







近来,大语言模型 (LLM) 已被证明是提高编程、内容生成、文本分析、网络搜索及远程学习等诸多领域生产力的可靠工具。
大语言模型对用户隐私的影响
尽管 LLM 很有吸引力,但如何保护好 输入给这些模型的用户查询中的隐私 这一问题仍然存在。一方面,我们想充分利用 LLM 的力量,但另一方面,存在向 LLM 服务提供商泄露敏感信息的风险。在某些领域,例如医疗保健、金融或法律,这种隐私风险甚至有一票否决权。
一种备选解决方案是本地化部署,LLM 所有者将其模型部署在客户的计算机上。然而,这不是最佳解决方案,因为构建 LLM 可能需要花费数百万美元 (GPT3 为 460 万美元),而本地部署有泄露模型知识产权 (intellectual property, IP) 的风险。
Zama 相信有两全其美之法: 我们的目标是同时保护用户的隐私和模型的 IP。通过本文,你将了解如何利用 Hugging Face transformers 库并让这些模型的某些部分在加密数据上运行。完整代码见 此处。
全同态加密 (Fully Homomorphic Encryption,FHE) 可以解决 LLM 隐私挑战
针对 LLM 部署的隐私挑战,Zama 的解决方案是使用全同态加密 (FHE),在加密数据上执行函数。这种做法可以实现两难自解,既可以保护模型所有者知识产权,同时又能维护用户的数据隐私。我们的演示表明,在 FHE 中实现的 LLM 模型保持了原始模型的预测质量。为此,我们需要调整 Hugging Face transformers 库 中的 GPT2 实现,使用 Concrete-Python 对推理部分进行改造,这样就可以将 Python 函数转换为其 FHE 等效函数。
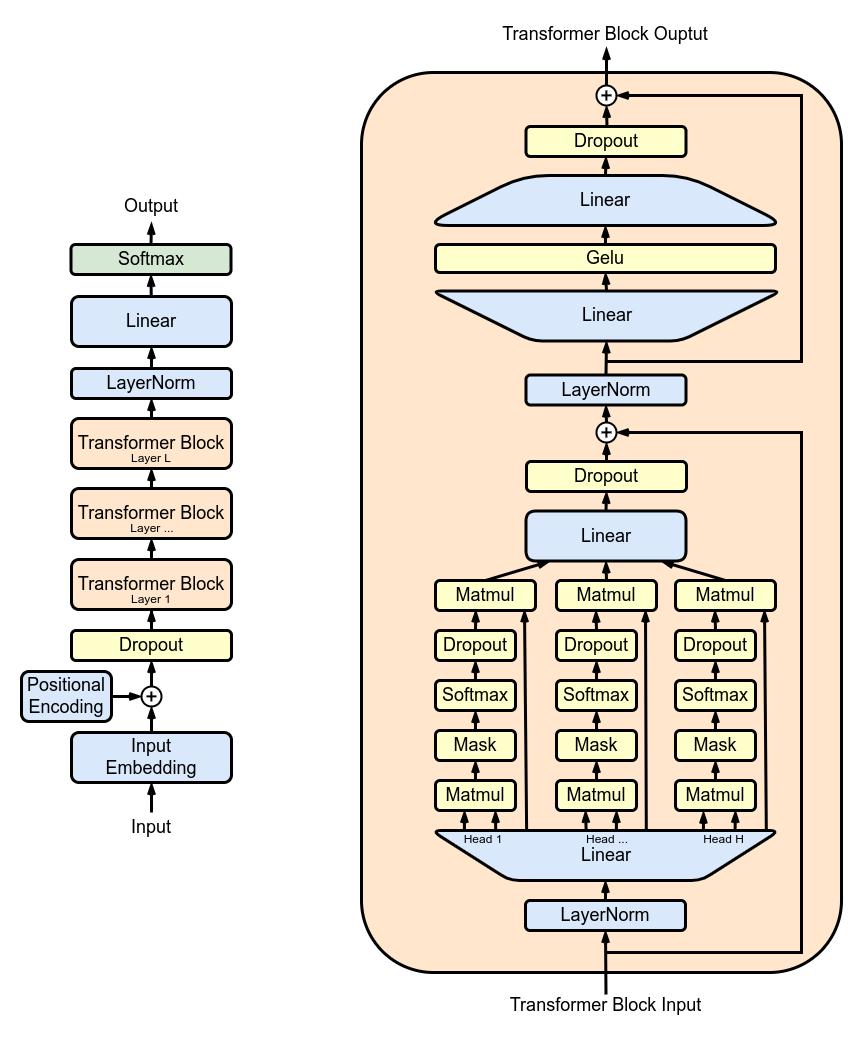
图 1 展示了由多个 transformer block 堆叠而成的 GPT2 架构: 其中最主要的是多头注意力 (multi-head attention,MHA) 层。每个 MHA 层使用模型权重来对输入进行投影,然后各自计算注意力,并将注意力的输出重新投影到新的张量中。
在 TFHE 中ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









