






前言
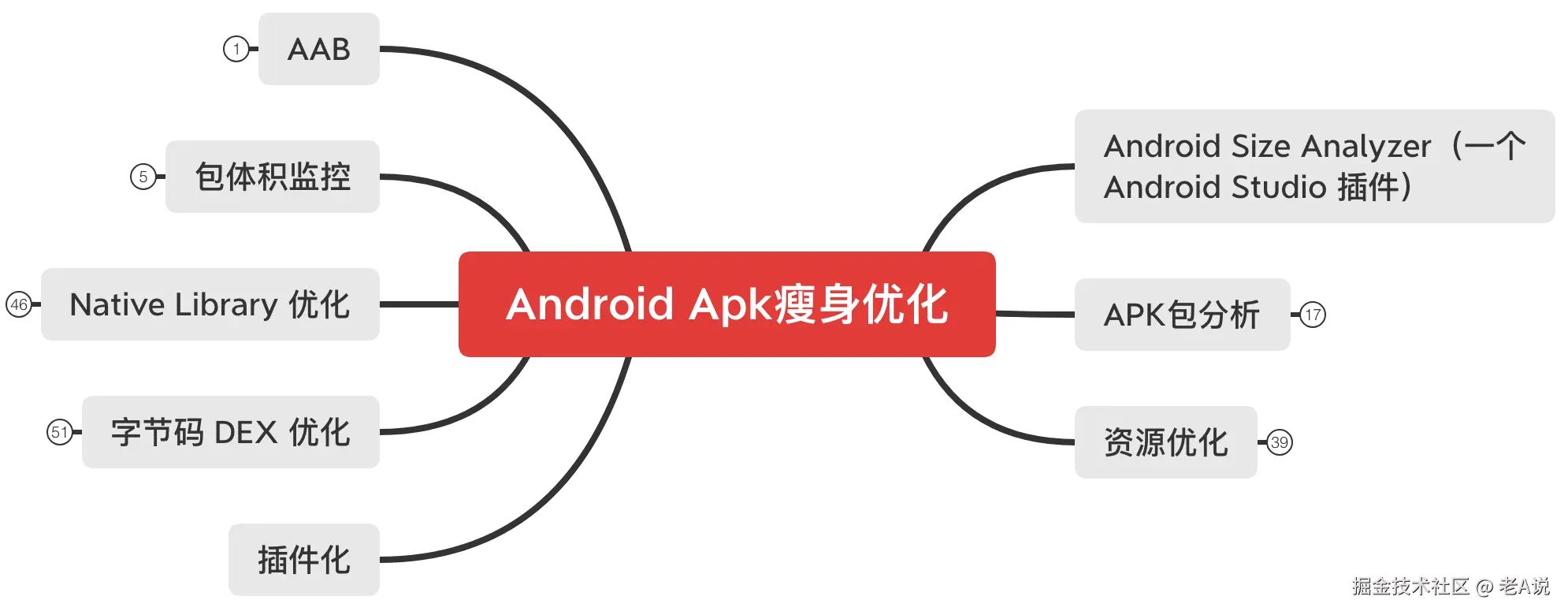
APK 包分析

通过对 APK 包的分析,我们主要的包体积优化集中在 lib、resources.arsc、classess.dex 这几个方向上;
resources.arsc

每个资源文件在 R 文件中 都是一个 class,每个资源名称都分配了一个 id,每个 id 都是一个四字节无符号整数,格式是 0xpptteeee,p 代表 package,t 代表 Type,e 代表 entry,最高字节代表 Package ID,次高字节代表 Type ID,后面两个代表 Entry ID;
- Package ID: 相当于是一个命名空间,限定资源的来源,Android 系统当前定义了两个资源命令空间,其中一个系统资源命令空间,它的 Package ID 等于 0x01,另外一个是应用程序资源命令空间,它的 Package ID 等于 0x7f。所有的位于『0x01, 0x7f』之间的 Package ID 都是合法的,而在这个范围之外的都是非法的 Package ID。前面提到的系统资源包 package-export.apk 的 Package ID 就等于 0x01;
- Type ID: 资源的类型ID,资源的类型有 animator、anim、;
- Entry ID: 每一个资源在其所属的资源类型中所出现的次序;
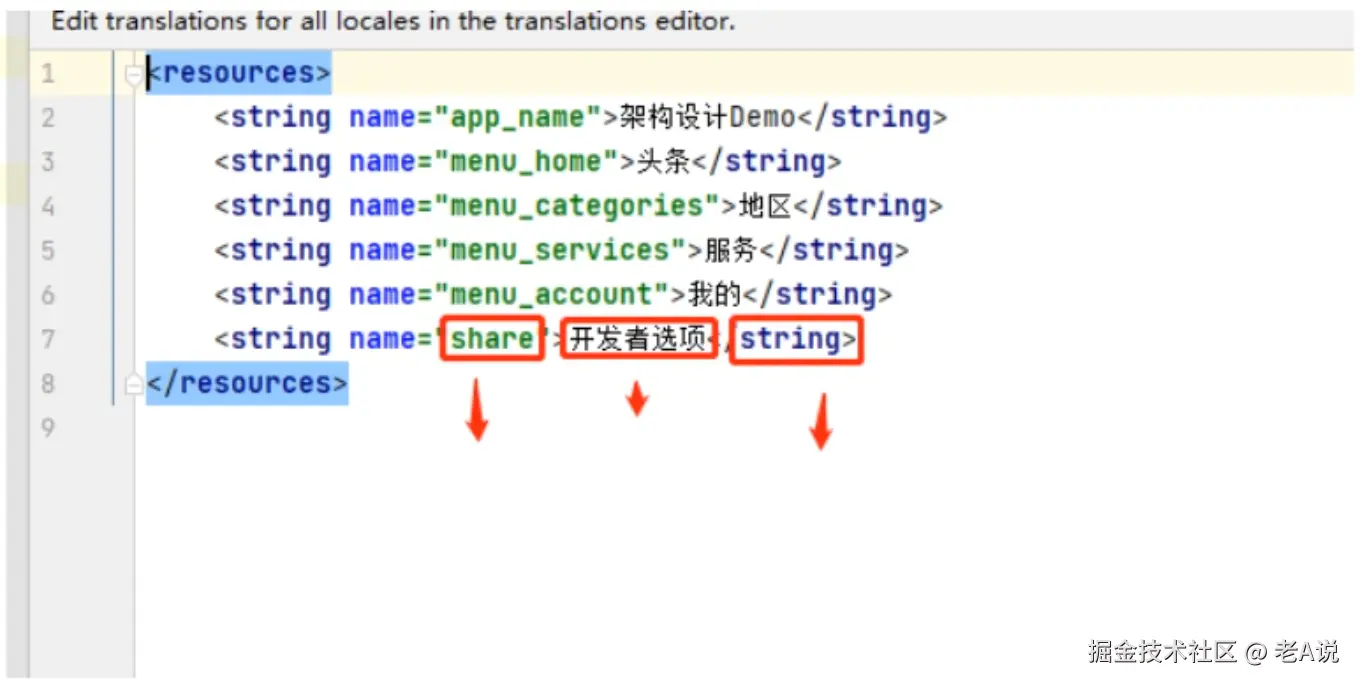
上面的这些 app_name share 叫做资源项名称(其它的还有 windowActionBar、ActionBarTabStyle 类似这种)而它们对应的资源项类型就是 string(其它的还有 attr、drawable 类似这些),资源项的值就是架构设计和头条这些;
Native Library 优化
优化主要在三个方向上:动态加载、压缩、合并裁剪
Library 动态加载
说到动态加载,我们先来了解一些基础知识;

通过上图我们可以看到
armeabi-v7a: 第7代 ARM v7,使用硬件浮点运算,具有高级扩展功能(支持 armeabi 和 armeabi-v7a,目前大部分手机都是这个架构);
arm64-v8a: 第8代,64位,包含AArch32、AArch64两个执行状态对应32、64bit(支持 armeabi-v7a、
armeabi 和 arm64-v8a);
x86: intel 32位,少数的平板应用此架构(支持 armeabi(性能有所损耗) 和 x86);
x86_64: intel 64位,少数的平板应用此架构(支持 x86 和 x86_64);
- 只适配 armeabi 的 APP 可以跑在 armeabi,armeabi-v7a,arm64-v8 上;
- 只适配 armeabi-v7a 可以运行在 armeabi-v7a 和 arm64-v8a;
- 只适配 arm64-v8a 可以运行在 arm64-v8a 上;
目前市面上手机设备绝大多数都是arm架构,因此armv7a几乎能兼容所有设备。大多数应用只会打包 arm-v7a
的 so 在 Apk 中;
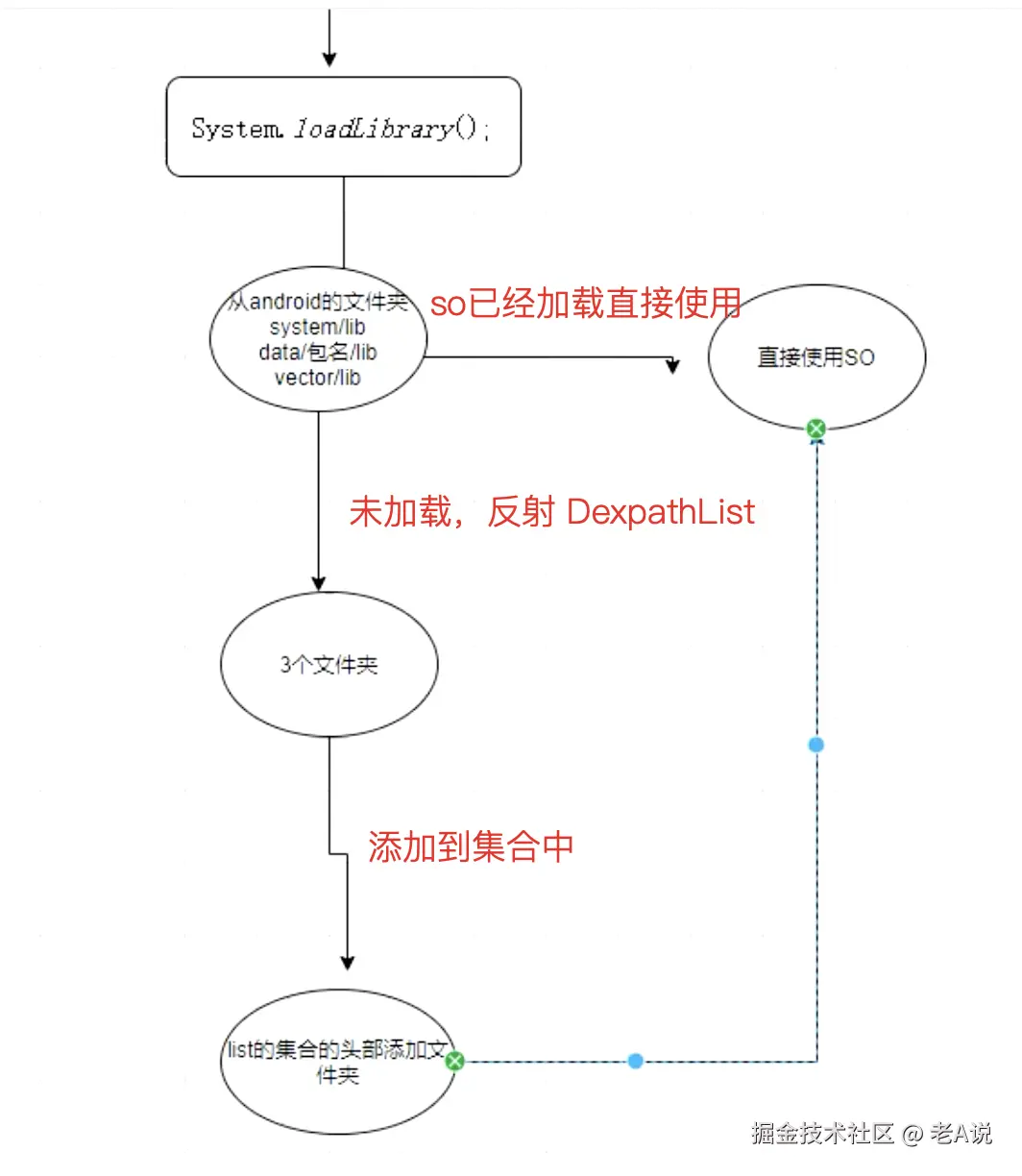
系统 so 的加载过程
- PackageManagerService 会把 so copy到 data/data/包名/lib 下
- app 启动 so 的路径会传递到 BaseDexClassLoader 的 DexPathList 的 nativeLibraryDirectories 集合中
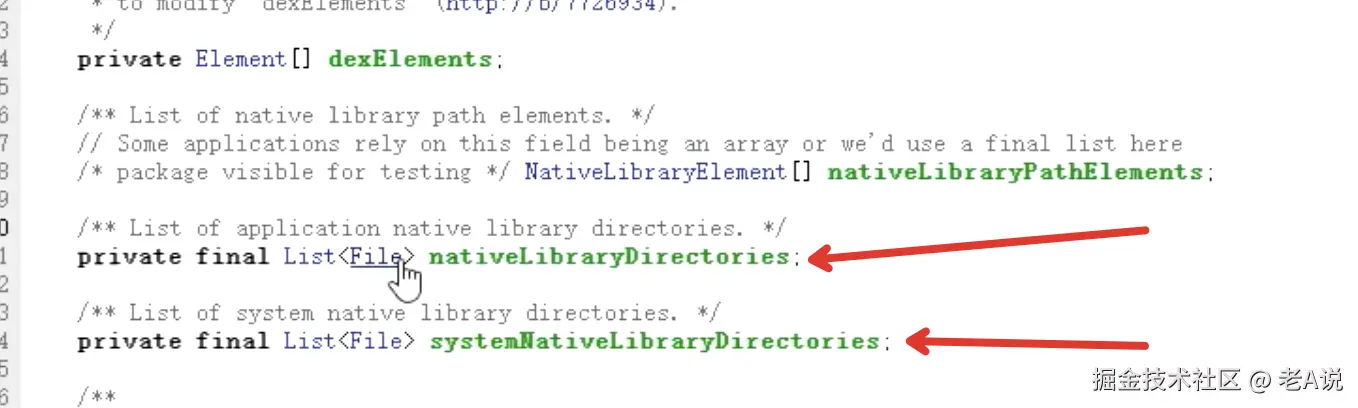
- 调用 System.loadLibrary 就行了
动态库打包配置

首先配置需要的架构,打包的时候 只会把这个架构的全部so文件打入到 apk 中;
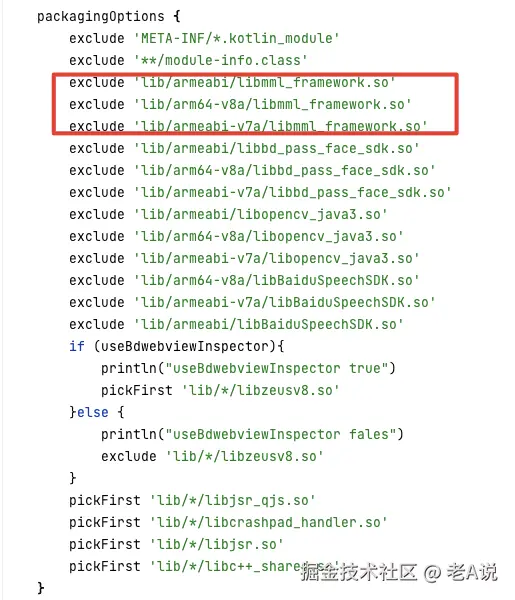
然后打包的时候,剔除指定不需要的 so 文件,一般用于 so 文件重复的时候;

其次,app 下的 build.gradle 下的 android 节点下 增加 productFlavors
- arm32 产出 32 位的 release、debug 包,dimension 维度
- arm64 产出 64 位的 release、debug 包;
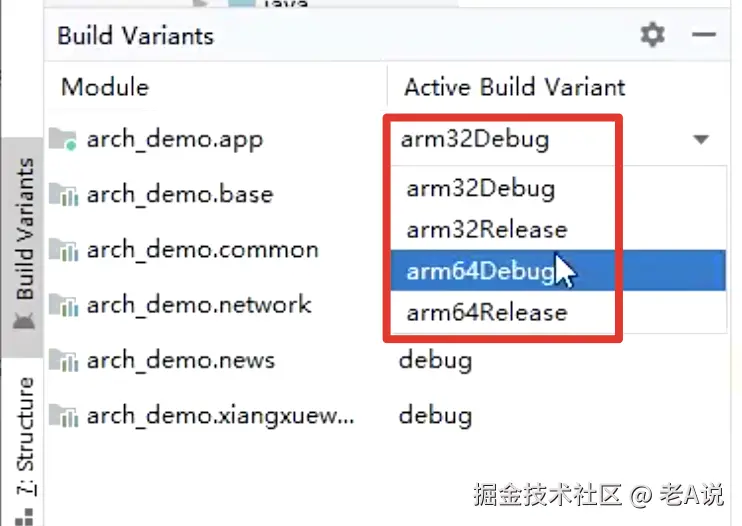
build 之后,会结合 buildTypes 生成不同的 build 变体;

最后, app 下的 build.gradle 下的 android 节点下 增加 splits;
universalApk 是否打一个包含所有 so 的 apk;
动态加载
动态加载有两种方案,一种是:SoLoader + linker,还有一种是借助于:Tinker;
我们先来看下 Tinker 的流程:TinkerLoadLibrary.java
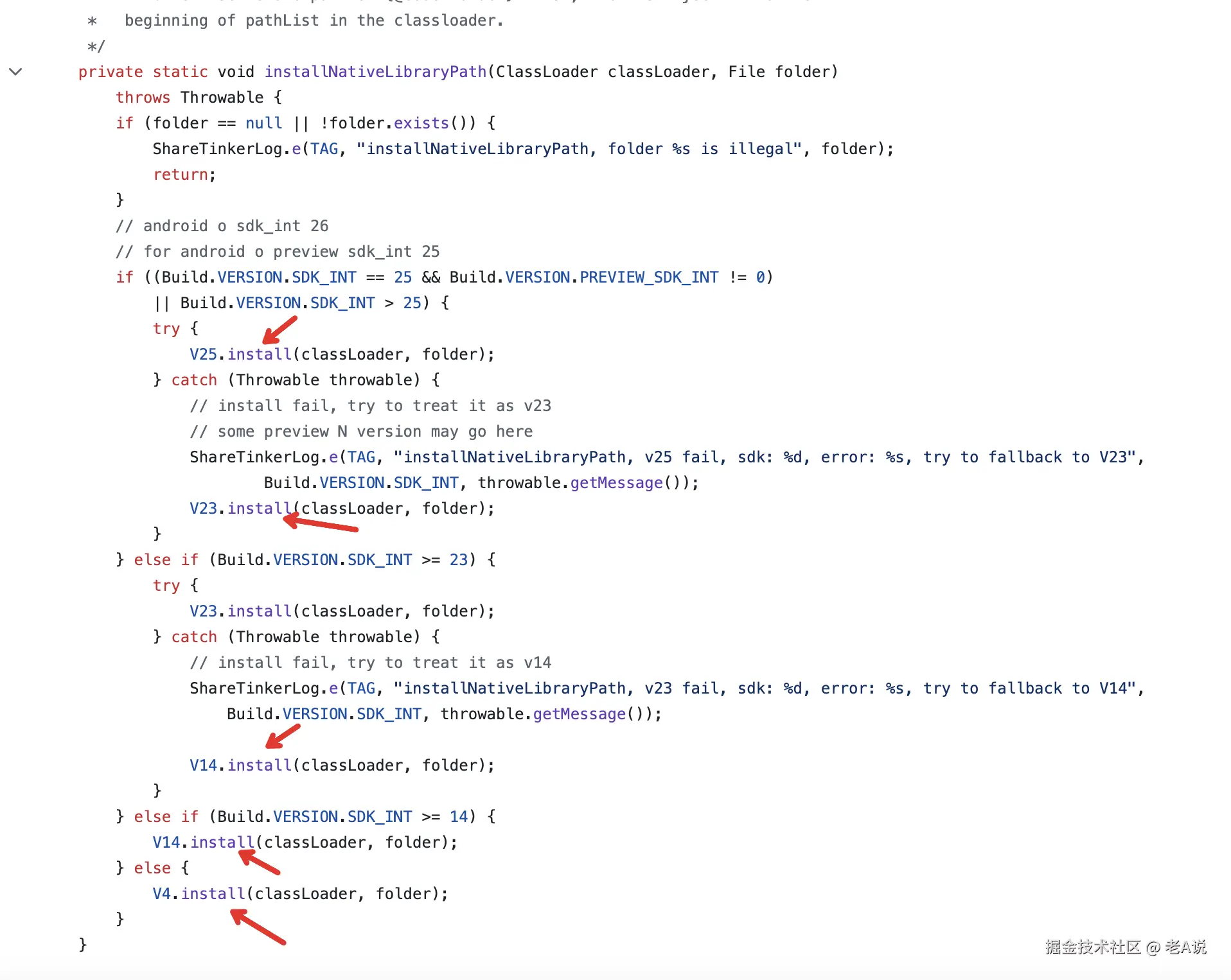
核心逻辑就在这个 installNativeLibraryPath 中,这里做了系统版本的区分;

本质就是 Hook libraryPathElements 数据,将 so 的完整路径加入到这个数组中;
Library 压缩
Library 优化最有效果的方法也是使用 XZ 或者 7-Zip 压缩,Facebook 有一个 So 加载的开源库 SoLoader,用来加载so 提升首次启动的时间
压缩方案的主要缺点在于首次启动的时间
Library 合并与裁剪
Library 合并。在 Android 4.3 之前,进程加载的 Library 数量是有限制的。在编译过程,我们可以自动将部分 Library 合并成一个。具体思路你可以参考文章《Android native library merging》以及 Demo
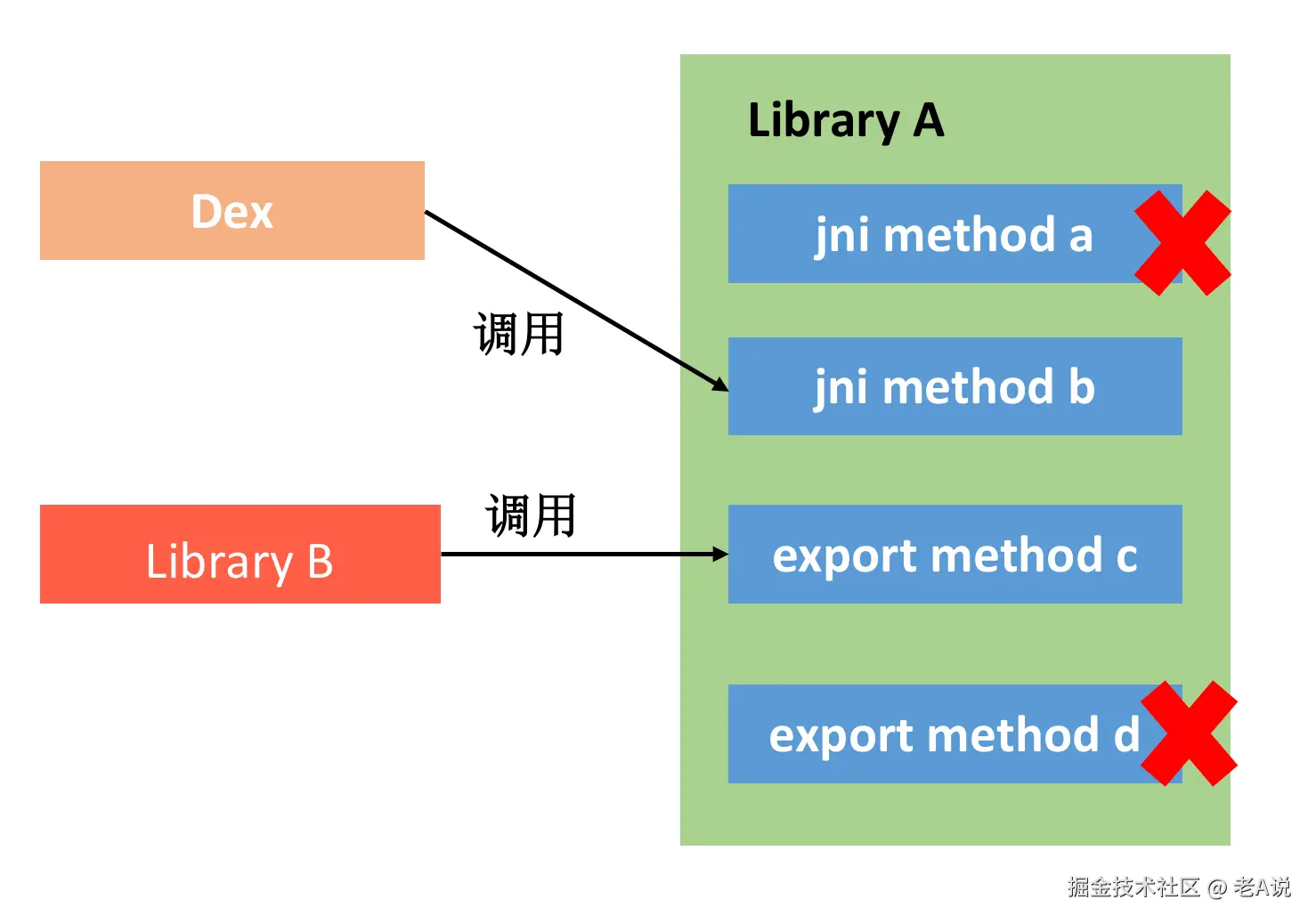
Library 裁剪。Buck 里面有一个 relinker 的功能,原理就是分析代码中 JNI 方法以及不同 Library 的方法调用,找到没有无用的导出 symbol,将它们删掉。这样 linker 在编译的时候也会把对应的无用代码同时删掉,这个方法相当于实现了 Library 的 ProGuard Shrinking 功能
资源优化
移除未使用资源
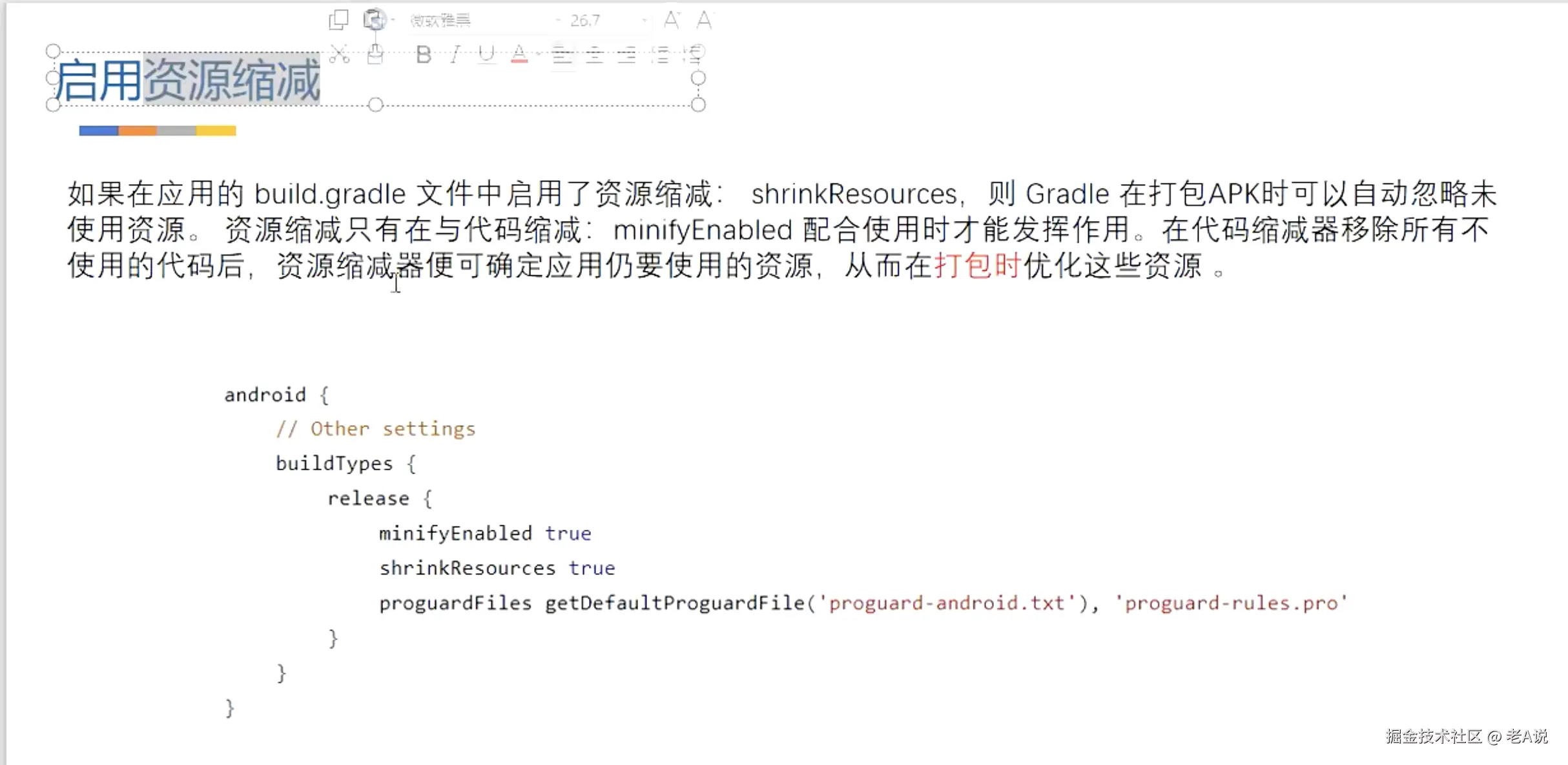
gradle 中开启资源缩减
shrinkResources true 只有配合 minifyEnabled true 一起使用才会生效,在代码缩减器移除所有不使用代码后,资源缩减器便可确定所有不使用的资源;
PS:资源移除 并不是真正的将图片删掉,而是进行了一系列的优化,图片移除上面的内容,xml 会清空里面的内容;
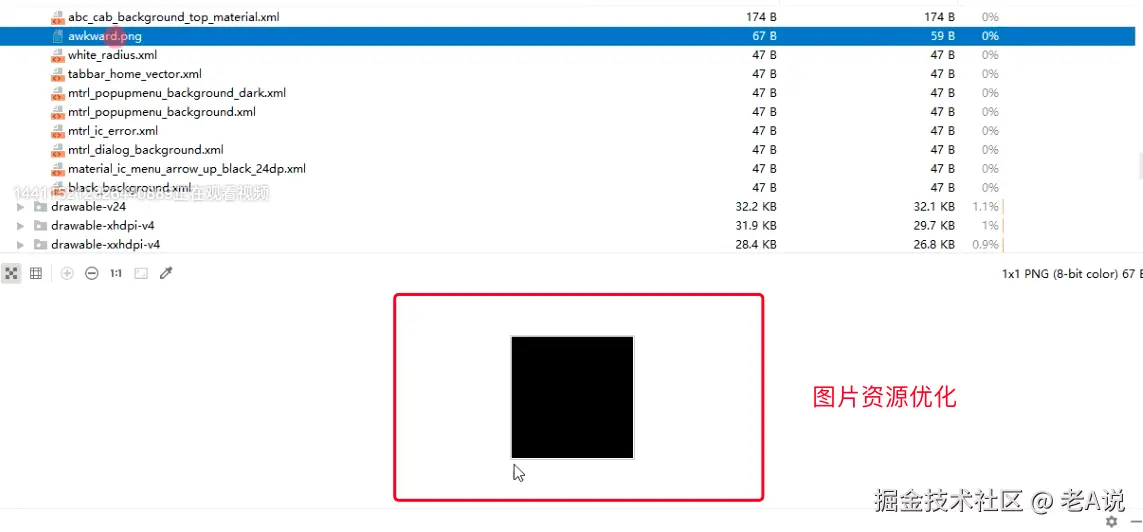
如上图,图片资源优化,移除了上面的内容;
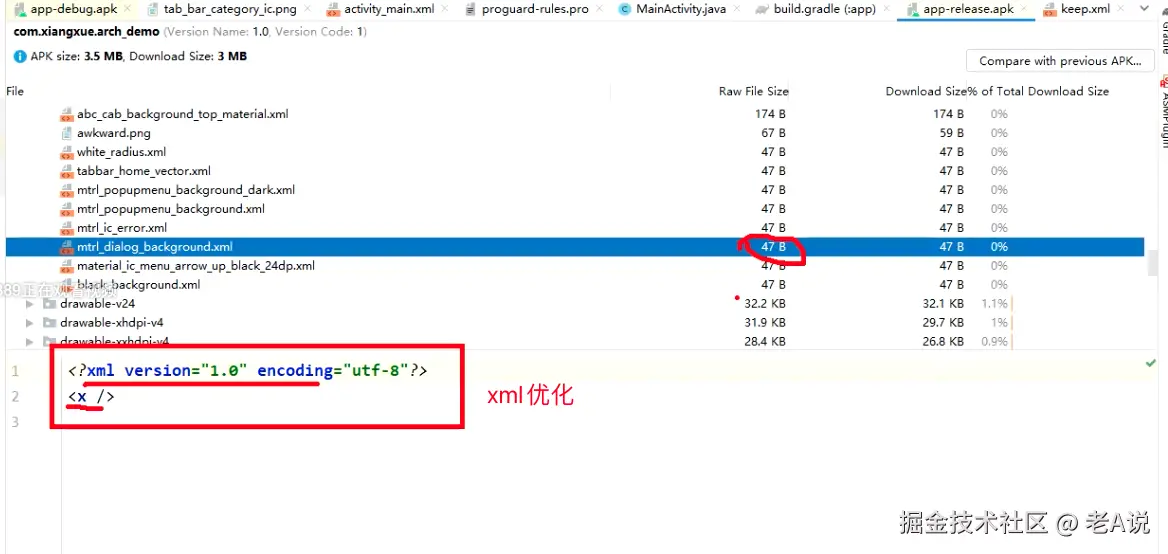
如上图,xml 是清空了里面的内容;
如果想要保留一些资源,在raw文件夹下 声明一个 keep.xml 文件;
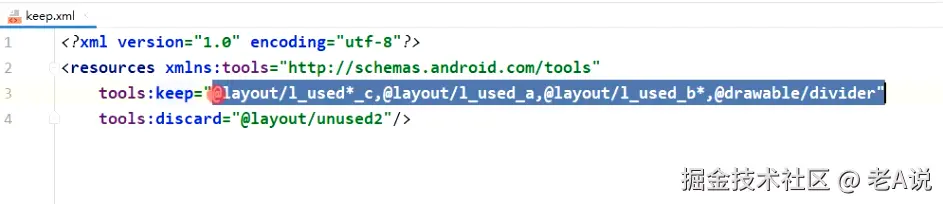
keep 列表是要保留的文件,哪怕没有用到, discard 列表是进行资源缩减,哪怕是被引用到;
Lint 资源分析器
主要使用 AS 自带的分析器来分析无用资源并删除,但是 lint 会检测不到在代码中直接使用的;

这种使用方式的话,lint 检测不到;
所以,替代方案:微信的 Matrix-ApkChecker

无用资源的检测
移除备用资源
resConfigs
通过 resConfigs 可以移除不必要的语言配置;
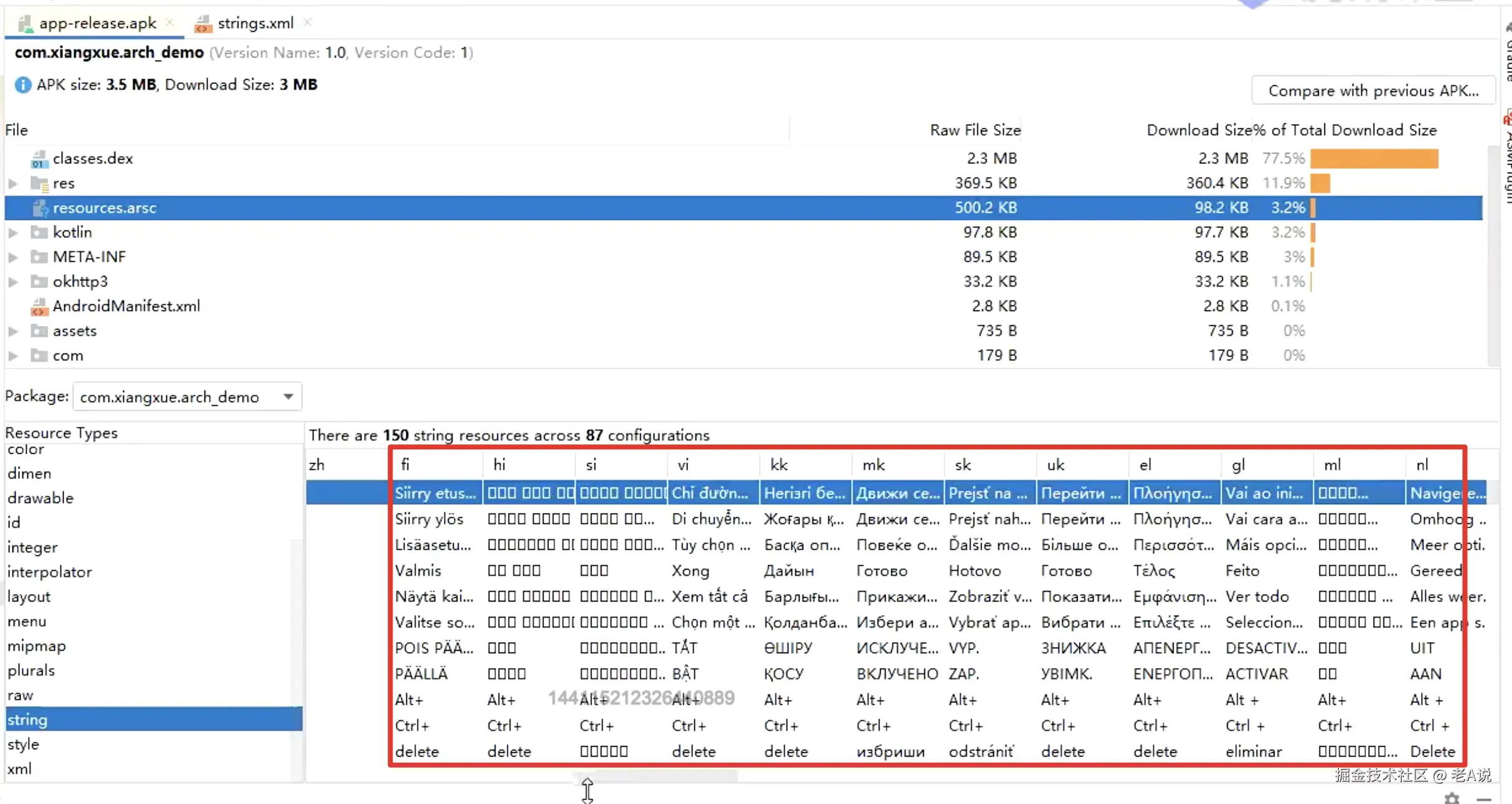
从图中可以看到,虽然我们只提供了中文,但是打出来的包中却含有其他语言;这些大都来自 google 提供的 androidx 下的 appcompat 包;

保留需要的语言,就会保留 default zh-rCN(简体、繁体) zh 这三种
使用矢量图
矢量图可以创建与分辨率无关的图标和其他可伸缩媒体。使用这些图形可以极大地减少 APK 占用的空间。 矢量图片在 Android 中以 VectorDrawable 对象的形式表示;
系统渲染每个 VectorDrawable 对象需要花费大量时间,而较大的图片则需要更长的时间才能显示在屏幕上。因此,建议仅在显示小图片时使用这些矢量图。
但是 矢量图 的优化比较大,如果小图过多,可以考虑使用 矢量图;
资源混淆
使用 WeChat 的资源混淆 AndResGuard;
原理就是:文件读取,IO 操作,通过修改 resource.arsc 文件中的资源名字和对应的地址 改为r/a/b 同步修改res 文件夹下对应的文件夹名字和资源 改为 r/a/b,映射名字进行简化;
字节码 DEX 优化
混淆
混淆大致分为种,prguard、D8&R8;
去掉 Debug 信息或者去掉行号
DebugItem
某个应用通过相同的 ProGuard 规则生成一个 Debug 包和 Release 包,其中 Debug 包的大小是 4MB,Release 包只有 3.5MB,既然它们 ProGuard 的混淆与优化的规则是一样的,那它们之间的差异在哪里呢?那就是 DebugItem
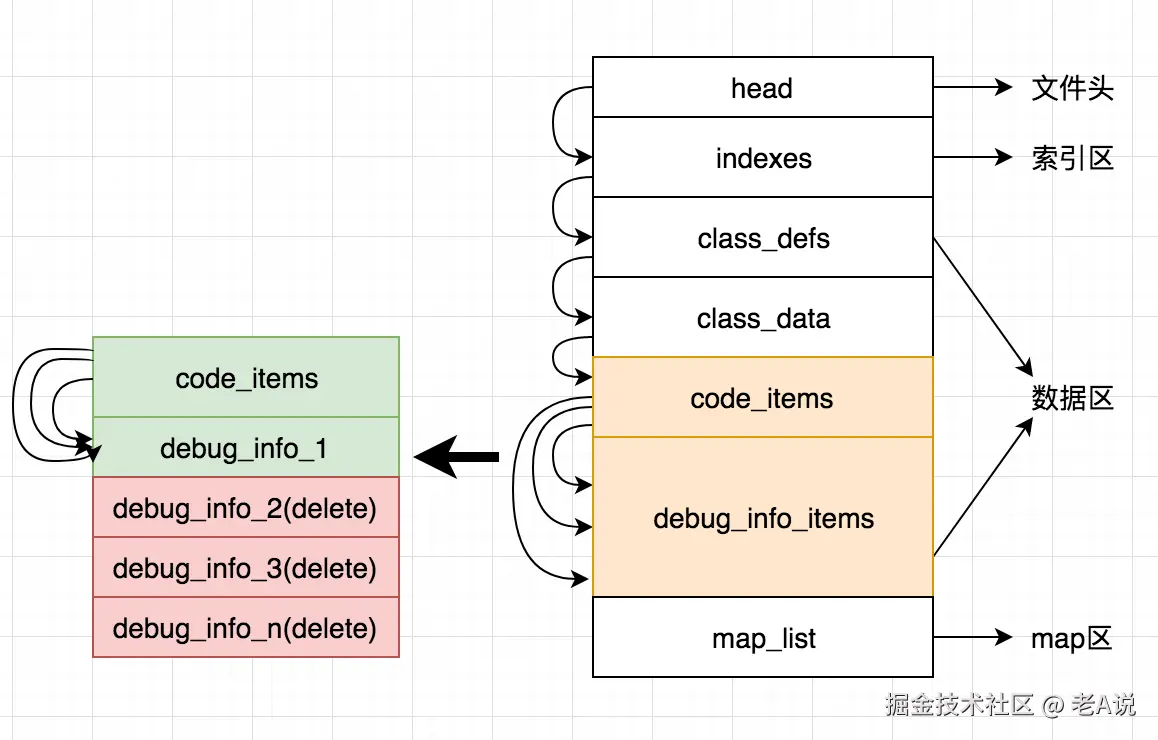
这里我们可以看下支付宝的方案:
支付宝的删除 Dex debugitem
方案一
核心思路也比较简单,就是行号查找离线化,让本来存放在 App 中的行号对应关系提前抽离出来存放在服务端,crash 上报的时候通过提前抽离的行号表进行行号反解,解决 crash 信息上报无行号,无法定位的问题
- 修改 proguard:利用 proguard 来删除 debugItem (去掉 -keep lineNumberTable),在删除行号表之前 dump 出一个临时的 dex
- 修改 dexdump:把临时的 dex 中的行号表关系 dump 成一个 dexpcmapping 文件(指令集行号和源文件行号映射关系),并存至服务端
- hook app runtime 的 crash handler,把 crash 时的指令集行号上报到反解平台
- 反解平台通过上报指令集行号和提前准备好 dexpcmapping 文件反解出正确的行号
方案二
直接修改 dex 文件,保留一小块 debugItem,让系统查找行号的时候指令集行号和源文件行号保持一致,这样就什么都不用做,任何监控上报的行号都直接变成了指令集行号,只需修改 dex 文件
DEX 分包
产生问题的本质是:如果将 Class A 与 Class B 分别编译到不同的 Dex 中,由于 method a 调用了 method b,所以在 classes2.dex 中也需要加上 method b 的 id
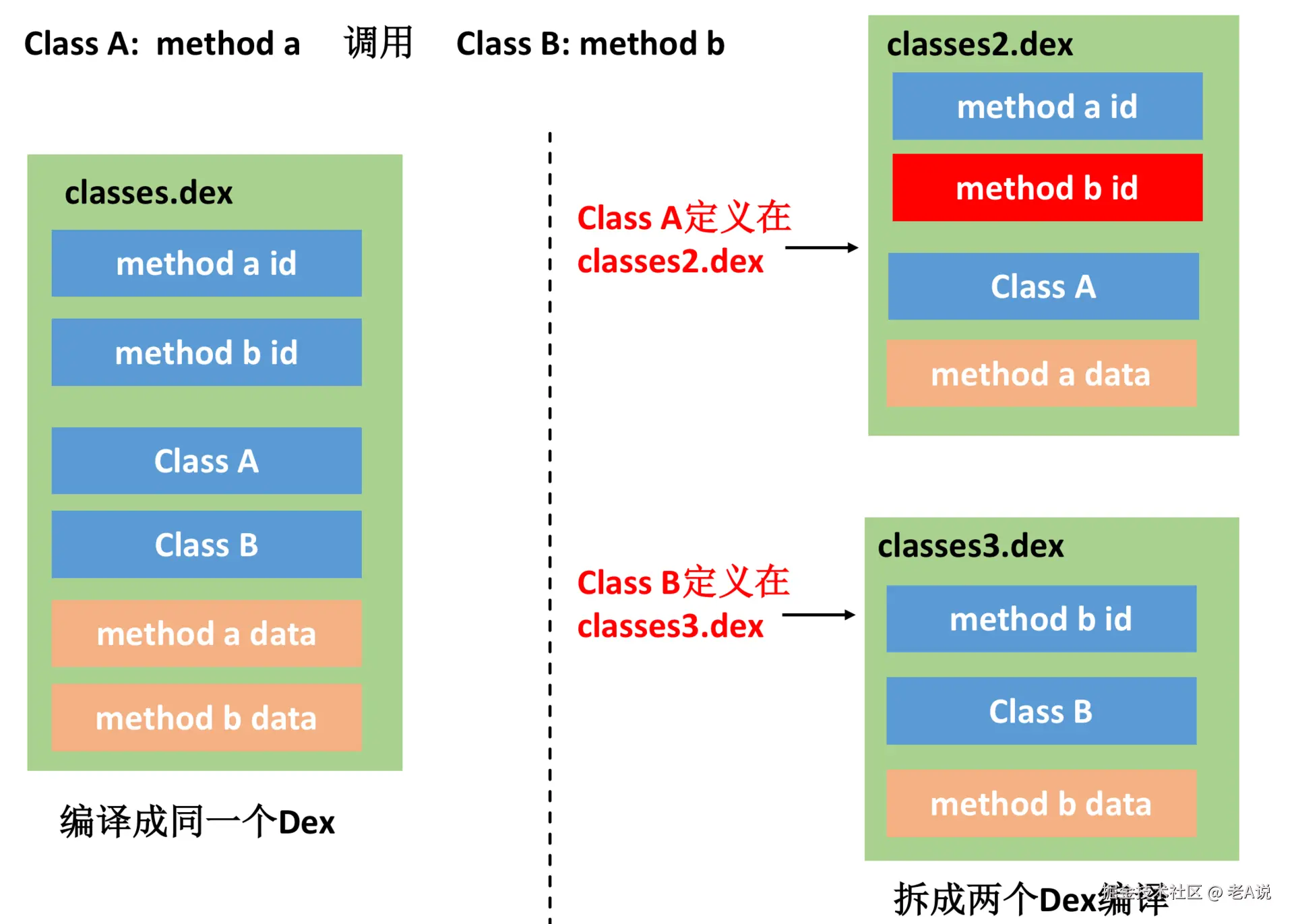
method b id 过多造成的影响:
- method id 爆表。我们都知道每个 Dex 的 method id 需要小于 65536,因为 method id 的大量冗余导致每个 Dex 真正可以放的 Class 变少,这是造成最终编译的Dex 数量增多;
- 信息冗余。因为我们需要记录跨 Dex 调用的方法的详细信息,所以在 classes2.dex 我们还需要记录 Class B 以及 method b 的定义,造成 string_ids、type_ids、proto_ids 这几部分信息的冗余;
优化原理:将有调用关系的类和方法分配到同一个 Dex 中,即减少跨 Dex 的调用的情况;
这里可以参考 FaceBook 的 ReDex
DEX 压缩
FaceBook 采用的压缩方案是:Facebook App 的 classes.dex 只是一个壳,真正的代码都放到 assets 下面。它们把所有的 Dex 都合并成同一个 secondary.dex.jar.xzs 文件,并通过 XZ 压缩;
Dex 压缩带来的问题:
- 首次启动解压;
- 应用首次启动的时候,需要将 secondary.dex.jar.xzs 解压缩,根据上图的配置信息,应该一共有 11 个 Dex
- Facebook 使用多线程解压的方式,这个耗时在高端机是几百毫秒左右,在低端机可能需要 3~5 秒
- ODEX 文件生成
- 当 Dex 非常多的时候会增加应用的安装时间。对于 Facebook 的这个做法,首次生成 ODEX 的时间可能就会达到分钟级别。
- Facebook 为了解决这个问题,使用了 ReDex 另外一个超级硬核的方法,那就是oatmeal
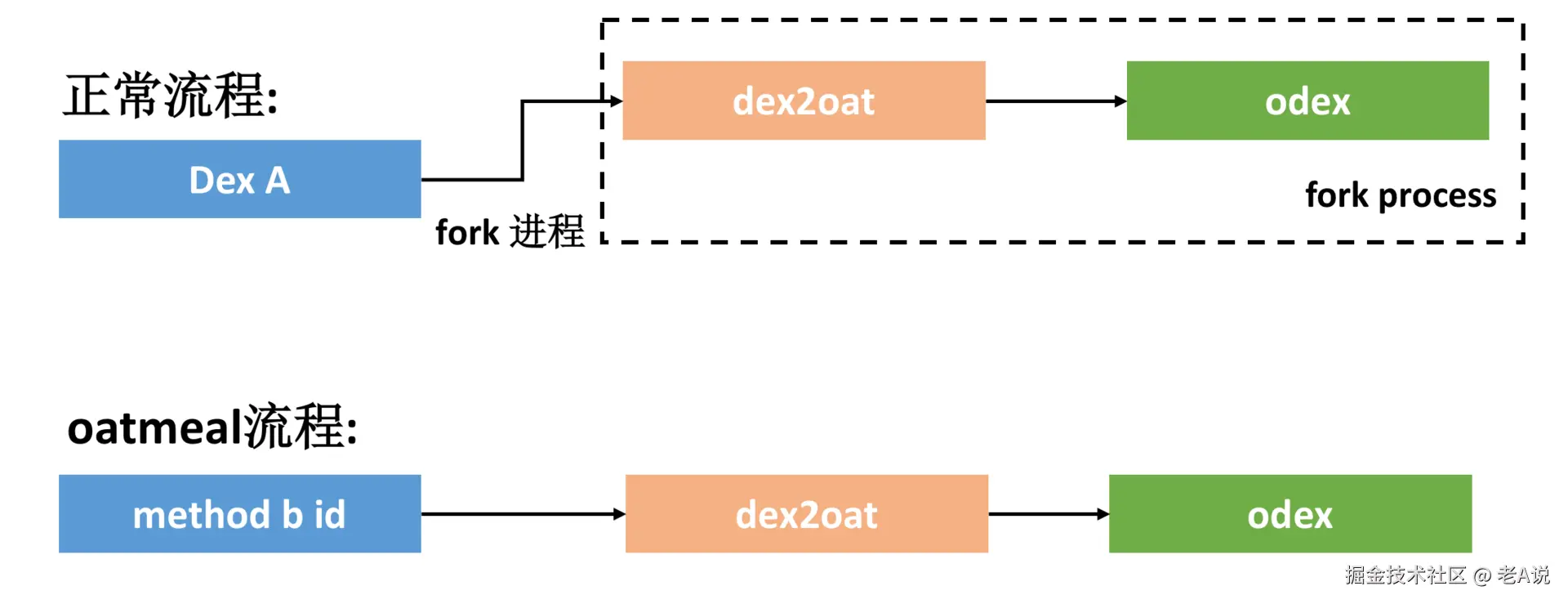
oatmeal 原理就是:根据 ODEX 文件的格式,自己生成一个 ODEX 文件。它生成的结果跟解释执行的 ODEX 一样,内部是没有机器码的;
好了,包体积优化的就写到这里吧;
欢迎三连
来都来了,点个关注,点个赞吧,你的支持是我最大的动力~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









