










一、 规范性能测试实施流程的意义
规范的性能测试实施流程能够加强测试工作流程控制,明确性能测试各阶段应完成的工作,指导测试人员正确、有序的开展性能测试工作,提高各角色在性能能测试中的工作效率。本次分享的性能测试实施流程是性能测试开展的”指导方针”,希望帮助您可以早日成为性能测试”达人”。
二、 性能测试实施流程
性能测试流程分为五个阶段,分别是【需求调研阶段】→【测试准备阶段】→【测试执行阶段】→【测试报告阶段】→【测试总结阶段】。
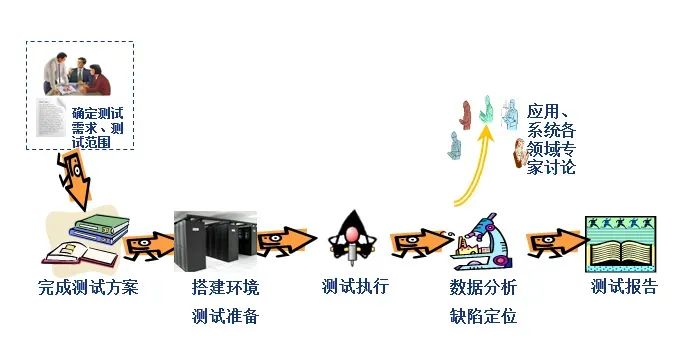
每个阶段做什么事情?重点关注什么?
1.需求调研阶段
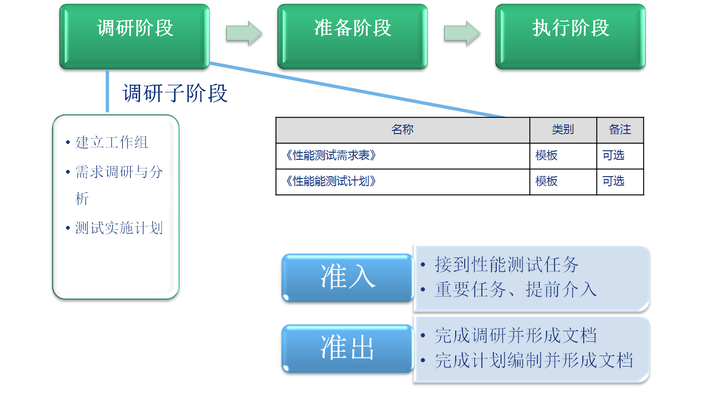
1.1. 阶段概述
调研阶段的主要工作为:组建工作小组、项目创建、需求分析、模型构建、定制性能测试详细实施计划。
重点关注:需求调研、需要分析、模型构建
1.2. 关键点描述
需求调研分为两个步骤进行:需求调研、需求分析。
该工作是性能测试必须的工作环节。工作产出文件为《XX项目性能测试需求表》,如:《云智慧_XXX系统_XXX模块性能测试需求表》。
此阶段模型构建主要是业务模型构建。
1.2.1需求调研
-
需求调研工作由性能测试实施人员牵头负责,产品经理、开发工程师、运维工程师配合完成;
-
需求调研的主要内容为:
-
系统线上环境的性能需求,例如性能需求、可靠性需求、可维护性需求等;
-
与系统性能需求相关的其它信息,包括系统信息(如线上环境硬件、参数配置、系统架构与部署方式、关联系统部署等)、业务信息(关键业务逻辑与处理流程、交易列表、交易量信息、业务分布规律等)、生产问题、文档资料等方面,并对收集到的信息进行汇总整理,实现对待测系统业务与技术的整体了解;
-
开发项目组、需求部门、运维部门等测试任务提出方应填写《云智慧_XXX系统_XXX模块性能测试需求表》中的“任务信息”和“测试背景”等信息,提出的测试需求,简单文字不能说明的,可附加文件;
-
性能测试小组的实施人员将调研获取的其它内容填入《云智慧_XXX系统_XXX模块性能测试需求表》;
-
对于新立项系统或系统新开发版本,《云智慧_XXX系统_XXX模块性能测试需求表》应与《需求规格说明书》中的性能需求相一致。
1.2.2需求分析
需求分析的基本流程是:
首先,由性能测试工程师根据需求调研所获取的信息进行分析,将《云智慧_XXX系统_XXX模块性能测试需求表》中的性能需求转换为具体的性能需求指标值;
其次,根据测试环境与线上环境的差异分析,由性能测试工程师将线上环境条件下的性能需求指标值转换为本次测试环境条件下的性能需求指标值;
例如:TPS(Transaction per Second):系统每秒处理交易数,推导过程如下:
当前线上APP1.0试用系统主要为查询类交易,交易占比40%,系统生产交易量统计为1个月约20W笔,假设APP2.0系统上线后业务量激增到每日查询类20W,则每日总交易量T达到:
T = 20W/40%=500000笔/日
系统处理能力TPS推导:APP2.0上线后交易量最大500000笔/日,系统晚间几乎无交易量,按2:8原则推算,则(500000*80%)/(8*20%*3600)=69.4笔/秒,取整为70笔/秒,每年按业务量增长50%计算,则一年后系统处理能力指标约等于70+70*50%=105笔/秒。
稳定性交易量推导:
取系统处理能力的60%*时长=105笔/秒*60%*8*3600=1814400笔。
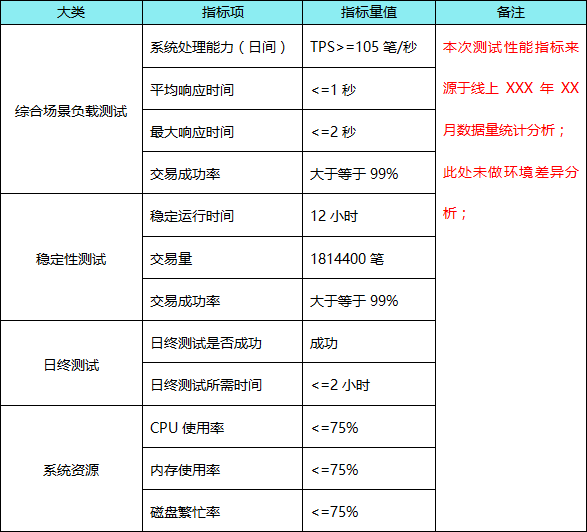
经过分析后汇总成测试指标值
需求分析其主要内容和规范性要求如下:
性能测试需求:应准确描述性能测试指标项及需求指标值。
系统范围:应准确描述性能测试需求指标值所依托的测试范围信息,如应描述测试范围的关联系统逻辑示意图,及各关联系统的信息;在对系统局部环节进行测试时,也需阐明具体测试范围,详细描述被测系统的相关子系统。
环境差异分析:应准确描述性能测试需求指标值所依托的测试环境信息,如须描述测试环境的总体网络拓扑结构图、测试环境机器配置表(数量、型号、资源、操作系统)、以及相应的软件配置、重要参数配置等。同时应准确描述线上环境的上述信息,并进行详细的环境差异性分析。
以上分析内容将作为性能测试方案的重要组成部分。
1.2.3模型构建例如:业务模型
根据200X年XX月XX日~200X年XX月XX日期间的业务高峰日200X年XX月XX日的业务量统计,经过略微调整得出以下业务模型,要求业务模型交易至少占线上交易量的90%以上:
2.测试准备阶段
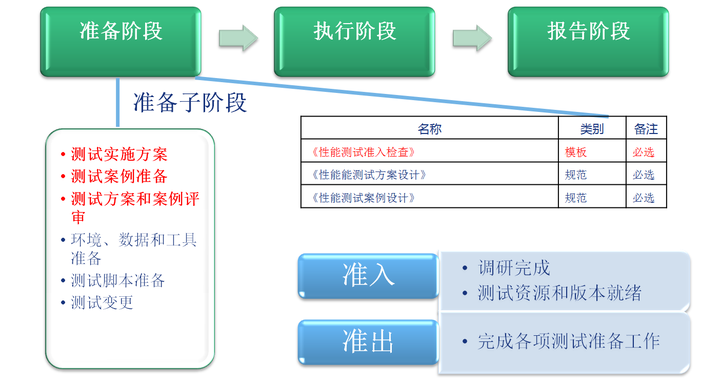
2.1阶段概述
测试准备阶段是性能测试工作中重要阶段。在准备阶段,需要完成业务模型到测试模型的构建、性能测试实施方案编写、测试环境的准备、性能测试案例设计、性能测试监控方案设计、性能测试脚本,及相关测试数据的准备,并在上述相关准备活动结束后按照测试计划进行准入检查。
重点关注:测试模型构建、方案设计、案例设计、数据准备等
2.2关键点描述
2.2.1测试模型构建
测试模型构建工作由性能测试实施人员完成;
在需求分析的基础上,对调研收集到的相关资料与信息进行分析梳理,重点分析跨系统的交易路径、交易关联关系、数据的处理与流转、业务量、交易比例、典型交易,以及系统的处理能力等性能测试点,针对性地确定多个业务场景,并为每个场景选择一套具体的业务交易集,按照业务量比例构建相应的测试模型。
本阶段的产出物为,各个测试场景,以及场景中典型交易及所占比率。
例如:从业务模型到测试模型推导
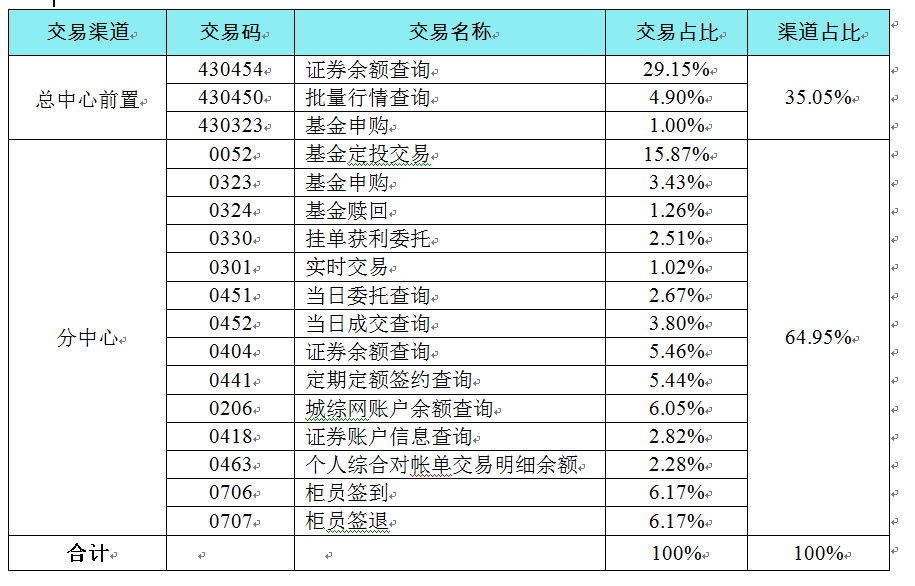
依据业务模型,通过与项目组及产品经理沟通,确定本次测试模型还需着重考虑以下内容:
(1) 考虑到后期证券系统数据库升级,历史查询可能会影响,所以本次测试单独增加一个场景:历史委托和历史成交查询各50%(即0456和0457)。同时,考虑到线上环境绝大部分该交易是由总中心前置发起,所以本次测试“历史委托和历史成交查询”交易均采用从总中心发起;
(2) 增加国债发行交易场景,国债发行认购日一般在柜台营业前进行,此场景只选择国债发行认购一支交易;
(3) 同时,证券系统交易高峰时段柜员签到、柜员签退交易占比较小。
通过以上分析得出本次测试模型有3个:一般交易日日间模型、国债发行日模型、以及历史查询交易模型。
一般交易日日间模型:
储蓄国债交易模型:

历史查询交易模型:

2.2.2方案设计
性能测试实施方案编制是性能测试工作中必须的工作环节,其产出为《性能测试方案》,如:《云智慧XXX项目_XXX功能模块性能能测试方案V1.0.xlsb》。
在方案中需要描述:测试需求、启停准则、测试模型设计、测试策略、测试内容、测试环境与工具需求,以及各个阶段的输出文档。在方案中还需说明性能测试工作的时间计划安排、预期的风险与风险规避方法等。测试模型设计内容来自本阶段测试模型设计中形成的测试场景,以及场景中典型交易及所占比率。
2.2.3案例设计
在案例设计中,包括案例的描述、测试环境描述(硬件、软件、应用版本、测试数据)、延迟设置、压力场景、执行描述、预期结果、监控要点。
案例设计是性能测试工作的必须工作环节,案例设计的产出文件是《性能测试案例》。
2.2.4数据准备
环境准备工作中涉及到基础数据的准备。测试数据的数量、逻辑关系要求十分严格,测试基础数据的准备一般采用自造模拟数据或者使用脱敏后的线上数据。
2.2.5测试脚本开发
测试脚本开发工作就是发挥LR的时候。
测试脚本是对业务操作的程序化体现,一个脚本一般为一项业务的过程描述。本活动主要为脚本的录制(编写)、修改和调试工作,从而保证在测试实施之前每个测试用例的脚本都能够在单笔和少量迭代次数的条件下能够正确执行。测试脚本开发的一般步骤如下:
-
通过录制,或者编写,完成脚本代码生成。代码生成时,主要根据需求插入事务,作为测试过程中统计交易响应时间的单位;
-
根据测试需求,进行参数化设置;
-
设定检查点,根据报文内容字段判断交易是否正确执行,即检查点的设置在应用层面;
-
根据测试要求确定是否设置集合点;
3.测试执行阶段
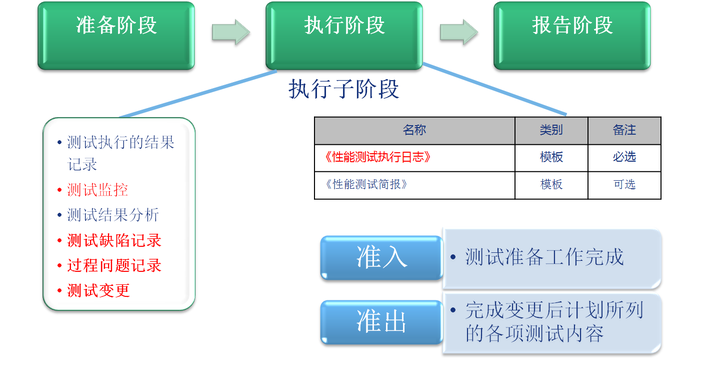
3.1阶段概述
测试执行阶段是执行测试案例,获得系统处理能力指标数据,发现性能测试缺陷的阶段。测试执行期间,借助测试工具执行测试场景或测试脚本,同时配合各类监控工具。执行结束后统一收集各种结果数据进行分析。根据需要,执行阶段可进行系统的调优和回归测试。
重点关注:结果记录、测试监控、结果分析
3.2关键点描述
3.2.1测试执行与结果记录
测试执行过程有相应的优先级策略,依据测试案例的优先级别,优先执行级别较高的测试案例。测试过程中,通过对每个测试结果的分析来决定是重复执行当前案例还是执行新的测试案例;通常发现瓶颈问题会立即进行调整并重新执行测试用例,直到当前的案例通过。
在执行阶段,测试的执行、分析调优、回归测试工作较为反复,须认真记录全部执行过程和执行结果,执行结果数据是分析瓶颈的主要依据。
3.2.2测试监控
测试的监控工作与执行工作同步进行,场景或脚本开始执行时,同时启动监控程序(可以用nmon或者系统命令top/vmstat/iostat 等),当然也可以用云智慧的监控宝和透视宝协同工作,监控宝可以监控网站/网页性能/Ping/DNS/FTP/UDP/TCP/SMTP等IT基础设施的性能指标,透视宝可以发现主机资源、Web应用、浏览器、APP等应用的性能瓶颈,如下图所示:
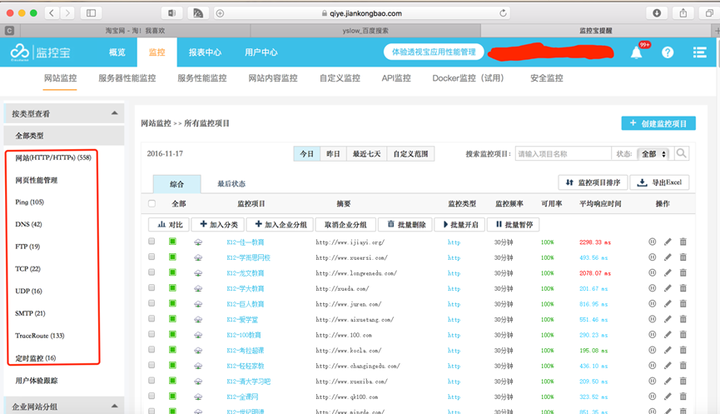
监控宝监控页面
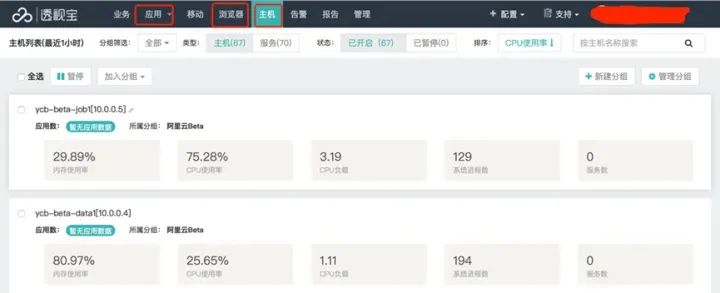
透视宝主机资源监控页面
在执行结束后,停止测试监控,并提取监控结果数据。
3.2.3测试结果分析
测试过程中根据前端性能测试工具显示结果、监控结果综合分析出现的测试问题。
例如:测试组在执行“一般日日间交易模型”负载测试570TPS压力时,数据库监控发现有死锁想象,具体如下:

问题分析:经与开发一同分析,原因如下:流控信息收集程序(pltflowGthDaemon)在同一柜员、在毫秒级并发做交易时plt_flowgather表出现死锁。测试环境联机交易使用同一个柜员号发起,因此出现概率较高。
4.测试报告阶段
4.1阶段概述
测试执行工作结束后开始撰写性能测试报告。性能测试报告在发布前需要进行评审。
4.2关键点描述
4.2.1报告撰写
性能测试报告要内容包括:测试目的、范围及方法、环境描述、测试结果描述、结果分析、结论和建议等。
4.2.2测试结果描述
测试结果的描述,应体现性能测试的执行过程,如:混合场景的容量测试结果展示中,需要描述各个并发梯度下测试结果及监控结果;在数字形式的结果记录中,要求小数点后精确3位有效数字。
4.2.3测试缺陷与问题
在性能测试分析报告中须描述测试过程发现的缺陷与问题,对于确认是测试缺陷的项进行风险评估,并给出风险提示。
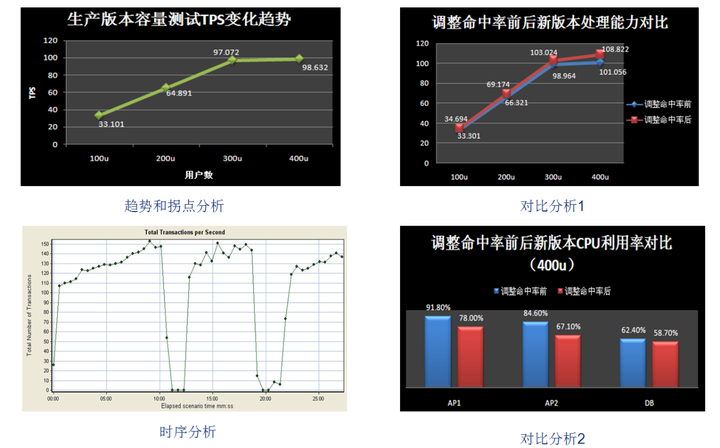
4.2.4最终结果分析
测试最终结果的分析,该部分内容应该全面、透彻、易理解且通过图表方式表达更直观。
例如:
4.2.5测试结论
测试结论是性能测试分析报告必须包括的内容。测试的结论须清晰、准确回答性能测试需求中描述的各项指标,需全面覆盖测试需求。
5.测试总结阶段
5.1阶段概述
性能测试的总结工作,主要对该任务的测试过程和测试技术进行总结。性能测试工作进入总结阶段,也意味着性能测试工作临近结束。在这个阶段,时间允许的情况下应将所有的重要测试资产进行归档保存。
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。



















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









