









where和group by同时使用是出现数据差异具体如下:
我们使用where 判断 .financingProductId = ‘11111111111111111’
其中部分有同一个enterpriseInfoId有不同的的数据,不同的financingProductId (点题)
两种实现方式
一、在where和group by同时使用来查询数据
SELECT
c.enterpriseInfoId,c.financingProductId
FROM
c_cooperative_organization c
WHERE
c.financingProductId = '11111111111111111'
GROUP BY c.enterpriseInfoId
二、group by得到的结果集作为再进行where判断
SELECT * FROM(
SELECT
c.enterpriseInfoId,c.financingProductId
FROM
c_cooperative_organization c
GROUP BY c.enterpriseInfoId
) d where d.financingProductId = '11111111111111111';
结论:第一种方式的结果会比第二种方式大
等价于用having
SELECT
c.enterpriseInfoId,c.financingProductId
FROM
c_cooperative_organization c
GROUP BY c.enterpriseInfoId HAVING financingProductId = '11111111111111111'
分析
我们先看sql执行顺序,
第一种方式的执行顺序
先进行条件判断再进行分组
第二种方式的执行顺序
先进行分组再进行条件判断
咋眼一看只是顺序调换,如同乘除顺序不会影响,其实不然
通过求数据集的差集来判断有哪些数据数多出来的
where xxx in not(效率低,生成环境不建议使用)
SELECT b.enterpriseInfoId FROM (
SELECT
c.enterpriseInfoId,c.financingProductId
FROM
c_cooperative_organization c
WHERE
c.isOldVersion = '0' and c.financingProductId = '11111111111111111'
GROUP BY c.enterpriseInfoId
) b
where b.enterpriseInfoId not in
(SELECT d.enterpriseInfoId FROM(
SELECT
c.enterpriseInfoId,c.financingProductId
FROM
c_cooperative_organization c
WHERE
c.isOldVersion = '0'
GROUP BY c.enterpriseInfoId
) d where d.financingProductId = '11111111111111111'
)
得到4条
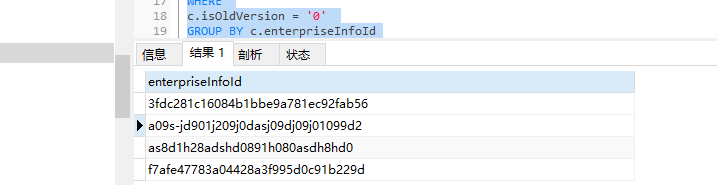
在看看其中一条的情况
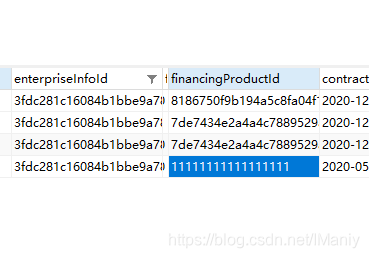
出现了如上上点题的情况,不同的financingProductId (点题)
细细分析
第一种方式为什么多,是因为在分组之前我们拿到了一条数据如下,再分组也有这数据了

第二种方式,它先分组,它取的可能就不是上面数据,可能是下面数据,这里就少了这数据了。

所以造成了,数据差异。
建议使用Having
我们如果就是想查询分组时,想要直接显示某个值,该值通过参数传进来。















 9110
9110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









