






misc40
下载图片是一个png的动图
 使用工具 APNG Disassembler可以进行分离,下载链接:APNG Disassembler download | SourceForge.net
使用工具 APNG Disassembler可以进行分离,下载链接:APNG Disassembler download | SourceForge.net
提取出来不止图片还有txt文本
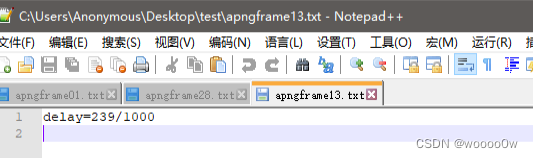
简单看一下等于号后面的数字没有大于256的,尝试使用脚本将ascii转换成字符
flag = ""
for i in range(1,69):
if i < 10:
i = '0'+str(i)
f = open('C:/Users/Anonymous/Desktop/test/apngframe'+str(i)+'.txt')
d = f.read()
flag += chr(int(d[d.find('=')+1:d.find('/')]))
print(flag)
可以看到flag了
misc41
不知道为什么没有了
misc42
看了大佬的wp是使用TweakPNG查看

然后将长度看作ascii码转换为字符
misc 43
先把残缺的png图片修复

根据提示是通过错误信息找出flag看了其他大佬的wp,有的是用 tweakpng 查看,有的是用 pngdebugger 查看错误信息(这里踩了一个坑,如果先修复了图片,用 pngdebugger 是看不出错误信息了)
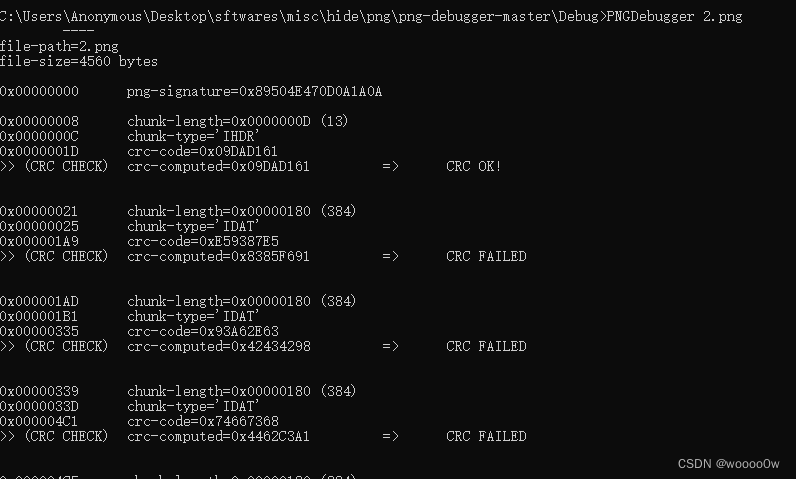
将第一个出现的字符串提取出来转换成二进制,将cmd窗口的内容提取成文本,当做写脚本练习吧
![]()
# -*- coding: UTF-8 -*-
import re
import binascii
s = open("1.txt", "r").read()
data_s = re.findall(r'crc-code=0x([\S]+)\n', s) # 正则匹配,寻找所有以 crc-code=0x 开头,提取后面除空白以为的任意字符串,直到出现换行转义符\n
print(data_s)
flag = ""
for i in data_s:
flag += i
print(flag)
print(binascii.unhexlify(flag)) # 将16进制字符串转换成二进制,然后print会将二进制变成文本字符串进行输出
misc 44
使用 pngdebugger 查看,crc值有错有对,但这题是通过将编号为1152的IDAT段的 ok 换成1,将 FAILED转换为0,写个脚本提取
# -*- coding: UTF-8 -*-
import re
import binascii
s = open("1.txt", "r").read()
data_s = re.findall(r'\(1152\).*?CRC ([FAILED,OK!]+)', s, re.DOTALL) # 匹配(1152)所在的段,直到结尾为FAILED或者OK!结束,在默认情况下.的作用是匹配除了换行符以外的所有字符,这里的re.DOTALL的作用是可以将. 匹配所有换行符
print(data_s)
flag = ""
for i in data_s:
if i == 'OK!':
flag += '1'
else:
flag += '0'
print(flag)解密后有些乱码,但不影响,添加一个 } 的flag是正确的

misc 45
这题的提示是:有时候也需要换一换思维格式
但还是不知道怎么做,看了别的大佬的writup,是需要将这个png转换成bmp,感觉这题有点脑洞了。转换网址:PNG转BMP - 免费在线将PNG文件转换成BMP (cdkm.com)
最后再用 binwalk 将它提取出来

提取出来的图片就是flag了
但是原理还是不太懂,为什么文件格式为png时就提取不出来,看了很多wp,得出的理由是 png 和 bmp 的像素读取方式不一样
misc 46
又是得看wp的一题,还是太菜了,学习嘛,不寒碜
这题的附件是一个近600张的gif,通过identify查看它的偏移量(identify貌似只能在linux中使用)

提取它每次偏移的值当做坐标,再作图
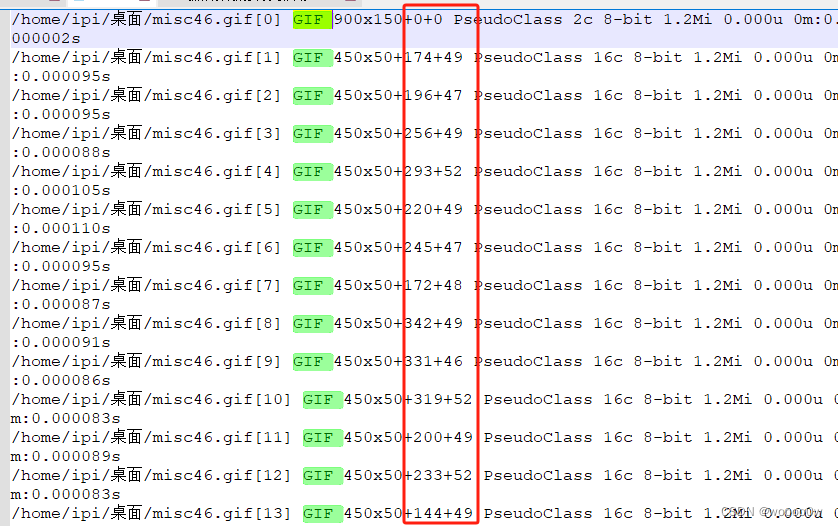
上脚本
import re
import matplotlib.pyplot as plt
from PIL import Image
f = open("1.txt", "r")
s = f.read()
# 正则表达式寻找偏移量
data_s = re.findall(r'GIF .*?\+(\d+)\+(\d+)', s, re.DOTALL)
# 将data_s里的坐标从str类型转换成int类型,不然后面的坐标不能识别
data_s = [[int(i) for i in j]for j in data_s]
# 创建一个新的RGB图像,大小为400*70的像素,背景颜色为白色(RGB的值为(255,255,255))
img = Image.new('RGB', (400, 100), (255, 255, 255))
# 创建一个新的RGB图像,大小为1*1的像素,背景颜色为黑色(RGB的值为(0,0,0))
new = Image.new('RGB', (1, 1), (0, 0, 0))
# 循环每次的坐标
for i in data_s:
# 将new(黑色像素点)粘贴到img(白色像素点)上,相当于填充
img.paste(new, i)
# 显示img图像
plt.imshow(img)
# 显示窗口以查看图像
plt.show()
misc 47
打开附件又是一个动图,但文件后缀是png,应该跟根据提示感觉跟上题的做法差不多,通过找偏移量画图,但是这类动图的偏移量不知道怎么找,看看其他大佬的wp

了解到通常这类图片称为apng,关于apng文件结构的了解可以看这篇文章Web 端 APNG 播放实现原理 - 知乎 (zhihu.com)
可以在010里看它的偏移值,在fcTL模块里可以看到它每次的偏移量

010可以将文件导出为16进制文本,然后上脚本提取
import matplotlib.pyplot as plt
from PIL import Image
import re
f = open("misc47.txt", "r")
s = f.read().replace(' ', '').replace('\n', '') # 将16进制的文本转换为长字符串,方便后面正则匹配提取
data_s = re.findall(r'6663544C.{24}0000(.{4})0000(.{4})', s, re.DOTALL) # 正则匹配提取偏移值(x,y)
data_s = [[int(i, 16) for i in j]for j in data_s] # 提取出来的数据还是一个16进制的str型字符串,所以需要转换成十进制的int型
# 提取坐标后作图
img = Image.new("RGB", (400, 100), (255, 255, 255))
pen = Image.new("RGB", (1,1), (0, 0, 0))
for i in data_s:
img.paste(pen, i)
print(len(data_s))
plt.imshow(img)
plt.show()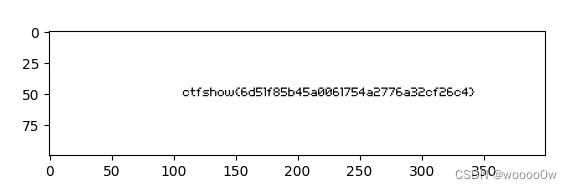
misc 48
先用010打开附件,可以看到一个提示
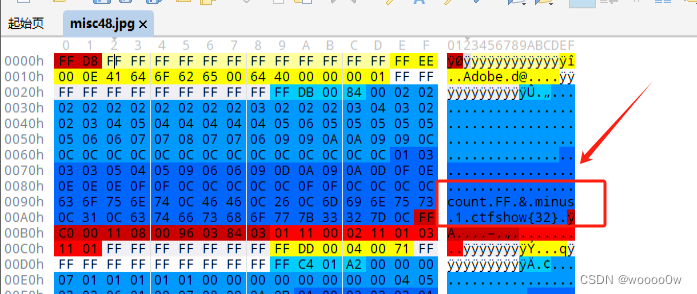
这个提示是说计算FF的格式并且每次减1,flag有32位
起初写了脚本只提取了前32个FF的个数减1,后面发现和其他大佬的wp不一样,原来是需要统计每两个有意义块之间的FF的数量再减一,因为每两个有意义块之间插入数据好像是不太影响的,至于要减一是因为这段中的最后一个FF是下一个有意义块的开头,取前32个段,然后将大于9的数字转换成16进制,确实有脑洞。
上个脚本
import re
f = open("misc48.txt", "r")
s = f.read().replace('\n', ' ') # 将换行符去掉,方便后面正则匹配提取
f.close()
data_s = re.findall('FF [FF ]*', s) # 正则匹配提取FF
num_list = [str(i).count('FF')for i in data_s] # 计算在提取出来的FF有多少个
num_list = [(i-1)for i in num_list]
print(num_list[:32])
flag = ''
for i in num_list[:32]:
if i > 9:
i = hex(i)[2:] # 去掉转换后开头多出的0x
flag += str(i)
print(flag)
misc 49
脑洞题,还好看了下wp,不然真想不到,这题就当练习下自己的脚本能力了
右边每串可识别的英文单词前都会有FFE加上个数字,把后面的这个数字提取出来就是再进行16进制的
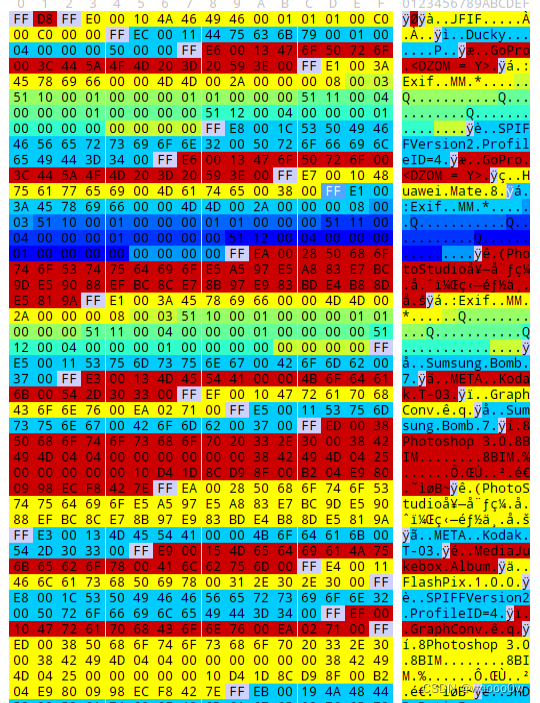
直接上脚本,有一个小坑,最好提取出来的大写字母还得换成小写
import re
f = open("misc49.txt", "r")
s = f.read().replace('\n', ' ')
f.close()
data_s = re.findall(r"FF E(.)", s)
print(len(data_s))
flag = ''
for i in data_s:
flag += i
flag = flag.lower()
print(flag)misc 50
直接用stegsolve工具逐一换颜色通道,就能看到flag,然后拼接起来
misc 51
还是先用stegsolve看一遍,没有发现,看看其他大佬的writup,看来是要写脚本提取出颜色比较异常的像素点,就借鉴了其他大佬的脚本来学习
import matplotlib.pyplot as plt
from PIL import Image
im = Image.open("misc51.png") # 使用Image模块的open方法打开名为'misc51.png'的图片。
im = im.convert('RGB') # 将图片转为RGB模式
image = Image.new("RGB", (900, 150)) # 创建一个宽高分别为900,150的RGB图像
pen = Image.new("RGB", (1, 1), (255, 255, 255)) # 创建一个白色的像素点图像
dic = {} # 创建字典
for x in range(900): # 图像的横向坐标
for y in range(150): # 图像的纵向坐标
s = im.getpixel((x, y)) # 提取每个像素点的颜色
dic[s] = dic.get(s, 0) + 1 # 对每个的像素点的颜色放进字典里,并统计数量
list_s = list(dic.items()) # 字典转换成列表
list_s.sort(key=lambda x: x[-1]) # 进行排序,接受一个key的函数,按照key中的条件进行排序,匿名函数(lambda函数),它的参数x表示列表中的每个元素,而x[-1]表示每个元素的最后一个元素。因此,这段代码将按照每个元素的最后一个元素进行排序。
print(list_s)
for x in range(900):
for y in range(150):
s = im.getpixel((x, y))
if s == (128, 96, 64) or s == (64,96,128) :
image.paste(pen, (x, y)) # 将符合要求的像素点位置标白
plt.imshow(image)
plt.show()通过一个排序可以看到比较异常的两个颜色,相比其他颜色要多得多,最好一个循环就是将符合这两种颜色的像素点位置在另一张创建还的图画上白色像素点

flag就出来了
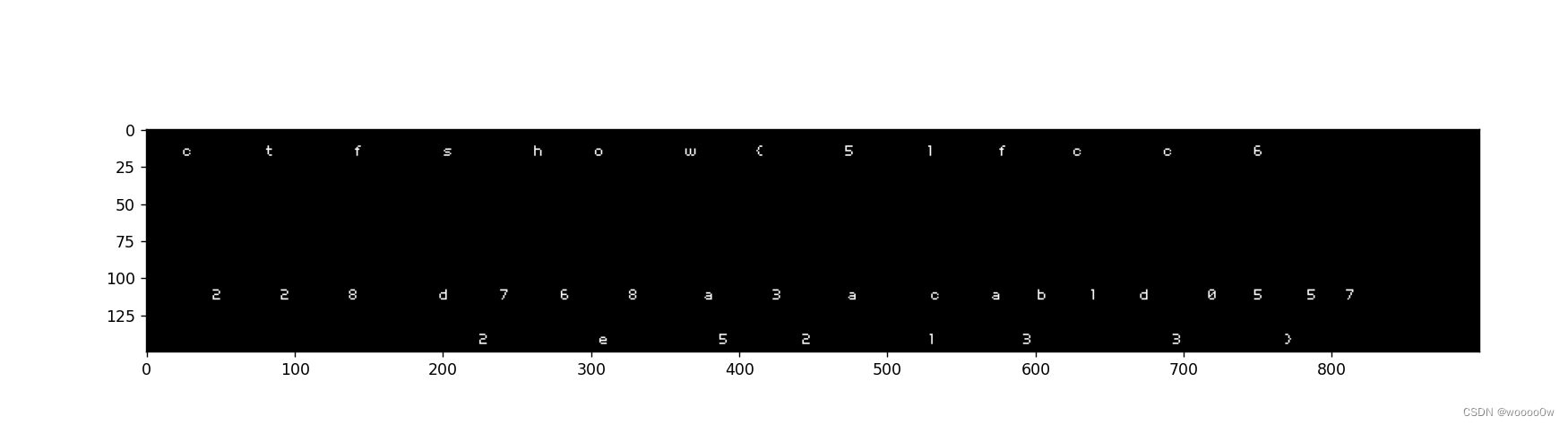
misc 52
用脚本提取图片出现次数最少的十个颜色位置,上脚本
import matplotlib.pyplot as plt
from PIL import Image
im = Image.open("misc52.png") # 使用Image模块的open方法打开名为'misc51.png'的图片。
im = im.convert('RGB') # 将图片转为RGB模式
image = Image.new("RGB", (900, 150)) # 创建一个宽高分别为900,150的RGB图像
pen = Image.new("RGB", (1, 1), (255, 255, 255)) # 创建一个白色的像素点图像
dic = {} # 创建字典
for x in range(900): # 图像的横向坐标
for y in range(150): # 图像的纵向坐标
s = im.getpixel((x, y)) # 提取每个像素点的颜色
dic[s] = dic.get(s, 0) + 1 # 对每个的像素点的颜色放进字典里,并统计数量
list_s = list(dic.items()) # 字典转换成列表
list_s.sort(key=lambda x: x[-1]) # 进行排序,接受一个key的函数,按照key中的条件进行排序,匿名函数(lambda函数),它的参数x表示列表中的每个元组,而x[-1]表示每个元素的最后一个元素。因此,这段代码将按照每个元素的最后一个元素进行排序。
print(list_s)
for x in range(900):
for y in range(150):
s = im.getpixel((x, y))
if s in [i[0] for i in list_s[:10]]: # 遍历切片list_s列表的前十个元组的第一个元素
image.paste(pen, (x, y)) # 将符合要求的像素点位置标白
plt.imshow(image)
plt.show()
misc 53
zsteg一把梭,或者stegsolve提取数据

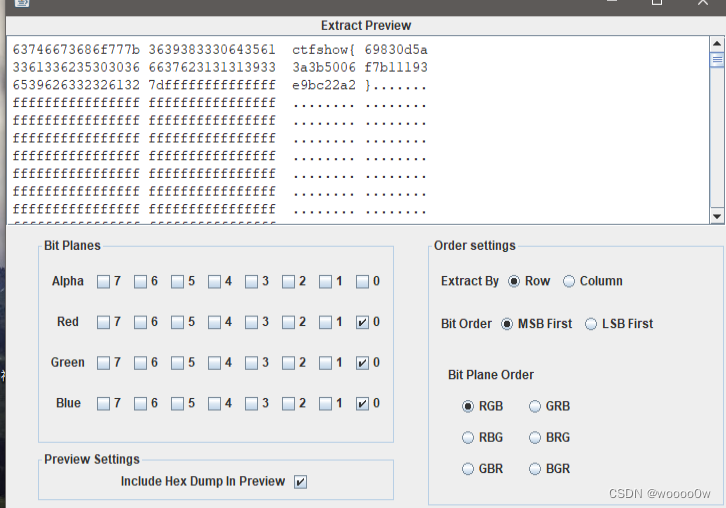
misc 54
用stegesolve打开图片,查看个通道时发现,alpha0,green0,blue0都藏着一段小字
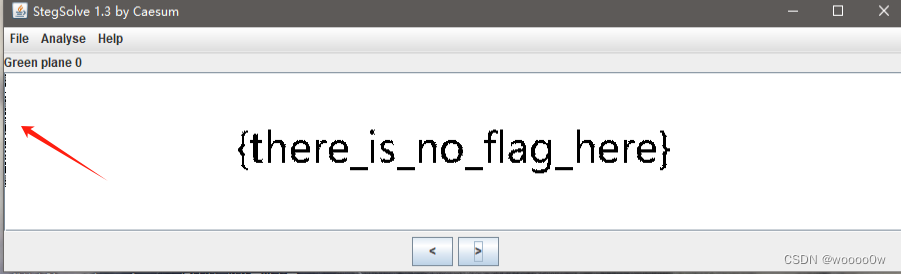
提取数据,因为是打竖排的所以选择Column,但是下面的为什么选RBG,BRG,BGR都可以提取成功,另外3个却不行
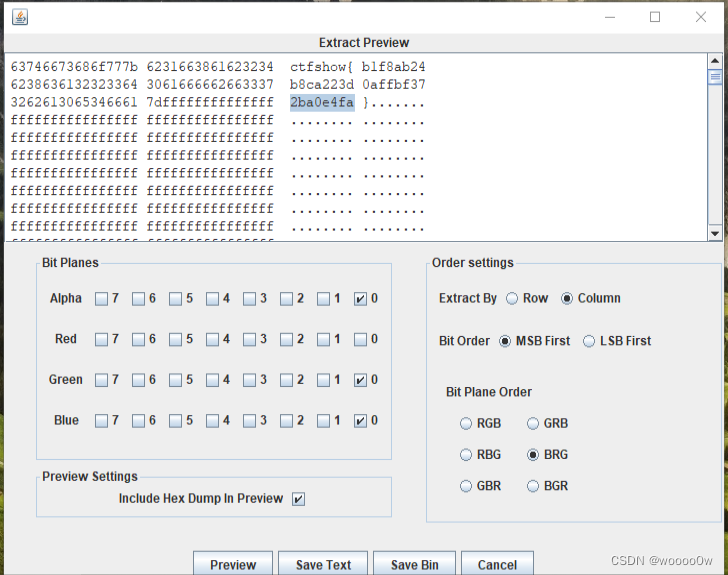
misc 55
打开图片发现是被翻转过的图片,先用美图秀秀将图片垂直翻转回来
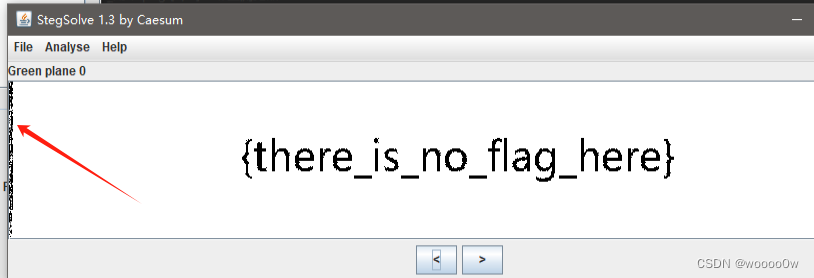
然后用stegsolve进行查看,发现红蓝绿都有隐藏的东西
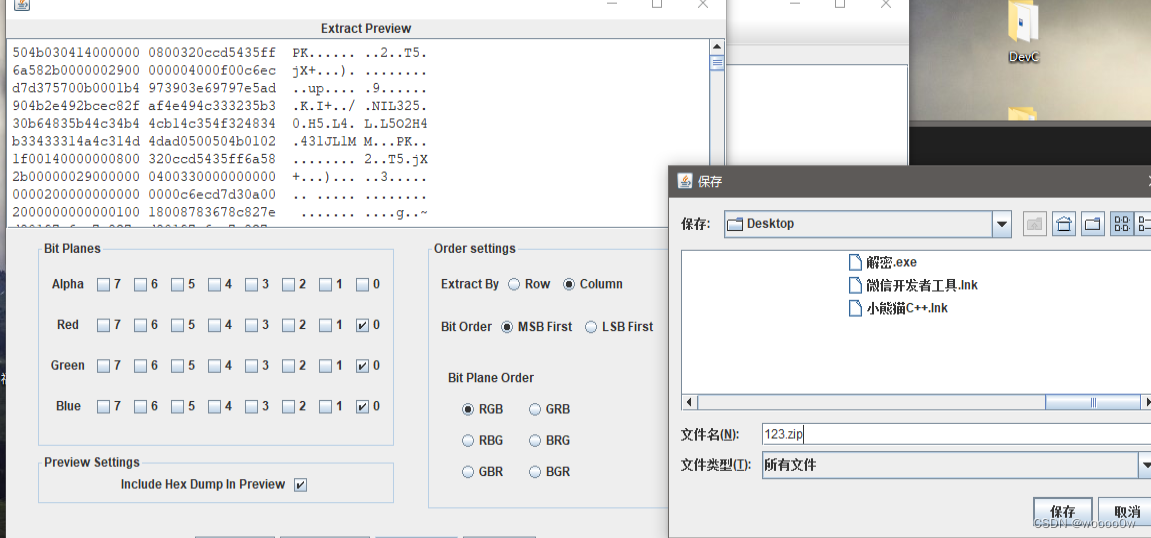
提取之后发现开头的是PK文件,将其保存为zip压缩文件
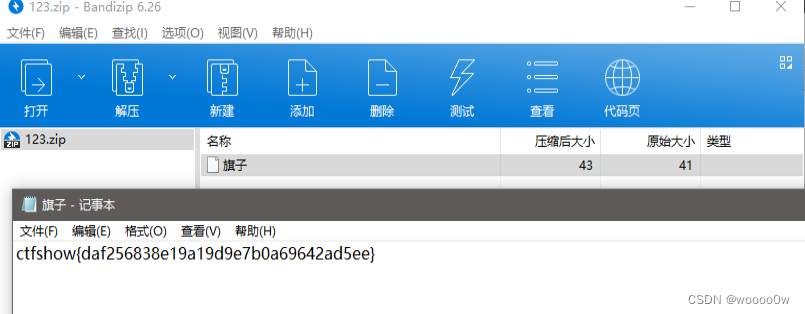
打开zip就能发现flag















 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









