







DBA
该算法是用来求序列数据集
S
的一致序列(平均序列)。由Franc-ois Petitjean提出的。目前,该方法求得的平均序列是最准确的。
假设一元组为
avg=s1+s2+⋯+snn(1)
如果 S 的元素为序列的时,如
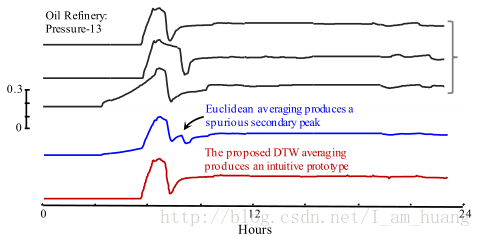
上图是对前三个序列求平均序列,采用传统的方法(上面的公式(1))求得的第四个序列出现原序列不存在的峰点,显然我们希望得到的平均序列是最下面的序列。为什么式(1)求得的平均序列会出现不存在的模式?主要是因为(1)是分别对序列对应位置上的点值求平均(点对点匹配),但是,在时间序列相似性度量我们知道点对点匹配求得的相似性容易受到序列的移位、错位等影响。同时我们了解动态时间规划(DTW)的思想很容易处理这种情况。举个例子:

上图是欧式距离的思想,点对点匹配。下图是DTW思想,序列的一个点对应另一个序列的一个或多个点。
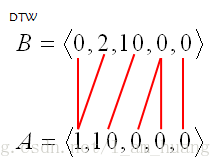
可以换一个角度理解DTW算法,就是求序列 B 和序列
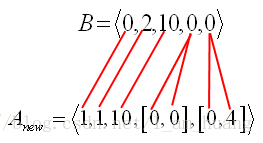
序列 Anew 可以包含子序列,序列 B 和序列
好了,接下来开始谈谈DBA的思想,DBA是通过求下式来获得平均序列
argmin∑i=1NDTW2(X,Ti)(2)
不幸的是,式(2)不能通过传统求极值的方法求解。并且该优化问题被认为式一个NP-Hard问题,可以采用启发式迭代算法逼近真实值。DBA就是求解式(2)的一种方法,是一种迭代算法。同样用一个例子来阐述DBA的求解步骤(展示一次迭代步骤),假设求序列 A={1,10,0,0,4} 、序列 B={0,2,10,0,0} 和序列 C={0,0,0,10,0} 的平均序列 T¯ :
第一次迭代(假设序列B为初始平均序列):
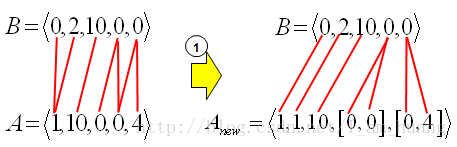
将DTW算法转化维欧式距离方法,求得新的序列 Anew 。

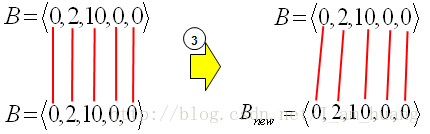
求得新的序列 Bnew 。
求得新的序列 Cnew 。
令 M={[1,0,0],[1,[0,0],2],[10,10,10],[[0,0],0,0][[0,4],0,0]} ,表示新序列集。接下来可以求得的新时间序列求平均:
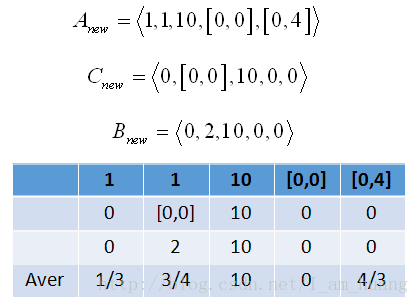
求得 T¯={13,34,10,0,43} ,第二次迭代令 T¯ 为平均序列重复上面的步骤,指导满足条件。
这里可能有人会问,这样求得的平均序列能不能保证式(2)是收敛的?可以根据定义证明:令 T={T1,T2,⋯,Tn} 是一个序列集, Tk¯ 是第 k 次迭代的平均序列。有:
因为 min∑Ni=1DTW2(X,Ti)=DTW2(T¯,Ti) 。所以可以保证算法的收敛性。接下来的问题是如何求得 T¯ ?首先先将DTW转化成欧式表达式:
∑i=1NDTW2(X,Ti)=∑e∈M(l)∑l=1L(X(l)−e)
其中, M(l) 是新序列集合 M 的第
所以, T¯==1|M(l)|∙∑e∈M(l)(e) 。
总结:求平均序列对于一些算法是非常重要的,如K-mean算法在每次迭代时都需要求某一序列集的平均讯列,采用DBA算法可以获得更为准确的平均序列,提高K-mean性能。更深入了解关DBA算法还是需要阅读期刊文献,下面这几篇文献可能有所帮助。真篇博文是我自己对DBA算法的理解,希望能提供一点帮助。
[1]: Petitjean F, Forestier G, Webb G I, et al. Dynamic Time Warping Averaging of Time Series Allows Faster and More Accurate Classification[C]// IEEE International Conference on Data Mining. IEEE, 2015:470-479.
[2]: Petitjean, Fran, ois, et al. A global averaging method for dynamic time warping, with applications to clustering[J]. Pattern Recognition, 2011, 44(3):678-693.
[3]: Petitjean F, Gançarski P. Summarizing a set of time series by averaging: From Steiner sequence to compact multiple alignment[J]. Theoretical Computer Science, 2012, 414(1):76-91.
代码下载(matlab和java):
[4]: > https://zenodo.org/record/10432#.WZZ3TDX_5K8














 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









