







 本文是关于Hadoop的学习总结,重点介绍了MapReduce的shuffle过程和combiner函数,HDFS的架构及shell命令,以及Yarn的资源管理架构和调度器。Hadoop生态圈还包括Hive和HBase,Hive提供SQL-like查询,而HBase是面向列的分布式数据库。
本文是关于Hadoop的学习总结,重点介绍了MapReduce的shuffle过程和combiner函数,HDFS的架构及shell命令,以及Yarn的资源管理架构和调度器。Hadoop生态圈还包括Hive和HBase,Hive提供SQL-like查询,而HBase是面向列的分布式数据库。
hadoop总结1 - - MapReduce和HDFS
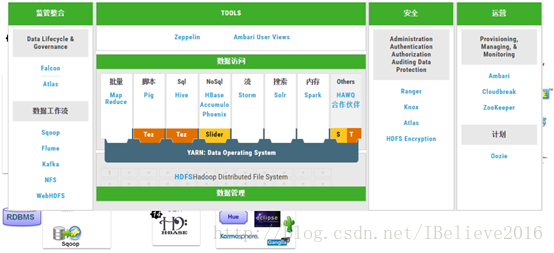
Hadoop是一个分布式的集群环境,它不需要我们深入了解许多分布式平台的细节,直接帮我们在上面搭建好了一个平台。Hadoop的核心是HDFS和MapReduce。当然,Hive, hbase, storm, spark等技术,也都是基于hadoop的。下图展示了hadoop的生态圈:
MapReduce
MapReduce是一种分布式计算框架,它实现了在多台机器上并行计算,主要由map过程和reduce过程组成。map接受输入数据,它对输入的每一条数据都进行map函数的处理,然后指定输出的键值对,将其发送到reduce端。reduce端会首先保证所有的数据都按照key进行排序,对相同的key的数据,统一做reduce函数操作。
shuffle过程
为了保证map的输出能按照key值的顺序传到reduce端,MapReduce指定了一个排序过程,这个排序过程我们成为shuffle过程。shuffle包括map端shuffle和reduce端shuffle。
在map端,map的输出不是直接写到磁盘,而是写到一个内存缓冲区做预排序,当缓冲区达到80%,就溢写到磁盘。所有溢写文件会被合并成一个已排序的输出文件。
在reduce端,只要有一个map任务完成, reduce就开始复制其输出,当复制完所有map输出后,reduce便进入合并阶段,合并后的每个文件都是相同的key值,此数据作为reduce的输入。
combiner函数
MapReduce除了map和reduce,还提供了combiner函数,它使map的输出更加“紧凑”,减少了带宽的占用。例如: map输出结果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









