






最近在学习值分布强化学习相关内容,这两天找了一篇前沿的值分布的论文阅读,论文名字叫DSAC-T:Distributional Soft Actor-Critic with Three Refinements
本文参考论文链接如下
DSAC:
DSAC-T:https://arxiv.org/abs/2310.05858
摘要(Abstract)
强化学习(reinforcement learning, RL)因其在处理复杂任务的决策控制问题时展现出强大的能力而备受关注。然而,由于强化学习领域广为人知的值过估计问题,普遍的无模型RL方法性能经常收到严重影响。针对这一问题,本文作者之前引入了DSAC算法,通过学习一个连续的高斯值分布来提高值估计的精度。但是,标准的DSAC也有其自身的缺点,包括偶尔不稳定的学习过程和必须根据不同任务奖励手动调整超参数。为了解决标准的DSAC算法的这些问题,本文进一步引进了三个重要的改进来解决这些缺点,包括expected value substituting、twin value distribution learning和variance-based critic gradient adjusting,改进后的算法被命名为DSAC-T,并在强化学习基准任务与现实轮式机器人控制任务上进行测试。
简介(Introduction)
随着神经网络技术的发展,强化学习在处理复杂任务决策控制问题时展现出了强大的能力。而在先前的无模型强化学习算法研究中,以DQN和DDPG等经典算法为例,他们经常学习到一些不切实际的高状态动作价值,导致算法的性能受到影响,这就是强化学习领域常说的值过估计问题。最早的行之有效的解决方法是Double Q-learning,其通过使用两个Q值将动作选择和动作评估解耦,在一定程度上解决过估计问题。该算法的一个与神经网络结合版本为double DQN,该方法利用一个Q网络来确定贪婪行为,而另一个Q网络被用来评估行为好坏。但这两个方法都有一个缺点:只能作用于离散的动作空间。为了将其推广到连续的动作空间,Fujimoto提出了clipped double Q-learning算法,其基于Actor-Critic框架,在两个Q估计之间的最小值中制定q值和策略函数的学习目标。后来,该方案被广泛应用于主流的RL算法中,包括TD3和SAC。
近年来,使用值分布方法来解决值过估计成为了强化学习主流设计方向。传统强化学习方法主要关注期望回报,而值分布方法通过建模完整的回报分布,提供了更丰富的信息表示。已有研究表明,这种方法不仅能更好地捕捉环境的固有不确定性,还能有效缓解强化学习中常见的过高估计问题。已有数学研究表明,值分布的方差与过高估计偏差呈反比关系,这为理解利用系统随机性和近似误差缓解过估计问题提供了理论基础。值分布方法通过学习随机回报的高斯分布来提高值估计精度,其目的是学习一个值分布函数,而不是仅仅关注它的期望值(即Q值)。
而现有的值分布算法如C51、IQN等,只能作用于离散的动作空间,为此,作者将值分布与SAC算法相结合,将值分布方法应用于连续动作空间,并引入Expected value substituting、Twin value distribution learning和Variance-based critic gradient adjusting三项改进工作,进一步提升算法性能。
最大熵强化学习框架(Maximum Entropy RL)
最大熵强化学习在优化目标中增加熵项,从而实现对探索性能的提升。策略熵定义如下:
将熵项代入到回报函数中,可以得到带熵项累计回报为:
并由此可得柔性Q函数为
策略评估:
对于给定的策略,应用贝尔曼算子
,利用以下公式可以逐渐压缩映射至其真值:
策略改进:
通过最大化策略评估压缩映射所得,可进行策略更新,策略改进公式如下:
也可以写作以下形式:
DSAC-T框架
DSAC-T是在SAC的基础上,引入值分布方法,通过对回报进行建模来解决值过估计问题。其对状态动作的回报定义如下:
该回报的期望对应于Q值,即
将最大熵强化学习中的压缩映射稍作修改,得到以下迭代公式:
将收集到的回报建模为
,表示给定(s,a)时Z值的概率密度。
对应的压缩映射定义为
,对于该值分布函数,其可用KL散度作为度量优化,其更新目标设置如下:
与大多数RL方法类似,该算法遵循一个策略评估(critic更新)和策略改进(actor更新)的循环。
策略评估:
根据上述值分布函数更新目标,构造的critic更新目标如下:
论文中将设定为高斯分布,其可表示为
。而对于
而言,
无法根据采样信息求得,该参数是未知的,因此无法对上述目标进行梯度更新。于是作者开发了另一个基于采样的更新目标版本:
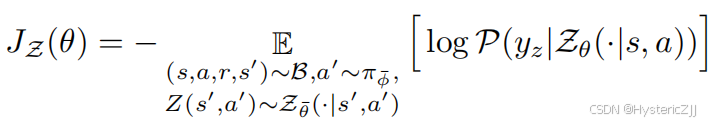
其中是采样所得的随机的回报:
根据以上信息,对基于采样的更新目标求梯度,可得:
该critic梯度由均值相关梯度和方差相关梯度两部分组成。方差相关梯度中TD误差平方的存在导致critic梯度容易爆炸,可能会导致学习不稳定。于是作者使用了clipping boundary技术,将方差相关梯度的
替换为
,将其限制在一定范围内,其定义为:
这里的b由人为给定,与奖励函数设计有关。使用此方法后的critic更新梯度被近似为
对于上述更新梯度,作者在训练中发现其偶尔会在一些任务的学习过程中不太稳定,经过分析研究得到的原因有两点:
1)在学习值分布函数过程中,由于均值相关梯度部分的会将回报的随机性传入到critic梯度中,导致偶现不稳定更新;
2)对随机TD error设置了固定的clipping boundary,该参数对任务奖励函数的量级极为敏感,因此对每个任务都要进行手动调参;
为解决以上问题,作者增加了三个重要的改进,以增强学习稳定性并降低对奖励放缩的敏感性。其在解决上述问题的之外,还实现了对算法性能的进一步提升:
1、Expected value substituting
该改进是为了纠正引起均值相关梯度的高随机性问题,DSAC-T的基本思想是用一个更稳定的值
来替换
。
的定义如下:
该方法用替换采样得到的
,由于
对应的是采样的
的期望,所以是
的期望。而
相较于
更加确定,因此该改进可以降低均值相关梯度的高随机性。
引入此项后更新梯度变为:
2、Twin value distribution learning
该改进的基本思想与clipped double Q-learning的思想相同,具体而言,DSAC-T中学习了两个值分布网络,即和
,这两个网络相互独立,分别计算其对应的Q值,不过在更新过程使用Q值时,使用算出来的较小的一个,即
使用这一取最小值的操作,可以进一步抑制过估计,甚至有产生轻微低估的倾向。对于策略学习来说,轻微的低估通常比高估更可取。这是因为被高估的行动值可能会在学习过程中传播,而被低估的行动通常会被策略所回避,从而阻止了它们的值的传播。此外,低估Q值可以作为策略优化的性能下界,有助于提高学习的稳定性。
使用该方法后,策略评估时更新目标变为:
其中,
3、Variance-based critic gradient adjusting
对于方差相关梯度的clipping boundary技术来说,其参数b由人为给定,是根据不同任务的奖励设置调试而来。使用clipping boundary的目的是防止采样得到的一些过大或者过小的罕见值对梯度更新产生较大影响。在值分布强化学习中,值分布的均值和方差是已知的,于是DSAC-T通过利用值分布所求方差信息,来实现对clip boundary的动态调整,该方法将b重新定义为:
其中ξ作为可修改的参数,通过调节该参数的大小可以调节动态调整的力度。
除此之外,对于更新目标的前半部分的均值相关梯度来说,由于其分母含有,这也可能导致该部分梯度对奖励设定的敏感性。于是该方法引入放缩系数
,定义为
将其与优化目标相乘,这样便可以将均值相关梯度约去,以改善其对奖励设定的敏感性,新的优化目标则变为:
最后,为了防止在某些任务的情况下,方差特别小导致更新目标的分母或者放缩系数
,该方法还对该放缩系数和更新梯度的分母做了微小的平移,最终critic更新梯度如下:
其中和
是很小的正数,并不会对更新梯度产生很大的影响。
以为同步速率的
和
的更新规则如下:
策略改进:
与最大熵强化学习策略目标类似,加入值分布的策略改进目标如下:
其中,温度系数设置为
这里为目标熵,
为学习速率。根据上面的讨论,标准的DSAC可以通过随机梯度下降迭代更新值分布、策略和温度参数来实现。
在使用Twin value distribution learning技术之后,由于是在两个Q网络的值里面选小的,其更新目标变更为:
以上为DSAC-T整体框架,其伪代码如下图:

实验结果
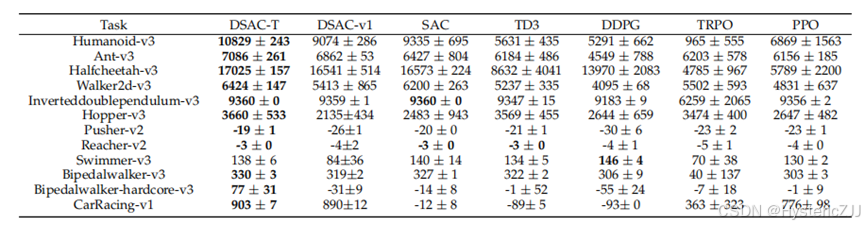
相较于主流算法,DSAC-T在强化学习典型任务测试能够超过或者匹配主流算法的性能,其平均最终回报如下图:
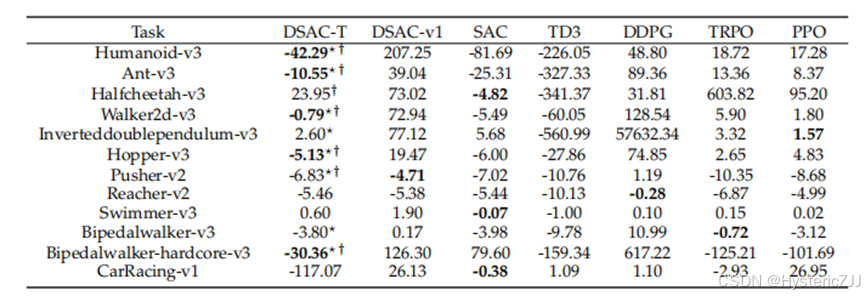
DSAC-T也对于其对值函数估计精确性做了实验验证,其性能表现出对值过估计问题很好的抑制能力,并且能做到一定程度的低估,这在强化学习算法训练是有益的,结果如下图:
作者还在现实世界控制轮式机器人轨迹跟踪任务上试验了DSAC-T的性能,篇幅也不长,这里不再整理赘述。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









