










常见缓存使用方式
项目中引入缓存一般是为了应对高频访问且不常修改的数据的查询,防止大量的请求进入数据库,导致其他数据操作的延迟。那么,保证缓存和数据库中的数据一致性则是缓存有效的必要前提。
在实际的软件开发过程中,缓存使用的方式最多的就是:缓存+数据库读写,即Cache Aside Pattern。
Cache Aside Pattern
读取数据时,先读缓存,缓存没有,再查询数据库,将查出来的值存入缓存中;
更新数据的时候,先更新数据库,然后再删除缓存。
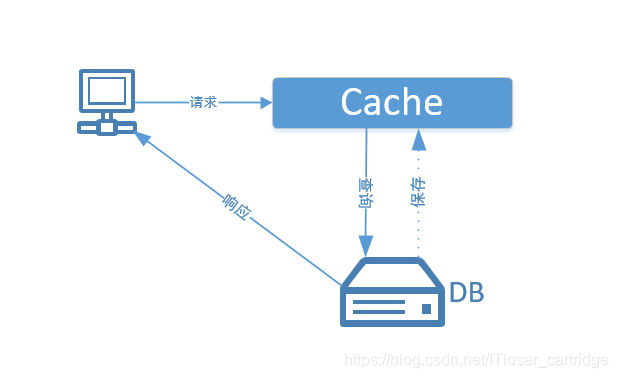
Cache Aside Pattern模式的问题
在上文对Cache Aside Pattern模式的介绍中可以看到,当有数据需要更新时,是先更新数据库,然后再删除缓存。如果在此过程中,更新数据库操作成功了,但是删除缓存失败,将会导致“缓存-数据库”数据的不一致性,缓存中的旧数据无法刷新。
方案二
为解决上述的Cache Aside Pattern模式存在的问题,我们可以对Cache Aside Pattern模式的数据保存方案进行一定的修改,我们将删除缓存操作提前,即当有数据需要更新时,优先删除缓存,再更新数据库。
方案二的问题
那么,修改后的Cache Aside Pattern模式是否能在正常的生产业务场景下保证“缓存-数据库”的数据一致性呢?
现在设想一中业务场景:在多用户访问的工作模式下,一个更新数据的请求已经将其对应的缓存删除,在更新数据库对应的数据时被阻塞;此时,另一个查询该数据的请求进入了业务系统,缓存中无法命中数据,则直接查询数据库,得到数据库中尚未修改的旧数据,并将旧数据存入缓存;原先被阻塞的更新数据库操作重新进行。此时,缓存中保存着旧数据,导致“缓存-数据库”数据的不一致。(注:其实这种场景很难发生,如果第一个请求已经进入数据库,则会获得对应数据的锁,第二个查询的请求将会被阻塞;如果请求一尚未进入数据库便已阻塞,则设想的场景就有可能出现)
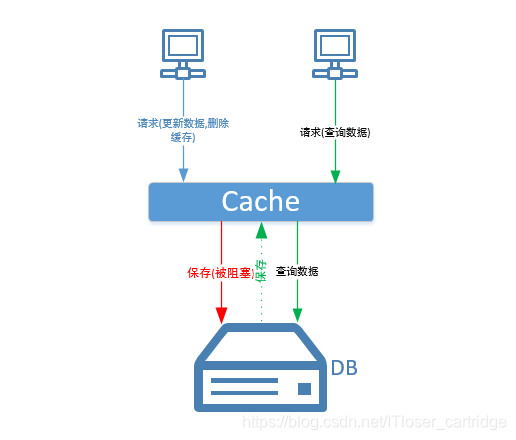
方案三
在一般的开发过程中,我们在多线程场景下保证数据准确的方案是对代码或者数据加锁,将一个多线程的操作转变成单线程来处理。同理,方案二的中的两个请求分属两个业务代码,无法通过单纯的加锁来解决,但是任然可以将这两个请求转变为单线程的方式一个一个处理。
我们引入一个请求队列,需要更新数据时,将“删除缓存+更新数据库”两步操作一起放入请求队列中;当有新的查询请求进来时,如果无法在缓存中命中,则将“查询数据库+更新缓存”两步操作一起放入原先的队列中;然后由一个线程去消费这个请求队列,此时即可保证多个线程的数据操作转变成单线程操作。此时便能保证(缓存-数据库)数据的强一致性
方案三的优化空间
多个对相同数据的“查询数据库+更新缓存”的操作没有任何意义,只需放入一个相关的操作即可,可以使用数据+操作的唯一标识实现;
方案三的弊端
- 如果有大量的更新操作积压在队列中,此时一个查询请求进入队列,则该请求很可能会超时;
- 单线程的消费能力有限,队列可能会积压大量的请求时,会导致服务无法正常工作。
总结
上述三种缓存的使用方案都各有利弊,其实一个系统并非只能采取一种方案,我们可以根据业务需求的不同采用不同的方案,比如:
- 记录一些用户信息这类不容易修改且对数据准确性要求并不是那么高的情况,采用Cache Aside Pattern模式的方案就可以完全胜任了,通过设置过期时间的方式,可以有效地处理掉缓存中的旧数据;
- 如果是一些金融报表、财务报表之类的数据,这些数据对准确性要求比较高,但是查询的并发量并不会很大,则可以采用方案二的模式;
- 如果是其他的对数据准确性要求比较高,且查询并发量很大的数据,则可以采用方案三的模式。但是方案三可能会带来服务队列消息积压等问题,需要慎重。
对比方案二和方案三,我个人其实更倾向与方案二的模式。由于数据库锁的存在,方案二要出现设想中的问题其实比想象中的要困难得多;相反比较方案三中,由于引入了队列处理方式,相对应的就可能会出现一系列队列可能出现得问题,需要额外花费精力去解决,最后可能得不偿失。














 8146
8146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









