









微信公众号基础开发概知(个人理解)
![]()
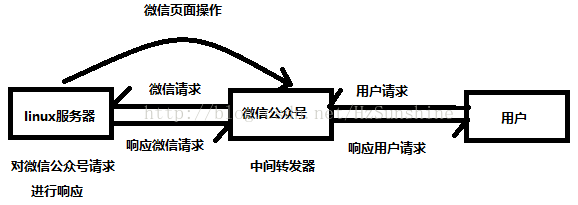
微信公众号:
把用户的请求转发给服务器,服务器对请求进行处理,然后按照微信的规则返还请求,再由公众号把结果显示给用户。(类似浏览器)
linux 服务器:
linux 服务器上的web服务才是真正的对用户请求进行正真的处理和响应。
linux服务器环境配置
python3.6 + aiohttp web框架 + mysql数据库
linux服务器aiohttp web框架
关于aiohttp web框架主体有以下部分:
1
app.py 是web服务运行主体程序。
2
orm.py 数据库操作底层程序,数据库对象映射程序。
3
models.py 定义你将会用到哪些数据库表单,并定义数据库表单中元素有哪些,数据类型是什么。
4
coroweb.py 对与aiohttp的web框架进行再封装。主要是对请求url的方法和参数进行判断和提取的一些类方法,并结合handler.py调用,来实现对与不同请求,进行对处理。
5
handler.py web 请求处理函数,定义了不同请求,用对应方法处理,并返还给用用户请求结果。
6
static 目录是存放你未来搭建网页所需前端部分的框架(css,js),此处未用未创建
(关于aiohttp web框架可学习廖雪峰Python教程实战部分 https://www.liaoxuefeng.com)
关于微信部分程序
1
微信公众号大概原理:微信公众号是当用户发送给公众号请求时,微信公众号会把用户请求包装,给web服务器发送一个对应的http请求,web会处理此请求,并把结果返还给公众号,公众号再把结果进行对应解析,发送给用户。
2
handler.py 就是把公众号发送来的请求进行处理,再返还给公众号,定义了一系列处理方法。
3
basic.py 服务器与公众号连接的验证信息设置。
4
recevie.py 对于公众号发来的请求进行解析的一些处理函数。
5
reply.py 服务器返还公众号数据的格式(将返还数据格式转换为公众号能处理的格式)
(关于微信部分学习微信公众号技术文档
https://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1472017492_58YV5)
项目 雾霾监测系统 说明
(仅说明微信公众号相关程序,不详细说明aiohttp web框架通用部分)
雾霾监测系统主要由两部分构成:
1是雾霾检测装置上传数据给服务器的数据库,服务器接收;
2是服务器数据库在发现用户请求本地雾霾数据信息时,从数据库提取对应信息并推送。
app.py 主体程序
1
#!/usr/bin/env python3
2
# -*- coding: utf8 *-
3
4
import logging
5
logging.basicConfig(level=logging.INFO)
6
7
import asyncio
8
9
from aiohttp import web
10
from aiohttp import ClientSession
11
12
from coroweb import add_routes
13
14
import orm
15
16
async def init(loop):
17
#创建数据库连接池
18
await orm.create_pool(loop=loop, host='127.0.0.1', port=3306, user='haze', password='hazepasswd', db='hazeserver')
19
app = web.Application(loop=loop)
20
add_routes(app, 'handlers')
21
# 监听0.0.0.0 IP的80端口的访问请求
22
srv = await loop.create_server(app.make_handler(), '0.0.0.0', 80)
23
logging.info('server started at http://139.199.82.84...')
24
return srv
25
26
loop = asyncio.get_event_loop()
27
loop.run_until_complete(init(loop))
28
loop.run_forever()
数据库的创建和web框架的信息对应
数据库mysql库创建(sql语句)
1
drop database if exists hazeserver;
2
3
create database hazeserver;
4
5
use hazeserver;
6
7
grant select,insert,update,delete on hazeserver.* to 'haze'@'127.0.0.1' identified by 'hazepasswd';
8
9
CREATE TABLE messages(
10
`id` VARCHAR(50) not null,
11
`addr` VARCHAR(50) not null,
12
`data` VARCHAR(50) not null,
13
`pm25` VARCHAR(20) not null,
14
`pm10` VARCHAR(20) not null,
15
PRIMARY KEY (`id`)
16
)engine=innodb default charset=utf8;
(库中存放雾霾监测点地址,时间和对应的pm2.5和pm10值,id为唯一索引)
对应
models.py 对应数据库表单的定义:
1
#!/usr/bin/env python3
2
# -*- coding: utf8 -*-
3
4
#web APP 所用到数据库表单定义
5
6
import time
7
# python中生成唯一ID库
8
import uuid
9
10
#调用orm,数据库的对象映射模块
11
from orm import Model, StringField, BooleanField, FloatField, TextField
12
13
#生成基于时间唯一的id,作为数据库表每一行主键
14
def next_id():
15
# time.time() 返回当前时间戳
16
# uuid.uuid4() 由伪随机数得到
17
return '%015d%s000' % (int(time.time() * 1000), uuid.uuid4().hex)
18
19
# 用户信息存储表
20
class Messages(Model):
21
# 表名定义
22
__table__='messages'
23
# id 为主键,唯一标识
24
id = StringField(primary_key=True, default=next_id, ddl='varchar(50)')
25
# 地点
26
addr = StringField(ddl='varchar(50)')
27
# 时间
28
data = StringField(ddl='varchar(50)')
29
# pm2.5
30
pm25 = StringField(ddl='varchar(20)')
31
# pm10
32
pm10 = StringField(ddl='varchar(20)')
雾霾检测装置上传数据给服务器的数据库,服务器接收
handlers.py
1
# 数据输入
2
@get('/messages')
3
async def messages(addr, pm25, pm10):
4
data = time.strftime('%Y-%m-%d %H:%M')
5
messages = Messages(addr = addr, data = data, pm25 = pm25, pm10 = pm10)
6
await messages.save()
7
response = '<h1>OK!!!</h1>'
8
return web.Response(body=response.encode('utf-8'), content_type='text/html')
雾霾监测传感装置通过http请求来上传数据:
格式example:
http://139.199.82.84/messages?addr=xautnew&pm25=100&pm10=200
登录到数据库查看如下
1
mysql> select * from hazeserver.messages where addr='xautnew' order by id DESC limit 0,1;
2
+----------------------------------------------------+---------+------------------+------+------+
3
| id | addr | data | pm25 | pm10 |
4
+----------------------------------------------------+---------+------------------+------+------+
5
| 0015038351446010b8df3517bd34b7ca4cd51360f71e822000 | xautnew | 2017-08-27 19:59 | 100 | 200 |
6
+----------------------------------------------------+---------+------------------+------+------+
7
1 row in set (0.00 sec)
服务器数据库在发现用户请求本地雾霾数据信息时,从数据库提取对应信息并推送
微信基本配置验证
1
# 微信基本配置验证
2
# 微信接口测试发送请求为:
3
# "GET /weixin?signature=...&echostr=...×tamp=...&nonce=... HTTP/1.0" 200 173 "-" "Mozilla/4.0"
4
@get('/weixin')
5
async def getwx(signature,echostr,timestamp,nonce):
6
# wxdict = request_query_url(request.query_string)
7
# signature = wxdict['signature']
8
# echostr = wxdict['echostr']
9
# timestamp = wxdict['timestamp']
10
# nonce = wxdict['nonce']
11
token='weixin' # 此处填写平台的token
12
# 字典序排序(以下为微信验证哈希处理)
13
tmp_list = [token, timestamp, nonce]
14
tmp_list.sort()
15
tmp_str = "%s%s%s" % tuple(tmp_list)
16
tmp_str = hashlib.sha1(tmp_str.encode('utf8')).hexdigest()
17
if tmp_str == signature:
18
return web.Response(body=echostr)
用户向微信公众号发送请求时,公众号会对服务器的web应用 以post的方式发送对应信息的xml格式的数据流的http请求,服务器处理完成后也会以xml格式进行回复。
receive.py 微信对请求xml数据进行提取
1
#!/usr/bin/env python3
2
# -*- coding: utf8 -*-
3
4
# 对微信接收的信息做提取处理
5
6
import xml.etree.ElementTree as ET
7
8
def parse_xml(web_data):
9
if len(web_data) == 0:
10
return None
11
xmlData = ET.fromstring(web_data)
12
msg_type = xmlData.find('MsgType').text
13
if msg_type == 'event':
14
return EventMsg(xmlData)
15
if msg_type == 'text':
16
return TextMsg(xmlData)
17
elif msg_type == 'image':
18
return ImageMsg(xmlData)
19
# 通用信息参数
20
class Msg(object):
21
def __init__(self, xmlData):
22
self.ToUserName = xmlData.find('ToUserName').text
23
self.FromUserName = xmlData.find('FromUserName').text
24
self.CreateTime = xmlData.find('CreateTime').text
25
self.MsgType = xmlData.find('MsgType').text
26
self.MsgId = xmlData.find('MsgId').text
27
28
# 事件参数提取
29
class EventMsg(object):
30
def __init__(self, xmlData):
31
self.ToUserName = xmlData.find('ToUserName').text
32
self.FromUserName = xmlData.find('FromUserName').text
33
self.MsgType = xmlData.find('MsgType').text
34
self.Event = xmlData.find('Event').text
35
36
# 文本消息参数
37
class TextMsg(Msg):
38
def __init__(self, xmlData):
39
Msg.__init__(self, xmlData)
40
self.Content = xmlData.find('Content').text.encode("utf-8")
41
# 图片信息参数
42
class ImageMsg(Msg):
43
def __init__(self, xmlData):
44
Msg.__init__(self, xmlData)
45
self.PicUrl = xmlData.find('PicUrl').text
46
self.MediaId = xmlData.find('MediaId').text
reply.py web 回复微信的格式
1
#!/usr/bin/env python3
2
# -*- coding: utf8 -*-
3
4
# 对微信回复信息进行格式规范
5
import time
6
7
class Msg(object):
8
def __init__(self):
9
pass
10
def send(self):
11
return "success"
12
13
class TextMsg(Msg):
14
def __init__(self, toUserName, fromUserName, content):
15
self.__dict = dict()
16
self.__dict['ToUserName'] = toUserName
17
self.__dict['FromUserName'] = fromUserName
18
self.__dict['CreateTime'] = int(time.time())
19
self.__dict['Content'] = content
20
21
def send(self):
22
XmlForm = """<xml>
23
<ToUserName><![CDATA[{ToUserName}]]></ToUserName>
24
<FromUserName><![CDATA[{FromUserName}]]></FromUserName>
25
<CreateTime>{CreateTime}</CreateTime>
26
<MsgType><![CDATA[text]]></MsgType>
27
<Content><![CDATA[{Content}]]></Content>
28
</xml>
29
"""
30
return XmlForm.format(**self.__dict)
31
32
33
class ImageMsg(Msg):
34
def __init__(self, toUserName, fromUserName, mediaId):
35
self.__dict = dict()
36
self.__dict['ToUserName'] = toUserName
37
self.__dict['FromUserName'] = fromUserName
38
self.__dict['CreateTime'] = int(time.time())
39
self.__dict['MediaId'] = mediaId
40
41
def send(self):
42
XmlForm = """
43
<xml>
44
<ToUserName><![CDATA[{ToUserName}]]></ToUserName>
45
<FromUserName><![CDATA[{FromUserName}]]></FromUserName>
46
<CreateTime>{CreateTime}</CreateTime>
47
<MsgType><![CDATA[image]]></MsgType>
48
<Image>
49
<MediaId><![CDATA[{MediaId}]]></MediaId>
50
</Image>
51
</xml>
52
"""
53
return XmlForm.format(**self.__dict)
web 关于微信的接口程序
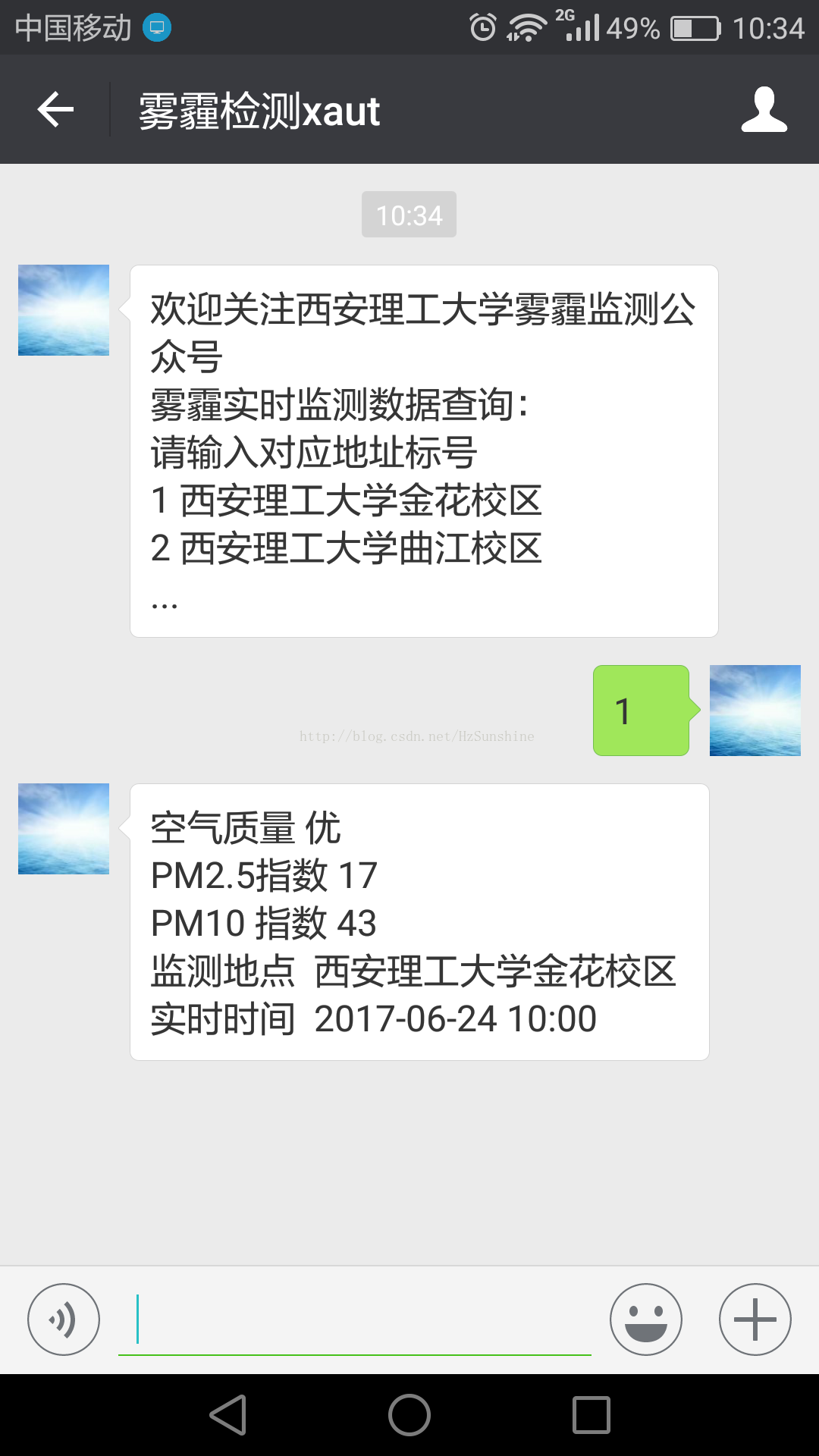
1.首次关注自动回复
2.用户发送请求,回复对应请求所需数据,其中数据是从数据库进行调用对应地址最新的1条数据信息。
1
# 微信
2
@post('/weixin')
3
async def postwx(request):
4
data = await request.text() # 读取请求body
5
recMsg = receive.parse_xml(data)
6
toUser = recMsg.FromUserName
7
fromUser = recMsg.ToUserName
8
# print(recMsg.Content.decode('ascii'))
9
if recMsg.MsgType == 'event':
10
if recMsg.Event == 'subscribe':
11
content = '''欢迎关注西安理工大学雾霾监测公众号
12
雾霾实时监测数据查询:
13
请输入对应地址标号
14
1 西安理工大学金花校区
15
2 西安理工大学曲江校区
16
...'''
17
replyMsg = reply.TextMsg(toUser, fromUser, content)
18
result = replyMsg.send()
19
elif recMsg.MsgType == 'text':
20
flag = True
21
if recMsg.Content.decode('ascii') == '1':
22
addr = 'addr="xaut"'
23
addrp = '西安理工大学金花校区'
24
elif recMsg.Content.decode('ascii') == '2':
25
addr = 'addr="xautnew"'
26
addrp = '西安理工大学曲江校区'
27
else:
28
flag = False
29
content = '''雾霾实时监测:
30
请输入对应地址标号
31
1 西安理工大学金花校区
32
2 西安理工大学曲江校区
33
...'''
34
if flag :
35
hz = await Messages.findAll(where=addr, orderBy='id desc', limit=(0, 1))
36
hzdict = dict(hz)
37
if int(hzdict['pm25']) <= 50:
38
quality = '优'
39
elif int(hzdict['pm25']) <= 100:
40
quality = '良'
41
elif int(hzdict['pm25']) <= 150:
42
quality = '轻度污染'
43
elif int(hzdict['pm25']) <= 200:
44
quality = '中度污染'
45
elif int(hzdict['pm25']) <= 300:
46
quality = '重度污染'
47
content = '''空气质量 %s
48
PM2.5指数 %s
49
PM10 指数 %s
50
监测地点 %s
51
实时时间 %s''' % (quality, hzdict['pm25'], hzdict['pm10'], addrp, hzdict['data'])
52
53
replyMsg = reply.TextMsg(toUser, fromUser, content)
54
result = replyMsg.send()
55
elif recMsg.MsgType == 'image':
56
mediaId = recMsg.MediaId
57
replyMsg = reply.ImageMsg(toUser, fromUser, mediaId)
58
result = replyMsg.send()
59
else:
60
result = 'success'
61
62
return web.Response(body=result)
测试效果图(图片是以前的)
遇到的问题:
遇到主要问题是当时雾霾检测装置上传数据,因为用的网络传输,自身服务器有带http服务,所以选择http传输最简单,再考虑下传输数据量不大,直接就是用get的方式进行访问传输数据。
参数解析当时是遇到了个坎。
查手册,http协议,了解到参数是放到了‘requst.query_string'的字符中。
开始时是一直以为原框架没有提参(其实没看懂。。),就用了一个相当相当low的方法来提参,利用正则表达式,把query_string存储的字符全读出然后切切切,分割完后存入字典。然后调用。如下程序中,把变量和值通过split切割,然后分别放入列表,再把列表转换为字典。
1
+# 导入正则库
2
+import re
3
+'''
4
+# url的请求参数解析函数
5
+def request_query_url(query_url_string):
6
+ # 正则分割把参数提取转换成列表
7
+ rq = re.split(r'[&=]', query_url_string)
8
+ # 把参数中的变量和值分别对应放入两个列表
9
+ i = 0
10
+ rq1 = []
11
+ rq2 = []
12
+ for element in rq:
13
+ if i % 2 == 0:
14
+ rq1.append(element)
15
+ else:
16
+ rq2.append(element)
17
+ i = i + 1
18
+ # 将两个列表转换为字典
19
+ rq_dict = dict(zip(rq1, rq2))
20
+ # 返回字典
21
+ return rq_dict
22
+'''
23
+# API 数据输入
24
+@get('/messages')
25
+async def messages(addr, data, pm25, pm10):
26
+ # messagesdict = request_query_url(request.query_string)
27
+ # addr = messagesdict['addr']
28
+ # data = messagesdict['data']
29
+ # pm25 = messagesdict['pm25']
30
+ # pm10 = messagesdict['pm10']
31
+ messages = Messages(addr = addr, data = data, pm25 = pm25, pm10 = pm10)
32
+ await messages.save()
33
+ response = '<h1>OK!!!</h1>'
34
+ return web.Response(body=response.encode('utf-8'), content_type='text/html')
后来,觉得不可能啊,web框架杂可能没有参数提取,就再查查,仔细再看程序。才发现,原框架确实是用了解析,不过,挺难还绕。如下是封装的参数调用。
通过装饰器来来附参数。
1
# 装饰器,给http请求添加方法和请求路径两个属性(应用于handler中)
2
# 三层嵌套装饰器,可以在decorator本身传参
3
# decorator将函数映射为http请求处理函数
4
def get(path):
5
# Define decorate @get('/path')
6
def decorator(func): # 传入参数是函数(handler定义的函数)
7
# python内置的functools.wraps装饰器作用是把装饰后的函数的__name__属性变为原始的属性
8
# 因为当使用装饰器后,函数的__name__属性会变为wrapper
9
@functools.wraps(func)
10
def wrapper(*args, **kw):
11
return func(*args, **kw)
12
wrapper.__method__ = 'GET' # 原始函数添加请求方法‘GET’
13
wrapper.__route__ = path # 原始函数添加路径
14
return wrapper
15
return decorator
类定义解析参数的处理,解析query_string直接用的是parse.parse_qs解析成参,然后通过for...in...放入字典。
1
# 作用是把handlers中url处理函数需接收的参数分析出来
2
# 从request(http请求的对象)中获取请求的参数
3
# 把request的参数放入对应的url处理函数中
4
class RequestHandler(object):
5
def __init__(self, func):
6
self._func = func
7
# 定义__call__方法可是为函数,导入request参数(对request处理)
8
async def __call__(self, request):
9
# 获取函数的需传入参数存入required_args字典{key(参数名),value(inspect.Parameter对象(包含参数信息))}
10
required_args = inspect.signature(self._func).parameters
11
logging.info('requerid args:%s' % required_args)
12
13
# 获取url请求参数存入request_data字典
14
if request.method == 'GET':
15
qs = request.query_string
16
request_data = {key:value[0] for key,value in parse.parse_qs(qs, True).items()}
17
logging.info('request form:%s' % request_data)
18
# 因为微信POST过来数据不规则,所以不在此对数据进行参数提取
19
else:
20
request_data = {}
21
22
# kw字典即是把函数需要的参数从request中提取出来
23
kw = { arg : value for arg, value in request_data.items() if arg in required_args}
24
25
# 添加request参数
26
if 'request' in required_args:
27
kw['request'] = request
28
# 检测参数表中有没有缺失
29
for key, arg in required_args.items():
30
# request参数不能为可变长参数
31
if key == 'request' and arg.kind in (arg.VAR_POSITIONAL, arg.VAR_KEYWORD):
32
return web.HTTPBadRequest(text='request parameter cannot be the var argument.')
33
# 如果参数类型不是变长列表和变长字典,变长参数是可缺省的
34
if arg.kind not in (arg.VAR_POSITIONAL, arg.VAR_KEYWORD):
35
# 如果还是没有默认值,而且还没有传值的话就报错
36
if arg.default == arg.empty and arg.name not in kw:
37
return web.HTTPBadRequest(text='Missing argument: %s' % arg.name)
38
39
logging.info('call with args: %s' % kw)
40
# 将request参数填入函数
41
try:
42
return await self._func(**kw)
43
except APIError as e:
44
return dict(error=e.error, data=e.data, message=e.message)
完整基于aiohttp web框架的微信公众号工程 https://github.com/msun1996/Hazeweb















 5117
5117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









