









 本文详细介绍了如何使用JavaScript、HTML和CSS实现一个歌词滚动效果,包括从字符串到数组对象的处理,动态生成DOM元素,以及根据音频播放进度调整歌词列表的偏移量。
本文详细介绍了如何使用JavaScript、HTML和CSS实现一个歌词滚动效果,包括从字符串到数组对象的处理,动态生成DOM元素,以及根据音频播放进度调整歌词列表的偏移量。
先看下效果吧:
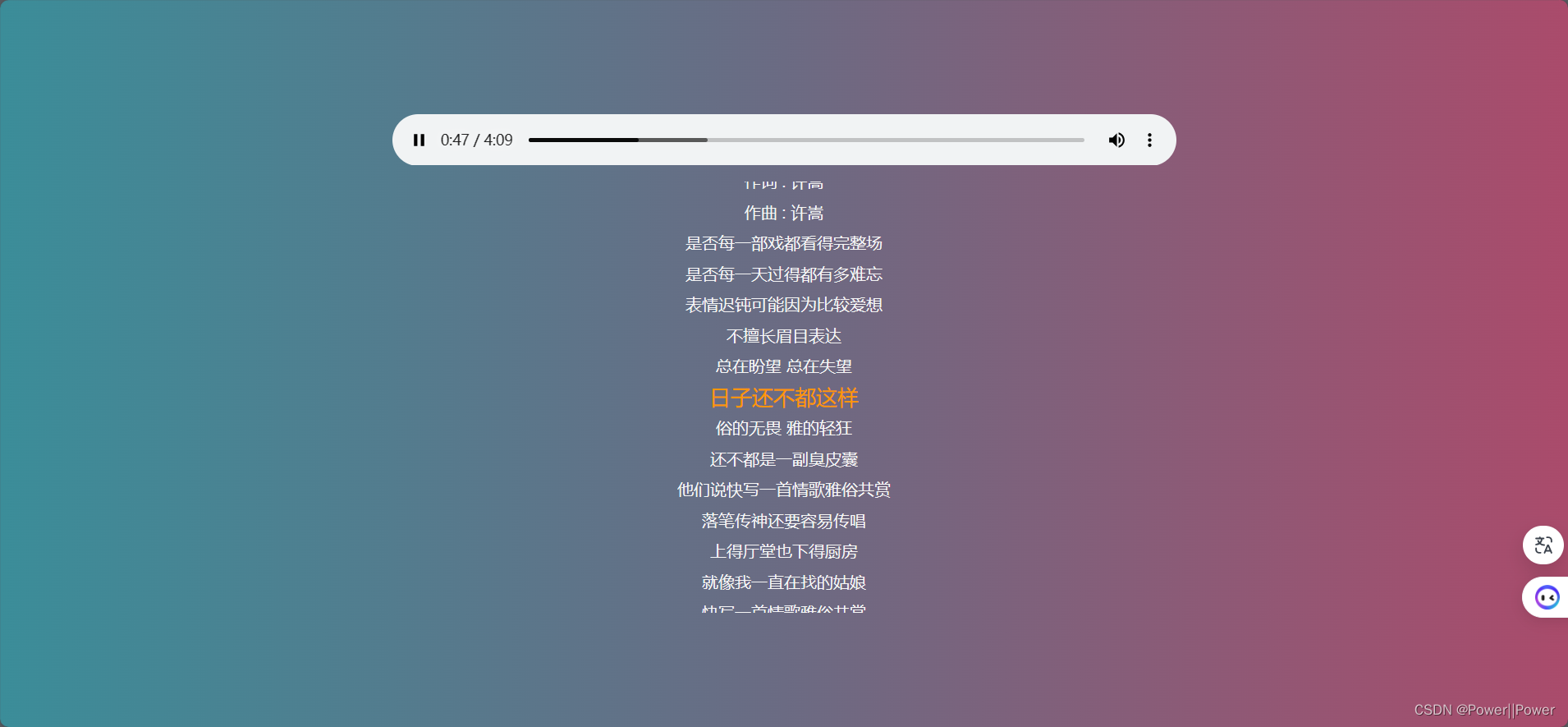
由于实现这个效果的重心是在于js,html 和 css 大家看代码就明白了
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="shortcut icon" href="./assets/favicon.ico" type="image/x-icon">
<link rel="stylesheet" href="./style.css">
<title>歌词滚动效果</title>
</head>
<body>
<div class="contain">
<audio src="./assets/music.mp3" controls></audio>
<div class="box">
<ul>
// 这里等后面使用js动态生成
</ul>
</div>
</div>
<script src="./main.js" type="module"></script>
</body>
</html>
css
* {
margin: 0;
padding: 0;
box-sizing: border-box;
list-style: none;
}
.contain {
width: 100vw;
height: 100vh;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
gap: 16px;
background: #aa4b6b; /* fallback for old browsers */
background: -webkit-linear-gradient(to right, #3b8d99, #6b6b83, #aa4b6b); /* Chrome 10-25, Safari 5.1-6 */
background: linear-gradient(to right, #3b8d99, #6b6b83, #aa4b6b); /* W3C, IE 10+/ Edge, Firefox 16+, Chrome 26+, Opera 12+, Safari 7+ */
}
audio{
width: 50%;
height: 50px;
}
.box{
width: 550px;
height: 420px;
text-align: center;
color: #f6f6f6;
/* 超出隐藏 */
overflow: hidden;
}
ul {
transition: .6s;
}
li{
height: 30px;
line-height: 30px;
transition: 0.2s;
}
.active{
color: rgb(255, 150, 4);
transform: scale(1.3);
}
js部分
1.导出资源
首先将准备好的歌词字符串进行导出
var lrc = `[00:01.06]难念的经
[00:03.95]演唱:周华健
[00:06.78]
[00:30.96]笑你我枉花光心计
[00:34.15]爱竞逐镜花那美丽
[00:36.75]怕幸运会转眼远逝
[00:39.32]为贪嗔喜恶怒着迷
[00:41.99]责你我太贪功恋势ƒ
[00:44.48]怪大地众生太美丽
....`;
export default lrc
2. 引入资源
在主文件里面进行引入
import lrc from "./assets/data.js";
console.log(lrc)
3. 歌词字符串转换为 数组对象的形式
解析歌词 转换为歌词数组对象的形式
因为目前歌词lrc 只是一个字符串对象,里面包含了歌曲时间和对应的歌词,但是在字符串里面,不好操作,我们需要将每一句歌词以及开始的时间放入一个歌词对象里面,然后将每一个歌词对象放入数组里面
const parseLrc = () => {
// 准备好一个包含歌词对象的数组
const lrcData = [];
// 按照"]"字符进行分割
const lines = lrc.split('\n');
// 生成一个数组,用来放置每一句歌词对象(包括时间,和 歌词)
// 循环遍历整个歌词数组
for (let i = 0; i < lines.length; i++) {
const item = lines[i].split(']')
const time = item[0].substring(1);
const words = item[1];
const obj = {
time: parseTime(time),
words
}
lrcData.push(obj);
}
return lrcData
}
- 观察 歌词字符串
[00:01.06]难念的经\n[00:03.95]演唱:周华健我们不难发现,我们首先可以按照\n 进行分割, 得到一个字符串数组
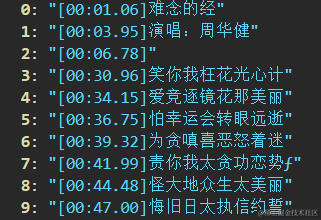
- 然后进行遍历,拿到第二项,再次进行分割 按照
]进行分割,得到['[00:01.06', '难念的经'],进而进行针对数组的第一项也就是开始时间 进行substring截取 - 然后创建一个歌词对象,在里面添加属性和值即可,
const obj = {
time: parseTime(time),
words
}
- 但是又遇到了问题, 我们上面的时间,如果不进行特殊处理的话,是这样的
00:39.32, 而我们希望它是39.32, 我们可以得出一个转换公式第一个项 * 60 + 第二项
转换时间的函数
const parseTime = (timeStr) => {
// 进行分割 按照:进行分割
const parts = timeStr.split(':');
return Number(parts[0]) * 60 + Number(parts[1])
}
- 最后将处理好的对象 添加到准备好的数组里面即可, 并返回这个数组
4. 绘制页面
创建 元素片段的作用 主要为了优化代码, 提高效率,其实对于这种少数循环插入, 可以不采用.
const doms = {
audio: document.querySelector('audio'),
box: document.querySelector('.box'),
ul: document.querySelector('.box ul')
}
const drawPage = () => {
// 创建元素片段
const frag = document.createDocumentFragment();
for (let i = 0; i < resulr.length; i++) {
// 创建li标签
const li = document.createElement('li');
// 设置li标签的文本内容
li.textContent = resulr[i].words;
frag.appendChild(li);
}
doms.ul.appendChild(frag);
}
drawPage()
5. 设置ul元素偏移
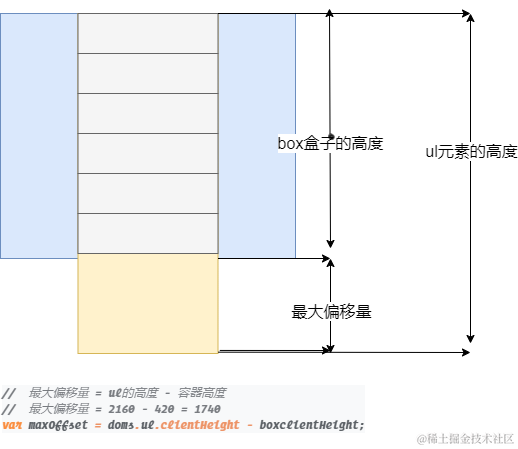
这个我们可以看一下图,来更好的方便去理解
这个是最大偏移量, 用来后续做边界判断的
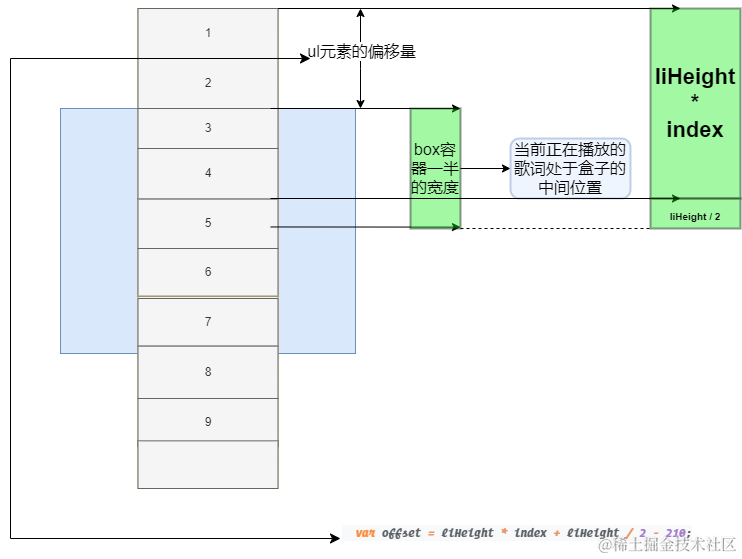
每次更新时间线之后, ul元素的偏移的量:
// 容器高度
var boxclientHeight = doms.box.clientHeight; // 420
// 每个 li 的高度
var liHeight = doms.ul.children[0].clientHeight;// 30
// 最大偏移量
// 最大偏移量 = ul的高度 - 容器高度
// 最大偏移量 = 2160 - 420 = 1740
var maxOffset = doms.ul.clientHeight - boxclientHeight;
console.log("最大偏移量", maxOffset);
// 高亮歌词 + 设置ul偏移量
const setOffset = () => {
let index = findIndex();
//
console.log(index);
// 30 * 1 + 15 = 45 - 210 = -165
let offset = liHeight * index + liHeight / 2 - 210;
console.log(offset);
if (offset < 0) {
offset = 0
}
// 如果超出最大偏移量 设置偏移量为最大偏移量
if (offset > maxOffset) {
offset = maxOffset
}
doms.ul.style.transform = `translateY(-${offset}px)`;
console.log(doms.ul.style.transform);
// 去掉之前的active样式
let li = doms.ul.querySelector('.active');
if (li) {
li.classList.remove('active');
}
// 添加active样式
li = doms.ul.children[index];
if (li) {
li.classList.add('active');
}
}
6. 添加事件监听, 不断执行偏移函数
doms.audio.addEventListener('timeupdate', setOffset);
7. 完整js代码
data.js
var lrc = `[00:00.000] 作词 : 许嵩
[00:01.000]作曲 : 许嵩
[00:15.450]是否每一部戏都看得完整场
[00:22.350]是否每一天过得都有多难忘
[00:29.300]表情迟钝可能因为比较爱想
[00:36.250]不擅长眉目表达
[00:42.010]总在盼望 总在失望
[00:45.460]日子还不都这样
[00:48.960]俗的无畏 雅的轻狂
[00:52.460]还不都是一副臭皮囊
[00:59.260]他们说快写一首情歌雅俗共赏
[01:03.710]落笔传神还要容易传唱
[01:07.110]上得厅堂也下得厨房
[01:10.210]就像我一直在找的姑娘
[01:14.070]快写一首情歌雅俗共赏
[01:17.570]打完字谜还要接着打榜
[01:21.020]如果胡同弄堂全都播放
[01:24.220]气韵里居然添了些孤芳自赏
[01:46.300]是否每一场美梦醒来都很爽
[01:52.660]是否每一次成熟都徒增了业障
[01:59.510]比痛和痒更多的
[02:02.760]是不痛不痒
[02:06.710]所以我爱进剧场
[02:12.460]总在盼望 总在失望
[02:15.960]日子还不都这样
[02:19.260]俗的无畏 雅的轻狂
[02:22.810]还不都是一副臭皮囊
[02:29.020]他们说快写一首情歌雅俗共赏
[02:34.120]落笔传神还要容易传唱
[02:37.620]上得厅堂也下得厨房
[02:40.670]就像我一直在找的姑娘
[02:44.570]快写一首情歌雅俗共赏
[02:48.020]打完字谜还要接着打榜
[02:51.480]如果胡同弄堂全都播放
[02:54.630]气韵里居然添了些孤芳自赏
[03:02.380]谁的故事有营养
[03:05.480]大俗或大雅的都在理直气壮
[03:09.380]洒狗血或白雪的现场
[03:13.230]都邀我观赏
[03:14.830]还真是大方
[03:19.430]快写一首情歌雅俗共赏
[03:22.790]落笔传神还要容易传唱
[03:26.240]上得厅堂也下得厨房
[03:29.690]就像我一直在找的姑娘
[03:33.290]有没有一种生活雅俗共赏
[03:36.690]情节起伏跌宕让人向往
[03:40.190]满纸荒唐中窥见满脸沧桑
[03:43.490]触到神经就要懂得鼓掌
[03:46.840]别说一不在乎二没期望
[03:50.300]太超脱 中枪中奖感觉会一样`;
export default lrc
main.js
import lrc from "./assets/data.js";
/**
* 将歌词字符 转换为对象的形式
* obj = {time:开始时间, words: 歌词内容}
*/
const parseLrc = () => {
// 准备好一个包含歌词对象的数组
const lrcData = [];
// 按照"]"字符进行分割
const lines = lrc.split('\n');
// console.log(lines);
// 生成一个数组,用来放置每一句歌词对象(包括时间,和 歌词)
// 循环遍历整个歌词数组
for (let i = 0; i < lines.length; i++) {
const item = lines[i].split(']')
// console.log(item);
const time = item[0].substring(1);
const words = item[1].substring(1);
const obj = {
time: parseTime(time),
words
}
lrcData.push(obj);
}
return lrcData
}
// 转换规则
// 00:39.32 ===> 0 + 39 + 0.32 = 39.32
// 01:02.86 ===> 60 + 2 + 0.86 = 62.86
const parseTime = (timeStr) => {
// 进行分割 按照:进行分割
const parts = timeStr.split(':');
return Number(parts[0]) * 60 + Number(parts[1])
}
const resulr = parseLrc()
// console.log(resulr);
// 页面绘制
// 获取dom
const doms = {
audio: document.querySelector('audio'),
box: document.querySelector('.box'),
ul: document.querySelector('.box ul')
}
const drawPage = () => {
// 创建元素片段
const frag = document.createDocumentFragment();
for (let i = 0; i < resulr.length; i++) {
// 创建li标签
const li = document.createElement('li');
// 设置li标签的文本内容
li.textContent = resulr[i].words;
frag.appendChild(li);
}
doms.ul.appendChild(frag);
}
drawPage()
// 找到当前歌词
const findIndex = () => {
// 播放器当前时间
const curTime = doms.audio.currentTime;
for (let i = 0; i < resulr.length; i++) {
if (curTime < resulr[i].time) {
return i - 1;
}
}
// 找遍了都没找到(说明播放到最后一句)
return lrcData.length - 1;
}
// 容器高度
var boxclientHeight = doms.box.clientHeight;
console.log("boxclientHeight", boxclientHeight);
// 每个 li 的高度
var liHeight = doms.ul.children[0].clientHeight;
console.log(liHeight); // 30
// 最大偏移量
var maxOffset = doms.ul.clientHeight - boxclientHeight;
// 最大偏移量 = ul的高度 - 容器高度
// 最大偏移量 = 2160 - 420 = 1740
console.log("最大偏移量", maxOffset);
// 高亮歌词 + 设置ul偏移量
const setOffset = () => {
let index = findIndex();
//
console.log(index);
// 30 * 1 + 15 = 45 - 210 = -165
let offset = liHeight * index + liHeight / 2 - 210;
console.log(offset);
if (offset < 0) {
offset = 0
}
if (offset > maxOffset) {
offset = maxOffset
}
doms.ul.style.transform = `translateY(-${offset}px)`;
console.log(doms.ul.style.transform);
// 去掉之前的active样式
let li = doms.ul.querySelector('.active');
if (li) {
li.classList.remove('active');
}
// 添加active样式
li = doms.ul.children[index];
if (li) {
li.classList.add('active');
}
}
doms.audio.addEventListener('timeupdate', setOffset);
到此就结束了, 主要难点在于计算ul的偏移量, 和 最大偏移量, 以及边界情况考虑. 不过,只要画好图,一分析,便会清晰明了许多.

















 2424
2424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









