







 redis理论知识1. 什么是缓存雪崩?怎么解决?通常,会使用缓存用于缓冲对 DB 的冲击。但是如果缓存宕机,所有请求将直接打在 DB,造成 DB 宕机——从而导致整个系统宕机,这就是缓存雪崩。如何解决呢?对缓存做高可用:搭建redis集群,防止缓存宕机限流降级:使用断路器,如果缓存宕机,为了防止系统全部宕机,限制部分流量(通过加锁或者队列来控制线程数量)进入DB,保证部分可用,其余的请求返回断路器的默认值。数据预热:在正式部署之前,先将可能的数据预先进行访问一遍,将大部分的数据都加载
redis理论知识1. 什么是缓存雪崩?怎么解决?通常,会使用缓存用于缓冲对 DB 的冲击。但是如果缓存宕机,所有请求将直接打在 DB,造成 DB 宕机——从而导致整个系统宕机,这就是缓存雪崩。如何解决呢?对缓存做高可用:搭建redis集群,防止缓存宕机限流降级:使用断路器,如果缓存宕机,为了防止系统全部宕机,限制部分流量(通过加锁或者队列来控制线程数量)进入DB,保证部分可用,其余的请求返回断路器的默认值。数据预热:在正式部署之前,先将可能的数据预先进行访问一遍,将大部分的数据都加载
redis理论知识
1. 什么是缓存雪崩?怎么解决?
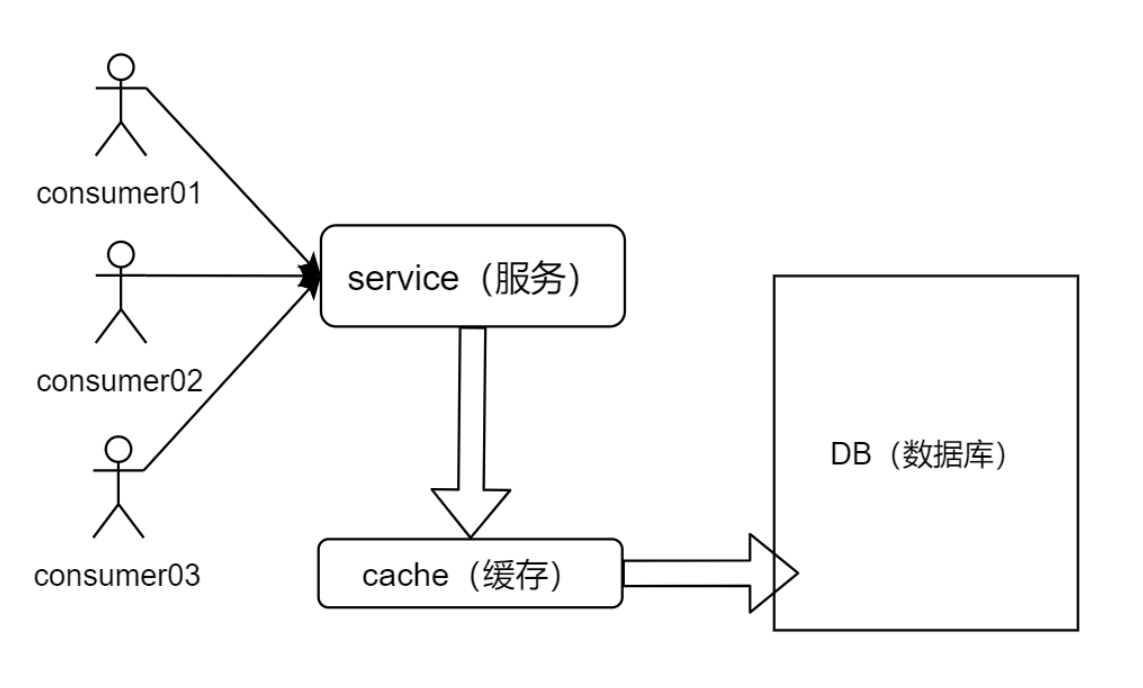
通常,会使用缓存用于缓冲对 DB 的冲击。
但是如果缓存宕机,所有请求将直接打在 DB,造成 DB 宕机——从而导致整个系统宕机,这就是缓存雪崩。
如何解决呢?
- 对缓存做高可用:搭建redis集群,防止缓存宕机
- 限流降级:使用断路器,如果缓存宕机,为了防止系统全部宕机,限制部分流量(通过加锁或者队列来控制线程数量)进入DB,保证部分可用,其余的请求返回断路器的默认值。
- 数据预热:在正式部署之前,先将可能的数据预先进行访问一遍,将大部分的数据都加载到缓存中,设置不同的过期时间,让缓存失效的时间尽量均匀。
2. 什么是缓存穿透?怎么解决?
缓存穿透:用户在缓存中查询一个没有的 key,即缓存没有命中,就去数据库中进行查询,同时数据库也没有,如果黑客大量的使用这种方式,那么就会导致 DB 宕机。
解决方案:
- 布隆过滤器:布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式进行存储,在控制层进行校验,把不符合规则的请求丢弃,从而避免对底层存储系统的查询压力。
- 我们可以使用一个默认值来防止,例如,当访问一个不存在的 key,然后再去访问数据库,还是没有,那么就在缓存里放一个占位符,下次来的时候,检查这个占位符,如果发生时占位符,就不去数据库查询了,防止 DB 宕机。
3. 什么是缓存击穿?怎么解决?
缓存击穿:一个key是个热点访问的数据,在扛着高并发,当某个时间点,该缓存失效导致大量的请求都打到了数据库中,从而导致DB瞬间压力过大而宕机。
解决方案:
- 设置热点数据的过期时间
- 使用分布式锁,可以在这些请求代码加上双重检查锁。但是那个阶段的请求会变慢。不过总比DB 宕机好。
4. 什么是缓存并发竞争?怎么解决?
解释:多个客户端写一个 key,如果顺序错了,数据就不对了。但是顺序我们无法控制。
解决方案:使用分布式锁,例如 zk,同时加入数据的时间戳。同一时刻,只有抢到锁的客户端才能写入,同时,写入时,比较当前数据的时间戳和缓存中数据的时间戳。
5. redis过期策略
(1)三种过期策略
-
定时删除
- 含义:在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
- 优点:保证内存被尽快释放
- 缺点:
- 若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
- 定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
-
惰性删除
- 含义:每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
- 优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
- 缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
-
定期删除
- 含义:每隔一段时间执行一次删除过期key操作
Redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,默认每 100ms 进行一次过期扫描 - 优点:
- 通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用–处理"定时删除"的缺点
- 定期删除过期key-------处理"惰性删除"的缺点
- 缺点
- 在内存友好方面,不如"定时删除"
- 在CPU时间友好方面,不如"惰性删除"
- 难点
- 合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
- 含义:每隔一段时间执行一次删除过期key操作
(2)Redis采用的过期策略
惰性删除+定期删除
-
惰性删除流程
① 在进行get或setnx等操作时,先检查key是否过期,
② 若过期,删除key,然后执行相应操作;
③ 若没过期,直接执行相应操作 -
定期删除流程(简单而言,对指定个数个库的每一个库随机删除小于等于指定个数个过期key)
① 遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
②检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
- 如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
- 随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
- 判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。
(3)内存淘汰机制
如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?-----------走内存淘汰机制。LRU以及LFU等
redis 内存淘汰机制有以下几个:
• noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了。
• allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
• allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的 key 给干掉啊。
• volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key(这个一般不太合适)。
• volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key。
• volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除。
Redis 4.0 里引入了一个新的淘汰策略 —— LFU(Least Frequently Used) 模式,它比 LRU 更加优秀。
LFU 表示按最近的访问频率进行淘汰,它比 LRU 更加精准地表示了一个 key 被访问的热度。
6. Redis 持久化之RDB和AOF
6.1 RDB
RDB 是 Redis 默认的持久化方案。在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中。即在指定目录下生成一个dump.rdb文件。Redis 重启会通过加载dump.rdb文件恢复数据。
(1)RDB详解
① 从配置文件了解RDB
打开 redis.conf 文件,找到 SNAPSHOTTING 对应内容
1 RDB核心规则配置(重点)
save <seconds> <changes>
# save ""
save 900 1
save 300 10
save 60 10000
解说:save <指定时间间隔> <执行指定次数更新操作>,满足条件就将内存中的数据同步到硬盘中。官方出厂配置默认是 900秒内有1个更改,300秒内有10个更改以及60秒内有10000个更改,则将内存中的数据快照写入磁盘。
若不想用RDB方案,可以把 save “” 的注释打开,下面三个注释。
2 指定本地数据库文件名,一般采用默认的 dump.rdb
dbfilename dump.rdb
3 指定本地数据库存放目录,一般也用默认配置
dir ./
4 默认开启数据压缩
rdbcompression yes
解说:配置存储至本地数据库时是否压缩数据,默认为yes。Redis采用LZF压缩方式,但占用了一点CPU的时间。若关闭该选项,但会导致数据库文件变的巨大。建议开启。
② 触发RDB快照
1 在指定的时间间隔内,执行指定次数的写操作
2 执行save(阻塞, 只管保存快照,其他的等待) 或者是bgsave (异步)命令
3 执行flushall 命令,清空数据库所有数据,意义不大。
4 执行shutdown 命令,保证服务器正常关闭且不丢失任何数据,意义也不大。
③ 通过RDB文件恢复数据
将dump.rdb 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可。在实际开发中,一般会考虑到物理机硬盘损坏情况,选择备份dump.rdb 。可以从下面的操作演示中可以体会到。
(2)RDB 的优缺点
优点:
1 适合大规模的数据恢复。
2 如果业务对数据完整性和一致性要求不高,RDB是很好的选择。
缺点:
1 数据的完整性和一致性不高,因为RDB可能在最后一次备份时宕机了。
2 备份时占用内存,因为Redis 在备份时会独立创建一个子进程,将数据写入到一个临时文件(此时内存中的数据是原来的两倍哦),最后再将临时文件替换之前的备份文件。
所以Redis 的持久化和数据的恢复要选择在夜深人静的时候执行是比较合理的。
(3)操作演示
[root@itdragon bin]# vim redis.conf
save 900 1
save 120 5
save 60 10000
[root@itdragon bin]# ./redis-server redis.conf
[root@itdragon bin]# ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set key1 value1
OK
127.0.0.1:6379> set key2 value2
OK
127.0.0.1:6379> set key3 value3
OK
127.0.0.1:6379> set key4 value4
OK
127.0.0.1:6379> set key5 value5
OK
127.0.0.1:6379> set key6 value6
OK
127.0.0.1:6379> SHUTDOWN
not connected> QUIT
[root@itdragon bin]# cp dump.rdb dump_bk.rdb
[root@itdragon bin]# ./redis-server redis.conf
[root@itdragon bin]# ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> FLUSHALL
OK
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> SHUTDOWN
not connected> QUIT
[root@itdragon bin]# cp dump_bk.rdb dump.rdb
cp: overwrite `dump.rdb'? y
[root@itdragon bin]# ./redis-server redis.conf
[root@itdragon bin]# ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
1) "key5"
2) "key1"
3) "key3"
4) "key4"
5) "key6"
6) "key2"
第一步:vim 修改持久化配置时间,120秒内修改5次则持久化一次。
第二步:重启服务使配置生效。
第三步:分别set 5个key,过两分钟后,在bin的当前目录下会自动生产一个dump.rdb文件。(set key6 是为了验证shutdown有触发RDB快照的作用)
第四步:将当前的dump.rdb 备份一份(模拟线上工作)。
第五步:执行FLUSHALL命令清空数据库数据(模拟数据丢失)。
第六步:重启Redis服务,恢复数据。数据是空的?这是因为FLUSHALL也有触发RDB快照的功能。
第七步:将备份的 dump_bk.rdb 替换 dump.rdb 然后重新Redis。
6.2 AOF
(1)AOF详解
AOF :Redis 默认不开启。它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
① 从配置文件了解AOF
打开 redis.conf 文件,找到 APPEND ONLY MODE 对应内容
1 redis 默认关闭,开启需要手动把no改为yes
appendonly yes
2 指定本地数据库文件名,默认值为 appendonly.aof
appendfilename "appendonly.aof"
3 指定更新日志条件
# appendfsync always
appendfsync everysec
# appendfsync no
解说:
always:同步持久化,每次发生数据变化会立刻写入到磁盘中。性能较差当数据完整性比较好(慢,安全)
everysec:出厂默认推荐,每秒异步记录一次(默认值)
no:不同步
4 配置重写触发机制
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
解说:当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。一般都设置为3G,64M太小了。
② 触发AOF快照
根据配置文件触发,可以是每次执行触发,可以是每秒触发,可以不同步。
③ 根据AOF文件恢复数据
正常情况下,将appendonly.aof 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可。但在实际开发中,可能因为某些原因导致appendonly.aof 文件格式异常,从而导致数据还原失败,可以通过命令redis-check-aof --fix appendonly.aof 进行修复 。从下面的操作演示中体会。
④ AOF的重写机制
前面也说到了,AOF的工作原理是将写操作追加到文件中,文件的冗余内容会越来越多。所以聪明的 Redis 新增了重写机制。当AOF文件的大小超过所设定的阈值时,Redis就会对AOF文件的内容压缩。
重写的原理:Redis 会fork出一条新进程,读取内存中的数据,并重新写到一个临时文件中。并没有读取旧文件(你都那么大了,我还去读你??? o(゚Д゚)っ傻啊!)。最后替换旧的aof文件。
触发机制:当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。这里的“一倍”和“64M” 可以通过配置文件修改。
(2)AOF 的优缺点
优点:数据的完整性和一致性更高
缺点:因为AOF记录的内容多,文件会越来越大,数据恢复也会越来越慢。
(3)操作演示
[root@itdragon bin]# vim appendonly.aof
appendonly yes
[root@itdragon bin]# ./redis-server redis.conf
[root@itdragon bin]# ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set keyAOf valueAof
OK
127.0.0.1:6379> FLUSHALL
OK
127.0.0.1:6379> SHUTDOWN
not connected> QUIT
[root@itdragon bin]# ./redis-server redis.conf
[root@itdragon bin]# ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
1) "keyAOf"
127.0.0.1:6379> SHUTDOWN
not connected> QUIT
[root@itdragon bin]# vim appendonly.aof
fjewofjwojfoewifjowejfwf
[root@itdragon bin]# ./redis-server redis.conf
[root@itdragon bin]# ./redis-cli -h 127.0.0.1 -p 6379
Could not connect to Redis at 127.0.0.1:6379: Connection refused
not connected> QUIT
[root@itdragon bin]# redis-check-aof --fix appendonly.aof
'x 3e: Expected prefix '*', got: '
AOF analyzed: size=92, ok_up_to=62, diff=30
This will shrink the AOF from 92 bytes, with 30 bytes, to 62 bytes
Continue? [y/N]: y
Successfully truncated AOF
[root@itdragon bin]# ./redis-server redis.conf
[root@itdragon bin]# ./redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379> keys *
1) "keyAOf"
第一步:修改配置文件,开启AOF持久化配置。
第二步:重启Redis服务,并进入Redis 自带的客户端中。
第三步:保存值,然后模拟数据丢失,关闭Redis服务。
第四步:重启服务,发现数据恢复了。(额外提一点:有教程显示FLUSHALL 命令会被写入AOF文件中,导致数据恢复失败。我安装的是redis-4.0.2没有遇到这个问题)。
第五步:修改appendonly.aof,模拟文件异常情况。
第六步:重启 Redis 服务失败。这同时也说明了,RDB和AOF可以同时存在,且优先加载AOF文件。
第七步:校验appendonly.aof 文件。重启Redis 服务后正常。
补充点:aof 的校验是通过 redis-check-aof 文件,那么rdb 的校验是不是可以通过 redis-check-rdb 文件呢???
6.3 总结
- Redis 默认开启RDB持久化方式,在指定的时间间隔内,执行指定次数的写操作,则将内存中的数据写入到磁盘中。
- RDB 持久化适合大规模的数据恢复但它的数据一致性和完整性较差。
- Redis 需要手动开启AOF持久化方式,默认是每秒将写操作日志追加到AOF文件中。
- AOF 的数据完整性比RDB高,但记录内容多了,会影响数据恢复的效率。
- Redis 针对 AOF文件大的问题,提供重写的瘦身机制。
- 若只打算用Redis 做缓存,可以关闭持久化。
- 若打算使用Redis 的持久化。建议RDB和AOF都开启。其实RDB更适合做数据的备份。AOF出问题了,还有RDB。
7. LRU与LFU
(1)LRU算法实现:
LRU算法实现:
import java.util.HashMap;
import java.util.Map.Entry 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









