







剖析程序的内存布局
原文标题:Anatomy of a Program in Memory
内存管理模块是操作系统的心脏;它对应用程序和系统管理非常重要。今后的几篇文章中,我将着眼于实际的内存问题,但也不避讳其中的技术内幕。由于不少概念是通用的,所以文中大部分例子取自32位x86平台的Linux和Windows系统。本系列第一篇文章讲述应用程序的内存布局。
在多任务操作系统中的每一个进程都运行在一个属于它自己的内存沙盘中。这个沙盘就是虚拟地址空间(virtual address space),在32位模式下它总是一个4GB的内存地址块。这些虚拟地址通过页表(page table)映射到物理内存,页表由操作系统维护并被处理器引用。每一个进程拥有一套属于它自己的页表,但是还有一个隐情。只要虚拟地址被使能,那么它就会作用于这台机器上运行的所有软件,包括内核本身。因此一部分虚拟地址必须保留给内核使用:
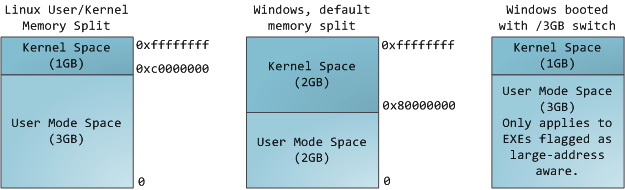
这并不意味着内核使用了那么多的物理内存,仅表示它可支配这么大的地址空间,可根据内核需要,将其映射到物理内存。内核空间在页表中拥有较高的特权级(ring 2或以下),因此只要用户态的程序试图访问这些页,就会导致一个页错误(page fault)。在Linux中,内核空间是持续存在的,并且在所有进程中都映射到同样的物理内存。内核代码和数据总是可寻址的,随时准备处理中断和系统调用。与此相反,用户模式地址空间的映射随进程切换的发生而不断变化:
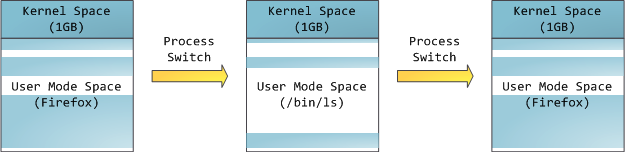
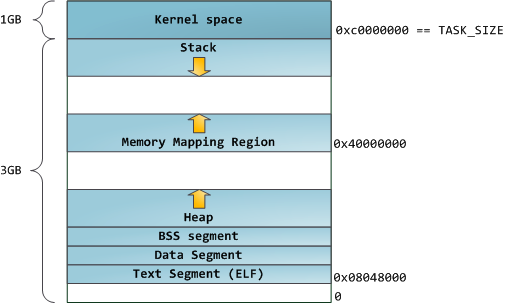
蓝色区域表示映射到物理内存的虚拟地址,而白色区域表示未映射的部分。在上面的例子中,Firefox使用了相当多的虚拟地址空间,因为它是传说中的吃内存大户。地址空间中的各个条带对应于不同的内存段(memory segment),如:堆、栈之类的。记住,这些段只是简单的内存地址范围,与Intel处理器的段没有关系。不管怎样,下面是一个Linux进程的标准的内存段布局:
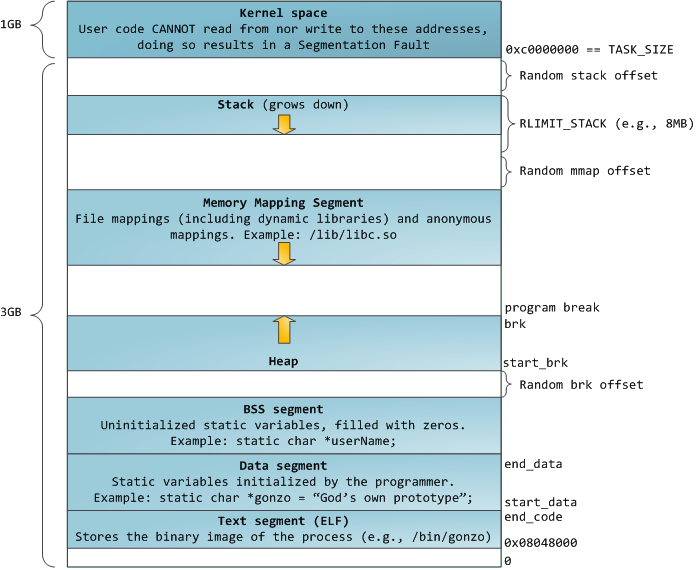
当计算机开心、安全、可爱、正常的运转时,几乎每一个进程的各个段的起始虚拟地址都与上图完全一致,这也给远程发掘程序安全漏洞打开了方便之门。一个发掘过程往往需要引用绝对内存地址:栈地址,库函数地址等。远程攻击者必须依赖地址空间布局的一致性,摸索着选择这些地址。如果让他们猜个正着,有人就会被整了。因此,地址空间的随机排布方式逐渐流行起来。Linux通过对栈、内存映射段、堆的起始地址加上随机的偏移量来打乱布局。不幸的是,32位地址空间相当紧凑,给随机化所留下的空当不大,削弱了这种技巧的效果。
进程地址空间中最顶部的段是栈,大多数编程语言将之用于存储局部变量和函数参数。调用一个方法或函数会将一个新的栈桢(stack frame)压入栈中。栈桢在函数返回时被清理。也许是因为数据严格的遵从LIFO的顺序,这个简单的设计意味着不必使用复杂的数据结构来追踪栈的内容,只需要一个简单的指针指向栈的顶端即可。因此压栈(pushing)和退栈(popping)过程非常迅速、准确。另外,持续的重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每一个线程都有属于自己的栈。
通过不断向栈中压入的数据,超出其容量就有会耗尽栈所对应的内存区域。这将触发一个页故障(page fault),并被Linux的expand_stack()处理,它会调用acct_stack_growth()来检查是否还有合适的地方用于栈的增长。如果栈的大小低于RLIMIT_STACK(通常是8MB),那么一般情况下栈会被加长,程序继续愉快的运行,感觉不到发生了什么事情。这是一种将栈扩展至所需大小的常规机制。然而,如果达到了最大的栈空间大小,就会栈溢出(stack overflow),程序收到一个段错误(Segmentation Fault)。当映射了的栈区域扩展到所需的大小后,它就不会再收缩回去,即使栈不那么满了。这就好比联邦预算,它总是在增长的。
动态栈增长是唯一一种访问未映射内存区域(图中白色区域)而被允许的情形。其它任何对未映射内存区域的访问都会触发页故障,从而导致段错误。一些被映射的区域是只读的,因此企图写这些区域也会导致段错误。
在栈的下方,是我们的内存映射段。此处,内核将文件的内容直接映射到内存。任何应用程序都可以通过Linux的mmap()系统调用(实现)或Windows的CreateFileMapping() / MapViewOfFile()请求这种映射。内存映射是一种方便高效的文件I/O方式,所以它被用于加载动态库。创建一个不对应于任何文件的匿名内存映射也是可能的,此方法用于存放程序的数据。在Linux中,如果你通过malloc()请求一大块内存,C运行库将会创建这样一个匿名映射而不是使用堆内存。’大块’意味着比MMAP_THRESHOLD还大,缺省是128KB,可以通过mallopt()调整。
说到堆,它是接下来的一块地址空间。与栈一样,堆用于运行时内存分配;但不同点是,堆用于存储那些生存期与函数调用无关的数据。大部分语言都提供了堆管理功能。因此,满足内存请求就成了语言运行时库及内核共同的任务。在C语言中,堆分配的接口是malloc()系列函数,而在具有垃圾收集功能的语言(如C#)中,此接口是new关键字。
如果堆中有足够的空间来满足内存请求,它就可以被语言运行时库处理而不需要内核参与。否则,堆会被扩大,通过brk()系统调用(实现)来分配请求所需的内存块。堆管理是很复杂的,需要精细的算法,应付我们程序中杂乱的分配模式,优化速度和内存使用效率。处理一个堆请求所需的时间会大幅度的变动。实时系统通过特殊目的分配器来解决这个问题。堆也可能会变得零零碎碎,如下图所示:

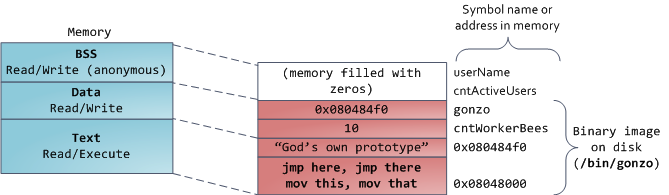
最后,我们来看看最底部的内存段:BSS,数据段,代码段。在C语言中,BSS和数据段保存的都是静态(全局)变量的内容。区别在于BSS保存的是未被初始化的静态变量内容,它们的值不是直接在程序的源代码中设定的。BSS内存区域是匿名的:它不映射到任何文件。如果你写static int cntActiveUsers,则cntActiveUsers的内容就会保存在BSS中。
另一方面,数据段保存在源代码中已经初始化了的静态变量内容。这个内存区域不是匿名的。它映射了一部分的程序二进制镜像,也就是源代码中指定了初始值的静态变量。所以,如果你写static int cntWorkerBees = 10,则cntWorkerBees的内容就保存在数据段中了,而且初始值为10。尽管数据段映射了一个文件,但它是一个私有内存映射,这意味着更改此处的内存不会影响到被映射的文件。也必须如此,否则给全局变量赋值将会改动你硬盘上的二进制镜像,这是不可想象的。
下图中数据段的例子更加复杂,因为它用了一个指针。在此情况下,指针gonzo(4字节内存地址)本身的值保 存在数据段中。而它所指向的实际字符串则不在这里。这个字符串保存在代码段中,代码段是只读的,保存了你全部的代码外加零零碎碎的东西,比如字符串字面 值。代码段将你的二进制文件也映射到了内存中,但对此区域的写操作都会使你的程序收到段错误。这有助于防范指针错误,虽然不像在C语言编程时就注意防范来得那么有效。下图展示了这些段以及我们例子中的变量:
你可以通过阅读文件/proc/pid_of_process/maps来检验一个Linux进程中的内存区域。记住一个段可能包含许多区域。比如,每个内存映射文件在mmap段中都有属于自己的区域,动态库拥有类似BSS和数据段的额外区域。下一篇文章讲说明这些”区域”(area)的真正含义。有时人们提到”数据段”,指的就是全部的数据段 + BSS + 堆。
对虚拟地址空间的布局就讲这些吧。下一篇文章将讨论内核是如何跟踪这些内存区域的。我们会分析内存映射,看看文件的读写操作是如何与之关联的,以及内存使用概况的含义。
参考: http://blog.csdn.net/drshenlei/article/details/4339110
内核是如何管理内存的
原文标题:How The Kernel Manages Your Memory
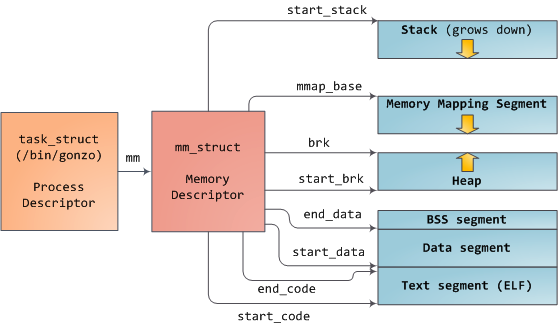
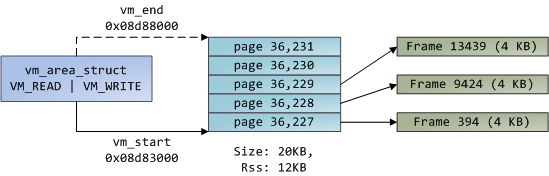
Linux进程在内核中是由task_struct的实例来表示的,即进程描述符。task_struct的mm字段指向内存描述符(memory descriptor),即mm_struct,一个程序的内存的执行期摘要。它存储了上图所示的内存段的起止位置,进程所使用的物理内存页的数量(rss表示Resident Set Size),虚拟内存空间的使用量,以及其他信息。我们还可以在内存描述符中找到用于管理程序内存的两个重要结构:虚拟内存区域集合(the set of virtual memory areas)及页表(page table)。Gonzo的内存区域如下图所示:
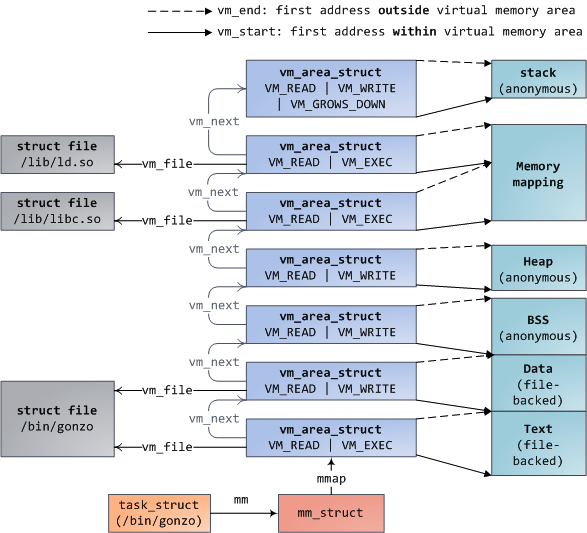
每一个虚拟内存区域(简称VMA)是一个连续的虚拟地址范围;这些区域不会交叠。一个vm_area_struct的实例完备的描述了一个内存区域,包括它的起止地址,决定访问权限和行为的标志位,还有vm_file字段,用于指出被映射的文件(如果有的话)。一个VMA如果没有映射到文件,则是匿名的(anonymous)。除memory mapping 段以外,上图中的每一个内存段(如:堆,栈)都对应于一个单独的VMA。这并不是强制要求,但在x86机器上经常如此。VMA并不关心它在哪一个段。
一个程序的VMA同时以两种形式存储在它的内存描述符中:一个是按起始虚拟地址排列的链表,保存在mmap字段;另一个是红黑树,根节点保存在mm_rb字段。红黑树使得内核可以快速的查找出给定虚拟地址所属的内存区域。当你读取文件/proc/pid_of_process/maps时,内核只须简单的遍历指定进程的VMA链表,并打印出每一项来即可。
在Windows中,EPROCESS块可以粗略的看成是task_struct和mm_struct的组合。VMA在Windows中的对应物时虚拟地址描述符(Virtual Address Descriptor),或简称VAD;它们保存在平衡树中(AVL tree)。你知道Windows和Linux最有趣的地方是什么吗?就是这些细小的不同点。
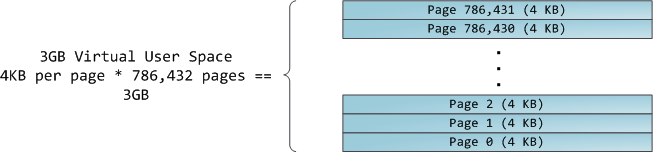
4GB虚拟地址空间被分割为许多页(page)。x86处理器在32位模式下所支持的页面大小为4KB,2MB和4MB。Linux和Windows都使用4KB大小的页面来映射用户部分的虚拟地址空间。第0-4095字节在第0页,第4096-8191字节在第1页,以此类推。VMA的大小必须是页面大小的整数倍。下图是以4KB分页的3GB用户空间:
处理器会依照页表(page table)来将虚拟地址转换到物理内存地址。每个进程都有属于自己的一套页表;一旦进程发生了切换,用户空间的页表也会随之切换。Linux在内存描述符的pgd字段保存了一个指向进程页表的指针。每一个虚拟内存页在页表中都有一个与之对应的页表项(page table entry),简称PTE。它在普通的x86分页机制下,是一个简单的4字节记录,如下图所示:

Linux有一些函数可以用于读取或设置PTE中的每一个标志。P位告诉处理器虚拟页面是否存在于(present)物理内存中。如果是0,访问这个页将触发页故障(page fault)。记住,当这个位是0时,内核可以根据喜好,随意的使用其余的字段。R/W标志表示读/写;如果是0,页面就是只读的。U/S标志表示用户/管理员;如果是0,则这个页面只能被内核访问。这些标志用于实现只读内存和保护内核空间。
D位和A位表示数据脏(dirty)和访问过(accessed)。脏表示页面被执行过写操作,访问过表示页面被读或被写过。这两个标志都是粘滞的:处理器只会将它们置位,之后必须由内核来清除。最后,PTE还保存了对应该页的起始物理内存地址,对齐于4KB边界。PTE中的其他字段我们改日再谈,比如物理地址扩展(Physical Address Extension)。
虚拟页面是内存保护的最小单元,因为页内的所有字节都共享U/S和R/W标志。然而,同样的物理内存可以被映射到不同的页面,甚至可以拥有不同的保护标志。值得注意的是,在PTE中没有对执行许可(execute permission)的设定。这就是为什么经典的x86分页可以执行位于stack上的代码,从而为黑客利用堆栈溢出提供了便利(使用return-to-libc和其他技术,甚至可以利用不可执行的堆栈)。PTE缺少不可执行(no-execute)标志引出了一个影响更广泛的事实:VMA中的各种许可标志可能会也可能不会被明确的转换为硬件保护。对此,内核可以尽力而为,但始终受到架构的限制。
虚拟内存并不存储任何东西,它只是将程序地址空间映射到底层的物理内存上,后者被处理器视为一整块来访问,称作物理地址空间(physical address space)。对物理内存的操作还与总线有点联系,好在我们可以暂且忽略这些并假设物理地址范围以字节为单位递增,从0到最大可用内存数。这个物理地址空间被内核分割为一个个页帧(page frame)。处理器并不知道也不关心这些帧,然而它们对内核至关重要,因为页帧是物理内存管理的最小单元。Linux和Windows在32位模式下,都使用4KB大小的页帧;以一个拥有2GB RAM的机器为例:
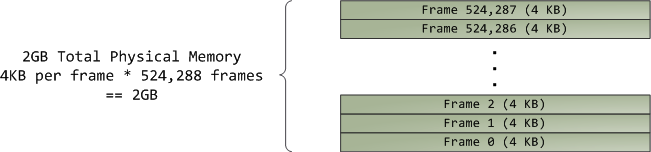
在Linux中,每一个页帧都由一个描述符和一些标志所跟踪。这些描述符合在一起,记录了计算机内的全部物理内存;可以随时知道每一个页帧的准确状态。物理内存是用buddy memory allocation技术来管理的,因此如果一个页帧可被buddy 系统分配,则它就是可用的(free)。一个被分配了的页帧可能是匿名的(anonymous),保存着程序数据;也可能是页缓冲的(page cache),保存着一个文件或块设备的数据。还有其他一些古怪的页帧使用形式,但现在先不必考虑它们。Windows使用一个类似的页帧编号(Page Frame Number简称PFN)数据库来跟踪物理内存。
让我们把虚拟地址区域,页表项,页帧放到一起,看看它们到底是怎么工作的。下图是一个用户堆的例子:
蓝色矩形表示VMA范围内的页,箭头表示页表项将页映射到页帧上。一些虚拟页并没有箭头;这意味着它们对应的PTE的存在位(Present flag)为0。形成这种情况的原因可能是这些页还没有被访问过,或者它们的内容被系统换出了(swap out)。无论那种情况,对这些页的访问都会导致页故障(page fault),即使它们处在VMA之内。VMA和页表的不一致看起来令人奇怪,但实际经常如此。
一个VMA就像是你的程序和内核之间的契约。你请求去做一些事情(如:内存分配,文件映射等),内核说”行”,并创建或更新适当的VMA。但它并非立刻就去完成请求,而是一直等到出现了页故障才会真正去做。内核就是一个懒惰,骗人的败类;这是虚拟内存管理的基本原则。它对大多数情况都适用,有些比较熟悉,有些令人惊讶,但这个规则就是这样:VMA记录了双方商定做什么,而PTE反映出懒惰的内核实际做了什么。这两个数据结构共同管理程序的内存;都扮演着解决页故障,释放内存,换出内存(swapping memory out)等等角色。让我们看一个简单的内存分配的例子:
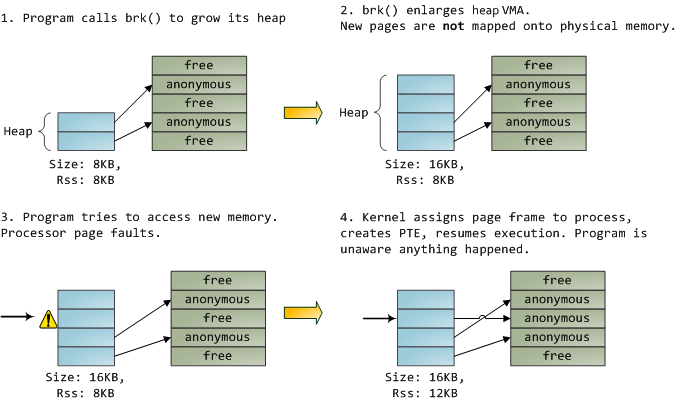
当程序通过brk()系统调用请求更多的内存时,内核只是简单的更新堆的VMA,然后说搞好啦。其实此时并没有页帧被分配,新的页也并没有出现于物理内存中。一旦程序试图访问这些页,处理器就会报告页故障,并调用do_page_fault()。它会通过调用find_vma()去搜索哪一个VMA含盖了产生故障的虚拟地址。如果找到了,还会根据VMA上的访问许可来比对检查访问请求(读或写)。如果没有合适的VMA,也就是说内存访问请求没有与之对应的合同,进程就会被处以段错误(Segmentation Fault)的罚单。
当一个VMA被找到后,内核必须处理这个故障,方式是察看PTE的内容以及VMA的类型。在我们的例子中,PTE显示了该页并不存在。事实上,我们的PTE是完全空白的(全为0),在Linux中意味着虚拟页还没有被映射。既然这是一个匿名的VMA,我们面对的就是一个纯粹的RAM事务,必须由do_anonymous_page()处理,它会分配一个页帧并生成一个PTE,将出故障的虚拟页映射到那个刚刚分配的页帧上。
事情还可能有些不同。被换出的页所对应的PTE,例如,它的Present标志是0但并不是空白的。相反,它记录了页面内容在交换系统中的位置,这些内容必须从磁盘读取出来并通过do_swap_page()加载到一个页帧当中,这就是所谓的major fault。
至此我们走完了"内核的用户内存管理"之旅的前半程。在下一篇文章中,我们将把文件的概念也混进来,从而建立一个内存基础知识的完成画面,并了解其对系统性能的影响。
参考:http://blog.csdn.net/drshenlei/article/details/4350928
页面缓存-内存与文件的那些事
原文标题:Page Cache, the Affair Between Memory and Files
上次我们考察了内核如何为一个用户进程管理虚拟内存,但是没有涉及文件及I/O。这次我们的讨论将涵盖非常重要且常被误解的文件与内存间关系的问题,以及它对系统性能的影响。
提到文件,操作系统必须解决两个重要的问题。首先是硬盘驱动器的存取速度缓慢得令人头疼(相对于内存而言),尤其是磁盘的寻道性能。第二个是要满足’一次性加载文件内容到物理内存并在程序间共享’的需求。如果你使用进程浏览器翻看Windows进程,就会发现大约15MB的共享DLL被加载进了每一个进程。我目前的Windows系统就运行了100个进程,如果没有共享机制,那将消耗大约1.5GB的物理内存仅仅用于存放公用DLL。这可不怎么好。同样的,几乎所有的Linux程序都需要ld.so和libc,以及其它的公用函数库。
令人愉快的是,这两个问题可以被一石二鸟的解决:页面缓存(page cache),内核用它保存与页面同等大小的文件数据块。为了展示页面缓存,我需要祭出一个名叫render的Linux程序,它会打开一个scene.dat文件,每次读取其中的512字节,并将这些内容保存到一个建立在堆上的内存块中。首次的读取是这样的:
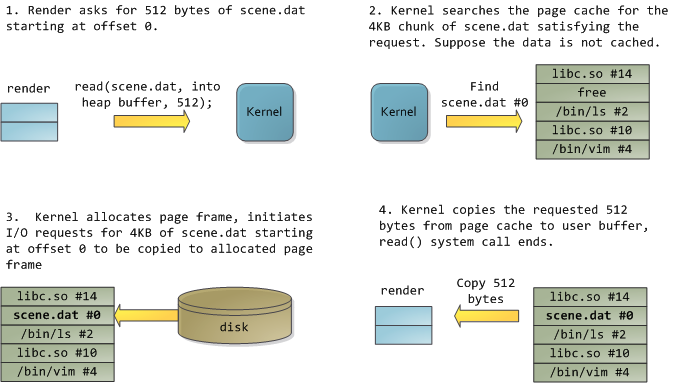
在读取了12KB以后,render的堆以及相关的页帧情况如下.
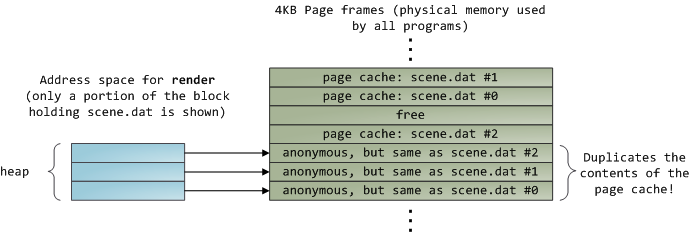
这看起来很简单,但还有很多事情会发生。首先,即使这个程序只调用了常规的read函数,此时也会有三个 4KB的页帧存储在页面缓存当中,它们持有scene.dat的一部分数据。尽管有时这令人惊讶,但的确所有的常规文件I/O都是通过页面缓存来进行的。在x86 Linux里,内核将文件看作是4KB大小的数据块的序列。即使你只从文件读取一个字节,包含此字节的整个4KB数据块都会被读取,并放入到页面缓存当中。这样做是有道理的,因为磁盘的持续性数据吞吐量很不错,而且一般说来,程序对于文件中某区域的读取都不止几个字节。页面缓存知道每一个4KB数据块在文件中的对应位置,如上图所示的#0, #1等等。与Linux的页面缓存类似,Windows使用256KB的views。
不幸的是,在一个普通的文件读取操作中,内核必须复制页面缓存的内容到一个用户缓冲区中,这不仅消耗CPU时间,伤害了CPU cache的性能,还因为存储了重复信息而浪费物理内存。如上面每张图所示,scene.dat的内容被保存了两遍,而且程序的每个实例都会保存一份。至此,我们缓和了磁盘延迟的问题,但却在其余的每个问题上惨败。内存映射文件(memory-mapped files)将引领我们走出混乱:
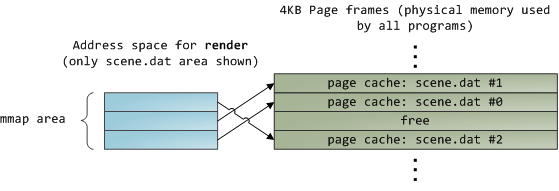
当你使用文件映射的时候,内核将你的程序的虚拟内存页直接映射到页面缓存上。这将导致一个显著的性能提升:《Windows系统编程》指出常规的文件读取操作运行时性能改善30%以上;《Unix环境高级编程》指出类似的情况也发生在Linux和Solaris系统上。你还可能因此而节省下大量的物理内存,这依赖于你的程序的具体情况。
和以前一样,提到性能,实际测量才是王道,但是内存映射的确值得被程序员们放入工具箱。相关的API也很漂亮,它提供了像访问内存中的字节一样的方式来访问一个文件,不需要你多操心,也不牺牲代码的可读性。回忆一下地址空间、还有那个在Unix类系统上关于mmap的实验,Windows下的CreateFileMapping及其在高级语言中的各种可用封装。当你映射一个文件时,它的内容并不是立刻就被全部放入内存的,而是依赖页故障(page fault)按需读取。在获取了一个包含所需的文件数据的页帧后,对应的故障处理函数会将你的虚拟内存页映射到页面缓存上。如果所需内容不在缓存当中,此过程还将包含磁盘I/O操作。
现在给你出一个流行的测试题。想象一下,在最后一个render程序的实例退出之时,那些保存了scene.dat的页面缓存会被立刻清理吗?人们通常会这样认为,但这是个坏主意。如果你仔细想想,我们经常会在一个程序中创建一个文件,退出,紧接着在第二个程序中使用这个文件。页面缓存必须能处理此类情况。如果你再多想想,内核何必总是要舍弃页面缓存中的内容呢?记住,磁盘比RAM慢5个数量级,因此一个页面缓存的命中(hit)就意味着巨大的胜利。只要还有足够的空闲物理内存,缓存就应该尽可能保持满状态。所以它与特定的进程并不相关,而是一个系统级的资源。如果你一周前运行过render,而此时scene.dat还在缓存当中,那真令人高兴。这就是为什么内核缓存的大小会稳步增加,直到缓存上限。这并非因为操作系统是破烂货,吞噬你的RAM,事实上这是种好的行为,反而释放物理内存才是一种浪费。缓存要利用得越充分越好。
由于使用了页面缓存体系结构,当一个程序调用write()时,相关的字节被简单的复制到页面缓存中,并且将页面标记为脏的(dirty)。磁盘I/O一般不会立刻发生,因此你的程序的执行不会被打断去等待磁盘设备。这样做的缺点是,如果此时计算机死机,那么你写入的数据将不会被记录下来。因此重要的文件,比如数据库事务记录必须被fsync() (但是还要小心磁盘控制器的缓存)。另一方面,读取操作一般会打断你的程序直到准备好所需的数据。内核通常采用积极加载(eager loading)的方式来缓解这个问题。以提前读取(read ahead)为例,内核会预先加载一些页到页面缓存,并期待你的读取操作。通过提示系统即将对文件进行的是顺序还是随机读取操作(参看madvise(), readahead(), Windows缓存提示),你可以帮助内核调整它的积极加载行为。Linux的确会对内存映射文件进行预取,但我不太确定Windows是否也如此。最后需要一提的是,你还可以通过在Linux中使用O_DIRECT或在Windows中使用NO_BUFFERING来绕过页面缓存,有些数据库软件就是这么做的。
一个文件映射可以是私有的(private)或共享的(shared)。这里的区别只有在更改(update)内存中的内容时才会显现出来:在私有映射中,更改并不会被提交到磁盘或对其他进程可见,而这在共享的映射中就会发生。内核使用写时拷贝(copy on write)技术,通过页表项(page table entries),实现私有映射。在下面的例子中,render和另一个叫render3d的程序(我是不是很有创意?)同时私有映射了scene.dat。随后render改写了映射到此文件的虚拟内存区域:
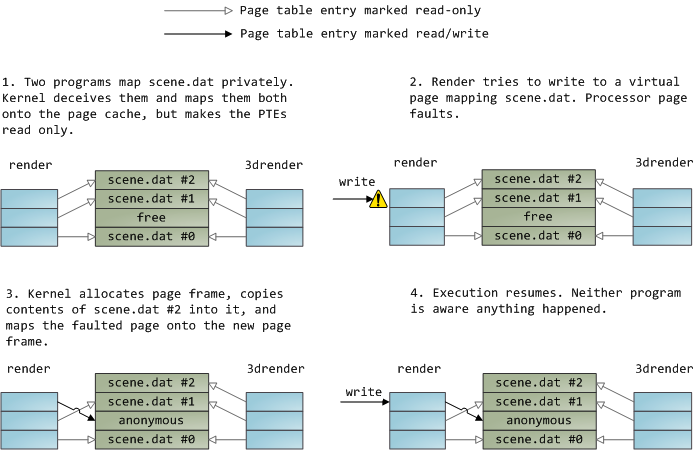
上图所示的只读的页表项并不意 味着映射是只读的,它们只是内核耍的小把戏,用于共享物理内存直到可能的最后一刻。你会发现’私有’一词是多么的不恰当,你只需记住它只在数据发生更改时 起作用。此设计所带来的一个结果就是,一个以私有方式映射文件的虚拟内存页可以观察到其他进程对此文件的改动,只要之前对这个内存页进行的都是读取操作。 一旦发生过写时拷贝,就不会再观察到其他进程对此文件的改动了。此行为不是内核提供的,而是在x86系统上就会如此。另外,从API的角度来说,这也是合理的。与此相反,共享映射只是简单的映射到页面缓存,仅此而已。对页面的所有更改操作对其他进程都可见,而且最终会执行磁盘操作。最后,如果此共享映射是只读的,那么页故障将触发段错误(segmentation fault)而不是写时拷贝。
被动态加载的函数库通过文件映射机制放入到你的程序的地址空间中。这里没有任何特别之处,同样是采用私有文件映射,跟提供给你调用的常规API别无二致。下面的例子展示了两个运行中的render程序的一部分地址空间,还有物理内存。它将我们之前看到的概念都联系在了一起。
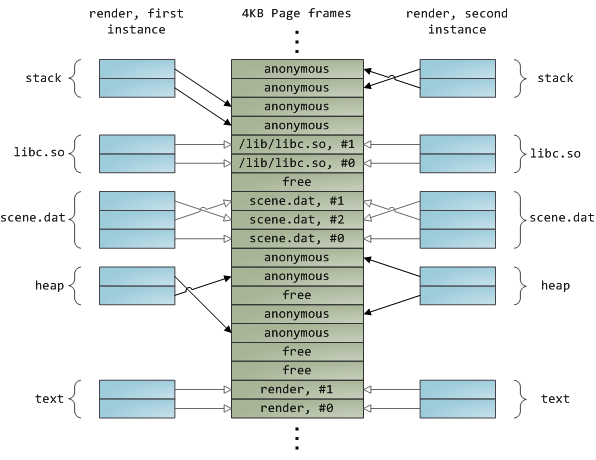
至此我们完成了内存基础知识的三部曲系列。我希望这个系列对您有用,并在您头脑中建立一个好的操作系统模型。















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









