







欢迎学习HBase
在大数据的采集、转换、存储、运算过程中,当数据量极大时关系型数据库的效率就显得略微的不足,因此,非关系型数据库的学习就从今天开始!HBase的版本为hbase-2.4.11-bin.tar.gz
环境准备
Hadoop:因为HBase的数据时存储在hdfs中的,所以我们需要先完成Hadoop的安装,安装教程链接
Zookeeper:HBase的集群管理以及元数据存储在zookeeper中,因此我们需要完成Zookeeper的安装,安装教程链接
资源下载
下载地址:网盘链接
提取码:1111
HBase安装部署
- 集群部署
| bigdata01 | bigdata02 | bigdata03 |
|---|---|---|
| NameNode | SecondaryNameNode | |
| DataNode | DataNode | DataNode |
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| HMaster | Backup-HMaster | |
| HRegionServer | HRegionServer | HRegionServer |
-
上传资源到集群中的一台节点,我这里是bigdata01

-
解压安装包并配置环境变量
[root@bigdata01 soft]# tar -zvxf hbase-2.4.11-bin.tar.gz -C /opt/module/[root@bigdata01 /]# vim /etc/profile #hbase export HBASE_HOME=/opt/module/hbase-2.4.11 export PATH=$PATH:$HBASE_HOME/bin让环境变量生效
source /etc/profile -
对HBase进行配置
-
配置hbase-env.sh,配置JAVA_HOME、HBASE_CLASSPATH、 HBASE_MANAGES_ZK
export JAVA_HOME=/opt/module/jdk export HBASE_CLASSPATH=/opt/module/hadoop-2.7.3/etc/hadoop export HBASE_MANAGES_ZK=false -
配置hbase-site.xml
<!--指定是否是分布式--> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!--指定hbase中的数据在hdfs上的存储路径--> <property> <name>hbase.rootdir</name> <value>hdfs://bigdata01:9000/hbase</value> </property> <!-- 指定zookeeper集群地址 --> <property> <name>hbase.zookeeper.quorum</name> <value>bigdata01,bigdata02,bigdata03:2181</value> </property> <!-- 指定master的Web端口号--> <property> <name>hbase.master.info.port</name> <value>60010</value> </property> <!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 --> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> -
配置regionservers
bigdata01 bigdata02 bigdata03 -
创建文件backup-masters,并写入集群需要设置为backup-Master的主机名
[root@bigdata01 conf]# vimbackup-masters bigdata03 -
将bigdata01中的HBase分发到其他节点
[root@bigdata01 module]# scp -r /opt/module/hbase-2.4.11/ bigdata02:/opt/module/ [root@bigdata01 module]# scp -r /opt/module/hbase-2.4.11/ bigdata03:/opt/module/ -
分别在三台节点启动Zookeeper
[root@bigdata01 /]# /opt/module/zookeeper-3.5.7/bin/zkServer.sh start [root@bigdata02 /]# /opt/module/zookeeper-3.5.7/bin/zkServer.sh start [root@bigdata03 /]# /opt/module/zookeeper-3.5.7/bin/zkServer.sh start -
启动hdfs
在bigdata01启动[root@bigdata01 /]# start-dfs.sh -
启动HBase
启HBase有两种方式,- 第一种: 单独启动
<!--先在bigdata01启动master--> [root@bigdata01 /]# /opt/module/hbase-2.4.11/bin/hbase-daemon.sh start master <!--再在三个节点分别启动regionserver--> [root@bigdata01 /]# /opt/module/hbase-2.4.11/bin/hbase-daemon.sh start regionserver [root@bigdata02 ~]# /opt/module/hbase-2.4.11/bin/hbase-daemon.sh start regionserver [root@bigdata03 ~]# /opt/module/hbase-2.4.11/bin/hbase-daemon.sh start regionserver <!--最后,在bigdata03启动master作为高可用--> [root@bigdata03 /]# /opt/module/hbase-2.4.11/bin/hbase-daemon.sh start master - 第二种:使用start-hbase.sh启动
此方法启动,在那台节点启动,HMaster就在那台节点,因此我们尽量在bigdata01和bigdata02上进行启动
- 第一种: 单独启动
-
启动成功验证
1.进程验证- bigdata01进程
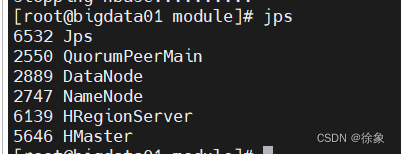
- bigdata02进程
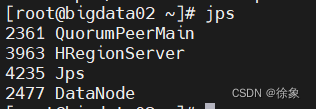
- bigdata03进程

- Web端查看

- bigdata01进程
-
测试
-
启动hbase shell
[root@bigdata03 ~]# /opt/module/hbase-2.4.11/bin/hbase shell
-
查看当前的namespace有哪些
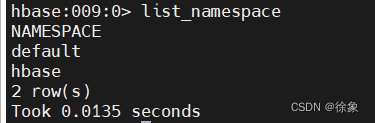
hbase:主要存储hbase的系统信息
default:是用户使用的 -
创建一个namespace
hbase:010:0> create_namespace 'bigdata'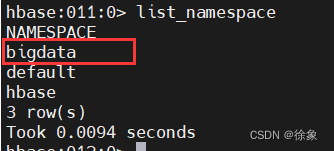
-
在自己创建的namespace中创建一张表
hbase:001:0> create 'bigdata:student',{NAME => 'info',VERSIONS => 5},{NAME=>'msg'} -
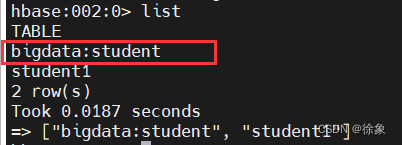
查看有哪些表:list
HBase高可用的安装部署就全部完成了,希望对你有用!!,关注我,以后不迷路!!
















 559
559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











