







太长不看版
我们把 Replicate 在 SDXL Cog 训练器中使用的枢轴微调 (Pivotal Tuning) 技术与 Kohya 训练器中使用的 Prodigy 优化器相结合,再加上一堆其他优化,一起对 SDXL 进行 Dreambooth LoRA 微调,取得了非常好的效果。你可以在 diffusers 上找到 我们使用的训练脚本🧨,或是直接 在 Colab 上 试着运行一下。
如果你想跳过技术讲解直接上手,可以使用这个 Hugging Face Space,通过简单的 UI 界面用我们精选的超参直接开始训练。当然,你也可以尝试干预这些超参的设置。
概述
使用 Dreambooth LoRA 微调后的 Stable Diffusion XL(SDXL) 模型仅需借助少量图像即可捕获新概念,同时保留了 SDXL 出图美观高质的优势。更难得的是,虽然微调结果令人惊艳,其所需的计算和资源消耗却相当低。你可在 此处 找到很多精彩的 SDXL LoRA 模型。
本文我们将回顾一些流行的、可以让你的 LoRA 微调更出色的实践和技术,并展示如何使用 diffusers 来运行或训练你自己的 LoRA 模型!
拾遗: LoRA (Low Rank Adaptation,低阶适配) 是一种可用于微调 Stable Diffusion 模型的技术,其可用于对关键的图像/提示交叉注意力层进行微调。其效果与全模型微调相当,但速度更快且所需计算量更小。要了解有关 LoRA 工作原理的更多信息,请参阅我们之前的文章 - 使用 LoRA 进行 Stable Diffusion 的高效参数微调。
致谢 ❤️:
本文展示的各种技术 (包括算法、训练脚本、实验以及各种探索) 是站在很多前人工作的基础上的,包括: Nataniel Ruiz 的 Dreambooth、 Rinon Gal 的 文本逆化 (textual inversion) 、Ron Mokady 的 枢轴微调、Simo Ryu 的 cog-sdxl、Kohya 的 sd-scripts 以及 The Last Ben 的 fast-stable-diffusion。在此,我们向他们和社区表示最诚挚的谢意!🙌
枢轴微调
枢轴微调 技术巧妙地将 文本逆化 与常规的扩散模型微调相结合。以 Dreambooth 为例,进行常规 Dreambooth 微调时,你需要选择一个稀有词元作为触发词,例如“一只 sks 狗” 中的 sks 。但是,因为这些词元原本就来自于词表,所以它们通常有自己的原义,这就有可能会影响你的结果。举个例子,社区之前经常使用 sks 作为触发词,但实际上其原义是一个武器品牌。
为了解决这个问题,我们插入一个新词元到模型的文本编码器中,而非重用词表中现有的词元。然后,我们优化新插入词元的嵌入向量来表示新概念,这种想法就是文本逆化,即我们对嵌入空间中的新词元进行学习来达到学习新概念的目的。一旦我们获得了新词元及其对应的嵌入向量,我们就可以用这些词元嵌入向量来训练我们的 Dreambooth LoRA,以获得两全其美的效果。
训练
使用 diffusers 的新训练脚本,你可以通过设置以下参数来进行文本逆化训练。
--train_text_encoder_ti
--train_text_encoder_ti_frac=0.5
--token_abstraction="TOK"
--num_new_tokens_per_abstraction=2
--adam_weight_decay_text_encodertrain_text_encoder_ti开启文本逆化训练,用于训练新概念的嵌入向量。train_text_encoder_ti_frac指定何时停止文本逆化 (即停止文本嵌入向量的更新,仅继续更新 UNet)。中途定轴 (即仅在训练前半部分执行文本逆化) 是 cog sdxl 使用的默认设置,我们目前的实验也验证了其有效性。我们鼓励大家对此参数进行更多实验。token_abstraction即概念标识符,我们在提示文本中用该词描述我们希望训练的概念。该标识符词元会用在实例提示、验证提示或图像描述文本中。这里我们选择TOK作为概念标识符,如 “TOK 的照片”即为一个含有概念标识符的实例提示。注意,--token_abstraction只是一个占位符,因此,在训练之前我们需要用一个新词元来代替TOK并对其进行训练 (举个例子,训练时“一张TOK的照片”会变成“一张<s0><s1>的照片”,其中<s0><s1>就是新词元)。同样地,需要确保这里的token_abstraction与实例提示、验证提示和自定义提示 (如有) 中的标识符相一致。num_new_tokens_per_abstraction表示每个token_abstraction对应多少个新词元 - 即需要向模型的文本编码器插入多少个新词元并对其进行训练。默认设置为 2,我们鼓励大家对不同取值进行实验并分享你们的发现!adam_weight_decay_text_encoder用于为文本编码器设置与 UNet 不同的权重衰减。
自适应优化器
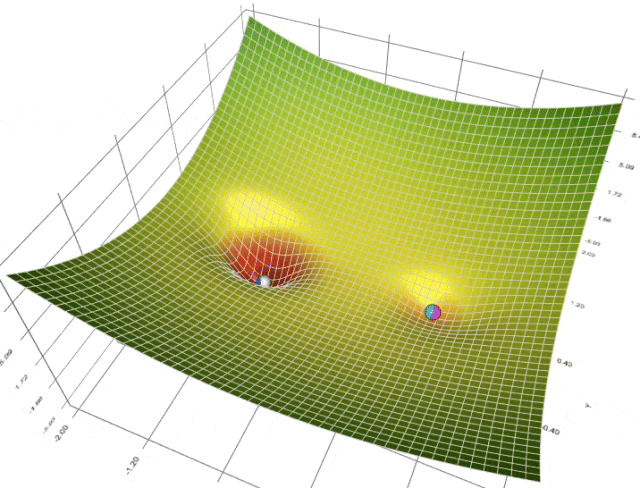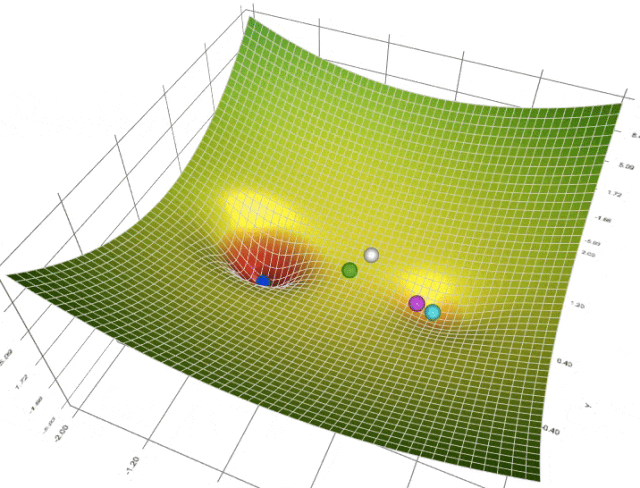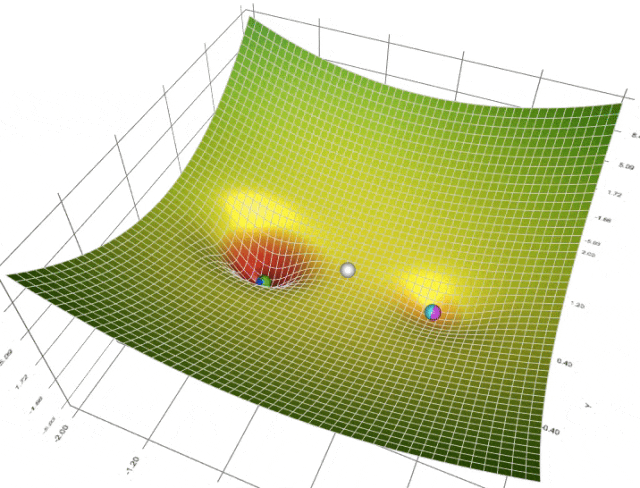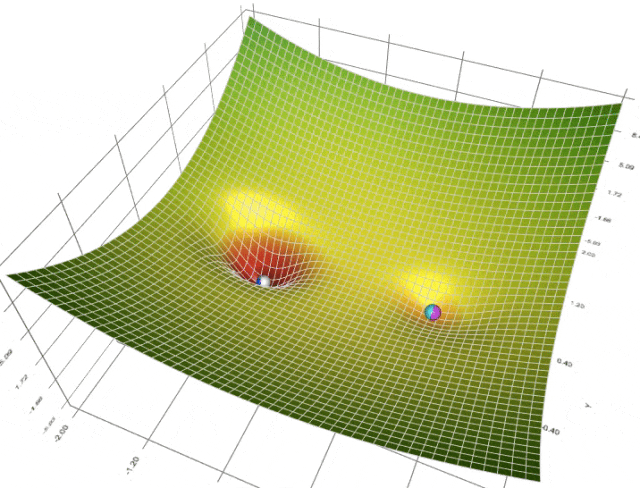
在训练或微调扩散模型 (或与此相关的任何机器学习模型) 时,我们使用优化器来引导模型依循最佳的收敛路径 - 收敛意味着我们选择的损失函数达到了最小值,我们认为损失函数达到最小值即说明模型已习得我们想要教给它的内容。当前,深度学习任务的标准 (也是最先进的) 优化器当属 Adam 和 AdamW 优化器。
然而,这两个优化器要求用户设置大量的超参 (如学习率、权重衰减等),以此为收敛铺平道路。这可能会导致我们需要不断试验各种超参,最后常常因为耗时过长而不得不采用次优超参,从而导致次优结果。即使你最后试到了理想的学习率,但如果学习率在训练期间保持为常数,仍然可能导致收敛问题。一些超参可能需要频繁的更新以加速收敛,而另一些超参的调整又不能太大以防止振荡。真正是“摁了葫芦起了瓢”。为了应对这一挑战,我们引入了有自适应学习率的算法,例如 Adafactor 和 Prodigy。这些方法根据每个参数过去的梯度来动态调整学习率,借此来优化算法对搜索空间的遍历轨迹。
我们的关注点更多在 Prodigy,因为我们相信它对 Dreambooth LoRA 训练特别有用!
训练
--optimizer="prodigy"使用 Prodigy 时,缺省学习率可以设置如下:
--learning_rate=1.0对扩散模型特别是其 LoRA 训练有用的设置还有:
--prodigy_safeguard_warmup=True
--prodigy_use_bias_correction=True
--adam_beta1=0.9
# 注意,以下超参的取值与默认值不同:
--adam_beta2=0.99
--adam_weight_decay=0.01在使用 Prodigy 进行训练时,你还可以对其他超参进行调整 (如: --prodigy_beta3 、prodig
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









