我们写的话,是不知道这个topic最终存放在什么地方,所以必须指定全,
读取Kafka中的数据的时候是需要指定zk的节点,只需要指定一个节点就可以了;目前我们使用的在代码中直接写上这些节点,以后全部要写到配置文件中
注意二:
kafka中存储的是键值对,即使我们没有明确些出来key,获取的时候也是需要利用tuple的方式获取值的;而对于放到一个kafka中的数据,这个数据到底存放到那个partition中呢?这个就需要使用hashPartition方式或者普通的轮询方式存放;对于没有明确指定key的发往kafka的数据,使用的就是轮询方式;














 1269
1269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









