






在大学的学习生涯中,Hadoop 这门课程为我们打开了大数据处理的神秘大门。每一堂课都像是一次充满惊喜的探险,让我们在知识的海洋中不断收获新的感悟。
Hadoop 是一个开源的分布式计算平台,它能够处理大规模的数据。在课程的学习中,我们首先了解了 Hadoop 的基本架构,包括 HDFS(Hadoop Distributed File System)和 MapReduce。HDFS 是一个分布式文件系统,它可以将大规模的数据存储在多个节点上,提高数据的可靠性和可用性。MapReduce 则是一种分布式计算模型,它可以将大规模的数据分成小块,并行地在多个节点上进行处理,提高数据的处理速度。
在学习 HDFS 的过程中,我们通过代码实践深刻体会到了它的强大之处。以下是一段简单的 HDFS 文件上传代码:
from hdfs import InsecureClient
# 创建 HDFS 客户端
client = InsecureClient('http://localhost:50070', user='root')
# 上传本地文件到 HDFS
local_path = '/path/to/local/file.txt'
hdfs_path = '/user/root/uploaded_file.txt'
client.upload(hdfs_path, local_path)通过这段代码,我们可以轻松地将本地文件上传到 HDFS 中,实现数据的分布式存储。这让我们明白了 HDFS 在大数据存储方面的高效性和便捷性。
下面我们来讲讲本学期学习的文章内容所学知识:
一、环境准备
- 硬件要求
- 多台服务器(本文假设使用 3 台服务器:1 台作为主节点,2 台作为从节点)
- 每台服务器具有足够的内存和硬盘空间
- 软件要求
- 操作系统:Linux(本文以 CentOS 7 为例)
- Java 环境(JDK 8 或更高版本)
二、步骤
(一)设置静态 IP
- 编辑网络配置文件
- 在每台服务器上,编辑网络配置文件(如
/etc/sysconfig/network - scripts/ifcfg - eth0) - 设置静态 IP 地址、子网掩码、网关和 DNS 服务器。例如:
- 在每台服务器上,编辑网络配置文件(如
TYPE=Ethernet
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
NAME=eth0
UUID=xxxxxx
DEVICE=eth0
ONBOOT=yes
IPADDR=192.168.1.100
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=8.8.8.8- 重启网络服务:
service network restart
三、设置主机名
- 修改主机名配置文件
- 在每台服务器上,编辑
/etc/hostname文件,设置主机名。例如: - 主节点:
master - 从节点 1:
slave1 - 从节点 2:
slave2
- 在每台服务器上,编辑
- 编辑 hosts 文件
- 在每台服务器上,编辑
/etc/hosts文件,添加主机名和 IP 地址的映射。例如:
- 在每台服务器上,编辑
192.168.1.100 master
192.168.1.101 slave1
192.168.1.102 slave2设置 IP 的映射
- 配置网络映射
- 确保每台服务器的
/etc/hosts文件中正确映射了 IP 地址和主机名(如上述步骤)
- 确保每台服务器的
安装 Java
- 下载 JDK
- 从 Oracle 官网下载 JDK 安装包(如
jdk - 8uXXX - linux - x64.tar.gz)
- 从 Oracle 官网下载 JDK 安装包(如
- 解压安装
- 在每台服务器上,解压 JDK 安装包到指定目录(如
/usr/local/java)
- 在每台服务器上,解压 JDK 安装包到指定目录(如
tar - zxvf jdk - 8uXXX - linux - x64.tar.gz - C /usr/local/java配置环境变量
- 编辑
/etc/profile文件,添加以下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_XXX
export PATH=$PATH:$JAVA_HOME/bin- 使环境变量生效:
source /etc/profile - 安装 Hadoop
- 下载 Hadoop
- 从 Hadoop 官网下载 Hadoop 安装包(如
hadoop - 2.7.3.tar.gz)
- 从 Hadoop 官网下载 Hadoop 安装包(如
- 解压安装
- 在每台服务器上,解压 Hadoop 安装包到指定目录(如
/usr/local/hadoop)
- 在每台服务器上,解压 Hadoop 安装包到指定目录(如
tar - zxvf hadoop - 2.7.3.tar.gz - C /usr/local/配置 Hadoop 环境变量
- 编辑
/etc/profile文件,添加以下内容:
export HADOOP_HOME=/usr/local/hadoop/hadoop - 2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- 使环境变量生效:
source /etc/profile
配置 Hadoop 核心文件
- 编辑
$HADOOP_HOME/etc/hadoop/core - site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>- 编辑
$HADOOP_HOME/etc/hadoop/hdfs - site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>- 编辑
$HADOOP_HOME/etc/hadoop/mapred - site.xml
<configuration>
<property>
<name>mapreduce.framework.console</name>
<value>yarn</value>
</property>
</configuration>- 编辑
$HADOOP_HOME/etc/hadoop/yarn - site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux - services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>配置 Hadoop 集群
- 在主节点上,编辑
$HADOOP_HOME/etc/hadoop/slaves文件,添加从节点主机名:
slave1
slave2- 格式化 Hadoop 文件系统
- 在主节点上,执行格式化命令:
hdfs namenode - format
- 在主节点上,执行格式化命令:
- 启动 Hadoop 集群
- 在主节点上,启动 Hadoop 集群:
start - all.sh<HDFS 分布式文件系统的实践与应用>
(一)认识 HDFS 常用命令
- 文件操作命令
- 创建目录:
- 命令:
hdfs dfs -mkdir /user/test - 解释:在 HDFS 的根目录下创建一个名为
/user/test的目录。
- 命令:
- 上传文件:
- 命令:
hdfs dfs -put local_file.txt /user/test - 解释:将本地的
local_file.txt文件上传到 HDFS 的/user/test目录中。
- 命令:
- 查看文件列表:
- 命令:
hdfs dfs -ls /user/test - 解释:查看
/user/test目录下的文件和目录列表。
- 命令:
- 下载文件:
- 命令:
hdfs dfs -get /user/test/local_file.txt local_download.txt - 解释:将 HDFS 中的
/user/test/local_file.txt文件下载到本地,并命名为local_download.txt。
- 命令:
- 删除文件或目录:
- 命令:
hdfs dfs -rm -r /user/test - 解释:递归删除
/user/test目录及其所有内容。
- 命令:
- 创建目录:
(二)运行首个 MapReduce 任务
- 编写 WordCount 示例
- Mapper 类:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for (String w : words) {
word.set(w);
context.write(word, one);
}
}
}
(三)JAVA API HDFS 前置工作 - 配置环境
- Windows 下 JDK 配置
- 下载 JDK 安装包:从 Oracle 官网下载适合 Windows 系统的 JDK 版本,如 JDK 8 或更高版本。
- 安装 JDK:运行安装程序,按照提示完成安装。
- 配置环境变量:
- 新建
JAVA_HOME变量,值为 JDK 的安装路径,例如C:\Program Files\Java\jdk1.8.0_xxx。 - 在
Path变量中添加%JAVA_HOME%\bin和%JAVA_HOME%\jre\bin。
- 新建
- 验证安装:打开命令提示符,输入
java -version,如果显示 JDK 版本信息,则配置成功。
- Windows 下 HADOOP 配置
- 下载 Hadoop 安装包:从 Hadoop 官网下载适合 Windows 系统的 Hadoop 版本。
- 解压安装包:将下载的压缩包解压到指定目录,例如
C:\hadoop。 - 配置环境变量:
- 新建
HADOOP_HOME变量,值为 Hadoop 的解压路径,例如C:\hadoop。 - 在
Path变量中添加%HADOOP_HOME%\bin。
- 新建
- 配置 Hadoop 相关文件:
- 编辑
C:\hadoop\etc\hadoop\core - site.xml,添加以下内容:
- 编辑
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration> 编辑C:\hadoop\etc\hadoop\hdfs - site.xml,添加以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>C:\hadoop\data\namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>C:\hadoop\data\datanode</value>
</property>
</configuration>
-
- 格式化 HDFS:打开命令提示符,进入
C:\hadoop\bin目录,执行hdfs namenode - format命令。 - 启动 HDFS:执行
start - dfs.cmd命令启动 HDFS 服务。
- 格式化 HDFS:打开命令提示符,进入
- 配置 Maven 仓库
- 下载并安装 Maven:从 Maven 官网下载 Maven 安装包,运行安装程序完成安装。
- 配置 Maven 环境变量:
- 新建
MAVEN_HOME变量,值为 Maven 的安装路径,例如C:\Program Files\Apache\maven。 - 在
Path变量中添加%MAVEN_HOME%\bin。
- 新建
- 配置本地 Maven 仓库:编辑
C:\Program Files\Apache\maven\conf\settings.xml文件,设置本地仓库路径,例如:收起
<localRepository>C:\maven\repository</localRepository>
- 编写 MapReduce 代码:参考前面的 WordCount 示例,在项目中编写 MapReduce 相关代码。
- 配置运行环境:在 IntelliJ IDEA 中配置 Hadoop 运行环境,设置 Hadoop 的安装路径等参数。
(四)应用 JAVA API HDFS
- 创建文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateFileHDFS {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path file = new Path("/user/test/new_file.txt");
if (fs.createNewFile(file)) {
System.out.println("File created successfully.");
} else {
System.out.println("File already exists.");
}
fs.close();
}
}- 解释:这段代码通过 Java API 在 HDFS 的
/user/test目录下创建一个名为new_file.txt的文件。 - 读取文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ReadFileHDFS {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path file = new Path("/user/test/new_file.txt");
if (fs.exists(file)) {
FSDataInputStream in = fs.open(file);
byte[] buffer = new byte[1024];
int bytesRead = 0;
while ((bytesRead = in.read(buffer)) > 0) {
System.out.println(new String(buffer, 0, bytesRead));
}
in.close();
}
fs.close();
}
}
- 解释:这段代码通过 Java API 读取 HDFS 中
/user/test/new_file.txt文件的内容。
<HIVE 数据仓库的搭建与操作>
HIVE 部署
(一)安装 MySQL
- 下载与安装
- 从 MySQL 官方网站下载适合你操作系统的 MySQL 安装包。
- 运行安装程序,按照提示进行安装。在安装过程中,设置好 root 用户的密码。
- 配置环境变量(可选)
- 对于 Linux 系统,可以将 MySQL 的 bin 目录添加到系统的 PATH 环境变量中,方便在命令行中执行 MySQL 相关命令。
(二)HIVE 直连数据库模式配置
- 下载与解压 HIVE
- 从 HIVE 官方网站下载 HIVE 的安装包,解压到指定目录。例如,在 Linux 系统下,可以解压到
/usr/local/hive目录。
- 从 HIVE 官方网站下载 HIVE 的安装包,解压到指定目录。例如,在 Linux 系统下,可以解压到
- 配置 HIVE
- 编辑
hive - site.xml文件- 在 HIVE 的配置目录(通常在
$HIVE_HOME/conf)下,创建hive - site.xml文件(如果不存在),并添加以下配置内容:
- 在 HIVE 的配置目录(通常在
- 编辑
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>your_mysql_password</value>
</property>
</configuration>-
-
- 这里的
your_mysql_password需要替换为你在安装 MySQL 时设置的 root 用户密码。
- 这里的
- 添加 MySQL 驱动
- 从 MySQL 官方网站下载 MySQL 的 JDBC 驱动(如
mysql - connector - java - x.x.x.jar),将其拷贝到 HIVE 的 lib 目录下($HIVE_HOME/lib)。
- 从 MySQL 官方网站下载 MySQL 的 JDBC 驱动(如
-
(三)启动 HIVE
- 初始化元数据
- 在 HIVE 安装目录下的 bin 目录中,执行以下命令初始化 HIVE 元数据:
- 命令:
schematool - initSchema - dbType mysql
- 命令:
- 这一步会在 MySQL 中创建 HIVE 所需的元数据库。
- 在 HIVE 安装目录下的 bin 目录中,执行以下命令初始化 HIVE 元数据:
- 启动 HIVE 服务
- 执行
hive命令启动 HIVE 服务。在命令提示符下,你将进入 HIVE 的命令行界面(CLI),可以在此执行 HiveQL 语句。
- 执行
三、DDL(数据定义语言)操作
(一)创建数据库
- HiveQL 语句
- 在 HIVE 的 CLI 中,使用以下语句创建数据库:
- 命令:
CREATE DATABASE my_database;
- 命令:
- 这里
my_database是你要创建的数据库名称,可以根据实际需求替换。
- 在 HIVE 的 CLI 中,使用以下语句创建数据库:
- 解释
- 这条语句会在 HIVE 中创建一个新的数据库。如果在创建时不指定路径,数据库默认会存储在 HDFS 的
/user/hive/warehouse目录下。
- 这条语句会在 HIVE 中创建一个新的数据库。如果在创建时不指定路径,数据库默认会存储在 HDFS 的
(二)查看数据库
- HiveQL 语句
- 在 HIVE 的 CLI 中,使用以下语句查看所有数据库:
- 命令:
SHOW DATABASES;
- 命令:
- 这条语句会列出 HIVE 中所有已存在的数据库。
- 在 HIVE 的 CLI 中,使用以下语句查看所有数据库:
- 查看特定数据库信息
- 如果你想查看特定数据库的详细信息,可以使用以下语句:
- 命令:
DESCRIBE DATABASE my_database;
- 命令:
- 这里
my_database是你要查看信息的数据库名称。
- 如果你想查看特定数据库的详细信息,可以使用以下语句:
通过以上步骤,我们完成了 HIVE 数据仓库的部署,并进行了基本的 DDL 操作。在实际的数据仓库项目中,还可以进一步进行数据加载(使用LOAD DATA语句等)、数据查询(使用SELECT语句等)和数据分析操作。HIVE 提供了一种便捷的方式来处理存储在 Hadoop 集群中的数据,尤其适合对 SQL 比较熟悉的数据分析师和开发人员。
<HBase 分布式数据库的搭建与操作>
安装与配置
(一)安装 Zookeeper
- 下载 Zookeeper
- 从 Zookeeper 官方网站(Apache ZooKeeper)下载 Zookeeper 的稳定版本。
- 解压下载的文件到指定目录,例如在 Linux 系统下:
tar -zxvf apache-zookeeper-x.x.x-bin.tar.gz -C /usr/local配置 Zookeeper
- 进入 Zookeeper 的配置目录(
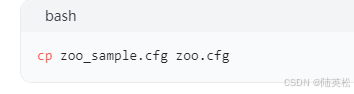
/usr/local/apache - zookeeper - x.x.x - bin/conf),将zoo_sample.cfg复制为zoo.cfg:
编辑zoo.cfg文件,配置数据目录和客户端端口等参数。例如:

启动 Zookeeper
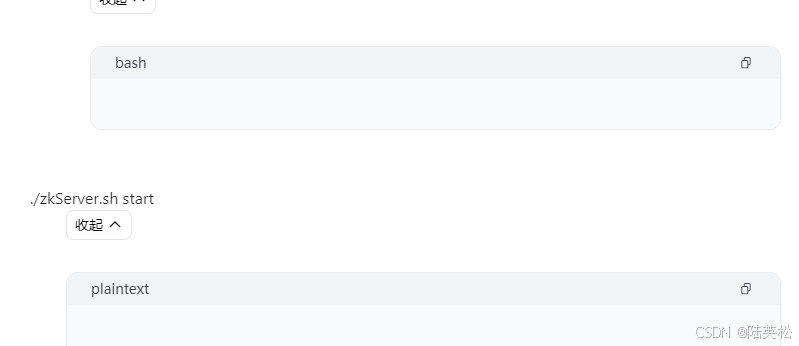
- 进入 Zookeeper 的 bin 目录,执行启动命令:
(二)安装及配置 HBase 集群
- 下载 HBase
- 从 HBase 官方网站(Apache HBase – Apache HBase® Home)下载 HBase 的稳定版本。
- 解压下载的文件到指定目录,例如在 Linux 系统下:
tar -zxvf hbase-x.x.x-bin.tar.gz -C /usr/local-
- 这里的
x.x.x是 HBase 的版本号。
- 这里的
- 配置 HBase
- 编辑
$HBASE_HOME/conf/hbase - site.xml文件(如果不存在则创建),添加以下配置:
- 编辑
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/apache - zookeeper - x.x.x - bin/data</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
</configuration>启动 HBase
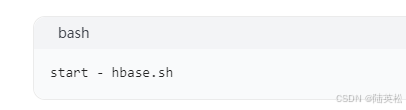
- 执行以下命令启动 HBase:
四、HBASE JAVA API
- 添加依赖
- 在 Java 项目中,添加 HBase 的依赖。如果使用 Maven,在
pom.xml文件中添加以下依赖:
- 在 Java 项目中,添加 HBase 的依赖。如果使用 Maven,在
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase - client</artifactId>
<version>x.x.x</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase - common</artifactId>
<version>x.x.x</version>
</dependency>
创建连接
- 使用 Java API 创建 HBase 连接:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; public class HBaseJavaExample { public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); Connection connection = ConnectionFactory.createConnection(conf); // 在这里进行后续操作 connection.close(); } }插入数据:
-

查询数据:

通过以上步骤,我们完成了 Zookeeper 的安装、HBase 集群的搭建与配置,并进行了 HBase Shell 操作和基于 Java API 的操作。在实际应用中,HBase 可用于处理海量数据的存储和实时查询,是大数据领域中重要的分布式数据库之一。
在大学生涯中接触和学习 Hadoop,就像是打开了一扇通往大数据世界的大门。从 Hadoop 集群的搭建和配置,到 HDFS 分布式文件系统的应用,再到 HIVE 数据仓库和 HBase 分布式数据库的深入实践,每一个环节都是对我们技术能力和思维模式的锻炼。
对于大学生而言,掌握 Hadoop 相关技术不仅仅是为了在简历上增添亮点,更是为了能够在这个数据驱动的时代中立足。通过实际操作和项目实践,我们培养了自己解决复杂问题的能力,学会了如何在分布式环境下高效地处理和分析数据。这些经验和技能,无论是在未来的学术研究中,还是在进入职场后,都将成为我们宝贵的财富。
随着大数据技术的不断发展,Hadoop 生态系统也在持续演变。作为新时代的大学生,我们要保持学习的热情和好奇心,不断探索新的技术和应用场景,将所学知识与实际需求相结合,为大数据领域的发展贡献自己的一份力量。愿每一位在 Hadoop 学习之路上的同学,都能收获知识、收获成长,在大数据的海洋中乘风破浪,驶向成功的彼岸。
青山不改,绿水长流!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









