










🌟 大家好,我是摘星! 🌟
今天为大家带来的是并发设计模式实战系列,第五章生产者/消费者模式,废话不多说直接开始~
目录
一、核心原理深度拆解
1. 生产消费协作模型
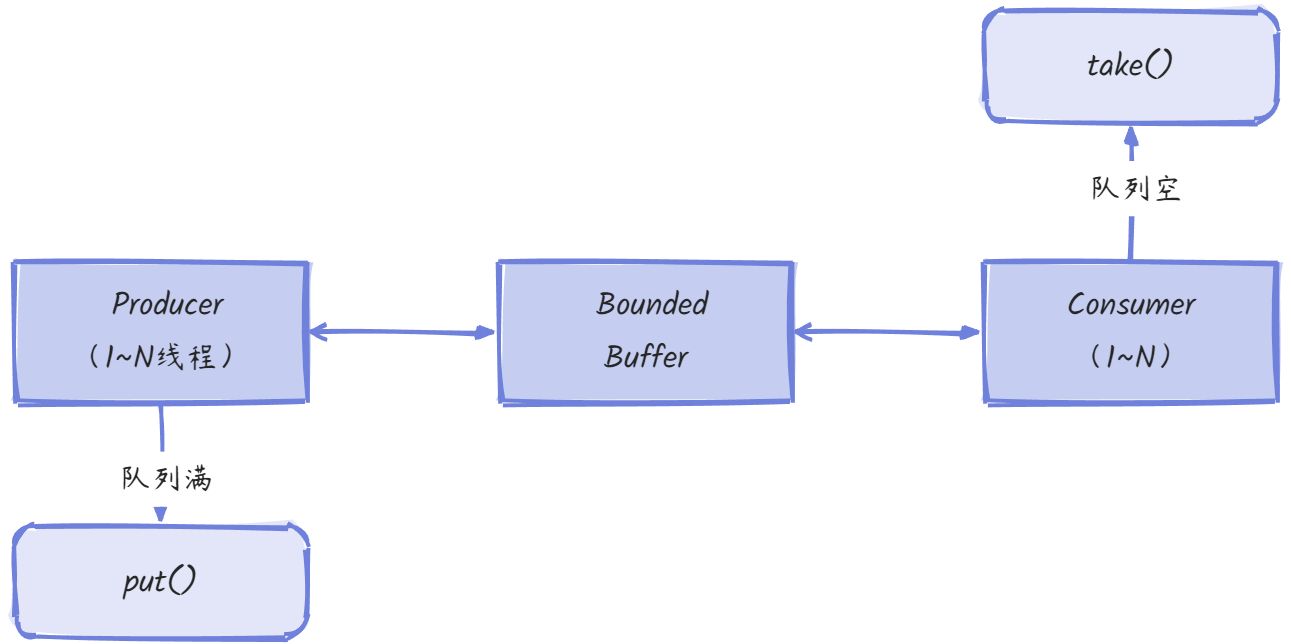
- 缓冲区作用:解耦生产消费节奏差异,防止数据丢失或系统崩溃
- 关键机制:
-
- 阻塞插入:当队列满时生产者自动挂起(put()方法)
- 阻塞获取:当队列空时消费者自动挂起(take()方法)
- 流量控制:通过队列容量实现背压(Backpressure)机制
2. 线程安全实现原理
// Java中的LinkedBlockingQueue核心实现
public void put(E e) throws InterruptedException {
final ReentrantLock putLock = this.putLock; // 分离读写锁
putLock.lockInterruptibly();
try {
while (count.get() == capacity) {
notFull.await(); // 队列满时自动阻塞
}
enqueue(e);
if (count.getAndIncrement() + 1 < capacity)
notFull.signal(); // 仅唤醒生产者
} finally {
putLock.unlock();
}
}二、生活化类比:餐厅传菜系统
| 系统组件 | 现实类比 | 核心规则 |
| 生产者 | 厨房厨师 | 3个灶台最多同时做5道菜 |
| 缓冲区 | 传菜窗口 | 最多容纳20盘菜(防堆积) |
| 消费者 | 服务员团队 | 根据顾客数量动态调整人手 |
- 流量高峰应对:
-
- 午餐高峰:传菜窗口填满 → 厨师暂停做新菜 → 服务员优先送菜
- 空闲时段:窗口保持5盘以下 → 厨师做特色菜预备
三、Java代码实现(生产级Demo)
1. 完整可运行代码
import java.util.concurrent.*;
public class ProducerConsumerDemo {
// 有界阻塞队列(Array实现更严格的控制)
private final BlockingQueue<String> buffer = new ArrayBlockingQueue<>(20);
// 生产者配置
class Producer implements Runnable {
private final String[] menu = {"鱼香肉丝", "宫保鸡丁", "水煮鱼"};
@Override
public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
String dish = menu[ThreadLocalRandom.current().nextInt(menu.length)];
buffer.put(dish); // 自动阻塞直到有空位
System.out.println("[厨师] 制作完成:" + dish + " | 窗口存量:" + buffer.size());
Thread.sleep(500); // 模拟烹饪时间
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 消费者配置
class Consumer implements Runnable {
@Override
public void run() {
try {
while (!Thread.currentThread().isInterrupted()) {
String dish = buffer.take(); // 自动阻塞直到有菜品
System.out.println("[服务员] 送出:" + dish + " | 剩余:" + buffer.size());
Thread.sleep(800); // 模拟送餐时间
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
// 启动系统
public void startSystem() {
ExecutorService producers = Executors.newFixedThreadPool(3);
ExecutorService consumers = Executors.newCachedThreadPool();
// 启动3个生产者(3个厨师)
for (int i = 0; i < 3; i++) {
producers.submit(new Producer());
}
// 启动动态消费者(根据队列负载)
new Thread(() -> {
while (true) {
int idealConsumers = Math.max(1, buffer.size() / 5); // 每5盘菜1个服务员
adjustConsumerCount(idealConsumers, consumers);
try {
Thread.sleep(3000); // 每3秒动态调整
} catch (InterruptedException e) {
break;
}
}
}).start();
}
// 动态调整消费者数量
private void adjustConsumerCount(int target, ExecutorService pool) {
int current = ((ThreadPoolExecutor) pool).getActiveCount();
if (target > current) {
for (int i = current; i < target; i++) {
pool.submit(new Consumer());
}
}
}
public static void main(String[] args) {
new ProducerConsumerDemo().startSystem();
}
}2. 关键配置说明
// 生产者线程池:固定数量(对应物理灶台数量)
Executors.newFixedThreadPool(3);
// 消费者线程池:动态调整(根据队列负载)
Executors.newCachedThreadPool();
// 队列选择:ArrayBlockingQueue vs LinkedBlockingQueue
// - ArrayBlockingQueue:固定容量,更严格的内存控制
// - LinkedBlockingQueue:节点链接,适合频繁插入删除四、横向对比表格
1. 多线程模式对比
| 模式 | 数据流向 | 资源控制 | 适用场景 |
| Producer-Consumer | 单向管道 | 队列容量限制 | 数据流水线处理 |
| Worker Thread | 任务直接分发 | 线程池大小限制 | 同质化任务处理 |
| Pipeline | 多级处理 | 各阶段独立控制 | 复杂数据处理流程 |
| Publish-Subscribe | 广播模式 | 主题分区控制 | 事件通知系统 |
2. 阻塞队列实现对比
| 队列类型 | 锁机制 | 内存占用 | 吞吐量 |
| ArrayBlockingQueue | 单锁+两个条件队列 | 连续内存 | 中高 |
| LinkedBlockingQueue | 双锁分离 | 分散内存 | 高 |
| PriorityBlockingQueue | 全局锁 | 堆结构 | 中 |
| SynchronousQueue | 无缓存 | 最低 | 极高 |
五、高级优化技巧
1. 消费者批量处理
// 批量获取提高吞吐量
List<String> batch = new ArrayList<>(10);
int count = buffer.drainTo(batch, 10); // 一次性取10个
if (count > 0) {
processBatch(batch);
}2. 优先级控制
// 使用优先级队列(需实现Comparator)
BlockingQueue<Order> queue = new PriorityBlockingQueue<>(20,
(o1, o2) -> o2.getVIPLevel() - o1.getVIPLevel());3. 死锁预防策略
// 设置超时时间的插入/获取
boolean success = buffer.offer(dish, 1, TimeUnit.SECONDS);
if (!success) {
log.warn("菜品无法及时制作:{}", dish);
}六、扩展:生产者-消费者模式的进阶应用
1. 分布式场景下的扩展
1.1 跨节点消息队列(Kafka架构思想)

- 分区策略:将数据拆分到多个队列(Partition),实现并行处理
- 消费组机制:同一消费组的消费者共享队列,不同消费组独立消费
- 重平衡协议:动态调整消费者与分区的映射关系
1.2 代码示例(基于Kafka API)
// 生产者配置
Properties producerProps = new Properties();
producerProps.put("bootstrap.servers", "kafka1:9092,kafka2:9092");
producerProps.put("key.serializer", StringSerializer.class.getName());
producerProps.put("value.serializer", StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(producerProps);
producer.send(new ProducerRecord<>("orders", "order-123", "VIP订单内容"));
// 消费者配置
Properties consumerProps = new Properties();
consumerProps.put("group.id", "order-processors");
consumerProps.put("bootstrap.servers", "kafka1:9092");
consumerProps.put("key.deserializer", StringDeserializer.class.getName());
consumerProps.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
consumer.subscribe(Collections.singletonList("orders"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
processOrder(record.value());
}
}2. 流量塑形策略
2.1 动态速率控制
| 策略类型 | 实现方法 | 适用场景 |
| 令牌桶 | 限制单位时间内放入队列的数量 | 突发流量平滑处理 |
| 漏桶算法 | 恒定速率消费,不受生产速度影响 | 严格限制处理速率 |
| 背压反馈 | 根据队列负载动态调整生产速率 | 实时响应系统 |
2.2 令牌桶实现示例
class RateLimiter {
private final Semaphore tokens;
private final ScheduledExecutorService refiller;
RateLimiter(int permitsPerSecond) {
this.tokens = new Semaphore(permitsPerSecond);
this.refiller = Executors.newSingleThreadScheduledExecutor();
refiller.scheduleAtFixedRate(() -> {
int current = tokens.availablePermits();
if (current < permitsPerSecond) {
tokens.release(permitsPerSecond - current);
}
}, 0, 1, TimeUnit.SECONDS);
}
void acquire() throws InterruptedException {
tokens.acquire();
}
}
// 在生产线程中使用
rateLimiter.acquire();
buffer.put(item);3. 容错机制设计
3.1 失败处理策略对比
| 策略 | 实现方式 | 数据一致性 | 系统影响 |
| 立即重试 | 在消费线程中直接重试 | 强一致 | 可能阻塞处理流程 |
| 死信队列 | 将失败消息存入特殊队列 | 最终一致 | 不影响主流程 |
| 定时重扫 | 定期检查未完成的消息 | 弱一致 | 额外存储开销 |
3.2 死信队列实现
// 主工作队列
BlockingQueue<Message> mainQueue = new LinkedBlockingQueue<>();
// 死信队列
BlockingQueue<Message> dlq = new LinkedBlockingQueue<>();
class Consumer implements Runnable {
@Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
Message msg = mainQueue.take();
try {
process(msg);
} catch (Exception e) {
if (msg.getRetryCount() < 3) {
msg.incRetryCount();
mainQueue.put(msg);
} else {
dlq.put(msg); // 进入死信队列
}
}
}
}
}
// 单独的死信处理线程
new Thread(() -> {
while (true) {
Message failedMsg = dlq.take();
alertAdmin(failedMsg);
archive(failedMsg);
}
}).start();七、性能调优监控
1. 关键监控指标
| 指标类别 | 具体指标 | 健康阈值 |
| 队列健康度 | 当前队列大小 / 队列容量 | <80% |
| 生产速率 | 单位时间放入队列的数量 | 根据系统处理能力设定 |
| 消费延迟 | 消息从入队到出队的时间差 | <业务允许最大延迟 |
| 错误率 | 处理失败消息占总消息量的比例 | <0.1% |
2. Java Flight Recorder监控配置
# 启动JFR记录
java -XX:StartFlightRecording=duration=60s,filename=recording.jfr \
-jar your-application.jar
# 分析队列状态
使用JDK Mission Visualizer查看:
- jdk.BlockingQueue$Take 事件
- jdk.BlockingQueue$Offer 事件
- 线程池的活跃线程数统计八、模式组合应用
1. 生产者-消费者 + 观察者模式
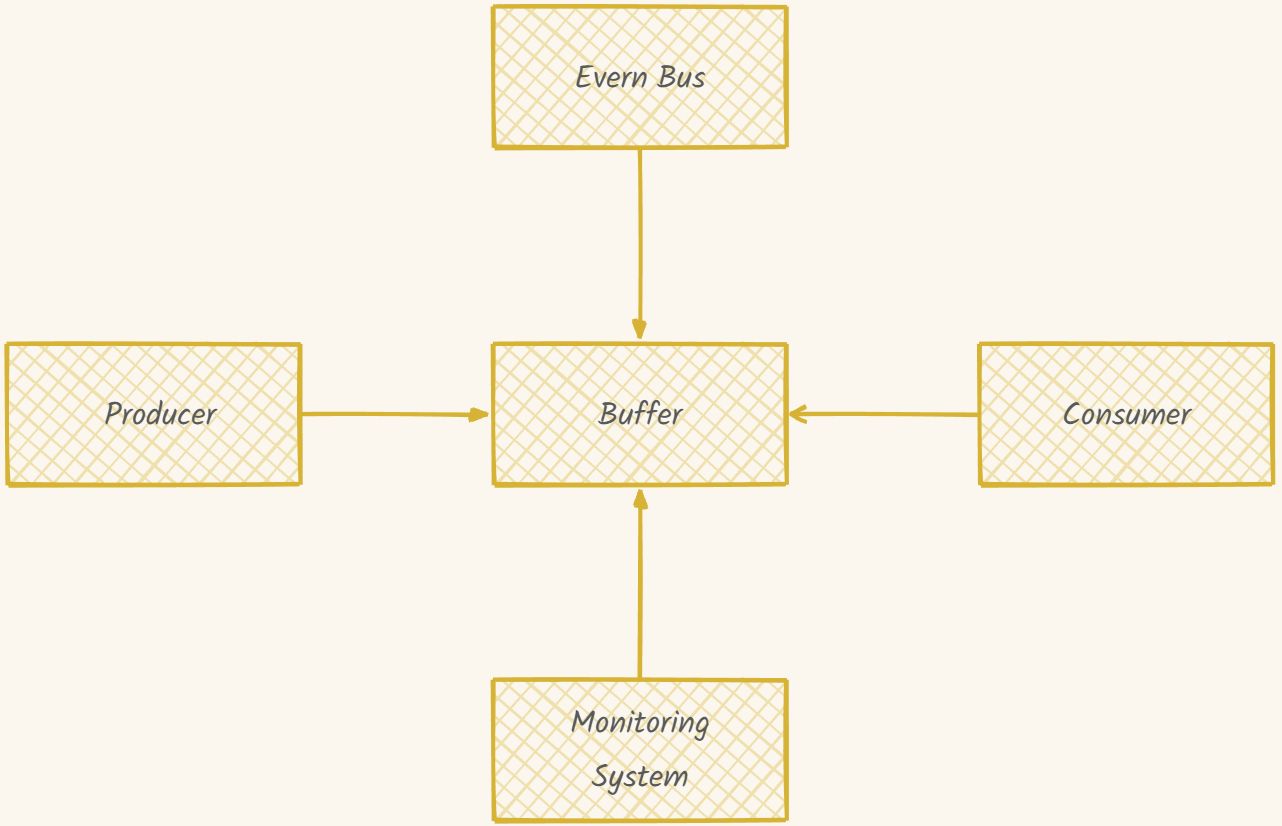
- 应用场景:实现实时监控告警系统
- 优势:解耦业务处理与监控逻辑
2. 多级流水线处理
// 三级处理流水线
BlockingQueue<RawData> inputQueue = new LinkedBlockingQueue<>();
BlockingQueue<ProcessedData> stage1Queue = new LinkedBlockingQueue<>();
BlockingQueue<FinalResult> stage2Queue = new LinkedBlockingQueue<>();
// 第一级:数据清洗
new Thread(() -> {
while (true) {
RawData data = inputQueue.take();
ProcessedData cleaned = cleanData(data);
stage1Queue.put(cleaned);
}
}).start();
// 第二级:业务计算
new Thread(() -> {
while (true) {
ProcessedData data = stage1Queue.take();
FinalResult result = calculate(data);
stage2Queue.put(result);
}
}).start();
// 第三级:结果存储
new Thread(() -> {
while (true) {
FinalResult result = stage2Queue.take();
saveToDatabase(result);
}
}).start();

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









