







 BLIP-2是一种新型视觉语言模型,它通过结合预训练的图像编码器和大语言模型,无需端到端预训练,实现了图像字幕生成、有提示图像字幕、视觉问答等任务的高效处理。模型采用轻量级QueryTransformer桥接视觉和语言模态,降低了训练成本并提高了性能。BLIP-2可在HuggingFaceTransformers中使用,支持多样的视觉语言任务,为实际应用提供了强大工具。
BLIP-2是一种新型视觉语言模型,它通过结合预训练的图像编码器和大语言模型,无需端到端预训练,实现了图像字幕生成、有提示图像字幕、视觉问答等任务的高效处理。模型采用轻量级QueryTransformer桥接视觉和语言模态,降低了训练成本并提高了性能。BLIP-2可在HuggingFaceTransformers中使用,支持多样的视觉语言任务,为实际应用提供了强大工具。
本文将介绍来自 Salesforce 研究院的 BLIP-2 模型,它支持一整套最先进的视觉语言模型,且已集成入 🤗 Transformers。我们将向你展示如何将其用于图像字幕生成、有提示图像字幕生成、视觉问答及基于聊天的提示这些应用场景。
BLIP-2 模型文档:
https://hf.co/docs/transformers/main/en/model_doc/blip-2
Transformers 模型及文档:
https://hf.co/transformers
简介
近年来,计算机视觉和自然语言处理领域各自都取得了飞速发展。但许多实际问题本质上其实是多模态的,即它们同时涉及几种不同形式的数据,如图像和文本。因此,需要视觉语言模型来帮助解决一系列组合模态的挑战,我们的技术才能最终得到广泛落地。视觉语言模型可以处理的一些 图生文 任务包括图像字幕生成、图文检索以及视觉问答。图像字幕生成可以用于视障人士辅助、创建有用的产品描述、识别非文本模态的不当内容等。图文检索可以用于多模态搜索,也可用于自动驾驶场合。视觉问答可以助力教育行业、使能多模态聊天机器人,还可用于各种特定领域的信息检索应用。
现代计算机视觉和自然语言模型在能力越来越强大的同时,模型尺寸也随之显著增大。由于当前进行一次单模态模型的预训练既耗费资源又昂贵,因此端到端视觉语言预训练的成本也已变得越来越高。
BLIP-2 通过引入一种新的视觉语言预训练范式来应对这一挑战,该范式可以任意组合并充分利用两个预训练好的视觉编码器和 LLM,而无须端到端地预训练整个架构。这使得我们可以在多个视觉语言任务上实现最先进的结果,同时显著减少训练参数量和预训练成本。此外,这种方法为多模态ChatGPT 类应用奠定了基础。
BLIP-2 论文链接:
https://arxiv.org/pdf/2301.12597.pdf
BLIP-2 葫芦里卖的什么药?
BLIP-2 通过在冻结的预训练图像编码器和冻结的预训练大语言模型之间添加一个轻量级 查询 Transformer (Query Transformer, Q-Former) 来弥合视觉和语言模型之间的模态隔阂 (modality gap)。在整个模型中,Q-Former 是唯一的可训练模块,而图像编码器和语言模型始终保持冻结状态。
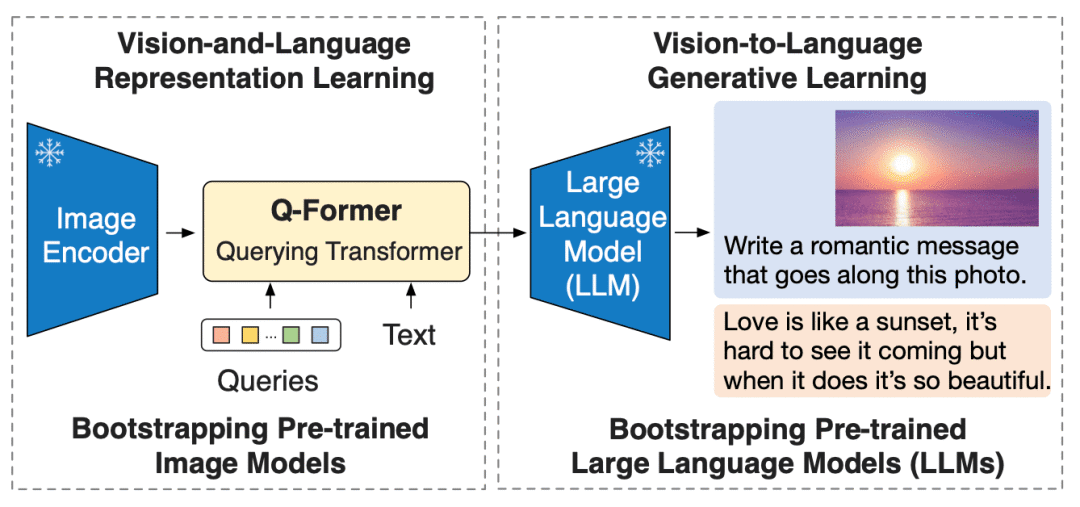
Q-Former 是一个 transformer 模型,它由两个子模块组成,这两个子模块共享相同的自注意力层:
与冻结的图像编码器交互的图像 transformer,用于视觉特征提取
文本 transformer,用作文本编码器和解码器
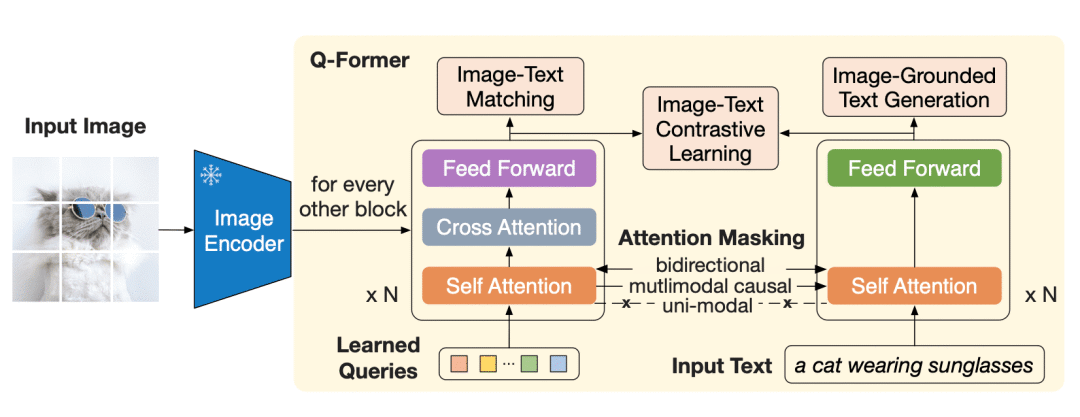
图像 transformer 从图像编码器中提取固定数量的输出特征,这里特征的个数与输入图像分辨率无关。同时,图像 transformer 接收若干查询嵌入作为输入,这些查询嵌入是可训练的。这些查询还可以通过相同的自注意力层与文本进行交互 (译者注: 这里的相同是指图像 transformer 和文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









