






Qibocal使用Qibo和Qibolab提供量子表征验证和验证协议。
Qibocal的主要特点:
- 自动化的校准程序。
- 使用runcard的声明性输入。
- 生成报告。
qibocal需要在qibolab的基础上进行操作
下图是Qibo“生态系统”的主要组成部分,第一个组件是基于Python 3的语言API,它定义了用于开发量子应用、模型和新算法的接口。第二个和第三个组件提供了大量的模型和算法代码库,并提供了代码示例和分步教程。第四个组件提供了实验室管理和量子硬件控制的几种工具。Qibo具有即插即用机制,专门针对多线程CPU、单GPU和多GPU等不同经典硬件配置的量子仿真代码,以及类似的量子硬件控制代码,从超导到包括FPGA和AWG设备在内的离子阱技术。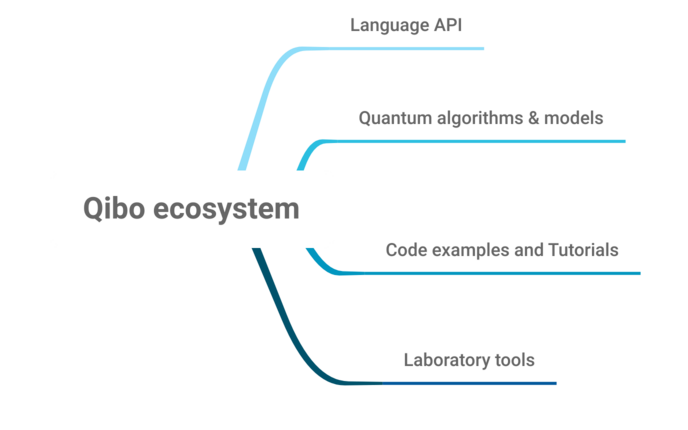
Qibolab支持不同的仪器,包括本地振荡器,qblox和FPGA。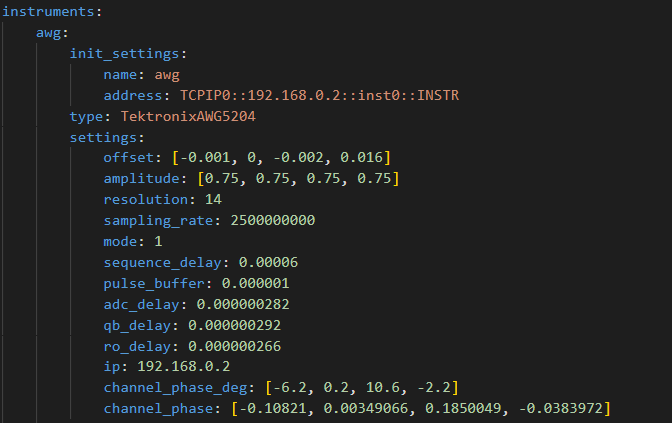
一、搭建环境
利用Anaconda创建虚拟环境qibo
激活虚拟环境qibo
根据说明步骤clong和install: qibo、qibolab以及qibocal
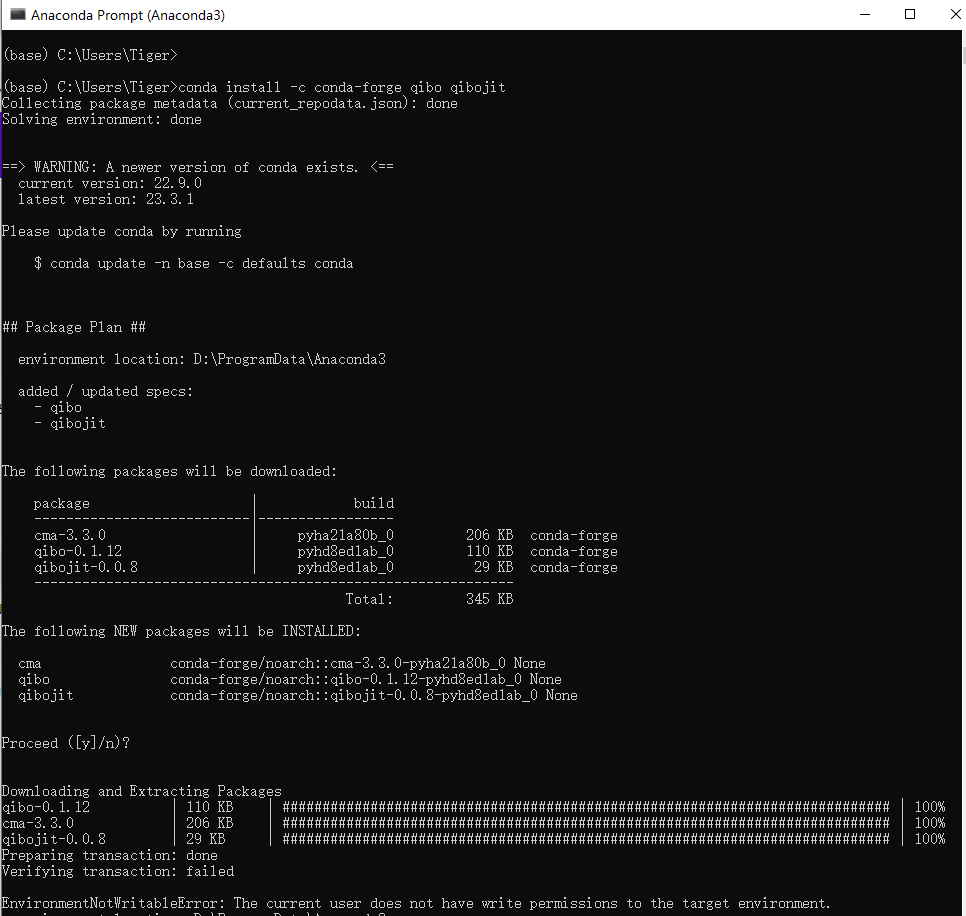
使用conda命令安装conda install -c conda-forge qibo qibojit
出现的错误:
ERROR: pip’s dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. qibocal 0.0.2 requires qibolab<0.0.3,>=0.0.2, but you have qibolab 0.0.3 which is incompatible.
pip的依赖解析器目前没有考虑到所有已安装的包。这种行为是以下依赖关系冲突的根源。Qibocal 0.0.2需要qibolab 0.0.3=0.0.2,但你有qibolab 0.0.3是不兼容的。

二、工作示例
利用Qibocal进行谐振腔光谱分析
1.RunCard编写
在qibocal中,我们采用声明式编程范式,即用户应该直接指定他想做什么,而不关心底层实现。
首先,用户需要指定一些全局参数,包括:
platform :平台名。
backend一节解释了Qibo提供的不同计算引擎,包括numpy、TensorFlow和qibojit。用户可以使用qibo.set_backend()方法在这些后端之间切换。platform参数用于为qibojit后端选择特定的平台,例如cuquantum或cupy。“platform”是指qibojit后端运行的特定硬件或软件环境。不同的平台可能具有不同的性能特征或需求,因此为用户的特定用例选择适当的平台非常重要。
runcard :平台runcard的路径(可选)。如果没有指定,将使用qibolab中可用的平台运行卡。
qubits :正在校准的量子位。
format :存储测量值的格式。
在qibocal中,所有的数据都使用qibocal.data. dataset存储,它提供了不同的数据存储格式,包括pickle和csv。
pickle模块是Python专用的持久化模块(数据持久化保存),可以持久化包括自定义类在内的各种数据,比较适合Python本身复杂数据的存贮。但是持久化后的字串是不可认读的,并且只能用于Python环境,不能用作与其它语言进行数据交换。
platform: tii5q
runcard: <path_to_platform_runcard>
qubits: [0]
format: pickle
actions:
first_routine:
arg1: ...
arg2: ...
second_routine:
arg1: ...
arg2: ...
platform: tii1q
qubits: [0]
format: csv
actions:
resonator_spectroscopy:
lowres_width: 5_000_000
lowres_step: 2_000_000
highres_width: 1_500_000
highres_step: 200_000
precision_width: 1_500_000
precision_step: 100_000
software_averages: 1
points: 5
2.运行例程
为了运行runcard中指定的所有校准例程,Qibocal使用qq命令,如果指定<output_folder>,则结果将保存在其中,否则qq将自动创建一个包含当前日期和用户名的默认文件夹。qq <runcard> -o <output_folder>
qq将在执行命令的同一目录中创建一个文件夹,其默认名称为YYYY-MM-DD-xxx-username,其中xyz是从000开始的三个整数,username是在QRC集群上启动作业的用户名。如果已经存在同名文件夹,程序将尝试创建xyz组合加1的文件夹,直到创建一个新文件夹。
qq : 是qibocal中的基本命令。它可以从命令行启动,使用:qq <path_to_runcard>,其中<path_to_runcard>是runcard的相对路径,这是一个yaml文件,包含执行qq所需的所有指令。
qq D:\qibo\qibocal\runcards\niGSC.yml -o dummy5
该文件是一个YAML格式的配置文件,用于定义量子计算机中的一些操作。具体来说,这个文件定义了一个名为“resonator_spectroscopy”的操作,它的参数如下:
- freqwidth: 频率宽度,单位为Hz,这里设置为30,000,000Hz。
- freqstep: 频率步长,单位为Hz,这里设置为1,000,000Hz。
- softwareaverages: 软件平均次数,这里设置为1。
- points: 测量点数,这里设置为5。
这个操作的作用是对谐振腔进行光谱测量,即测量谐振腔的共振频率。由于设置的参数是“wide”,因此这个操作的频率范围比较宽,可以覆盖较大的频率范围。该操作包括在频率范围内进行多次测量,以便在每个频率点上测量信号的强度。具体来说,该操作将在10 MHz的频率范围内进行5个测量,每个测量的频率步长为200 kHz。此外,该操作还定义了最小和最大的衰减值,以及衰减值的步长。最后,该操作将进行1次软件平均。
第二个是rabi_pulse_amplitude操作,该操作涉及将 Rabi 脉冲应用于量子比特,并测量结果状态。代码块中指定的参数如下:
- pulse_amplitude_start:Rabi 脉冲的起始幅度。
- pulse_amplitude_end:Rabi 脉冲的结束幅度。
- pulse_amplitude_step:每个幅度值之间的步长。
- software_averages:要执行的软件平均数。
- relaxation_time:在执行测量之前等待的时间,以使量子比特放松。
- nshots:每个幅度值要测试的次数。
总体而言,该操作用于校准量子比特的 Rabi 频率,这是量子计算中的重要参数。
YAML文件中的software_averaging参数用于指定重复给定实验的次数,并对结果求平均值。在所提供的代码块中,对几个实验(包括resonator_spectroscopy, qubit_spectroscopy和rabi_pulse_amplitude)将software_average设置为1。这意味着每个实验将运行一次,结果将不会平均。如果想增加重复实验和平均实验的次数,可以简单地将software_averaging的值更改为更大的数字。例如,如果想运行10次谐振光谱实验并对结果进行平均,可以将software_平均化参数更改为10。
3.可视化数据
Qibocal通过qq-live命令提供了实时绘图的可能性,qq-live 就是专门用于实时绘图的命令。qq-live < output_folder >
qq-live -p 8085
将以本地模式启动flask服务器。通过打开相应的网页,你会看到一个由qq生成的所有文件夹的列表,在qq-live执行的目录中。如果你选择其中一个,你会看到qq生成的页面。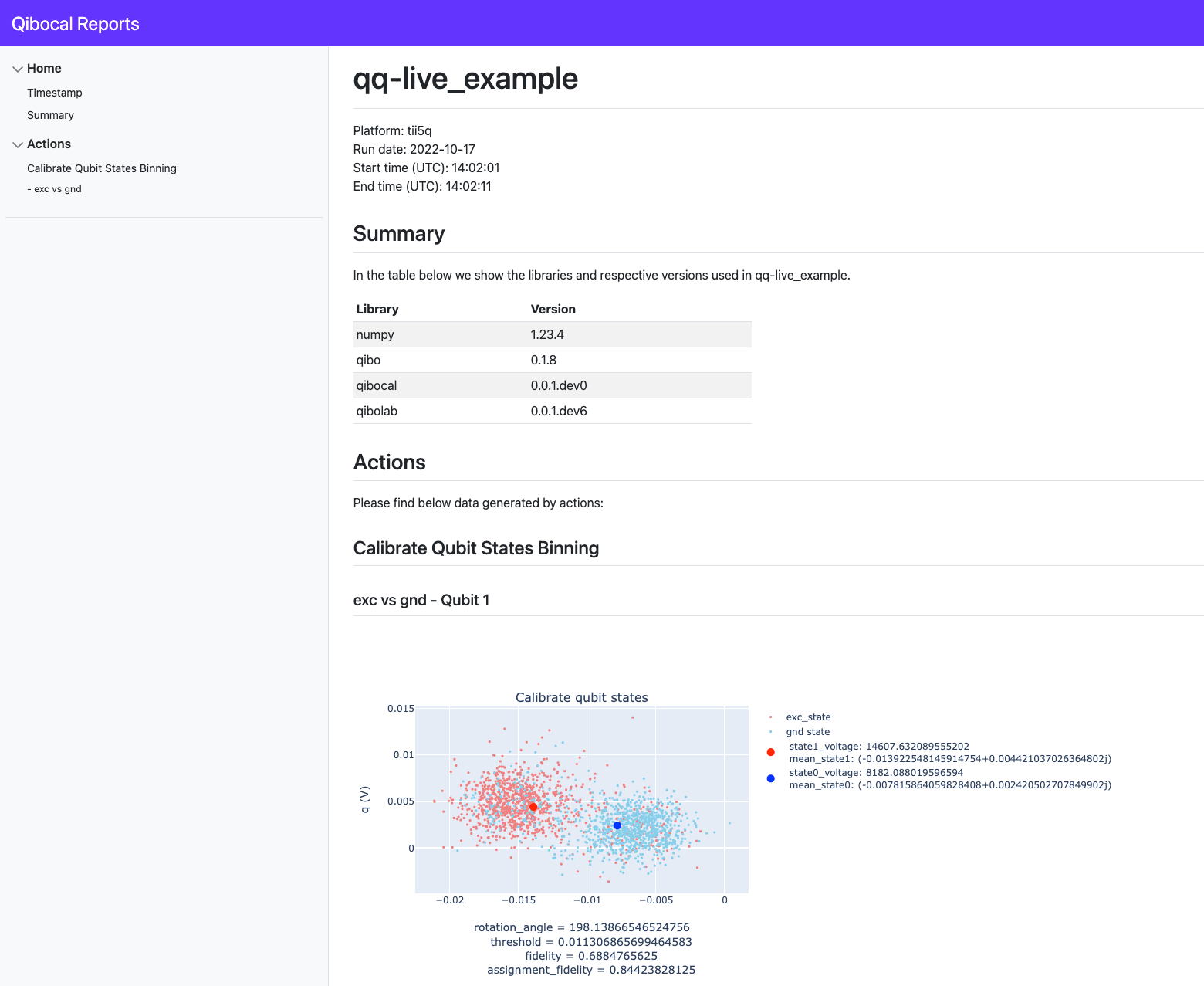
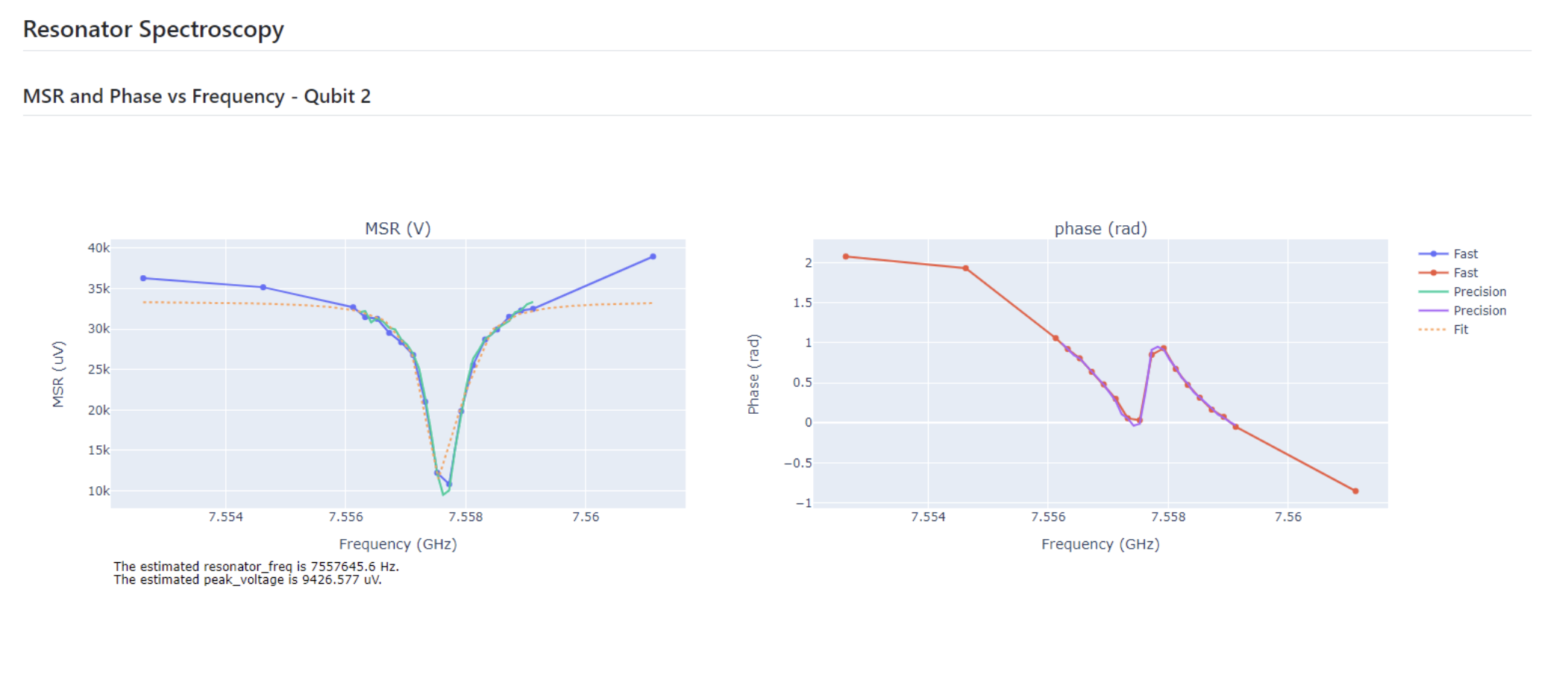
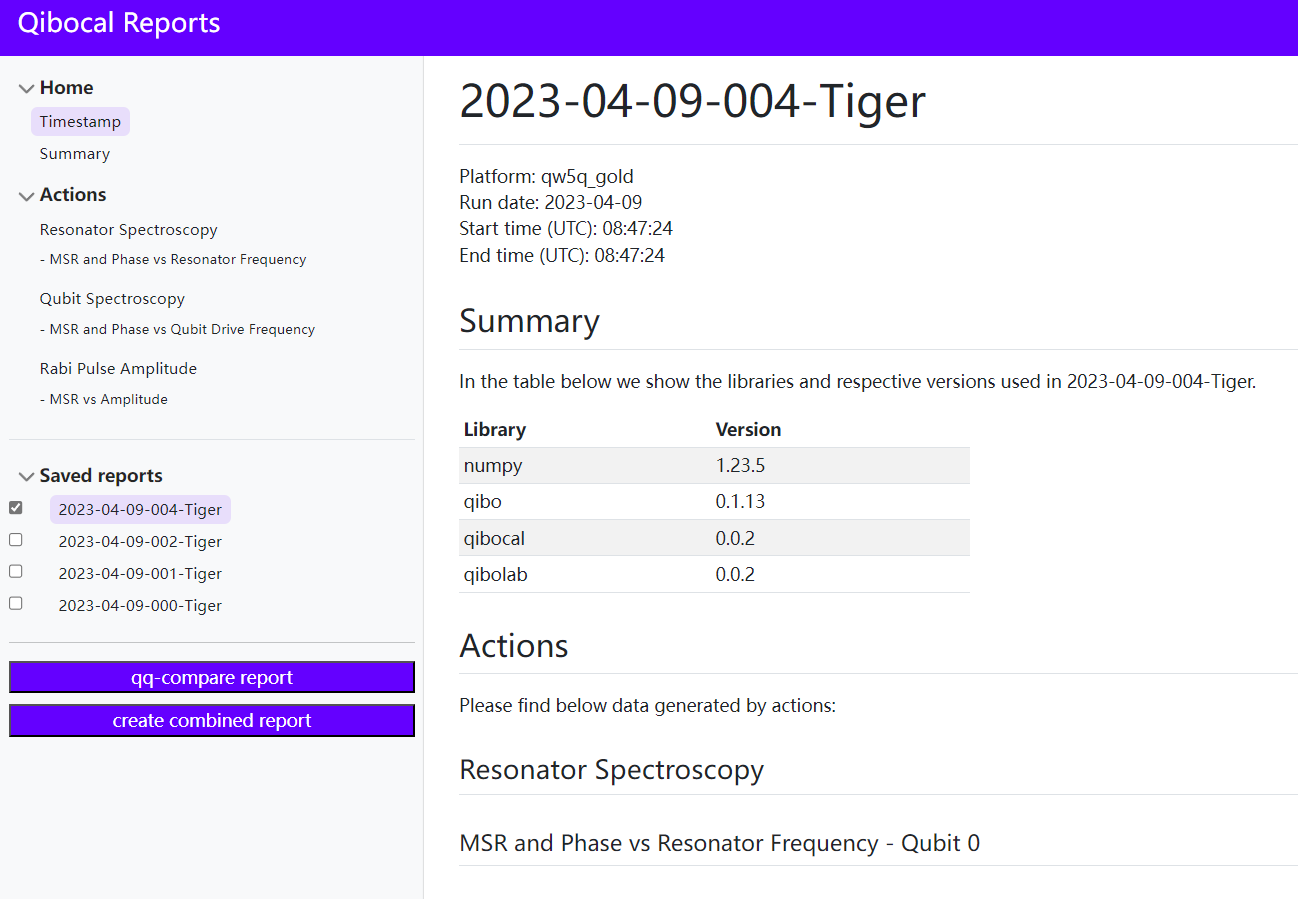
4.将报表上传至服务器
为了将报告上传到集中式服务器,向服务器管理员发送您的公共ssh密钥(来自您计划上传报告的机器),然后使用qq-upload <output_folder>命令。这个程序将把你的报告上传到服务器,并生成一个唯一的URL。qq-upload < output_folder >
5.简单测试
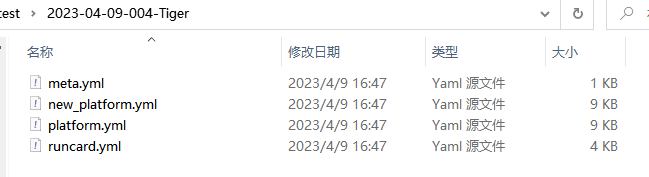
运行runcard文件,runcard
- platform.yml:在校准开始时使用的包含平台runcard的yaml
- new_platform.yml: a yaml 运行指定的校准程序后,包含更新的平台runcard的yaml;
- runcard.yml: 执行qq时提供的runcard副本;
- index.html:显示报告的Web页面;
- data: 包含按例程划分的所有结果的文件夹.
(qibo) D:\qibo>qq d:\qibo\qibocal\runcards\actions_qm.yml -o action_qm
2023-04-10 15:46:03,949 - qm - INFO - Starting session: 458359b8-d4ee-4184-8e21-cb56a123305c
2023-04-10 15:46:46,503 - qm - ERROR - Failed to detect to QuantumMachines server. Tried connecting to 192.168.0.1:80.
//无法连接至QuantumMachines服务器
RuntimeError: Cannot establish connection to <qibolab.instruments.qm.QMOPX object at 0x000001AC73F0EB90> instruments. Error captured: 'Failed to detect to QuantumMachines server. Tried connecting to 192.168.0.1:80.'
//QMOPX用于控制量子机(QM) OPX控制器的仪器对象
QMOPX是qibolab.instruments.qm模块中的一个类,表示量子机器OPX仪器。它用于控制OPX并通过网络与OPX通信。QMOPX构造函数接受两个参数:乐器的名称以及字符串形式的IP地址和端口号。在给定的代码块中,当simulation_duration为None时,QMOPX用于实例化控制器对象。构造器中使用的IP地址和端口号被硬编码为“192.168.0.1:80”。当simulation_duration不为None时,将实例化一个QMSim对象,它是OPX的模拟器。QMSim构造函数接受四个参数:仪器的名称、OPX集群的IP地址和端口号、以纳秒为单位的模拟持续时间,以及一个布尔标志云(用于确定是否使用云资源进行模拟)。localooscillator类是用来表示一个本地振荡器仪器,它被用来产生微波信号驱动和读出。在给定的代码块中,实例化了六个localooscillator对象,并设置了它们的频率。
OPX是Quantum Machines (QM)公司生产的一种量子计算机控制器。在qibolab中,QMOPX类被用于控制OPX控制器。在OPX控制器上播放脉冲需要一个“config”字典和一个用QUA语言编写的程序。在QMOPX类中,控制器、元素和脉冲都在给定脉冲序列后注册,以便配置仅包含与参与的量子比特相关的元素。执行任意qibolab“PulseSequence”的QUA程序在“play”和“playpulses”中编写,并在“executeprogram”中执行。QMOPX类有一些属性,包括isconnected,manager,config,timeofflight和smearing。其中,config是在多个方法中生成的字典,用于在OPX上执行脉冲。

三、源代码文件分析
1. .github/workflow
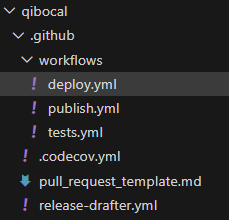
提供的代码块是位于 qibocal/.github/workflows/deploy.yml 的 GitHub Actions 配置文件。该文件定义了一个名为 Deploy 的工作流程,该工作流程在推送、合并分支组、发布事件(发布类型为 published)时触发。该工作流程包含一个名为 build 的作业,该作业使用了一个名为 deploy-pip-poetry.yml 的 Action,该 Action 位于 qiboteam/workflows/.github/workflows/deploy-pip-poetry.yml。该 Action 会在 Ubuntu、macOS 和 Windows 操作系统上运行,使用 Python 3.8、3.9 和 3.10 进行测试。该 Action 还会使用 Poetry 工具安装依赖项,并在发布事件时将软件包发布到 PyPI。
qibocal/.github/workflows 目录下的文件是用于配置 GitHub Actions 工作流程的文件。工作流程是一系列自动化操作,可以在代码仓库中的事件发生时触发,例如推送代码、合并分支或发布软件包。工作流程可以使用 GitHub 提供的 Actions 或自定义脚本来执行操作,例如构建、测试、部署或通知。在 qibocal/.github/workflows 目录下的文件定义了不同的工作流程,可以根据需要进行修改或添加。
当版本有更新的时候进行推送。
2. doc
这个其实就是源码官网的文档说明,转化后相当于本地缓存,.rst的后缀名改为.md也可以查看
rst 文件打开方式_python_没有梦想的咸鱼~-DevPress官方社区
RST文件打开_power0405hf的博客-CSDN博客
source文件夹下是对api接口、开发者等指导教程
api-refernce
api-refernce中的qibocal.rst介绍了量子电路中的校准技术。
Qibocal
Calibration routines
校准技术是用于减少量子电路执行误差的技术。为了进行校准,将实验的理论结果与使用量子设备运行相同实验得到的读数进行比较。校准至少有两个目标:
- 推导出供硬件使用的信号的确切值,以获得理论操作的最佳实现;
- 推导出系统松弛时间,即由于机器超载而不再可靠的硬件操作执行的阈值时间间隔。
qibocal.rst文件中列出了当前和未来的qibocal校准例程。该文件包括了一个表格,其中包含了每个例程的方法、代码、在设备上测试的情况以及是否自动化。
下表列出了当前和未来的qilocal例程: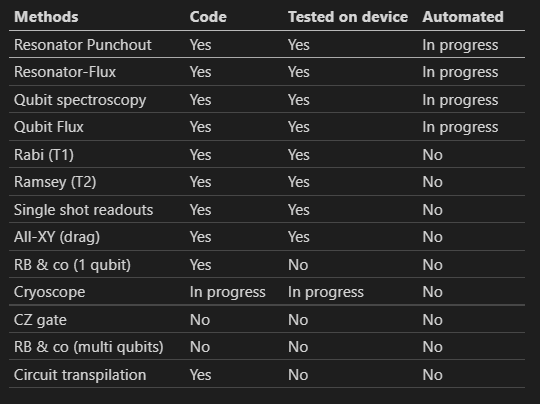
developer-guides
开发者文档,没有特别重要的东西。
getting-started
getting-started中介绍了niGSC和从样本中提取特征。
niGSC
Non-Interactive Gate Set Characterization 非交互门集表征,包涵三个类
1.电路工厂,当调用时产生电路的迭代器。
2.实验类,它接受一个可迭代的产生电路的对象,可选一些参数。它能够执行电路并覆盖/存储/处理必要的数据。3.一个存储和显示门集表征结果的类。
Standard Randomized Benchmarking
标准随机基准。一般来说,标准RB协议的思想是量化量子器件在实现门方面的性能。为此,量子器件需要能够制备一个量子态,用门修饰这个量子态,并最终测量量子态调制的结果。基态y(m)的生存概率取决于所施加门m的序列长度,用以下指数函数调制:
Qibocal Implementation
resonator_sample
如何通过采样提取特征?
该方法的目的是尽可能减少对芯片的调用次数,同时仍然提取有关不同校准例程特征的信息。该方法是为扫描参数的例程构建的,并尝试提取沿扫描平滑变化的特征。
我们选择一个样本点高斯分布周围的初始猜测与给定的标准变化。在机器中执行新的采样点,并与背景噪声进行比较。如果提取的样本偏离背景噪声,即绝对信噪比较高,则认为发现了潜在特征。否则我们将重新抽取样本。当检测到某个特性时,将在该值周围执行一次小扫描,以便对该值进行微调。然后,这被用作表征协议的下一次迭代的初始猜测,并带有更改的参数。
当实验参数缓慢移动时,该算法密切遵循一个特征。
我们允许输入精度和范围,样本是在初始猜测周围采取的。以及用于微调结果的快速扫描的精度。
max_runs: 40
thr: 5
spans: [10000000, 5000000]
small_spans: [1000000, 100000]
resolution: 100000
max_runs: 设置在算法确定特征不在给定范围内之前要提取的高斯分布样本的最大数量
thr:信噪比的最小阈值,算法将决定该特征已被检测到,并将继续进行下一步。
spans: 列出新参数将被采样的跨度。具有递减范围的列表将更精确地找到特征,代价是运行采样算法更多次。了解所需特征的比例对设计跨度列表非常有帮助。以Hz为单位展示的谐振器穿孔示例。
small_spans:找到功能时运行的小型扫描的范围列表。将执行10个均匀分布点的扫描。这将与特征的最终期望精度直接相关。以Hz为单位展示的谐振器穿孔示例。
resolution: 高斯分布样本在采样空间中的精度。在算法的初始部分,该值将是用于检测特征的精度。该值需要足够小,以使特征可被检测到。
autoruncard
如何写你的自动卡片?
自动化需要一个比简单的线性步骤序列更复杂的工作流程。具体而言,要求具备以下特点:
branching 在一个任务之后分支更多的任务
merging要求之前运行过多个例程
passing data由前一次校准操作计算的值应可用于后续校准操作
conditioning根据校准结果决定如何进行
为了实现这一功能,必须提供复杂校准任务的充分表示,以及一个合适的执行者,给定任务规范和运行的机器,它能够完全自动化地执行整个任务,除非某些单独的操作导致意想不到的结果。
为了在可能的复杂流的空间上提供一个更清晰的抽象,执行被划分为两个不同的机制,以便组成一个更简单但更常见的部分的最一般的流,以及一个更复杂但完全通用的附加部分。这两部分被称为:
Normal Flow 它由有向无环图(DAG)定义
Exceptional Flow 它允许从正常流的任何点分支,并根据动态条件改变它
如何使用?
目前只实现了Normal Flow,它由runcard定义,如下所示: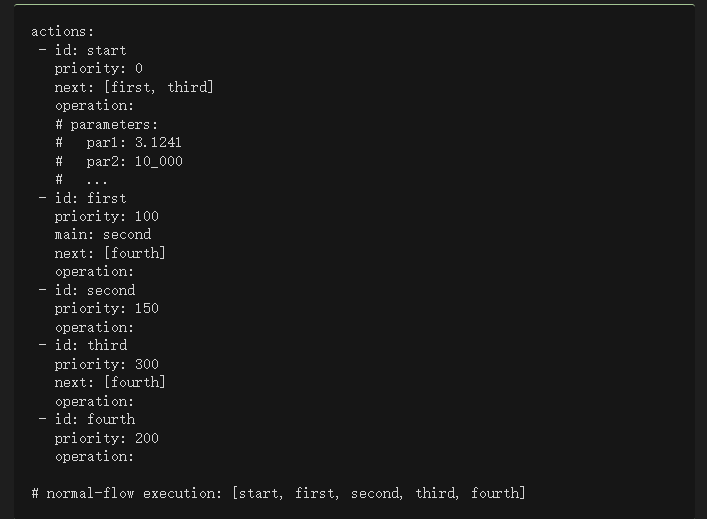
example(使用方法的详细步骤)
本节展示了使用Qibocal执行谐振器光谱的步骤。
运行卡包含运行特定任务所需的所有必要信息。出于我们的目的,我们可以使用以下runcard并将其保存为example.yml:
platform: tii5q
qubits: [2]
format: csv
actions:
resonator_spectroscopy:
lowres_width: 5_000_000
lowres_step: 2_000_000
highres_width: 1_500_000
highres_step: 200_000
precision_width: 1_500_000
precision_step: 100_000
software_averages: 1
为了运行runcard中指定的所有校准例程,Qibocal使用qq命令
Qibocal needs Qibolab!
qilocal包与qibolab紧密合作。实际上,为了适当地进行校准,必须能够将适当的理论测试转换为相应的脉冲序列,以便在硬件中解释它们。在本节中,我们将解释如何执行属于tii平台的设备的校准。为此,必须正确安装qibolab。要正确执行此过程,请访问Qibolab安装页面,其中解释了如何安装适当的extra_dependencies。
3. runcards
runcards文件夹包含了一些用于运行Qibocal的配置文件。这些配置文件被称为“runcards”,它们包含了一些参数和选项,用于指定Qibocal的行为和选项。
"""
1. resonator_spectroscopy:谐振器谱分析,用于测量谐振器的频率响应。参数包括频率宽度(freq_width)、频率步长(freq_step)、测量次数(nshots)等。
2. resonator_punchout:谐振器冲击实验,用于测量谐振器在不同振幅下的响应。参数包括频率宽度(freq_width)、频率步长(freq_step)、最小振幅因子(min_amp_factor)等。
3. resonator_spectroscopy_flux:磁通谐振器谱分析,用于测量谐振器在不同磁通下的频率响应。参数包括频率宽度(freq_width)、频率步长(freq_step)、偏置宽度(bias_width)等。
4. qubit_spectroscopy:量子比特谱分析,用于测量量子比特的频率响应。参数包括驱动振幅(drive_amplitude)、驱动持续时间(drive_duration)、频率宽度(freq_width)等。
5. qubit_spectroscopy_flux:磁通量子比特谱分析,用于测量量子比特在不同磁通下的频率响应。参数包括驱动振幅(drive_amplitude)、频率宽度(freq_width)、偏置宽度(bias_width)等。
6. rabi_pulse_amplitude:拉比脉冲振幅实验,用于测量量子比特在不同脉冲振幅下的响应。参数包括脉冲振幅起始值(pulse_amplitude_start)、脉冲振幅结束值(pulse_amplitude_end)、脉冲振幅步长(pulse_amplitude_step)等。
7. rabi_pulse_length:拉比脉冲长度实验,用于测量量子比特在不同脉冲长度下的响应。参数包括脉冲持续时间起始值(pulse_duration_start)、脉冲持续时间结束值(pulse_duration_end)、脉冲持续时间步长(pulse_duration_step)等。
8. allXY:AllXY实验,用于评估量子比特门操作的性能。参数包括β参数(beta_param)、软件平均次数(software_averages)、测量点数(points)等。
9. t1:T1实验,用于测量量子比特的能量弛豫时间。参数包括读出延迟起始值(delay_before_readout_start)、读出延迟结束值(delay_before_readout_end)、读出延迟步长(delay_before_readout_step)等。
10. ramsey:Ramsey实验,用于测量量子比特的相干时间。参数包括脉冲间隔起始值(delay_between_pulses_start)、脉冲间隔结束值(delay_between_pulses_end)、脉冲间隔步长(delay_between_pulses_step)等。
此外,还有一些未测试的实验操作,如rabi_pulse_length_and_amplitude、calibrate_qubit_states、allXY_drag_pulse_tuning、drag_pulse_tuning、dispersive_shift、spin_echo_3pulses 和 flipping。
"""
具体来说,runcards文件夹中的文件包括:
- default.yaml:这是默认的runcard文件,它包含了一些默认的参数和选项,用于运行Qibocal。
- example.yaml:这是一个示例runcard文件,它包含了一些示例参数和选项,用于演示如何使用runcard文件。
- qaoa.yaml:这是一个用于运行QAOA算法的runcard文件,它包含了一些特定于QAOA算法的参数和选项。
- vqe.yaml:这是一个用于运行VQE算法的runcard文件,它包含了一些特定于VQE算法的参数和选项。
- niGSC.yml这个文件是一个YAML格式的配置文件,用于定义量子计算机的一些操作。在这个文件中,定义了一些操作,包括标准随机基准测试(standardrb)、X-Id随机基准测试(XIdrb)和模拟滤波随机基准测试(simulfilteredrb)等。这些测试可以用于评估量子计算机的性能和噪声水平。在这个文件中,还定义了一些参数,如量子比特数(nqubits)、深度(depths)、运行次数(runs)、测量次数(nshots)、噪声模型(noisemodel)和噪声参数(noiseparams)等。这些参数可以根据需要进行修改。此外,文件中还定义了使用的后端(backend),这里使用的是numpy后端。
numpy是一个Python库,用于科学计算和数值计算。在量子计算中,numpy可以用作量子计算机的后端,用于模拟量子计算机的运行。在niGSC.yml文件中,使用numpy作为后端,可以在本地计算机上模拟量子计算机的运行,以评估量子计算机的性能和噪声水平。
- dummy.yml是一个用于模拟量子计算机的配置文件。在该文件中,可以指定量子计算机的硬件参数、后端、量子算法等信息。在该文件中,platform参数指定了量子计算机的硬件平台,这里设置为dummy,表示使用虚拟量子计算机进行模拟。qubits参数指定了量子比特的编号,这里设置为[0],表示只使用编号为0的量子比特。format参数指定了输出文件的格式,这里设置为csv,表示输出为CSV格式的文件。
actions参数指定了要执行的量子算法和实验。在该文件中,注释掉了几个实验,只保留了resonator_spectroscopy_flux实验。该实验用于测量谐振腔的频率响应,需要指定一些参数,如freq_width、freq_step、bias_width等。这些参数的具体含义可以在文件中找到注释。
4. severscript
qibocal-index-reports.py是一个用于生成Qibocal报告索引的Python脚本。该脚本会遍历指定目录下的所有报告文件,并将它们的元数据(如标题、日期、平台等)存储到一个JSON文件中,以便在Web页面中显示。在该脚本中,ROOT变量指定了报告文件所在的根目录,ROOT_URL变量指定了报告文件在Web页面中的URL前缀,OUT变量指定了生成的JSON文件的输出路径,DEFAULTS变量指定了元数据的默认值。该文件中的 meta_from_path 函数会从每个文件夹中的 meta.yml 文件中读取元数据信息,并将其与默认值合并。register 函数则会从文件夹的元数据信息中提取出报告的标题、日期、平台、开始时间和结束时间,并生成一个包含这些信息的元组。最后,make_index 函数会遍历所有文件夹,将每个文件夹中的报告信息添加到一个列表中,并将该列表写入到 /home/users/qibocal/qibocal-reports/index.json 文件中。
qibocal-update-on-change.py是一个用于监视Qibocal报告文件夹的Python脚本。该脚本会在报告文件夹中的任何文件发生更改时,自动更新报告索引文件index.json。在该脚本中,REPORTS_DIR变量指定了报告文件夹的路径,INDEX_FILE变量指定了报告索引文件的路径,DEFAULTS变量指定了报告元数据的默认值。该脚本使用了Python标准库中的pathlib、json和time模块,以及第三方库watchdog中的Observer和EventHandler类。其中,pathlib模块用于处理文件路径,json模块用于读写JSON文件,time模块用于获取当前时间,Observer和EventHandler类用于监视文件夹的变化。
5. src
decorators.py定义了一个名为plot的装饰器函数,用于向报告和实时绘图页面添加图表。该函数接受两个参数:header和method。header是图表在报告中使用的标题,method是在qibocal.plots中定义的绘图方法。装饰器函数plot返回一个名为wrapped的函数,该函数接受一个函数作为参数f。如果函数f已经有了属性plots,则将(header, method)插入到列表的开头,以便在报告中具有正确的图表顺序。否则,将[(header, method)]赋值给f.plots。最后,返回函数wrapped。
poetry.lock,是由 Poetry 1.4.1 自动生成的文件。该文件用于锁定项目的依赖项版本,以确保在不同的环境中使用相同的依赖项版本。在该文件中,每个依赖项都列出了其名称、版本号和依赖项的哈希值。这些信息用于确保在不同的环境中使用相同的依赖项版本,以避免由于依赖项版本不同而导致的不兼容性问题。
5.1 auto
auto文件夹中的程序都是用于自动化处理Qibocal报告的。其中,init.py文件是一个空文件,它的作用是将auto文件夹变成一个Python包。
draw.py
是一个用于绘制执行图的Python模块。该模块提供了一些函数,可以将执行图绘制成PNG或SVG格式的图片,并将图片保存到指定的文件中。在该模块中,draw_circuit函数用于绘制量子电路的执行图,draw_program函数用于绘制量子程序的执行图,draw_dag函数用于绘制DAG电路的执行图。这些函数都接受一个DAGCircuit对象作为输入,该对象表示执行图的有向无环图(DAG)。该模块使用了Python标准库中的io、tempfile、subprocess和shutil模块,以及第三方库graphviz中的Source类。其中,io模块用于处理文件输入输出,tempfile模块用于创建临时文件,subprocess模块用于执行外部命令,shutil模块用于文件操作,Source类用于生成DOT语言的图形描述。
execute.py
包含了一个任务执行器的实现,用于执行任务图并跟踪其历史记录。在该文件中定义的 Executor 类有多个方法,用于执行图中的任务。
- Executor:执行器,用于执行任务的图并跟踪其历史记录。它包含了一些方法,如load()方法,用于从runcard加载执行图和相关的执行器;available()方法,用于检查任务是否具有所有满足依赖关系的任务;successors()方法,用于检索指定任务的后继任务;next()方法,用于解析要执行的下一个任务;current属性,用于检索与head指针关联的当前任务;run()方法,用于实际执行任务。
- load():从runcard加载执行图和相关的执行器。
- available():检查任务是否具有所有满足依赖关系的任务。
- successors():检索指定任务的后继任务。
- next():解析要执行的下一个任务。
- current:检索与head指针关联的当前任务。
- run():实际执行任务。
总的来说,qibocal/src/qibocal/auto/execute.py文件中定义了一个名为Executor的类,用于执行任务的图并跟踪其历史记录。如果您需要了解更多关于任务执行的信息,可以查看这个文件中定义的类和方法的具体实现.
请详细说明load方法的作用
根据您的查询,load()方法定义在Executor类中,用于从runcard加载执行图和相关的执行器。具体来说,load()方法接受一个card参数,该参数可以是一个字典或一个路径。它使用Runcard.load()方法加载runcard,并使用Graph.from_actions()方法从runcard的操作中创建执行图。最后,它返回一个Executor对象,该对象包含了加载的执行图和一个空的历史记录。
总的来说,load()方法的作用是从runcard加载执行图和相关的执行器,并返回一个Executor对象,该对象包含了加载的执行图和一个空的历史记录
这个执行图指的是什么
根据您的查询,"这个执行图"指的是qibocal/src/qibocal/auto/execute.py文件中定义的Executor类中的执行图。执行图是一个有向无环图,用于表示任务之间的依赖关系。在Executor类中,执行图由Graph类实现,它包含了一组任务和它们之间的依赖关系。具体来说,每个任务都是一个Task对象,它包含了任务的ID、优先级、依赖关系等信息。执行图中的每个任务都有一个唯一的ID,用于标识该任务。任务之间的依赖关系由next属性表示,它是一个列表,包含了该任务的后继任务的ID。在执行图中,每个任务都有一个优先级,用于确定任务的执行顺序。执行图中的任务按照优先级从高到低排序,优先级相同的任务按照它们在next列表中的顺序排序。Executor类中的方法,如available()、successors()和next(),都是用于操作执行图的方法,用于检查任务是否具有所有满足依赖关系的任务、检索指定任务的后继任务和解析要执行的下一个任务。总的来说,执行图是Executor类中用于表示任务之间依赖关系的数据结构,它是实现自动化校准的关键之一
请详细说明available方法
根据您的查询,available()方法定义在Executor类中,用于检查任务是否具有所有满足依赖关系的任务。具体来说,available()方法检查执行图中的每个任务是否具有所有满足依赖关系的任务。如果任务具有所有满足依赖关系的任务,则该任务被认为是“可用的”,否则该任务被认为是“不可用的”。如果所有任务都是可用的,则available()方法返回True,否则返回False。
在Executor类中,任务之间的依赖关系由next属性表示,它是一个列表,包含了该任务的后继任务的ID。因此,available()方法的实现涉及到遍历执行图中的每个任务,并检查它们的后继任务是否都已经完成。如果后继任务都已经完成,则该任务被认为是可用的,否则该任务被认为是不可用的。
总的来说,available()方法的作用是检查任务是否具有所有满足依赖关系的任务,并返回一个布尔值表示任务是否可用。如果您需要了解更多关于任务执行的信息,可以查看Executor类中定义的其他方法的具体实现
operation.py
qibocal/src/qibocal/auto/operation. py中引用的文本解释了Parameters类的用途。为了实现每个校准程序的特定参数,需要对其进行子类化。Parameters类是代数数据类型的一个示例,它是一种通过组合其他类型来定义类型的方法。实际参数结构仅用于校准程序本身。load方法用于从runcard加载参数,可能会查看前面的步骤输出.
runcard.py
runcard.py 是一个用于执行校准例程的 Python 模块。它定义了两个 Pydantic 数据类:Action 和 Runcard。Action 类用于指定一个校准例程中的操作,包括操作的唯一标识符、要执行的操作、操作的主要后续操作、分支操作、优先级和输入参数。Runcard 类则用于指定一个完整的校准例程,包括一系列的 Action 对象。Runcard 类有一个 load 方法,用于从 YAML 文件或字典中加载一个 Runcard 实例。在加载过程中,load 方法会将 YAML 文件或字典转换为 Python 对象,并使用 Pydantic 进行验证和类型转换 .
status.py
"""Describe the status of a completed task.描述已完成任务的状态。
Simple and general statuses are defined here, but more of them can be defined
by individual calibrations routines, and user code as well::
这里定义了简单和通用的状态,但是可以通过单独的校准例程和用户代码来定义更多的状态
class PinkFirst(Status):
'''Follow the pink arrow as the next one.'''
@dataclass
class ParametrizedException(Status):
'''Trigger exceptional workflow, passing down a further parameter.
Useful if the handler function is using some kind of threshold, or can
make somehow use of the parameter to decide, but in a way that is not
completely established, so it should not be hardcoded in the status
type.
'''
myvalue: int
@dataclass
class ExceptionWithInput(Status):
'''Pass to next routine as input.'''
routine_x_input: float
In general, statuses can encode a predetermined decision about what to do next,
so the decision has been handled by the fitting function, or an open decision,
that is left up to the handler function.
通常,状态可以编码关于下一步做什么的预先确定的决策,因此该决策已由拟合函数处理,或者
由处理程序函数处理的开放决策。
"""
class Status:
"""The exit status of a calibration routine."""
class Normal(Status):
"""All green."""
class Broken(Status):
"""Unrecoverable."""
task.py
task.py是一个Python模块,用于跟踪执行的操作。它定义了一个名为Task的类,该类包含有关操作的信息,例如操作的优先级,参数和结果。此外,Task类还包含用于加载和运行操作的方法。具体而言,Task类的run方法将执行操作并返回结果。Task类的load方法用于从字典中加载操作描述符。Task类的datapath方法返回一个路径,该路径指向存储操作数据的文件。Task类的data方法将读取该文件并返回数据。如果文件不存在,则返回None。Task类的operation属性返回与操作描述符关联的操作。如果操作描述符未指定操作,则引发RuntimeError。Task类的parameters属性返回与操作描述符关联的参数。Task类的priority属性返回与操作描述符关联的优先级。如果未指定优先级,则返回一个大于任何手动输入的数字的数字 .
validate.py
"""Extra tools to validate an execution graph.验证执行图的额外工具"""
from .graph import Graph
def starting_point(graph: Graph):
"""Check graph starting point.
Since a graph is designed to work with a unique starting point, the user
has to make sure to specify a single one, since the starting point is
identified only by a 0 priority (i.e. top-priority).
The execution of a graph with multiple starting points has to be considered
undefined behavior.
检查图形起始点。由于图形设计为具有唯一的起始点,因此用户必须确保指定单个起始点,因为起始点仅由0优先级标识(即最高优先级)。具有多个起始点的图的执行必须被视为未定义行为。
"""
candidates = []
for task in graph.tasks():
if task.action.priority == 0:
candidates.append(task)
if len(candidates) != 1:
return False
return True
5.3 cli
_base.py
_base.py文件中包含了一些全局CLI选项和一些命令函数。全局CLI是指在整个Qibocal项目中可用的命令行界面。command函数是用于执行量子校准验证和验证的主要命令函数。
live_plot函数是用于在Dash服务器上实时绘制校准数据的命令函数。
upload函数是用于将输出文件夹上传到服务器的命令函数。
compare函数是用于创建一个比较文件夹的命令函数,该文件夹包含了多个数据文件夹的数据,以便进行比较。此外,还定义了一些常量,如UPLOAD_HOST,TARGET_DIR和ROOT_URL等。这些常量用于指定上传到服务器的位置和URL
builders.py
定义了一个名为 load_yaml 的函数,用于从磁盘中加载 YAML 文件并返回其内容。该函数使用 yaml 库来加载文件,并使用 safe_load 方法来避免潜在的安全漏洞。
5.2 fitting
utils.py 导入了 NumPy 和 SciPy 库,并定义了几个函数用于拟合数据。lorenzian 函数实现了洛伦兹峰函数,用于描述某些物理现象中的峰值。rabi 和 ramsey 函数分别实现了超导量子比特的 Rabi 振荡和 Ramsey 振荡的拟合函数。exp 函数实现了指数函数的拟合。最后,flipping 函数实现了翻转量子比特振荡的拟合函数。
def lorenzian(frequency, amplitude, center, sigma, offset):
# http://openafox.com/science/peak-function-derivations.html
return (amplitude / np.pi) * (
sigma / ((frequency - center) ** 2 + sigma**2)
) + offset
这段代码定义了一个名为 lorenzian 的函数,用于计算洛伦兹峰的函数值。它采用以下公式。其中 frequency 是自变量,表示频率;amplitude 是峰的振幅;center 是峰的中心频率;sigma 是峰的半高宽;offset 是峰的偏移量。这个函数的实现非常简单,只是一个数学公式的实现。如果你需要更多的函数来拟合你的数据,你可以看看这个文件中的其他函数,如 rabi、ramsey、flipping、cos 等。这些函数都是用于拟合量子比特的振荡行为的。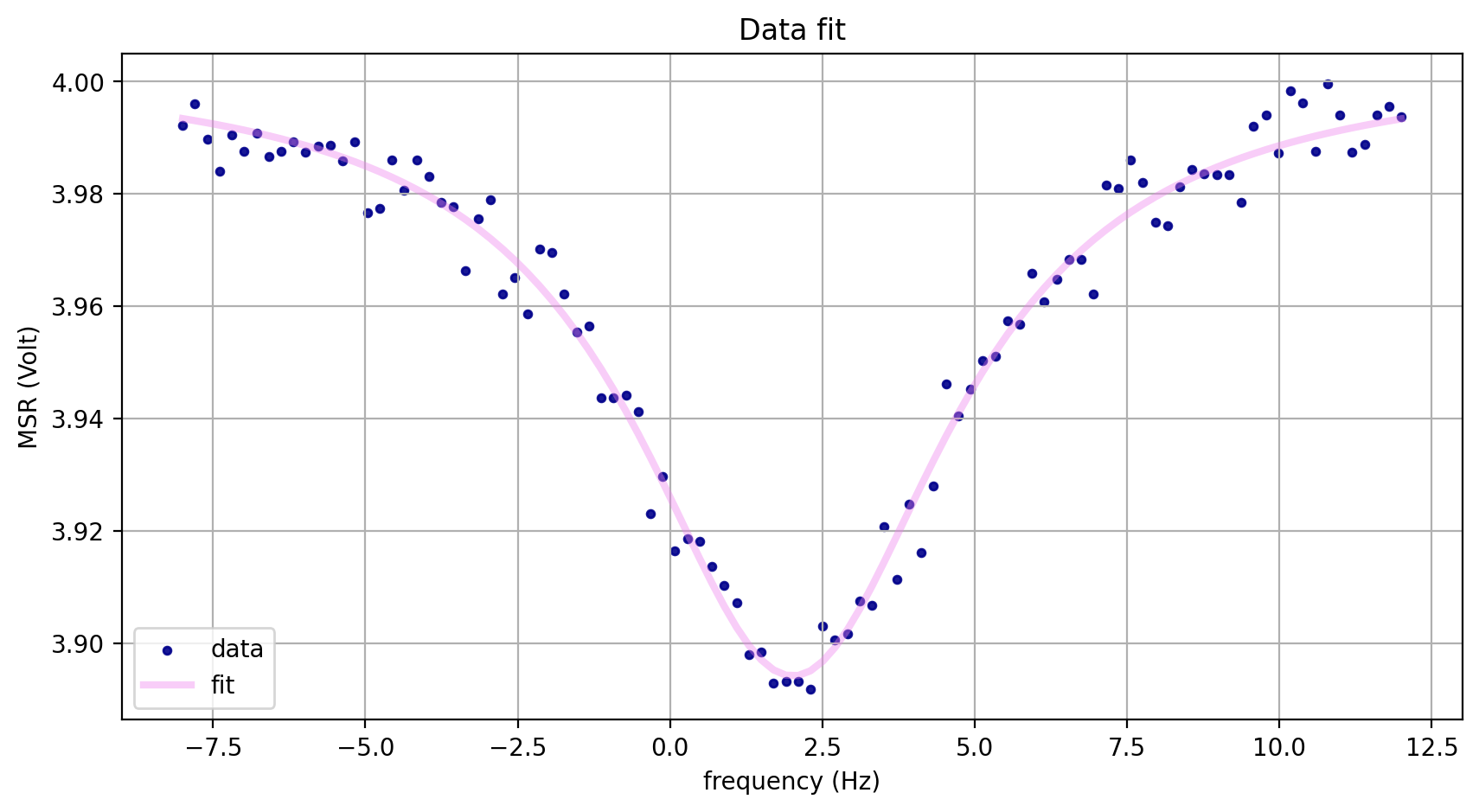
utils文件里都是标定流程中各个步骤的拟合函数。例如:
def rabi(x, p0, p1, p2, p3, p4):
# A fit to Superconducting Qubit Rabi Oscillation
# Offset : p[0]
# Oscillation amplitude : p[1]
# Period T : 1/p[2]
# Phase : p[3]
# Arbitrary parameter T_2 : 1/p[4]
return p0 + p1 * np.sin(2 * np.pi * x * p2 + p3) * np.exp(-x * p4)
这段代码定义了一个名为 rabi 的函数,用于拟合超导量子比特的 Rabi 振荡。函数的输入参数为 x 和五个拟合参数 p0、p1、p2、p3 和 p4,分别对应如下含义:
- p0:偏移量(Offset)
- p1:振荡幅度(Oscillation amplitude)
- p2:周期(Period)的倒数
- p3:相位(Phase)
- p4:任意参数 T2 的倒数
函数的输出为拟合结果。具体实现方式为,根据输入的 x 和五个参数 p0、p1、p2、p3 和 p4,计算出一个正弦函数和一个指数函数的乘积,然后加上偏移量 p0,得到最终的拟合结果。
methods.py 的 Python 文件,用于实现拟合算法。该文件定义了一个名为 fit 的函数,该函数接受一个 method 参数,用于指定拟合算法的类型。该函数还接受一些可选参数,包括 xdata、ydata、p0、bounds 和 sigma。其中,xdata 和 ydata 参数用于指定拟合数据的输入,p0 参数用于指定拟合算法的初始参数,bounds 参数用于指定拟合算法的参数范围,sigma 参数用于指定拟合数据的误差。
该文件中定义了多个拟合算法,包括 fit_linear、fit_exponential、fit_gaussian 和 fit_lorentzian 等。这些算法都是基于 scipy.optimize.curve_fit 函数实现的,该函数使用非线性最小二乘法来拟合数据。每个算法都会返回一个元组,其中包含拟合参数和协方差矩阵。
因此,该 Python 文件的作用是提供了多个拟合算法的实现,以便于用户可以根据自己的需求选择合适的算法来拟合数据。
5.3 plots
针对不同测试项目进行的绘图脚本。
5.4 web
和qq-compare相关
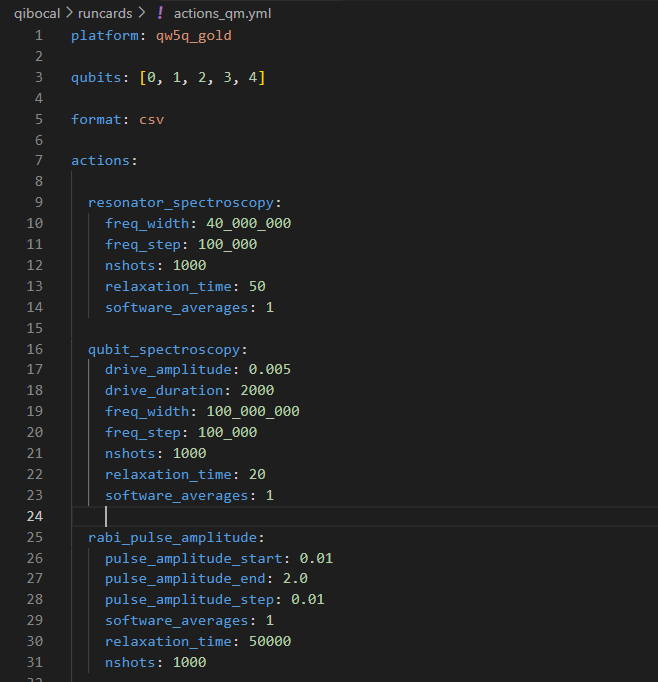
四、Qibocal自动化校准流程
是在已经标定完的基础之上进行校准。
1.在runcards中写入变量,例如测谐振腔腔频。
platform: qw5q_gold
qubits: [0, 1, 2, 3, 4]
format: csv
actions:
resonator_spectroscopy:
freq_width: 40_000_000
freq_step: 100_000
nshots: 1000
relaxation_time: 50
software_averages: 1
2.会调用calibrations里characterization中的校准函数
@plot("MSR and Phase vs Resonator Frequency", plots.frequency_msr_phase)
def resonator_spectroscopy(
platform: AbstractPlatform,
qubits: dict,
freq_width: int, """执行高分辨率扫描的宽度频率(HZ)"""
freq_step: int, """高分辨率扫描的步进频率(HZ)"""
nshots: int = 1024,
relaxation_time: int = 50,
software_averages: int = 1,
):
3.加载设备—创建脉冲序列—
# reload instrument settings from runcard
platform.reload_settings()
# create a sequence of pulses for the experiment:
# MZ
# taking advantage of multiplexing, apply the same set of gates to all qubits in parallel
sequence = PulseSequence()
ro_pulses = {}
for qubit in qubits:
ro_pulses[qubit] = platform.create_qubit_readout_pulse(qubit, start=0)
sequence.add(ro_pulses[qubit])
4.定义 / 谐振腔频率 / 要扫描的参数及其范围
# define the parameter to sweep and its range resonator frequency
delta_frequency_range = np.arange(-freq_width // 2, freq_width // 2, freq_step)
sweeper = Sweeper(
Parameter.frequency,
delta_frequency_range,
pulses=[ro_pulses[qubit] for qubit in qubits],
)
5.创建数据集对象存储MSR、phase、i、q、谐振腔频率的结果
# create a DataUnits object to store the results,
# DataUnits stores by default MSR, phase, i, q
# additionally include resonator frequency
data = DataUnits(
name="data",
quantities={"frequency": "Hz"},
options=["qubit", "iteration"],
)
6.重复指定次数实验
# repeat the experiment as many times as defined by software_averages
for iteration in range(software_averages):
results = platform.sweep(
sequence, sweeper, nshots=nshots, relaxation_time=relaxation_time
)
7.检索每个量子比特的结果—对结果进行平均—存储结果
# retrieve the results for every qubit
for qubit in qubits:
# average msr, phase, i and q over the number of shots defined in the runcard
result = results[ro_pulses[qubit].serial]
# store the results
r = result.to_dict(average=False)
r.update(
{
"frequency[Hz]": delta_frequency_range + ro_pulses[qubit].frequency,
"qubit": len(delta_frequency_range) * [qubit],
"iteration": len(delta_frequency_range) * [iteration],
}
)
data.add_data_from_dict(r)
8.拟合数据
# finally, save the remaining data and fits
yield data
yield lorentzian_fit(
data,
x="frequency[GHz]",
y="MSR[uV]",
qubits=qubits,
resonator_type=platform.resonator_type,
labels=["readout_frequency", "peak_voltage"],
)
9.其他绘图函数
@plot(
"MSR and Phase vs Resonator Frequency",
plots.frequency_msr_phase)
@plot(
"MSR and Phase vs Resonator Frequency and Attenuation",
plots.frequency_attenuation_msr_phase,
)
@plot(
"MSR and Phase vs Resonator Frequency and Amplitude",
plots.frequency_amplitude_msr_phase,
)
@plot(
"MSR and Phase vs Resonator Frequency and Flux",
plots.frequency_flux_msr_phase,
)
@plot(
"MSR and Phase vs Resonator Frequency",
plots.dispersive_frequency_msr_phase)
import numpy as np
from qibolab.platforms.abstract import AbstractPlatform
from qibolab.pulses import PulseSequence
from qibocal.data import DataUnits
from qibocal.decorators import plot
from qibocal.fitting.methods import res_spectroscopy_flux_fit
from qibocal.plots import frequency_attenuation, frequency_bias_flux
def snr(signal, noise):
"""Signal to Noise Ratio to detect peaks and valleys.首先定义一个信噪比函数,用来检测波峰和波谷。(为什么用SNR进行检测?)"""
return 20 * np.log(signal / noise)
def choose_freq(freq, span, resolution):
"""Choose a new frequency gaussianly distributed around initial one.选择在初始频率周围呈高斯分布的新频率。
Args:
freq (float): frequency we sample around from.
span (float): search space we sample from.
resolution (int): number of points for search space resolution.
Returns:
freq+ff (float): new frequency sampled gaussianly around old value.旧值附近的新频率采样呈高斯分布。
"""
g = np.random.normal(0, span / 10, 1)
f = np.linspace(-span / 2, span / 2, resolution)
for ff in f:
if g <= ff:
break
return freq + ff
def get_noise(background, platform, ro_pulse, qubit, sequence):
"""Measure the MSR for the background noise at different points and average the results.在不同点测量背景噪声的MSR,并对结果取平均值。
Args:
background (list): frequencies where no feature should be found.没有特征的频率。
platform ():
ro_pulse (): Used in order to execute the pulse sequence with the right parameters in the right qubit.用于在正确的量子位中执行具有正确参数的脉冲序列。
qubit (int): TODO: might be useful to make this parameters implicit and not given.
sequence ():
Returns:
noise (float): Averaged MSR value for the different background frequencies.不同背景频率下的平均MSR值
"""
noise = 0
for b_freq in background:
ro_pulse.frequency = b_freq
msr = platform.execute_pulse_sequence(sequence)[ro_pulse.serial].msr.mean()
noise += msr
return noise / len(background)
def scan_level(
best_f,
best_msr,
max_runs,
thr,
span,
resolution,
noise,
platform,
ro_pulse,
qubit,
sequence,
):
"""Scans for the feature by sampling a gaussian near the previously found best point. Decides if the freature
is found by checking if the snr against background noise is above a threshold.
通过在先前找到的最佳点附近进行高斯采样来扫描特征。通过检查背景噪声的信噪比是否高于阈值来确定是否发现该特征。
Args:
best_f (int): Best found frequency in previous scan. Used as starting point.上次扫描中找到的最佳频率。用作起点。
best_msr (float): MSR found for the previous best frequency. Used to check if a better value is found.找到了上一个最佳频率的MSR。用于检查是否找到更好的值。
max_runs (int): Maximum amount of tries before stopping if feature is not found.如果找不到特征,停止前的最大尝试次数
thr (float): SNR value used as threshold for detection of the feature.用作特征检测阈值的SNR值
span (int): Search space around previous best value where the next frequency is sampled.搜索上一个最佳值周围的空间,其中对下一个频率进行采样
resolution (int): How many points are taken in the span.
noise (float): MSR value for the background noise.背景噪声的MSR值
platform (AbstractPlatform): Platform the experiment is executed on.
ro_pulse (ReadoutPulse): Used in order to execute the pulse sequence with the right parameters in the right qubit.
qubit (int): qubit coupled to the resonator that we are probing.
sequence (PulseSequence):
Returns:
best_f (float): Best frequency found for the feature.
best_msr (float): MSR found for the feature.
phase (float): Phase found for the feature.
i (float): In-phase signal
q (float): Quadrature signal.
"""
freq = best_f
for _ in range(max_runs):
ro_pulse.frequency = freq
result = platform.execute_pulse_sequence(sequence)[ro_pulse.serial]
msr = result.msr.mean()
if abs(snr(msr, noise)) >= thr:
msr1 = msr
if platform.resonator_type == "3D":
msr = -msr
best_msr = -best_msr
if msr < best_msr:
best_f, best_msr = freq, msr1
return (
best_f,
best_msr,
result.phase.mean(),
result.i.mean(),
result.q.mean(),
)
freq = choose_freq(best_f, span, resolution)
return best_f, best_msr, result.phase, result.i, result.q
def scan_small(best_f, best_msr, span, resolution, platform, ro_pulse, qubit, sequence):
"""Small scan around the found feature to fine-tune the measurement up to given precision.
在找到的特征周围进行小范围扫描,将测量微调到给定的精度。
Args:
best_f (int): Best found frequency in previous scan. Used as starting point.
best_msr (float): MSR found for the previous best frequency. Used to check if a better value is found.
span (int): Search space around previous best value where the next frequency is sampled.
resolution (int): How many points are taken in the span. Taken as 10 for the small scan.
platform (AbstractPlatform): Platform the experiment is executed on.
ro_pulse (ReadoutPulse): Used in order to execute the pulse sequence with the right parameters in the right qubit.
qubit (int): qubit coupled to the resonator that we are probing.
sequence (PulseSequence):
Returns:
best_f (float): Best frequency found for the feature.
best_msr (float): MSR found for the feature.
phase (float): Phase found for the feature.
i (float): In-phase signal.
q (float): Quadrature signal.
"""
start_f = best_f
scan = np.linspace(-span / 2, span / 2, resolution)
for s in scan:
freq = start_f + s
ro_pulse.frequency = freq
result = platform.execute_pulse_sequence(sequence)[ro_pulse.serial]
msr = result.msr.mean()
msr1 = msr
if platform.resonator_type == "3D":
msr = -msr
best_msr = -best_msr
if msr < best_msr:
best_f, best_msr = freq, msr1
return best_f, best_msr, result.phase.mean(), result.i.mean(), result.q.mean()
@plot("Frequency vs Attenuation", frequency_attenuation)
def resonator_punchout_sample(
platform: AbstractPlatform,
qubits: dict,
min_att,
max_att,
step_att,
max_runs,
thr,
spans,
small_spans,
resolution,
points=10,
):
"""Use gaussian samples to extract the punchout of the resonator for different values of attenuation.使用高斯样本提取不同衰减值的谐振器穿孔。
Args:
platform (AbstractPlatform): Platform the experiment is executed on.
qubits (dict): Dict of target Qubit objects to perform the action
min_att (int): minimum attenuation value where the experiment starts. Less attenuation -> more power.实验开始时的最小衰减值。衰减更少->功率更大。
max_att (int): maximum attenuation reached in the scan.扫描中达到最大衰减。
step_att (int): change in attenuation after every step.每步后衰减的变化。
max_runs (int): Maximum amount of tries before stopping if feature is not found.如果找不到特征,停止前的最大尝试次数。
thr (float): SNR value used as threshold for detection of the feature.用作特征检测阈值的SNR值
spans (list): Different spans to search for the feature at different precisions.不同的跨度以不同的精度搜索特征。
small_spans (list): Different spans for the small sweeps to fine-tune the feature.
resolution (int): How many points are taken in the span for the scan_level() function.
points (int): Number of points plotted at a time in qq-live.
Returns:
data (Data): Data file with information on the feature response at each attenuation point.数据(数据):包含每个衰减点的特征响应信息的数据文件。
"""
for qubit in qubits:
data = DataUnits(
name=f"data_q{qubit}", quantities={"frequency": "Hz", "attenuation": "dB"}
)
platform.reload_settings()
sequence = PulseSequence()
ro_pulse = platform.create_qubit_readout_pulse(qubit, start=0)
sequence.add(ro_pulse)
resonator_frequency = qubits[qubit].readout_frequency
attenuation_range = np.arange(min_att, max_att, step_att)
best_f = resonator_frequency
opt_att = 30
opt_snr = 0
for k, att in enumerate(attenuation_range):
platform.set_attenuation(qubit, att)
background = [best_f + 1e7, best_f - 1e7]
noise = get_noise(background, platform, ro_pulse, qubit, sequence)
best_msr = noise
for span in spans:
best_f, best_msr, phase, i, q = scan_level(
best_f,
best_msr,
max_runs,
thr,
span,
resolution,
noise,
platform,
ro_pulse,
qubit,
sequence,
)
for span in small_spans:
best_f, best_msr, phase, i, q = scan_small(
best_f, best_msr, span, 11, platform, ro_pulse, qubit, sequence
)
results = {
"MSR[V]": best_msr,
"i[V]": i,
"q[V]": q,
"phase[rad]": phase,
"frequency[Hz]": best_f,
"attenuation[dB]": att,
}
data.add(results)
if k % points == 0:
yield data
if att >= opt_att:
if abs(snr(best_msr, noise)) > opt_snr:
opt_snr = abs(snr(best_msr, noise))
opt_att = att
opt_f = best_f
data1 = DataUnits(
name=f"results_q{qubit}",
quantities={"snr": "dimensionless", "frequency": "Hz", "attenuation": "dB"},
)
f_err = len(str(int(small_spans[-1] / 10)))
results = {
"snr[dimensionless]": opt_snr,
"frequency[Hz]": round(opt_f, -f_err),
"attenuation[dB]": opt_att,
}
data1.add(results)
yield data1
yield data
@plot("Frequency vs Current", frequency_bias_flux)
def resonator_flux_sample(
platform: AbstractPlatform,
qubits: dict,
bias_min,
bias_max,
bias_step,
fluxlines,
max_runs,
thr,
spans,
small_spans,
resolution,
params_fit,
points=10,
):
"""Use gaussian samples to extract the flux-frequency response of the resonator for different values of bias.使用高斯样本提取谐振器针对不同偏置值的通量-频率响应。
Args:
platform (AbstractPlatform): Platform the experiment is executed on.
qubits (dict): Dict of target Qubit objects to perform the action
bias_min (float): minimum bias value where the experiment starts.实验开始时的最小偏置值。
bias_max (float): maximum bias reached in the scan.扫描时达到的最大偏置。
bias_step (float): change in bias after every step.
fluxlines (list): ids of the bias lines to use for the experiment. Use qubit if matching the qubit id.用于实验的偏置线的id。如果匹配量子位id,则使用量子位。
max_runs (int): Maximum amount of tries before stopping if feature is not found.
thr (float): SNR value used as threshold for detection of the feature.
spans (list): Different spans to search for the feature at different precisions.
small_spans (list): Different spans for the small sweeps to fine-tune the feature.
resolution (int): How many points are taken in the span for the scan_level() function.
params_fit (dic): Dictionary of parameters for the fit. {qubit : [freq_rh, g, Ec, Ej], ... }.
freq_rh is the resonator frequency at high power and g in the readout coupling.
If Ec and Ej are missing, the fit is valid in the transmon limit and if they are indicated,
contains the next-order correction.
points (int): Number of points plotted at a time in qq-live.
Returns:
data (Data): Data file with information on the feature response at each bias point.
"""
for qubit in qubits:
params_fit = params_fit[qubit]
for fluxline in fluxlines:
data = DataUnits(
name=f"data_q{qubit}_f{fluxline}",
quantities={"frequency": "Hz", "bias": "V"},
)
if fluxline == "qubit":
fluxline = qubit
platform.reload_settings()
for f in fluxlines:
platform.set_bias(qubit, 0)
sequence = PulseSequence()
ro_pulse = platform.create_qubit_readout_pulse(qubit, start=0)
sequence.add(ro_pulse)
resonator_frequency = qubits[qubit].readout_frequency
qubit_biasing_bias = qubits[qubit].sweetspot
platform.set_bias(qubit, qubit_biasing_bias)
bias_range = np.arange(bias_min, bias_max, bias_step) + qubit_biasing_bias
start = next(
(
index
for index, curr in enumerate(bias_range)
if curr >= qubit_biasing_bias
)
)
start_f = resonator_frequency
background = [start_f + 1e7, start_f - 1e7]
noise = get_noise(background, platform, ro_pulse, qubit, sequence)
bias_range = np.concatenate((bias_range[start:], bias_range[:start][::-1]))
index = len(bias_range[start:])
best_f = start_f
for k, curr in enumerate(bias_range):
if k == index:
best_f = start_f
best_msr = noise
platform.set_bias(qubit, curr)
for span in spans:
best_f, best_msr, phase, i, q = scan_level(
best_f,
best_msr,
max_runs,
thr,
span,
resolution,
noise,
platform,
ro_pulse,
qubit,
sequence,
)
for span in small_spans:
best_f, best_msr, phase, i, q = scan_small(
best_f, best_msr, span, 11, platform, ro_pulse, qubit, sequence
)
results = {
"MSR[V]": best_msr,
"i[V]": i,
"q[V]": q,
"phase[rad]": phase,
"frequency[Hz]": best_f,
"bias[V]": curr,
}
data.add(results)
if k % points == 0:
yield data
yield res_spectroscopy_flux_fit(
data,
x="bias[V]",
y="frequency[Hz]",
qubit=qubit,
fluxline=fluxline,
params_fit=params_fit,
)
yield data















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









