







 本文详细介绍了如何在Ubuntu 14.04上配置和编译Nutch 2.3.1,包括环境预装、Nutch下载、HBase的安装、Nutch源码编译以及Nutch工作流程的执行。编译涉及修改nutch-site.xml、ivy.xml和gora.properties文件,以及配置数据存储为HBase。
本文详细介绍了如何在Ubuntu 14.04上配置和编译Nutch 2.3.1,包括环境预装、Nutch下载、HBase的安装、Nutch源码编译以及Nutch工作流程的执行。编译涉及修改nutch-site.xml、ivy.xml和gora.properties文件,以及配置数据存储为HBase。
nutch简介:
目前nutch主要有1.x版本和2.x版本,两个的主要区别在于它们的底层数据库的存储形式不一样,1.x版本是基于hadoop架构的,底层存储使用的是HDFS(Hadoop式分布式存储),而2.x版本采用的是Apache Gora,使得nutch可以访问HBase,Accumulo、Mysql、DataFileAroStore等NoSQL。另外nutch1.X版本从1.7开始不再提供完整的部署文件,只提供源代码和相关的build.xml文件,这就要求用户必须自己手动编译nutch,而整个nutch2.x版本都不提供完整的编译文件,所以要想学习nutch的功能,也必须自己动手编译。
下面我将按照我配置成功的步骤来介绍以下nutch2.3.1版本的编译,以及简单的爬行操作。
环境预装:
1.系统:ubuntu14.04
2.java环境安装,jdk 1.8
3.habse0.98.8-hadoop2安装( 下载地址:
http://archive.apache.org/dist/hbase/hbase-0.98.8/hbase-0.98.8-hadoop2-bin.tar.gz)
nutch下载:
下载地址:http://www.apache.org/dyn/closer.lua/nutch/2.3.1/apache-nutch-2.3.1-src.tar.gz
下载后解压该文件,进入该文件主目录,标记该主目录为NUTCH_HOME.
编译nutch:
1.进入NUTCH_HOME/conf,修改文件nutch-site.xml文件,添加:
<property>
<name>http.agent.name</name>
<value>Horizon</value>
<description>HTTP 'User-Agent' request header. MUST NOT be empty -please set this to a single word uniquely related to your organization. NOTE: You should also check other related properties:http.robots.agents http.agent.description http.agent.url http.agent.email http.agent.version and set their values appropriately.</description>
</property>
<property>
<name>http.robot.agents</name>
<value>test</value>
</property>
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.hbase.store.HBaseStore</value>
<description>Default class for storing data</description>
</property>2.修改NUTCH_HOME/ivy/ivy.xml以确保HBase gora-hbase dependency有效
<!-- Uncomment this to use HBase as Gora backend. -->
<dependency org="org.apache.gora" name="gora-hbase" rev="0.6.1" conf="*->default" />3.在NUTCH_HOME/ivy/ivy.xml中添加hbase-commoon-0.98.8-hadoop2.jar的依赖关系
<dependency org="org.apache.hbase" name="hbase-common" rev="0.98.8-hadoop2" conf="*->default" />4.确保HBaseStore被设置为数据存储的默认方式
修改NUTCH_HOME/conf/gora.properties,添加:
gora.datastore.default=org.apache.gora.hbase.store.HbaseStore5.回到NUTCH_HOME目录下,执行命令:
ant runtime 进行编译。
编译过程中,第一次编译需要国外的maven网站上下载一些必要的.jar文件爱女,所以第一次编译时间较长。也可以在ivy文件下的ivysettings.xml文件下可以修改要下载的网站地址:
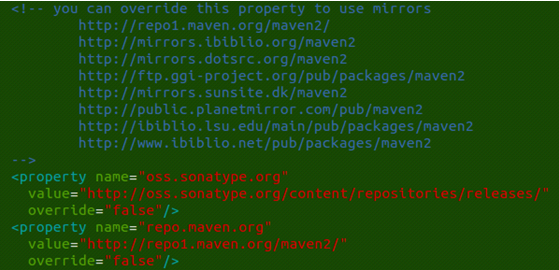
这里可以修改name为repo.maven.org的value值为上面的一个网址,但是由本人亲测,虽然自带的网址比较慢,但还是能够编译成功的。另外,还可以改成国内的开源maven网站,但是在我想编译的这段时间,貌似它是崩溃的。。。。。。
之后若是改变了conf中的配置文件和代码文件,都是需要重新执行ant runtime进行重新编译的。注意在执行编译的时候千万不要ant clean,否则你将会再次迎来漫长的编译时光。
6.编译完成后NUTCH_HOME目录下将会生成一个runtime的文件夹,runtime中包含deploy和local两个文件。要进行爬虫爬行的话,需要进入local文件执行相应的命令。
至此nutch的编译部分完成。下面来体验以下nutch的工作流程:
nutch工作流程:
1.修改配置文件
1.1 修改conf下的regex-urlfilter.txt文件,在文件末尾,有这样的正则表达式:

默认情况下,该文件表示的可以接受任意形式的url网页,如果要改成只保留自己想要的网页,以新浪网为例,其网址为:
http://www.sina.com.cn/
只需要修改成如下所示即可:
#+.
+^http://([a-z0-9]*\.)*sina.com.cn/1.2 创建种子站点,在runtime/local文件夹下创建urls文件夹,并在urls文件夹下创建seed.txt,在该文件中写入你想要爬行的网址,每一行代表一个网址。
2.开始运行nutch
2.1
先在主目录下执行ant runtime重新编译。
切记在运行之前,需要先打开HBase,打开方法为先进入安装HBase的文件下面的bin目录,执行./start-hbase.sh命令

出现上述提示,表示打开成功。
2.2 再次进入NUTCH_HOME下的runtime下的local,执行bin/nutch inject urls/seed.txt下结果:
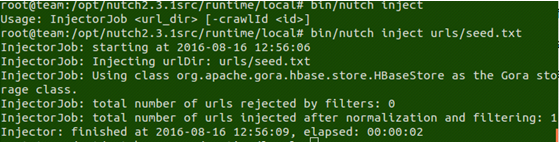
表示已经成功注入了一个网页。
2.3 执行bin/nutch generate -topN 10下结果:
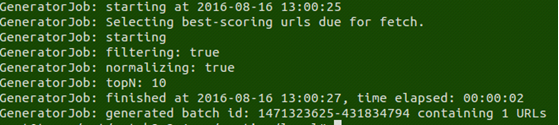
接下来按照nutch的工作流程,依次执行,fetch、parse、updatedb等一系列的命令,可通过nutch产生的hadoop.log日志文件查看nutch的详细流程。
除了上述的一步步的去实现nutch的每个步骤外,还可以直接通过命令:
bin/crawl <seedDir> <crawlID> [<solrUrl>] <numberOfRounds>如:
bin/crawl urls/seed.txt 1 1直接执行nutch的整个流程。















 794
794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









