







一、要求:查询massage表下的content字段内容(第一个字符到第10个字符)
使用需求:新闻信息内容等字符串非常长的时候,要进行信息列表预览,不需要展示全部内容。
如图所示:

select substring(content,1,10) as content from massage
sql执行结果:

二、在数据库表中随机抽取n条数据
使用需求:随机推荐等随机问题可以使用
随机抽取5条数据
select * from table order by rand() limit 5;
三、sql语句中进行判断
使用需求:表中有a、b、c三列,取三列中最小的
select (case when a>b then a else b end) FROM abc
建议 as xxx 方便拿值
select case when a>b then a else b end as name FROM abc
使用语句:IF(expr1,expr2,expr3)
expr1 是TRUE (expr1 <> 0 and expr1 <> NULL),则 IF()的返回值为expr2; 否则返回值则为 expr3
select IF(a<b,a,IF(b<c,b,c))
from abc
在补充个知识点
IFNULL(expr1,expr2)
假如expr1 不为 NULL,则 IFNULL() 的返回值为 expr1; 否则其返回值为 expr2。IFNULL()的返回值是数字或是字符串,具体情况取决于其所使用的语境。
四、分类统计数量sql
如表中type字段有n种值,分别统计n种值的数据数量。
select count(*) as count,type from user group by type
@Query(nativeQuery=true,value="select status,count(*) as num from c_apply_equity_fund_info GROUP BY status")
public List<Object> findGroupByStatus();
案例:

需要查询到数据如下:
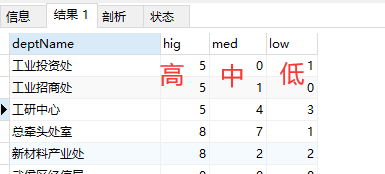
第一种连表统计查询SQL:
SELECT
a.deptName,
( SELECT COUNT( 1 ) AS hig FROM c_risk_occur b WHERE b.riskLevel = '高' AND b.deptName = a.deptName ) AS hig,
( SELECT COUNT( 1 ) AS med FROM c_risk_occur b WHERE b.riskLevel = '中' AND b.deptName = a.deptName ) AS med,
( SELECT COUNT( 1 ) AS low FROM c_risk_occur b WHERE b.riskLevel = '低' AND b.deptName = a.deptName ) AS low
FROM
c_risk_occur a
GROUP BY
deptName ORDER BY deptName
第二种判断求和SQL(通过判断把一条数据根据是否满足条件 变为0或1,再计算)
SELECT
deptName,
SUM( CASE WHEN riskLevel = '高' THEN 1 ELSE 0 END ) AS hig,
SUM( CASE WHEN riskLevel = '中' THEN 1 ELSE 0 END ) AS med,
SUM( CASE WHEN riskLevel = '低' THEN 1 ELSE 0 END ) AS low
FROM
c_risk_occur
GROUP BY
deptName
运行速度:第一种 远小于 第二种
数据800条,第一种 1.5s ,第二种 0.09s
五、项目表数据+其下面的模块表分数字段的平均值
如:一个项目表下面有4个模块,模块中的分数分别为60,50,89,53,要实现的样子是
项目表字段+平均分字段
select n.*,m.avgscore from (select a.id,avg(b.grade) as avgscore from project a left join supervision b on a.id=b.project_id where b.status=1 GROUP BY a.id) m left join project n on m.id=n.id;
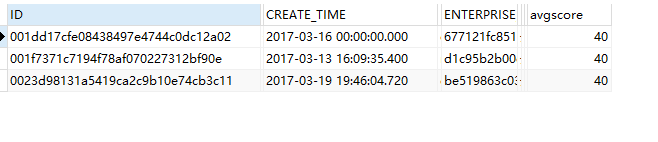
简单的求平均值:
select avg(grade) as avgscore from c_process_supervision where status=1 group by PROJECT_ID
六、十行数据尽量均分为三组
SQL Server NTILE()函数
SELECT
v,
NTILE (3) OVER (
ORDER BY v
) buckets
FROM
sales.ntile_demo
SQL Server NTILE()函数简介SQL Server NTILE()是一个窗口函数,它将有序分区的行分配到指定数量的大致相等的组或桶中。 它从一个开始为每个组分配一个桶号。 对于组中的每一行,NTILE()函数分配一个桶号,表示该行所属的组。
NTILE()函数的语法如下:
NTILE(buckets) OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)

SQL
在上面语法中,
buckets - 行划分的桶数。 存储桶可以是表达式或子查询,其计算结果为正整数。 它不能是一个窗口功能。PARTITION BY子句将结果集的行分配到应用了NTILE()函数的分区中。ORDER BY子句指定应用NTILE()的每个分区中行的逻辑顺序。
如果行数不能被桶整除,则NTILE()函数返回两个大小的组,它们的差值为1。 较大的组总是按照OVER()子句中ORDER BY指定的顺序位于较小的组之前。
另一方面,如果行的总数可以被桶整除,则该函数在桶之间均匀地划分行。
java算法实现NTILE()函数
//尽量均分
public static int[] matchExpert2(int total,int count){
int anArray[] = new int[count];
if(total % count == 0){
int recordExpert = total / count;
for(int expertNum:anArray){
expertNum = recordExpert;
System.out.println(expertNum);
}
}else {
int recordCount1 = (total / count)+1;
int n=0;//n表示组中记录数为recordCount1的最大专家数.
int m=recordCount1*n;
while (((total-m) % (count -n )) !=0){
n++;
m=recordCount1*n;
anArray[n-1] = recordCount1;
System.out.println(recordCount1);
}
int recordCount2 = (total - m) /(count-n);
for (int i=n;i <count;i++){
anArray[i] = recordCount2;
System.out.println(recordCount2);
}
//将前n个组的记录数设为recordCount1.
//将n+1个至后面所有组的记录数设为recordCount2.
}
System.out.println(Arrays.toString(anArray));
return anArray;
}
七、数据库随机应用——sql server的随机函数newID()和RAND()
随机函数newID()
SELECT * FROM user ORDER BY NEWID()
–随机排序
SELECT TOP 10 * FROM user ORDER BY NEWID()
–从Orders表中随机取出10条记录
随机函数:rand()
1、
A:select floor(rand()*N) —生成的数是这样的:12.0
B:select cast( floor(rand()*N) as int) —生成的数是这样的:12
2、
A:select ceiling(rand() * N) —生成的数是这样的:12.0
B:select cast(ceiling(rand() * N) as int) —生成的数是这样的:12
其中里面的N是一个你指定的整数,如100,可以看出,两种方法的A方法是带有.0这个的小数的,而B方法就是真正的整数了。
大致一看,这两种方法没什么区别,真的没区别?其实是有一点的,那就是他们的生成随机数的范围:
方法1的数字范围:0至N-1之间,如cast( floor(rand()*100) as int)就会生成0至99之间任一整数
方法2的数字范围:1至N之间,如cast(ceiling(rand() * 100) as int)就会生成1至100之间任一整数
八、查出每门课都大于60的学生的姓名
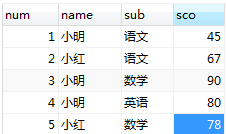
select name from score group by name having min(sco)>=60
查询平均分大于80的学生姓名
select name from score1 GROUP BY name having avg(sco)>80
九、TO_DAYS函数来比较时间
select * from lito where to_days(now())-to_days(create_time)<1
十、 mysql 查询当天、本周,本月,上一个月的数据
今天
select * from 表名 where to_days(时间字段名) = to_days(now());
昨天
SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) = 1
近7天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名)
近30天
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名)
本月
SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) , '%Y%m' )
上一月
SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1
查询本季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(now());
查询上季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(DATE_SUB(now(),interval 1 QUARTER));
查询本年数据
select * from `ht_invoice_information` where YEAR(create_date)=YEAR(NOW());
查询上年数据
select * from `ht_invoice_information` where year(create_date)=year(date_sub(now(),interval 1 year));
查询当前这周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now());
查询上周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now())-1;
查询上个月的数据
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(DATE_SUB(curdate(), INTERVAL 1 MONTH),'%Y-%m')
select * from user where DATE_FORMAT(pudate,'%Y%m') = DATE_FORMAT(CURDATE(),'%Y%m') ;
select * from user where WEEKOFYEAR(FROM_UNIXTIME(pudate,'%y-%m-%d')) = WEEKOFYEAR(now())
select * from user where MONTH(FROM_UNIXTIME(pudate,'%y-%m-%d')) = MONTH(now())
select * from user where YEAR(FROM_UNIXTIME(pudate,'%y-%m-%d')) = YEAR(now()) and MONTH(FROM_UNIXTIME(pudate,'%y-%m-%d')) = MONTH(now())
select * from user where pudate between 上月最后一天 and 下月第一天
查询当前月份的数据
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(now(),'%Y-%m')
查询距离当前现在6个月的数据
select name,submittime from enterprise where submittime between date_sub(now(),interval 6 month) and now();
SQL server判断是否本年度
select count(*) from C_PROJECT_APPLY_FLOW where datediff(year,createTime,2019)=0
SQL server当前时间
DATEPART(YYYY,GETDATE())
SQL server 格式化时间
convert(varchar(10),字段名,转换格式)
SELECT CONVERT(varchar(100), GETDATE(), 0): 05 16 2011 10:57AM
SELECT CONVERT(varchar(100), GETDATE(), 1): 05/16/11
SELECT CONVERT(varchar(100), GETDATE(), 2): 11.05.16
SELECT CONVERT(varchar(100), GETDATE(), 3): 16/05/11
SELECT CONVERT(varchar(100), GETDATE(), 4): 16.05.11
SELECT CONVERT(varchar(100), GETDATE(), 5): 16-05-11
SELECT CONVERT(varchar(100), GETDATE(), 6): 16 05 11
SELECT CONVERT(varchar(100), GETDATE(), 7): 05 16, 11
SELECT CONVERT(varchar(100), GETDATE(), 8): 10:57:46
SELECT CONVERT(varchar(100), GETDATE(), 9): 05 16 2011 10:57:46:827AM
SELECT CONVERT(varchar(100), GETDATE(), 10): 05-16-11
SELECT CONVERT(varchar(100), GETDATE(), 11): 11/05/16
SELECT CONVERT(varchar(100), GETDATE(), 12): 110516
SELECT CONVERT(varchar(100), GETDATE(), 13): 16 05 2011 10:57:46:937
SELECT CONVERT(varchar(100), GETDATE(), 14): 10:57:46:967
SELECT CONVERT(varchar(100), GETDATE(), 20): 2011-05-16 10:57:47
SELECT CONVERT(varchar(100), GETDATE(), 21): 2011-05-16 10:57:47.157
SELECT CONVERT(varchar(100), GETDATE(), 22): 05/16/11 10:57:47 AM
SELECT CONVERT(varchar(100), GETDATE(), 23): 2011-05-16
SELECT CONVERT(varchar(100), GETDATE(), 24): 10:57:47
SELECT CONVERT(varchar(100), GETDATE(), 25): 2011-05-16 10:57:47.250
SELECT CONVERT(varchar(100), GETDATE(), 100): 05 16 2011 10:57AM
SELECT CONVERT(varchar(100), GETDATE(), 101): 05/16/2011
SELECT CONVERT(varchar(100), GETDATE(), 102): 2011.05.16
SELECT CONVERT(varchar(100), GETDATE(), 103): 16/05/2011
SELECT CONVERT(varchar(100), GETDATE(), 104): 16.05.2011
SELECT CONVERT(varchar(100), GETDATE(), 105): 16-05-2011
SELECT CONVERT(varchar(100), GETDATE(), 106): 16 05 2011
SELECT CONVERT(varchar(100), GETDATE(), 107): 05 16, 2011
SELECT CONVERT(varchar(100), GETDATE(), 108): 10:57:49
SELECT CONVERT(varchar(100), GETDATE(), 109): 05 16 2011 10:57:49:437AM
SELECT CONVERT(varchar(100), GETDATE(), 110): 05-16-2011
SELECT CONVERT(varchar(100), GETDATE(), 111): 2011/05/16
SELECT CONVERT(varchar(100), GETDATE(), 112): 20110516
SELECT CONVERT(varchar(100), GETDATE(), 113): 16 05 2011 10:57:49:513
SELECT CONVERT(varchar(100), GETDATE(), 114): 10:57:49:547
SELECT CONVERT(varchar(100), GETDATE(), 120): 2011-05-16 10:57:49
SELECT CONVERT(varchar(100), GETDATE(), 121): 2011-05-16 10:57:49.700
SELECT CONVERT(varchar(100), GETDATE(), 126): 2011-05-16T10:57:49.827
SELECT CONVERT(varchar(100), GETDATE(), 130): 18 ??? ??? 1427 10:57:49:907AM
SELECT CONVERT(varchar(100), GETDATE(), 131): 18/04/1427 10:57:49:920AM
如果判断是否本月year改称month,本日day
十一、查询一个最近的一个组所有数据
如查询最近的一个时间点的所有省份数据

SELECT PROVINCE_NAME,SUM(PEOPLE_NUM) PEOPLE_NUM FROM T_TELECOM_SCENIC_PRO_MONTH WHERE DATE_STR >= CONCAT(DATE_FORMAT(NOW(),'%Y'),'01010000') AND DATE_STR <= CONCAT(DATE_FORMAT(NOW(),'%Y'),'12312359') AND PROVINCE_ID != '31' GROUP BY PROVINCE_ID ORDER BY PEOPLE_NUM DESC
可以通过group by PROVINCE_ID 为分组对象,查组中最新的一个
十二、查询在一个部门下的所以用户,已逗号相隔的字符串显示
结果如下:
0d2868cb9dfb4f1,2a4b73b5c0434e,ad4e9356abbaf132bca4,e256ac680caa45d48
sql
select GROUP_CONCAT(id SEPARATOR ',') as ids from s_user where sign_id = 'e256ac680caa45dcbff339edd96efd48'
利用了GROUP_CONCAT()函数,其他应用如下
每个名字都只出现一次,又能够显示所有的名字相同的人的id呢?——使用group_concat()
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
select name, GROUP_CONCAT(id order by id desc SEPARATOR ',') as ids from s_user group by name
在上面基础上去重,加上关键字 DISTINCT
如
group_concat( DISTINCT (case when delivery_type='1' then delivery_name else null end) SEPARATOR ',') as delivery_names
查询重复数据
查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断
select * from people
where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1)
十三 删除重复行(自连接)
数据中用重复的name、price,但id不一样的数据,需要删除重复数据
-- 用于删除重复行的SQL 语句(1) :使用极值函数
DELETE FROM Products1 P1
WHERE rowid < (
SELECT MAX(P2.rowid)
FROM Products1 P2
WHERE P1.name = P2. name
AND P1.price = P2.price);
-- 用于删除重复行的SQL 语句(2) :使用非等值连接
DELETE FROM Products1 P1
WHERE EXISTS (
SELECT *FROM Products1 P2
WHERE P1.name = P2.name
AND P1.price = P2.price
AND P1.rowid < P2.rowid);
用于查找价格相等但商品名称不同(自连接)
-- 用于查找价格相等但商品名称不同的记录的SQL 语句
SELECT DISTINCT P1.name, P1.price
FROM Products P1, Products P2
WHERE P1.price = P2.price
AND P1.name <> P2.name;
分数排名
分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
SELECT s1.Score,(SELECT COUNT(distinct(s2.Score))
FROM Scores s2 WHERE s1.Score < s2.Score) + 1 AS Rank
FROM Scores s1
ORDER BY s1.Score DESC;
查找所有至少连续出现三次的数字(利用变量)
三个自连接可以查询到,但效率不高。
利用用户变量实现对连续出现的值进行计数。 两个变量,一个用于判断,一个用于计数;
select distinct Num as ConsecutiveNums
from (
select Num,
case
when @prev = Num then @count := @count + 1
when (@prev := Num) is not null then @count := 1
end as CNT
from Logs, (select @prev := null,@count := null) as t
) as temp
where temp.CNT >= 3
存在量词处理
select distinct num as ConsecutiveNums
from Logs l1 where
exists( select 1 from logs l2 where l1.num = l2.num and l1.id = l2.id-1)
and exists( select 1 from logs l2 where l1.num = l2.num and l1.id = l2.id-2)
统计数据(面试题,我当时发懵,count函数写成sum一直报错,造化弄人)
对,day_id,统计result为fail和success

结果如下
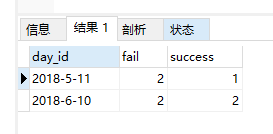
SQL
SELECT
a.day_id,
( SELECT COUNT( * ) AS fail FROM test b WHERE b.result = 'fail' AND b.day_id = a.day_id ) AS fail,
( SELECT COUNT( * ) AS fail FROM test b WHERE b.result = 'success' AND b.day_id = a.day_id ) AS success
FROM
test a
GROUP BY
day_id
其实很简单的,不应该不应该。
十四 sqlserver,oracle,mysql字符串拼接
sqlserver:
select '123'+'456';
oracle:
select '123'||'456' from dual;
或
select concat('123','456') from dual;
mysql:
select concat('123','456');
注意:SQL Server中没有concat函数(SQL Server 2012已新增concat函数)。oracle和mysql中虽然都有concat,但是oracle中只能拼接2个字符串,所以建议用||的方式;mysql中的concat则可以拼接多个字符串。
通过字符串拼接来同步数据
mysql为例
SELECT a.create_time ,b.create_time ,concat('UPDATE t_two set create_time = ''',a.create_time,''' where id =' , a.id) as tempsql
FROM t_one a LEFT JOIN t_two b on a.key = b.value
生成tempsql语句

复制再执行
十五、两表中数据同步
sql 两表查询后 更新某表中部分字段
update t_one a,t_two b SET b.create_time = a.create_time where a.key=b.value
inner join
update t_one a inner join t_two b on a.key=b.value SET b.create_time = a.create_time
十六、查表字段和注释
SELECT COLUMN_NAME as field_name , COLUMN_COMMENT as field_note FROM information_schema.COLUMNS WHERE TABLE_NAME = ?1 and TABLE_SCHEMA = schema
十七、group by之后取每个分组最新的一条
思路:
1、首先,使用GROUP_CONCAT函数 他可以设置分组的条件 在这里我们需要的条件就是时间最新的一条
select SUBSTRING_INDEX(group_concat(id order by `createTime` desc),',',1) from v_merchantsInfo_node GROUP BY merchantsInfoId
2、用的 in 查询 把数据全部查询出来
select * from v_merchantsInfo_node as t where t.id in (select SUBSTRING_INDEX(group_concat(id order by `createTime` desc),',',1) from v_merchantsInfo_node GROUP BY merchantsInfoId
相关知识点:
substring_index(str,delim,count)
str:要处理的字符串
delim:分隔符
count:计数
例如:str=www.wikibt.com
substring_index(str,'.',1)
结果是:www
substring_index(str,'.',2)
结果是:www.wikibt
也就是说,如果count是正数,那么就是从左往右数,第N个分隔符的左边的全部内容。相反,如果是负数,那么就是从右边开始数,第N个分隔符右边的所有内容,如:
substring_index(str,'.',-2)
结果为:wikibt.com
十八、多种方式实现连表查询去除重复
1 DISTINCT
select DISTINCT(id) from a left join b on a.id=b.aid DISTINCT查询结果是 第一个表唯一的数据 重复的结果没显示出来
SELECTDISTINCT(a.id), a.*, b.type FROM table1 aLEFTJOIN table2 b ON a.sponsor_id = b.sponsor_id WHERE b.type = 1AND a.sponsor_id = 10;
SELECTDISTINCT a.*, b.type FROM table1 aLEFTJOIN table2 b ON a.sponsor_id = b.sponsor_id WHERE b.type = 1AND a.sponsor_id = 10;
2 GROUP BY
select * from a leftjoin(selectidfrom b groupbyid) as b on a.id=b.aid拿出b表的一条数据关联 使A表与B表所显示的记录数为 1:1对应关系。
SELECT a.*, b.type FROM table1 aLEFTJOIN ( SELECT * FROM table2 GROUPBY sponsor_id ) AS b ON a.sponsor_id = b.sponsor_id WHERE b.type = 1AND a.sponsor_id = 10;
3 max取唯一
select * from a leftjoin (selectmax(id) fromtablegroupbyid) as b on a.id=b.aid 拿出b表的最后一条数据关联
SELECT a.*, b.type FROM table1 aLEFTJOIN ( SELECTMAX( kid ), type, sponsor_id FROM table2 GROUPBY sponsor_id ) AS b ON a.sponsor_id = b.sponsor_id WHERE b.type = 1AND a.sponsor_id = 10;
4 IN巧用
SELECT a.* FROM table1 a WHERE a.sponsor_id IN ( SELECT sponsor_id FROM table2 WHEREtype = 1AND sponsor_id = 10 );
SELECT a.*,1FROM table1 a WHERE a.sponsor_id IN ( SELECT sponsor_id FROM table2 WHEREtype = 1AND sponsor_id = 10 );
十九、根据部门分组,显示每个部门的工资等级
SELECT *, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee
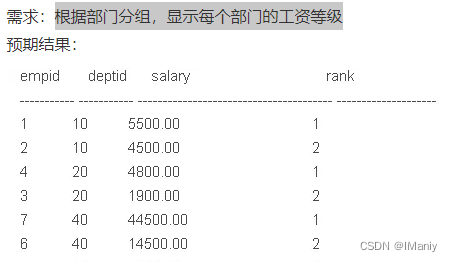
知识补充:
row_number()从1开始,为每一条分组记录返回一个数字,这里的ROW_NUMBER() OVER (ORDER BY xlh DESC) 是先把xlh列降序,再为降序以后的没条xlh记录返回一个序号。
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)
二十、把一个表中的值,改成另一个表中的值,两个表都有唯一的ID,并且通过ID相同来更改
UPDATE t_chat_message_record
JOIN t_assistant_chat ON t_chat_message_record.id = t_assistant_chat.record_id
SET t_chat_message_record.theme_type = t_assistant_chat.type















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









