







1.摘要
MVS和立体匹配方法通常构造3D成本体积以正则化和回归深度或视差,但是这些方法会受到高分辨率输出的限制。因为随着体积分辨率的增加,内存和时间成本呈立方增长。此论文提出一种内存和时间高效的成本体积公式,以补充现有的基于3D成本体积的多视点立体和立体匹配方法。
首先,提出的成本量建立在特征金字塔上,以逐渐精细的尺度编码几何结构和上下文。然后,可以通过前一阶段的预测缩小每个阶段的深度(或视差)范围。随着成本体积分辨率的逐渐提高和深度(或视差)间隔的自适应调整,以从粗到精的方式恢复输出。应用于代表性的MVS网络,比DTU基准(第一名)提高了35.6%,GPU内存和运行时间分别减少了50.6%和59.3%。
源码在https://github.com/alibaba/cascade-stereo。
2.导言
现有技术的多视图立体和立体匹配算法通常根据一组假设深度(或视差)和扭曲特征来计算3D成本体积。将3D卷积应用于该成本体积以正则化和回归最终场景深度(或视差)。3D成本体积的方法通常限于低分辨率输入图像(和结果),因为3D CNN通常耗费时间和GPU内存。通常,这些方法对特征图进行下采样,以在较低分辨率下形成成本体积,并采用上采样或后细化来输出最终高分辨率结果。
作者提出一种新的三维成本体积级联公式。从特征金字塔提取多尺度特征用于标准多视图立体和立体匹配网络。从粗到细,早期阶段的成本体积建立在具有稀疏采样深度假设的较大尺度语义2D特征上,这使得体积分辨率较低。后阶段,使用来自前阶段的估计深度或视差来自适应调整深度或视差假设的采样范围,使得语义特征更精细。
如图:

典型的立体匹配算法包含四个步骤:匹配成本计算、匹配成本聚合、视差计算和视差细化。局部方法将匹配成本与相邻像素进行聚合,并通常使用赢家通吃策略来选择最佳视差。全局方法构造一个能量函数,并试图最小化它以找到最佳视差。
3.方法论
使用代表性的MVSNet和PSMNet作为骨干网络,分别演示级联成本体积在多视图立体和立体匹配任务中的应用。
如图:

成本-体积公式(Cost volume Formulation)
构建3D成本体积需要多视图立体和立体匹配中的三个主要步骤:
1.确定离散假设深度或视差平面
2.将提取的每个视图的2D特征映射到假设平面,并构建特征体
3.将这些特征体融合在一起以构建3D成本体
pixel-wise构建cost是不稳定的,在遮挡、重复纹理、低纹理、反射等区域都不好 → 3D CNNs at multiple scales可以用来聚集上下文信息,使得正则化时更鲁棒
【MVS中的3D成本体积】
MVSNet[52]建议使用不同深度的前向平行平面作为假设平面,深度范围通常由稀疏重建确定。坐标映射由单应性确定:
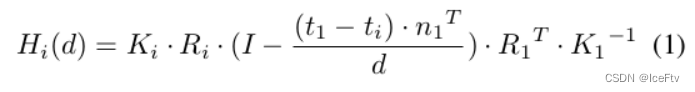
通过单应变换将2D feature map投影到ref视点的假设平面上,构建feature volume
最终通过方差将每个视点的特征体聚合成一个cost volume
【SM中的3D成本体积】
立体匹配PSMNet[3]中的3D成本体积使用视差水平作为假设平面,视差范围根据特定场景设计。由于左图像和右图像已被校正,坐标映射由x轴方向上的偏移确定:
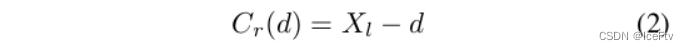
由于左右视点都被矫正过,因此只是一个x轴的平移(相当于MVS中的投影变换,只是变得很简单)
之后通过类似方法进行聚合,不过方法有
直接聚集,不进行特征降维
sum of absolute differences
计算左右相关性,product only a single-channel correlation map for each disparity level
group-wise correlation
级联成本量
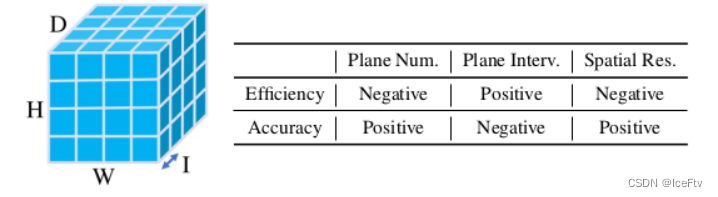
图3:左:标准成本量。D是假设平面的数量,W×H是空间分辨率,I是平面间隔。右:影响效率(运行时间和GPU内存)和准确性的因素。
【深度假设范围】
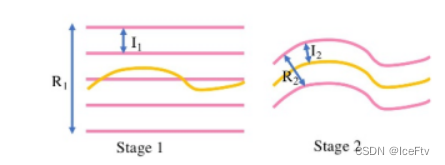
图4:假设平面生成示意图。Rk和Ik分别是第k阶段的假设范围和假设平面数。粉红线是假设平面。黄线表示第1阶段的预测深度(或视差)图,用于确定第2阶段的假设范围和假设平面间隔。
在接下来的阶段中,我们可以基于前一阶段的预测输出,缩小假设范围。因此,得到Rk+1=Rk·Wk,其中Rk是第k阶段的假设范围,Wk<1是假设范围的缩减因子。
【深度假设平面数】
假设平面的对应数量dk由以下等式确定:dk=Rk/Ik。
基于级联公式,可以有效地减少假设平面的总数,因为假设范围逐步显著减少,同时仍然覆盖整个输出范围。
【空间分辨率】
在每个阶段将成本体积的空间分辨率加倍,同时将输入特征图的分辨率加倍。
每一步空间分辨率翻倍 1/4 → 1/2 → 1
【Warping Operation】
将级联成本体积公式应用于多视图立体,基于等式1,并将第(k+1)阶段的单应性扭曲函数重写为:
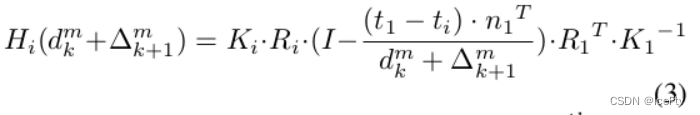
其中,dmk表示第k级的第m个像素的预测深度,以及∆m k+1是要在第k+1级学习的第m个像素的剩余深度。
类似地,在立体匹配中,我们基于级联成本体积重新计算公式2。第k+1级的第m个像素坐标映射表示为:
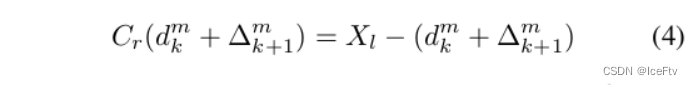
其中dMk像素表示第k级的第m个像素的预测视差,以及∆ m k+1表示要在第k+1级学习的第m个像素的残余视差。
特征金字塔
为了获得高分辨率深度(或视差)图,以前的工作通常使用标准成本体积生成相对较低分辨率的深度(或差异)图,然后使用2D CNN对其进行上采样和细化。标准成本量是使用顶层特征图构建的,顶层特征图包含高级语义特征,但缺乏低级精细表示。
从特征金字塔网络的特征映射构建三个成本体积。它们对应的空间分辨率是输入图像大小的{1/16,1/4,1}。
损失函数
和原来一样L1,只是在不同的stage计算的loss给上不同的参数加权起来。
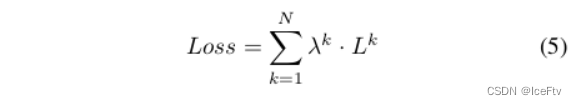
4.实验
【阶段数】
overall质量先显著增加,后平稳,最终选择的是3阶段模型
深度假设数:96,48,48
深度间隔:2,2,1
cascade?:将原始固定的代价体替换为三阶段的代价体
upsample?:对特征图插值,以增加代价体的空间分辨率
feature pyramid?:通过特征图金字塔增加代价体分辨率
空间分辨率的提高对重建结果的影响大
级联代价体不同阶段分别学习效果更好(不进行参数共享)
参考链接:
https://blog.csdn.net/double_ZZZ/article/details/122611004
https://blog.csdn.net/weixin_43537073/article/details/124386841


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









