







主要梳理下字符编码的由来、常见的字符编码以及JAVA中使用的字符编码
编码的意义
- 计算机信息存储在磁盘上,而磁盘存储信息其实都是以二进制码进行存储的。编码的意义在于将磁盘中存储的二进制信息转换成文字、图片等信息以便显示。并且,编码还可以用于通信当中。一般来说,开放的操作系统,例如Linux和Windows都是采用的是ASCII编码。我们在浏览国外Web网页的时候出现乱码,就是因为编码方式不同,因此解码之后得到的便是乱码。
ASCII编码
- 早期的ASCII编码采用的是7位二进制表示一个字符,总共能表示128个字符,占一个字节,其中,最高位为0。
- 后期对ASCII编码进行了扩充,其最高位均是1。
ANSI
- 为了扩充ASCII编码,以用于显示本国的语言,不同的国家和地区制定了不同的标准,因此产生了GB2312和JIS等编码方式。这些使用两个字节来代表一个字符的各种衍生的编码方式,统称为ANSI。例如在中国ANSI表示GB2312编码,在日本ANSI则表示JIS编码。
GB2312
- 因为ASCII最多只能表示256个字符,而汉字个数远远超过了ASCII的所能表达的个数,因此中国指定了自己的编码方式,用两个字节表示一个汉字,理论上最多可表示65536个字符,在兼容了ASCII后,GB2312收录了常用的6763个汉字字符。
- GB2312采用的是二维矩阵编码法对所有的字符进行编码。矩阵大小为94x94,每个汉字对应该矩阵中的一个单元。
GBK
- 因为GB2312表达生僻汉字的能力有限,产生了GBK。GBK即是对GB2312的扩充,共收录了21003个汉字,883个符号,1894个枣子马尾,简繁体字融于一库。
- GBK采用双字节表示,总体编码范围在8140~FEFE。满足了计算机对汉字的处理需要
Unicode
- 为了同一所有的编码,产生了Unicode编码,整合了所有字符集,如GB2312、JIS、Ain等编码,是一个很大的集合。用两字节表示。虽然解决了不同字符编码之间转换的问题,但是效率也大大降低了。
UTF-8
- UTF-8是对Unicode的优化,是可变字节长度的,假设Unicode编码对一个英文字母进行编码,另外一个字节必然是0,对存储和传输来说都是很耗资源的。因此,为了提高Unicode的编码效率,就出现了UTF-8编码。UTF-8可以自动选择编码长度。
UTF-16
- UTF-16是把Unicode字符集的抽象码位映射成16位长的整数的序列。用于数据存储和传递。
Java中的编码
- 因为Unicode字符超过了65536个,其主要原因是增加了大量的汉语、日语和韩语等表意文字。
- 代码点:代码点是指与一个编码表中的某个字符对应的代码值
- 代码单元:在基本的多语言级别中,每个字符用16位表示,通常被成为代码单元。一个字符对应一个代码点,一个代码点对应一个或者多个代码单元
- Java中采用UTF-16编码,对于基本的字符,一个代码单元(16bit)就可以表示。但是对于一些辅助字符,采用一对连续的代码单元进行编码。例如数学符号Z(整数集合),代码点值是U+1D56B,代码单元为U+D835和U+DD6B。
char数据类型
- char数据类型是一个采用UTF-16编码表示Unicode代码点的代码单元,但是当用char数据类型表示辅助符号的时候会出现问题。
- 举例:
String sentence = String("Z is the set of integers") //Z此处为整数集合char ch = sentence.charAt(1) //此处ch为Z而不为空格,因为Z占两个代码单元
import java.util.*
public class Demo{
public static void main(String[] args){
//Z打印不出来 用代码单元表示 由两个代码单元\ud835和\udd6b表示
String str = "\ud835\udd6b is the set of integers";
System.out.println(str);
char charOne = str.charAt(1);
char charTwo = str.charAt(3);
System.out.printf("charOne = %c\ncharTwo = %c\n",charOne,charTwo);
}
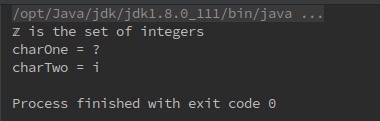
}- 运行结果
- 说明:charAt返回的是代码点,而Z是由两个代码点组成的,所以charTwo是i。charOne无法显示,因为char类型占两个字节,但是charAt(1)返回的代码点是四个字节















 1950
1950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









