










大家好!我是测试彭于晏~
最近在工作中使用locust做性能压测,发现这款工具非常强大,特别是在单台压测机能够制造更多的并发量,于是整理成了这份文档,故分享给大家。
(一)认识Locust
1.主流性能测试工具对比
| 工具 | Locust | Jmeter | Loadrunner |
| 是否收费 | 免费 | 免费 | 收费 |
| 语言 | Python | Java | C |
| 并发机制 | 协程 | 线程 | 进程/线程 |
| 单机并发能力 | 高 | 低 | 低 |
| 场景压测 | 支持 | 支持 | 支持 |
| 分布式 | 支持 | 支持 | 支持 |
2.Locust性能测试工具介绍
-
简介
Locust是一款易于使用的分布式负载测试工具,一个locust节点就可以在一个进程中支持数千并发用户,基于事件,通过gevent使用轻量级执行单元。
-
线程和协程的区别
-
-
一个线程可包含多个协程
-
线程和进程是同步机制,协程是异步
-
线程的切换由操作系统调度,协程由用户自己进行调度
-
协程相较于线程更加轻量,资源消耗更低
-
-
为什么选择locust?
-
-
基于协程,低成本实现更多并发
-
有第三方插件,易于扩展
-
支持分布式、高并发能力
-
(二)Locust基础语法
1.Locust安装
pip install locust2.Locust文档详解
https://cloud.tencent.com/developer/article/1594240
3.Locust核心概念
User类
概念:表示要生成进行压力测试的用户
用户:每个user实例相当于一个用户
task
概念:用于处理用户的行为,比如:登录会员-> 获取会员信息-> 刊登物件
-
TastSet:定义用户将执行的一组任务的类,测试任务开始后,每个locust用户会从TastSet中随机挑选一个任务执行
-
4.Locust运行与监控
-
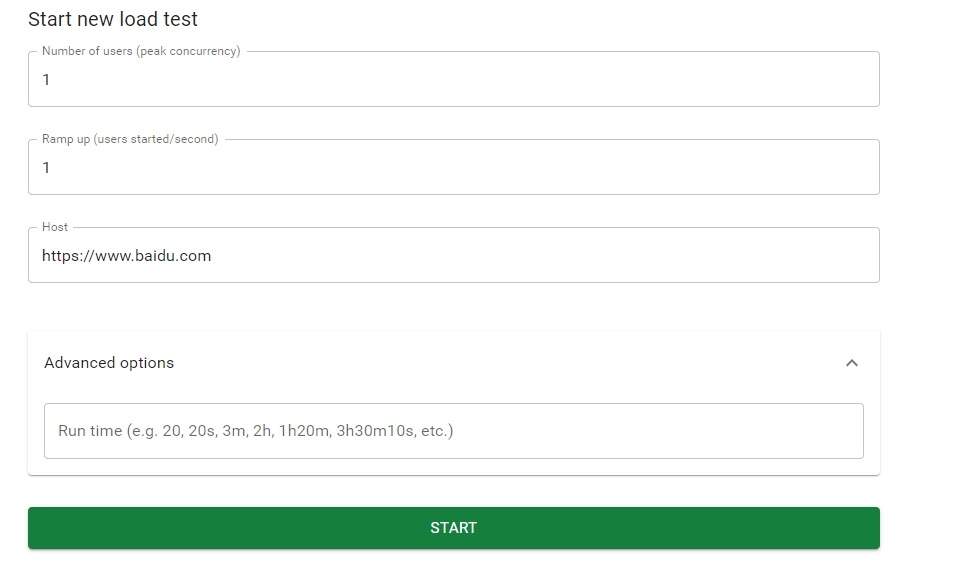
图形化界面
1. 通过命令行启动Locust服务,然后访问http://localhost:8089
2. 在页面设置执行压测的策略,并发的用户数,每秒启动的用户数,执行多长时间等
3. 点击start,开启执行压测
-
命令行界面
locust -f locustfile.py --headless -u 100 -r 10 -t 30s-
启动参数
-
-f, --locustfile:指定 locustfile 的文件路径。
-
-H, --host:指定要测试的主机地址。
-
-u, --users:设置并发用户数。
-
-r, --spawn-rate:设置用户生成速率。
-
-t, --run-time:设置测试运行时间。
-
-L, --no-reset-stats:在测试期间不重置统计数据。
-
–csv:将结果保存为 CSV 文件。
-
–headless:以无界面模式启动 Locust
-
--web-host IP地址:设置web页面的访问IP
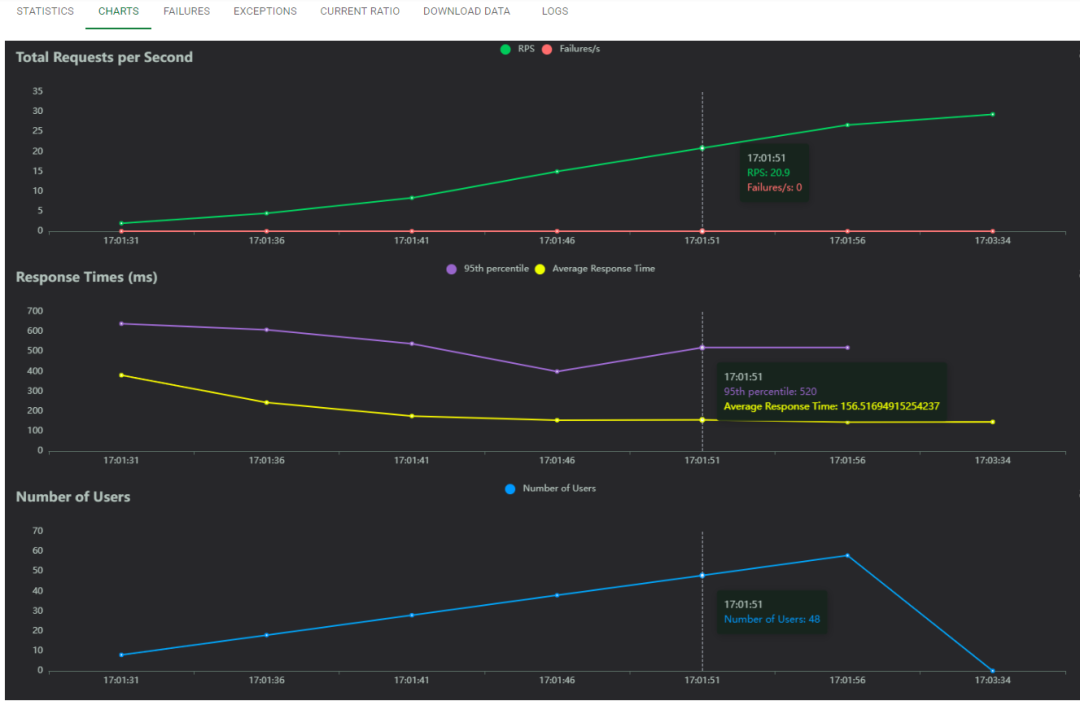
5. 性能指标
-
RPS
Requests per Second:每秒完成的请求数,类似于TPS,反映服务器的处理能力
-
响应时间
Average Response Time:每个请求的平均响应时间
-
用户数
Number of Users
(三)Locust扩展应用
1. 参数化
1.1 通过引入队列的方式,实现方式是将测试数据插入队列,然后依次取出,数据取完后locust会自动停止。
1.2 若是需要将测试数据循环使用,则每次取出数据后,然后再插入队尾,即可实现循环压测
import queue# 读取测试数据(读取csv文件的测试数据)csv_list = csv_to_list('user.csv')# 创建队列q = queue.Queue()# 遍历列表数据,将数据放入队列for i in csv_list:q.put(i)# 从队列取出数据,原理:先进先出q.get()
2. 检查点
-
默认检查点
locust默认情况会使用默认的检查点,比如当接口超时,链接失败等原因,会判断请求失败。
-
手动设置检查点
使用self.client提供的catch_response=True参数,添加locust提供的success和failure方法。其中failure方法需要传入一个参数,内容就是失败的原因。
3. 思考时间
wait_time
-
固定时间:constant(wait)
-
区间随机时间:between(min_wait, max_wait)
-
自适应时间:constant_pacing(wait),设置每个任务的最长时间
4. 权重
测试中,存在多个User Class,默认情况下locust将为每个User Class的实例的数量是相同的。通过设置weight属性,来控制locust为我们的User Class 生成不同数量的实例。
方式一
在HttpUser类中任务函数通过@task设置,能够在同个Class类中设置不同任务的权重比
class QuickstartUser1(HttpUser):# 设置该任务权重为:1@task(1)def task_demo1(self):print("执行的第一个任务")# 设置该任务权重为:3@task(3)def task_demo2(self):print("执行的第一个任务")
方式二
文件中存在多个用户类场景,可以通过在类的属性中定义权重,,在启动locust服务后,会更加设置的权重来执行任务,比如下图中QuickstartUser1和QuickstartUser2执行权重是:1:3
class QuickstartUser1(HttpUser):# 设置该类下的权重为:2weight = 1def task_demo1(self):print("执行的第一个任务")def task_demo2(self):print("执行的第一个任务")class QuickstartUser2(HttpUser):# 设置该类下的权重为:3weight = 3def task_demo3(self):print("执行的第一个任务")def task_demo3(self):print("执行的第一个任务")
5. 集合点
什么是集合点?
在性能测试过程中,假设需要测试系统能否支持1000人同时访问该业务,然后在调用该业务之前加入集合点,当所设置的虚拟用户运行到集合点时,便开始检测集合点是否以满足1000人,如果不满足,已到达集合的用户在该位置等待,当设置的虚拟用户达到1000人时,然后才会去执行1000人同时访问该业务,从而通过高并发的压测,测试系统的性能瓶颈。
# 通过gevent并发机制,使用gevent的锁来实现from locust import HttpUser, TaskSet, task, between, eventsfrom gevent._semaphore import Semaphoreall_locusts_spawned = Semaphore()all_locusts_spawned.acquire() # 阻塞线程def on_hatch_complete(user_count,**kwargs):"""Select_task类的钩子方法"""print(f"{user_count}个虚拟用户产生完成")# 创建钩子方法all_locusts_spawned.release()# 挂在到locust钩子函数(所有的Locust示例产生完成时触发)events.spawning_complete.add_listener(on_hatch_complete)n = 0class UserBehavior(TaskSet):def on_start(self):global nn += 1print("%s个虚拟用户开始启动" % n)all_locusts_spawned.wait() # 同步锁等待@taskdef test2(self):url = '/detail'with self.client.get(url, headers={}, catch_response=True) as response:print("用户同时执行查询")class WebsiteUser(HttpUser):host = 'https://www.baidu.com'wait_time = between(1, 2)tasks = [UserBehavior]
6. 分布式
如果单台机器不足以模拟所需的用户数量,Locust可以可以设置为单机主从模式和多机主从模式,具体可参考文档:https://blog.csdn.net/qq_36076898/article/details/109015136?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-109015136-blog-131328446.235^v43^pc_blog_bottom_relevance_base6&spm=1001.2101.3001.4242.1&utm_relevant_index=1
7. 高性能FastHttpUser
相对于HttpUser是直接继承python-request,FastHttpUser则是使用更快的geventhttpclient代替,它提供了一个相似的 API,在相同的并发条件下使用FastHttpUser能有效减少压测机的资源消耗,从而达到更大的http请求数
(四)性能测试场景实例
压测场景
备注:多场景串连,模拟用户登录-> 然后获取用户的物件列表
1.压测策略
并发用户数:100个,每秒增加2个用户,压测时长:1min, 登录接口和获取物件列表权重比为:1:10
2.测试脚本
# -*- coding:utf-8 -*-# Time: 2024/5/18import osfrom locust import HttpUser, task, between,constant, constant_pacing, SequentialTaskSetfrom loader import csv_to_listimport queue# 读取测试数据csv_list = csv_to_list('user.csv')# 创建队列q = queue.Queue()# 将数据放入队列for i in csv_list:q.put(i)# 多个任务按照顺序执行class UserBehavior(SequentialTaskSet):access_token = Noneheaders = {'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1'}@task(1)def login(self):"""登录 """self.headers.update({'Content-Type': 'application/x-www-form-urlencoded', 'device': 'pc', 'deviceid': '48jjqt2uk0r8gopajpc616hqm7'})data = {'login_type': 'pwd'}data.update(q.get())q.put(data)# print(data)with self.client.post("/v2/user/login", headers=self.headers, data=data, verify=False, catch_response=True, name='登录') as response:if response.status_code != 200:response.failure('Failed to get land list api')if response.json()['status'] != 1:response.failure('Failed to get land list')else:self.access_token = response.json().get('data').get('access_token')@task(10)def get_user_house_list(self):""""获取物件列表"""payload = {"device": "pc","deviceid": "bno6bbc7na848krqc6vpi39s54","current_page": 1,"page_size": 15}self.headers.update({'access-token': self.access_token})with self.client.post("/v1/user/ware/open", headers=self.headers, json=payload, verify=False, catch_response=True, name='获取物件列表') as response:if response.status_code != 200:response.failure('Failed to get land list')if response.json()['status'] == 1:response.success()# print(response.json())# HttpUser类是Locust的基类,用于定义用户行为class QuickstartUser(HttpUser):wait_time = between(1, 2)host = 'https://test.123.com'tasks = [UserBehavior]
3.测试结果

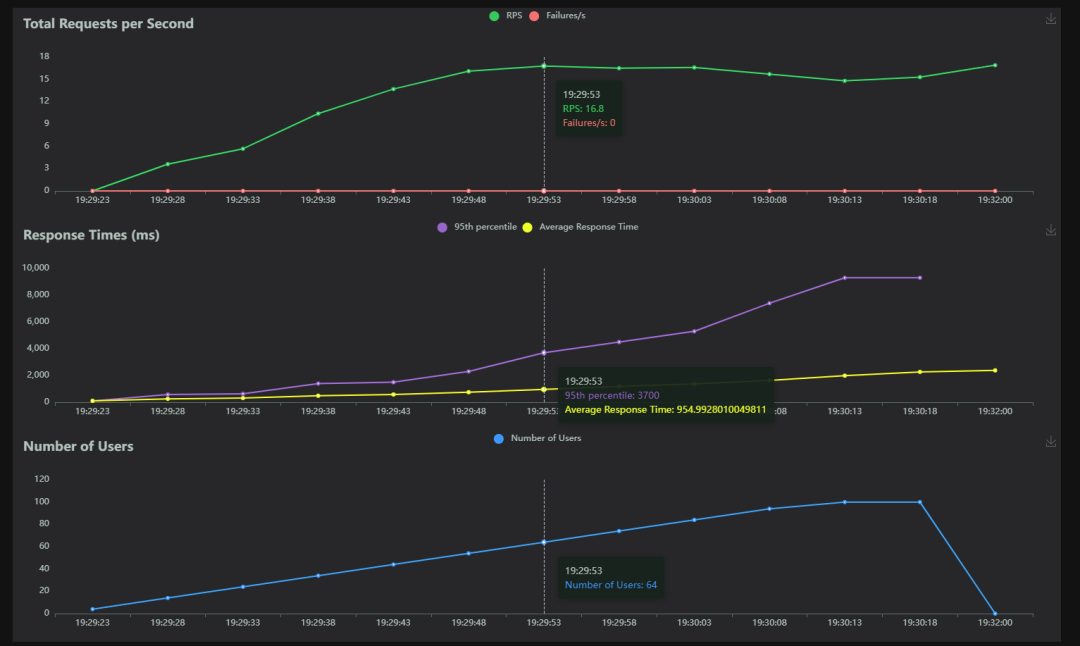
结论:通过曲线图可以看到,当用户数达到64,RPS峰值达到16.8,随着压力进一步的增大,RPS明显区域平稳,此时基本可以看出该接口RPS趋于16,即RPS =16,另外随机压力的增大,响应时间是越来越慢,故实际的符合要求的RPS明显要低于16
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
















 849
849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









