







 本文详细介绍了强化学习中的DQN算法,包括其工作原理和潜在的过高估计问题。接着,文章阐述了Double DQN如何通过使用两个独立的网络来解决这个问题,以减少动作价值的过高估计。最后,简要提到了Dueling DQN,该算法通过分离状态价值和优势函数来改进DQN,以更好地估计每个动作的价值。
本文详细介绍了强化学习中的DQN算法,包括其工作原理和潜在的过高估计问题。接着,文章阐述了Double DQN如何通过使用两个独立的网络来解决这个问题,以减少动作价值的过高估计。最后,简要提到了Dueling DQN,该算法通过分离状态价值和优势函数来改进DQN,以更好地估计每个动作的价值。
【强化学习】DQN、Double DQN、Dueling DQN的总结
作者:刘兴禄,清华大学,清华伯克利深圳学院,博士在读
DQN
(图片来自Wang Shusen的教学视频,网址:https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0)
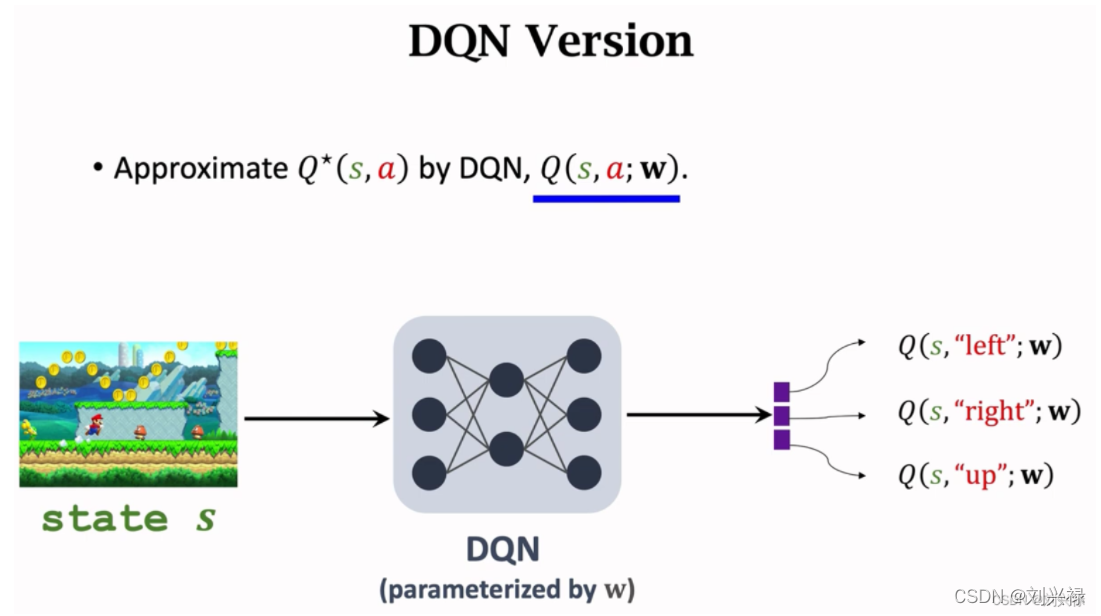
综上,我们来总结一下用TD-learning的DQN版本的算法流程:
- 观察到一个交互(transition) ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1);
- 计算TD target: y target = r t + γ max a Q ( s t + 1 , a ; w t ) y_{\text{target}} = r_t + \gamma \underset{a}{\max \,\,}Q(s_{t+1}, a; \mathbf{w}_{t}) ytarget=rt+γamaxQ(st+1,a;wt);
- 计算TD error: δ t = Q ( s t , a t ; w t ) − y target \delta_t = Q(s_{t}, a_t; \mathbf{w}_{t})-y_{\text{target}} δt=Q(st,at;wt)−ytarget;
- 更新神经网络参数: w t + 1 ← w t − α ⋅ δ t ∂ Q ( s t , a t ; w ) ∂ w \mathbf{w}_{t+1}\leftarrow \mathbf{w}_{t} - \alpha \cdot \delta_t \frac{\partial Q(s_t, a_t; \mathbf{w})}{\partial\mathbf{w}} wt+1←wt−α⋅δt∂w∂Q(st,at;w)
这里注意:
- 我们在状态 s t s_t st下,试探了一步 a t a_t at,得到了reward r t r_t rt,状态更新到 s t + 1 s_{t+1} st+1,我们觉得基于这个试探(探索动作 a t a_t at),我们可以做一个更靠谱的估计 y target = r t + γ max a Q ( s t + 1 , a ; w t ) y_{\text{target}} = r_t + \gamma \underset{a}{\max \,\,}Q(s_{t+1}, a; \mathbf{w}_{t}) ytarget=rt+γamaxQ(st+1,a;wt)
我们将这个更靠谱的估计,就当做真实的值(这也就是为什么叫他target),我们努力往这个方向靠拢。
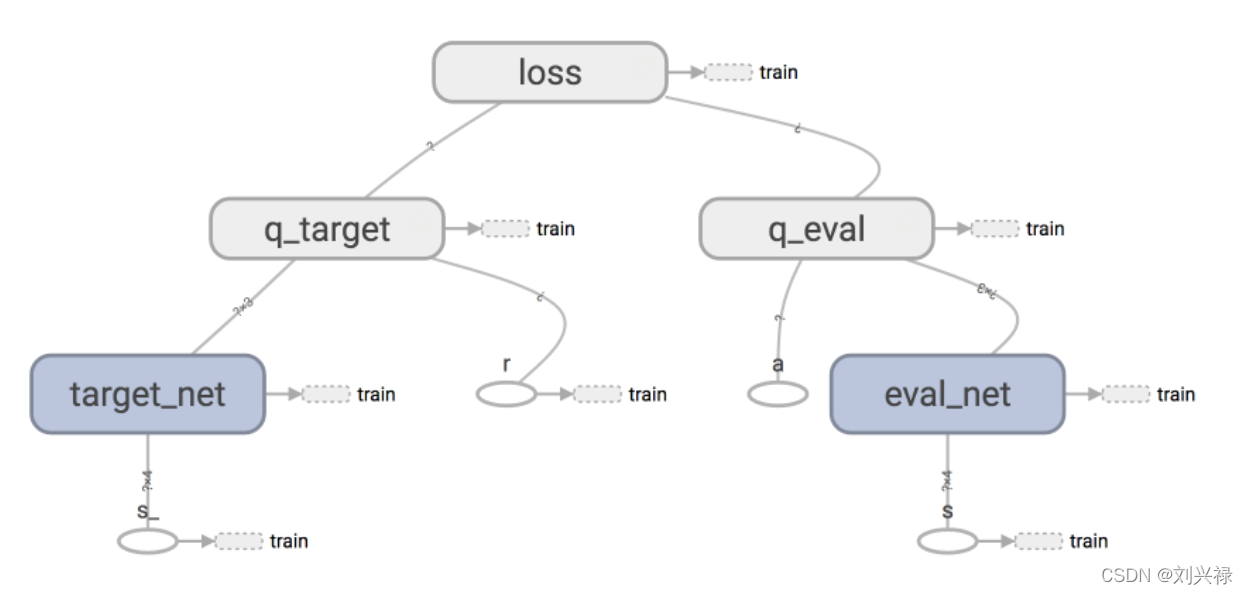
在下图中,就是左边的q_target,他的输入是状态 s t + 1 s_{t+1} st+1以及上一步的奖励 r t r_t rt。由于我们对嗲一步可以采取的动作 a a a做了 max \max max,因此动作 a a a就被消掉了,因此q_target不依赖与动作 a a a。只需要 s t + 1 s_{t+1} st+1和 r t r_t rt即可。
(图片来自莫凡的github: https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow)q_target或者 y target y_{\text{target}} ytarget是我们想要达到的目标,我们其实相当于有将它作为了标签。但是我们预估出来的是多少呢,其实就是 y ^ = Q ( s t , a t ; w t ) \hat{y} = Q(s_{t}, a_t; \mathbf{w}_{t}) y^=Q(st,at</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2997
2997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









