






字典的定义和操作
用途:字典可以提供基于key检索value的场景实现
定义用法:
my_dict1 = {key:value, key:value, key:value}
my_dict2 = {}
my_dict3 = dict()常用操作:
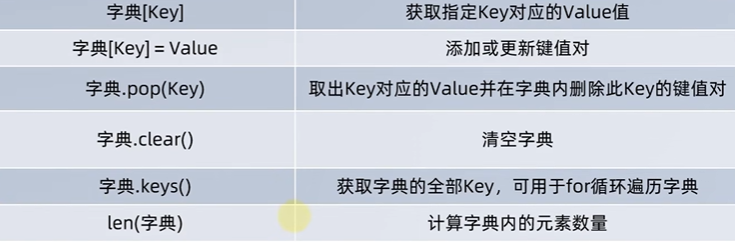
操作注意:新增和更新元素的语法一致“字典[key]”,如果key不存在即新增,如果key存在则更新(key不可重复)
特点:
可以容纳多个数据
可以容纳不同类型的数据
每一份数据是keyvalue键值对
可以通过key获取value,key不可重复(重复会覆盖原有)
不支持下标索引
可以修改(增删等)
支持for循环,不支持while循环
示例:
'''
完成员工信息统计,包括姓名,部门,工资,级别
通过for循环,对所有级别为1级的员工,级别上升一级,工资增加1k元
'''
#记录数据
personal = {
"xiaoming":{
"apart":"tech",
"sala":3000,
"level":1
},
"wang":{
"apart":"market",
"sala":5000,
"level":2
},
"xiaozhang":{
"apart":"market",
"sala":7000,
"level":3
},
"fang":{
"apart":"tech",
"sala":4000,
"level":1
},
"xiaoliu":{
"apart":"market",
"sala":6000,
"level":2
}
}
#for循环遍历字典
fornameinpersonal:
#if判断级别
ifpersonal[name]["level"] == 1:
#获取信息
employee_personal = personal[name]
#修改信息
employee_personal["level"] = 2
employee_personal["sala"] += 1000
#更新回原dict
personal[name] = employee_personal
#print
print(f"升职加薪的操作:{personal}")总结
分类:
是否支持下标索引:
支持:list、tuple、str —— 序列类型
不支持:set、dict —— 非序列类型
是否支持重复元素:
支持:list、tuple、str —— 序列类型
不支持:set、dict —— 非序列类型
是否可以修改:
支持:list、set、dict
不支持:tuple、str
特点对比:
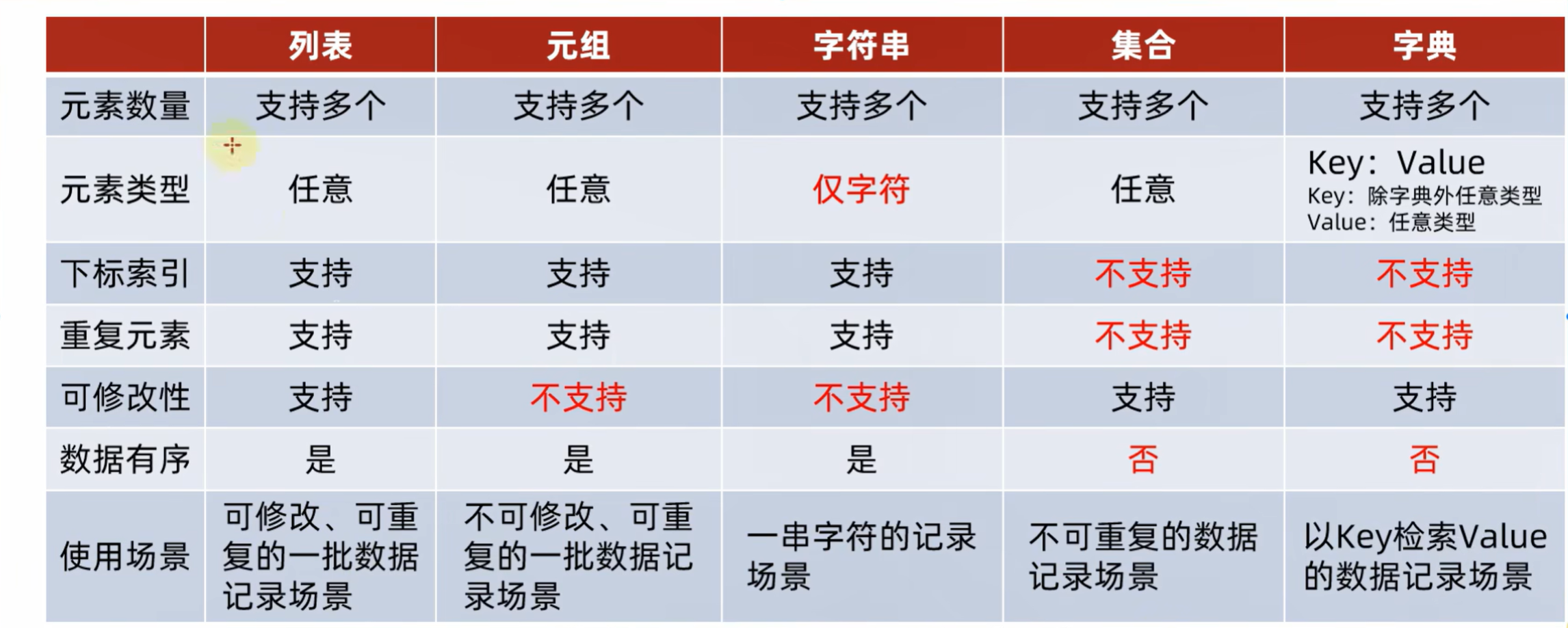
存储应用场景:
列表:数据,可修改,可重复
元组:数据,不可修改,可重复
字符串:字符串
集合:数据,去重
字典:数据,用key检索value
数据容器的通用操作
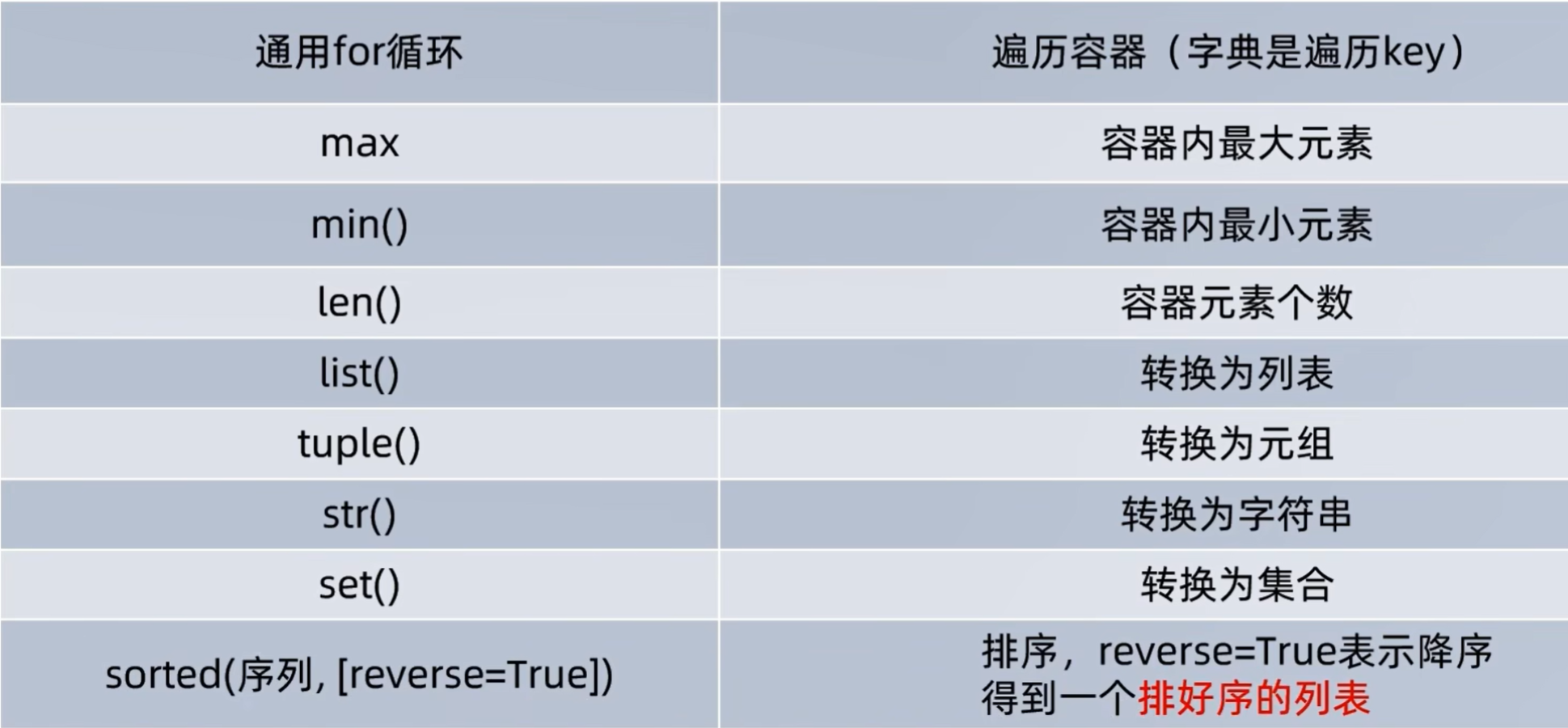
字符串如何进行大小比较:依据ASCII码表,基于码值,从头到尾一位一位比较
chapter7 函数进阶
函数的多返回值
语法:
'''
def test_return():
return 1,2
x,y = test_return()
print(x)
print(y)注意:
按照返回值的顺序,写对应顺序的多个变量接收即可
变量之间用逗号隔开
支持不同类型的数据return
函数的多种传参方式
位置参数:
根据参数位置来传递参数
传递的参数和定义的参数和顺序及个数必须一致
defuser_info(name, age, gender):
print(f"name = {name}, age = {age}, gender = {gender}")
user_info("xiaoming",20,"male")关键字参数:
通过“键-值”形式传递参数,可以不限参数顺序
可以和位置参数混用,混用时位置参数需在前
defuser_info(name, age, gender):
print(f"name = {name}, age = {age}, gender = {gender}")
user_info("xiaowang", gender="male", age=20)#位置参数在前,后两个参数顺序颠倒时都需要写成键值对形式
缺省参数(默认参数):
不传递参数值时会使用默认的参数值
默认值的参数必须定义在最后
defuser_info(name, age, gender="male"):#默认值的参数必须定义在最后
print(f"name = {name}, age = {age}, gender = {gender}")
user_info("xiaowang", 20)不定长参数(可变参数):
一般用于 不确定调用的时候会传递多少个参数
位置(不定长)传递以 * 号标记的一个形式参数,以元组的形式接受参数,形参一般命名为 args
defuser_info(*args):
print(args)
user_info("xiaowang", 20)
#打印结果:('xiaowang', 20),是一个元组关键字(不定长)传递以 ** 号标记的一个形式参数,以字典的形式接受参数,形参一般命名为 kwargs
defuser_info(**args):
print(args)
user_info(name="xiaowang", age=20)
#打印结果:{'name': 'xiaowang', 'age': 20},是一个字典函数作为参数传递
函数本身是可以作为参数,传入另一个函数中使用
将函数传入的作用:传入计算逻辑,而非传入数据
示例:
deftest_func(compute):
result = compute(1,2)
print(result)
print(type(compute))
defcompute(x,y):
returnx+y
test_func(compute)
'''
结果:
3
<class 'function'>
'''lambda匿名函数
与def关键字定义函数的区别:
def关键字,可以定义带有名字的函数;lambda关键字,可以定义匿名函数(无名称)
带有名称的函数,可以基于名称重复使用;无名称的函数,只可临时使用一次
定义语法:
lambda传入参数: 函数体
#传入参数表示匿名函数的形式参数,如:x,y表示接受2个形参
#函数体只能写一行示例:
deftest_func(compute):
result = compute(1, 2)
print(result)
test_func(lambdax, y: x+y)
#结果:3注意:
匿名函数用于临时构建一个函数,只用一次的场景
匿名函数的定义中,函数体只能写一行代码,如果函数体要写多行代码,不可用lambda匿名函数,应使用def定义带名函数
chapter8 文件操作
文件编码
是什么:编码就是一种规则集合,记录了内容和二进制之间进行相互转换的逻辑。编码有许多种,我们最常用的是UTF-8编码
用途:将内容翻译成二进制保存在计算机中,同时利用编码将计算机中保存的0和1反向翻译回可识别的内容
文件的读取操作
操作文件需要通过open函数打开文件得到文件对象:
f = open("apple.txt", f, UTF-8)
#f = open(文件名字符串,打开文件的访问模式(只读f,写入w,追加a),编码模式(推荐UTF-8))
#f =open("D:/CODE/testproject/test230226/word.txt", "r", encoding = "UTF-8")
#第一个写地址,第三个要用关键字参数encoding="UTF-8"
文件对象有如下的读取方法:

文件读取完成后,要使用文件对象.close()方法关闭(或者with open() as f)文件对象,否则文件会被一直占用
示例:单词计数
'''
通过windows的notepad,将如下内容,复制并保存到word.txt
内容:
www.baidu.com www.bubei.com
www.bilibili.com www.acfun.com
www.bing.com www.douyin.com
通过文件读取操作,读取此文件,统计bi单词出现的次数
'''
f = open("D:/CODE/testproject/test230226/word.txt", "r", encoding = "UTF-8")
#1
str_word = f.read()#读取全部文件字节
num = str_word.count("bi")#在全部字节中统计bi的次数
print(f"单词bi一共出现次数:{num}次")
#2
# count = 0
# for line in f:#循环文件行
# line = line.strip()#strip移除首尾的空格和换行符或者指定字符串
# words = line.split(" ")#将空格前后分开
# for word in words:
# if word == "bi":
# count += 1#利用count累加统计次数
# print(f"单词bi一共出现次数:{count}次")
#2适用于在单词中搜索单词
#3
count = 0
forlineinf:
line_list = line.strip()
num = line_list.count("bi")
print(f"单词bi一共出现次数:{num}次")
#3本质与1无异,1用read在str中统计,3用for line in在list中统计文件的写入操作
写入文件使用open函数的"w"模式进行写入
写入的方法:
write(), 写入内容
write方法,内容并未真正写入文件,而是将内容积攒到程序的内存中,称之为缓冲区
flush(), 刷新内容到硬盘中
当调用flush时,内容会真正写入文件
注意:
w模式,文件不存在,会创建新文件
w模式,文件存在,会清空原有内容
close()方法,带有flush()方法的功能
示例:
f = open("D:/CODE/testproject/test230226/write.py", "w", encoding="UTF-8")#打开文件(open会自动创建空文件,如果文件尚不存在)
f.write("Hello World!")#内容写到内存中
f.flush()#将内存中积攒的内容,写入到硬盘的文件中
f.close()#close方法内置了flush的功能,所以第三行可以不写文件的追加操作
使用open函数的"a"模式进行追加写入
追加的方法:等同于w模式的操作,打开—追加—关闭
注意:
a模式,文件不存在,会创建新文件
a模式,文件存在,会在最后追加写入文件
可以使用"\n"类写出换行符
综合案例
'''
需求:有一份账单文件bill.txt,记录了消费收入的具体记录,内容如下:
xiaoming,2023-02-26,100,消费,正式
xiaowang,2023-02-25 200,收入,测试
要求读取文件
将文件写出到bill.txt.bak文件作为备份
同时,将文件内标记为测试的数据行丢弃
实现思路:open和r模式打开一个文件对象,并读取文件
open和w模式打开另一个文件对象,用于文件写入
for循环内容,判断是否测试,如果不是测试就write写出,是测试就continue跳过
将2个文件对象均close()
'''
fr = open("D:/CODE/testproject/test230226/bill.txt", "r", encoding="UTF-8")
fw = open("D:/CODE/testproject/test230226/bill.txt.bak", "w", encoding="UTF-8")
forlineinfr:
line = line.strip()#移除换行符\n
ifline.split(",")[4] == "测试":#使用split按照","分割,取下标为4的元素,即正式/测试,用if判断是否为测试
continue#如果是测试,则跳过不写入
fw.write(line)#将内容写入到.bak文件中
print("\n")#由于用strip移除了换行符,应手动写入换行符
fr.close()#写出文件调用close会自动flush
fw.close()chapter9 异常/模块/包
了解异常
当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的“异常”,也就是我们常说的BUG
BUG:1945年9月9日,马克二型计算机无法正常工作,最终定位到70号继电器出错,一只飞蛾躺在中间。负责人哈珀用镊子将死掉的飞蛾取出,用透明胶布铁道“事件记录本”中,并注明“第一个发现虫子的实例。”从此之后,引发软件失效的缺陷,便被称之为BUG
异常的捕获
为什么要捕获异常:在可能发生异常的地方,进行捕获,当异常出现的时候,提供解决方式,而不是任由其导致程序无法执行
捕获异常的语法:
try:
可能要发生异常的语句
except异常as别名:
出现异常的准备手段
[else:]
未发现异常时应做的事情
[finally:]
不管出不出现异常都会做的事情
#try和finally属于可选,可写可不写示例:
捕获常规异常:
try:
f = open("bill.txt","r")#r模式打开一个不存在的文件
except:
f = open("bill.txt","w")#遇到如上异常时,改为w模式捕获单个指定异常:
try:
print(name)
exceptNameErrorase: #这个只能捕获NameError异常
print("出现了变量未定义的异常")捕获多个指定异常:
try:
print(1/0)
except(NameError,ZeroDivisionError):
print("出现了变量未定义 或 除以0的变量")捕获所有异常:
#基础语法就能捕获所有异常
try:
xxx
except:
xxx
#except Exception写法
try:
xxx
exceptExceptionase:
print("出现异常了")没有出现异常(else,可选):
try:
print("Hello!")
exceptExceptionase:
print("出现异常了。")
else:
print("没有出现异常~")无论是否异常都要执行(finally,可选):
try:
f = open("test.txt","r")
exceptExceptionase:
f = open("test.txt","w")
else:
print("没有出现异常~")
finally:
f.close()#无论是否异常,都执行关闭文件操作如何捕获所有异常:
except:
except Exception as xxx:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









