







注意这里都是针对你谷的。
你谷的评测结果一堆,但是最常见的就这么几种:
AC,WA,RE,CE,TLE,MLE
其中 CE 的话咱也没办法,如果是高精的题目而你又用了 __int128 的话那么你就要注意你是用的什么语言评测,目前 C++17 是支持 __int128 的,但剩下的本人并没有亲测,大家可以试验一下(注意需要用万能头)。剩下的 CE 就说明你的代码有本质问题无法编译成功了,当然也有可能是编译器卡住,不过几率很少。
AC是最好的情况,如果是正解的话不需要优化。
那么剩下的 WA,RE,TLE,MLE 所出现的问题,就都有可能是你没有优化的结果了(WA,RE 也有可能是取余写错位置、或者算法结构本身有问题、调试的代码没删除、少写了一句特判、数组开的不够、使用 unsigned long long 过多等等,我们这里只讲因为没有优化而错误的 WA 和 RE)。
接下来我们就来了解了解优化代码的几种方法吧!
1.const
在C++中,要定义常量,可以用到 #define 和 const,然鹅,#define 非常消耗内存,时间也较慢。所以以后尽量使用 const 吧!
为了让大家信服这一结论,我们来看看实际效果。
首先,我们写一个用 #define 定义的常量,并输出,代码如下:
#include<bits/stdc++.h>
#define inf 0x7fffffff
//const int inf=0x7fffffff;
using namespace std;
int main(){
cout<<inf;
return 0;
}我们编译后输出。
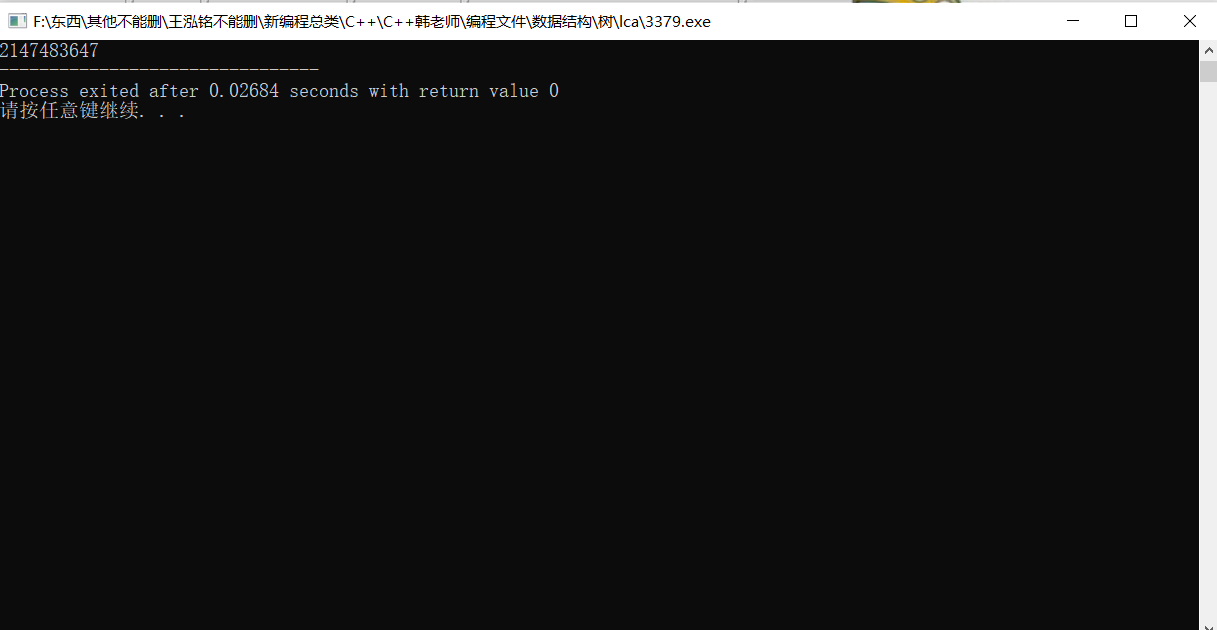
用时 0.02684 秒。
我们接下来改用 const 定义。
#include<bits/stdc++.h>
//#define inf 0x7fffffff
const int inf=0x7fffffff;
using namespace std;
int main(){
cout<<inf;
return 0;
}继续编译后输出。
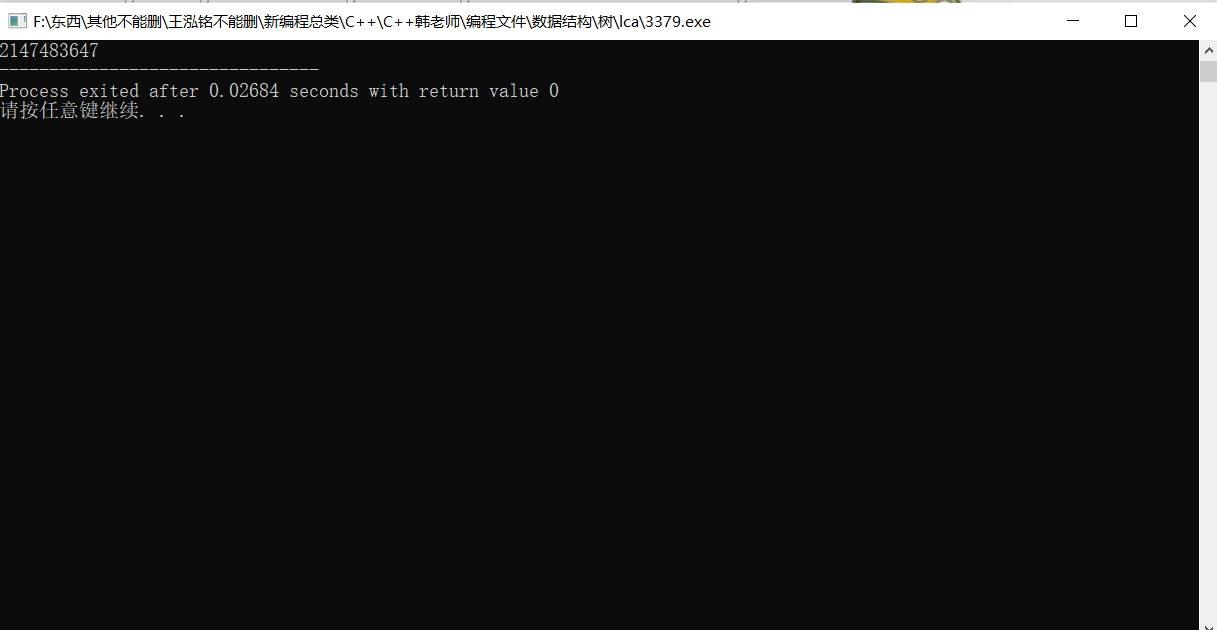
用时 0.02061 秒。
相差 6.23 毫秒。
虽然看着这样差的较少,可是当常量变多或者与其他优化方法连用,const 的优点就会变得更加明显了。
此外,const 还可以在友元中使用,它可以减少参数传递的时间。
2.链表和数组
二叉树问题有时候确实要用到链表,可是大部分时候用结构体或者数组也可以!
无论是几维数组,它们都是连续内存。连续内存的话我们只需要寻址一次,就可以找到整个数组在内存当中的位置。但是链表不是连续内存,所以每次查找电脑需要反复寻址,这样效率十分低下。
举个例子,最短路中,除了Floyd可以使用二维数组之外,剩下的我们都可以用vector存边、链式前向星、邻接表这三种方法解决存图问题。理论来说,vector存边是最快的(注意是理论来说),因为vector本质上是一个数组,而链式前向星和邻接表本质是链表,所以理论时间复杂度较慢。
3.指针
指针找的是地址,变量查找的时候要先变成指针,所以说实话,指针较快。
虽然使用指针比较麻烦,普通时候可以用变量,但有时候不是都必须用变量的!
比如:传参。
特别是传参传数组的时候,一定不要这么写!
void f(int dis[]){
//......
} 由于数组是用连续内存的,你不需要给他个数组,这样传数组是要耗费许多时间和空间的!!!
所以,你只需要把指针给他就好啦!
void f(int *dis){
//......
} 4.快读
快读也是非常好的加速措施,主要使用了c++最快的读入方法getchar(),把加减乘除的过程改成了位运算,非常好理解。
int read(){
int x=0,f=1;
char c=getchar();
while(c<'0'||c>'9'){
if(c=='-')f=-1;
c=getchar();
}
while(c>='0'&&c<='9'){
x=(x<<3)+(x<<1)+(c^48);
c=getchar();
}
return x*f;
}如果你要进行输出优化的话,也比较方便,我们需要用到putchar(),这里就不展示代码了。
在这里还有几条关于输入输出的温馨提示。
如果你使用cin,cout,可以适当使用 ios::sync_with_stdio(0),但是考场上不建议用加速器,因为容易输入的时候落下字符,请不要冒险。
更禁忌的是,请不要cin,cout和scanf,printf混用,容易造成事故!
5.inline
注意,是 inline,不是 online。
inline 可以让你的函数(非递归)在原来的函数中编译,也就是说,他不会开多余的内存。
例如一段快读代码,加上 inline 后,变成了:
#include<bits/stdc++.h>
using namespace std;
inline int read(){
int x=0,f=1;
char c=getchar();
while(c<'0'||c>'9'){
if(c=='-')f=-1;
c=getchar();
}
while(c>='0'&&c<='9'){
x=(x<<3)+(x<<1)+(c^48);
c=getchar();
}
return x*f;
}
int main(){
int r=read();
return 0;
}此时编译运行的话,实际上编译器运行的代码变成了:
#include<bits/stdc++.h>
using namespace std;
int main(){
int r,x=0,f=1;
char c=getchar();
while(c<'0'||c>'9'){
if(c=='-')f=-1;
c=getchar();
}
while(c>='0'&&c<='9'){
x=(x<<3)+(x<<1)+(c^48);
c=getchar();
}
r=x*f;
return 0;
} 这样一份快读,既节省了时间,又节省了空间,代码量也没有增加,实用方便。
又及:以后能写在主函数里的就不要写在外面!
6.递归
在用广搜和深搜都能解决的题目中,尽量用广搜,不要额外开栈!
在dp当中,有时候也能写记忆化,但记忆化是基于搜索的,所以能用dp不要用记忆化!
其他函数例如 gcd,能用循环不要用递归!
将可能改为循环解决的递归改成循环,会让整个代码可行性高,可读性有时候也会增强,能造成明显的空间优化。
7.斐波那契数列
斐波那契数列是可以用递归解决的, 如下。
#include<bits/stdc++.h>
using namespace std;
int ans,n;
int f(int x){
if(x==1||x==2)return 1;
else return f(x-1)+f(x-2);
}
int main(){
cin>>n;
ans=f(n);
cout<<ans;
return 0;
}但是递归需要额外开栈,所以我们想到了用数组递推。
#include<bits/stdc++.h>
using namespace std;
int n,a[1001]={0,1,1};
int main(){
cin>>n;
for(int i=3;i<=n;i++)a[i]=a[i-1]+a[i-2];
cout<<a[n];
return 0;
}这样一来确实剩下了不少栈空间,但我们又需要用数组,算下来其实空间没大怎么减少,而且如果输入的 $n$ 很小的话,第二种方法所占用的内存甚至可能比递归所占用的还要多。
回头想一想,其实我们完全可以只用变量解决,可以完美地把递归和一代递推的弊端去除,解决问题。
#include<bits/stdc++.h>
using namespace std;
int n,a=1,b=1,c;
int main(){
cin>>n;
for(int i=3;i<=n;i++){
c=a+b;
a=b;
b=c;
}
cout<<b;
return 0;
}8.声明变量
每次定义变量计算机将会在内存条找出一块空地址存储数据,但蓝皮书上明显画出内存条和CPU距离很长,为了不让你的CPU被烧,请将变量声明在循环外,让你的CPU把 n 次操作改为 1 次操作。
比如说迭代 gcd,请不要这么写:
inline int gcd(int a,int b){
while(b){
int c=a;
a=b;
b=c%b;
}
//...
}这样每次定义变量 c 的时候CPU都会回去找内存条,再想想你(wo)那个总是坏掉的主板,请珍惜资源,改成这么写:
inline int gcd(int a,int b){
int c;
while(b){
c=a;
a=b;
b=c%b;
}
//...
}9.register
第八条中说过,定义变量的时候CPU需要找内存条,但内存条对于CPU来说比较长,交互的速度会比较慢。
但是蓝皮书里还说过,CPU有一半是缓存。如果你让你的CPU傻傻的去跑内存条,就相当于你自己带着龙虾鲍鱼却还要不远万里跑去啃猪骨头(非常牵强的比喻),所以我们直接用 register 把变量开在CPU里就好了。
所以我们把第七条里讲过的斐波那契递推二代加个 register:
for(register int i=3;i<=n;i++){
c=a+b;
a=b;
b=c;
}会比原来快十倍。
然鹅在某些需要开很多大型变量的时候,请不要过多使用 register,这是由于CPU缓存比内存条小得多,只有开几个变量的空间。
如果你没有过多使用 register 并且本地测试通过然而在提交你谷评测的时候依然卡崩,有可能是因为服务器CPU肝爆了,缓存部分被其他人提交的 register 占满了,导致CPU去找内存条,又回到起点了。
10.三目运算符
在递归状态(如并查集 find 函数)下 1e5 数据规模会带来 100ms 的速度提升。
比如输出YES,NO的代码 ,我们可能会这么写:
if(a==b)cout<<"YES";
else cout<<"NO";这份代码已经很好了,但三目运算符除了速度,还可以节省代码量。
cout<<(a==b?"YES":"NO");//输出三目运算符的话别忘了加括号!11.i++和++i
i++是先执行后加,++i是先加后执行,但是对于类似for循环这种对i++和++i的本质不做要求的代码,尽量使用i++,因为i++更快。
12.STL
STL虽然很好用,但是却很慢,不仅因为要离开编译器到文件库查找,还因为STL本身有许多防止出错的检查项,拉低一些速度。但是STL由于是非常先进的库,里面的函数算法都是该函数时间的极限最小可能,极其优秀。比如sort函数,时间复杂度为 O(nlogn),速度极为迅速,且占用空间不大,相比于占用空间极大的 O(n) 的桶排序,STL将快速排序和桶排序的优缺点削除,创造出了空间和时间都最少的排序算法。再比如,对于LCA的倍增方法,我们需要求对数来完成倍增过程,如果你自己写二分法的话,复杂度为 log 级别,但STL非常厉害,是用牛顿迭代求对数,时间复杂度几乎为 O(1),非常迅速,且不用写复杂的二分,只需要调用STL自带函数log2()就可以了,节省代码量,这种情况完全可以选择效率较高的STL。
当然有时候STL效率较低,比如vector容器常数很大,影响了速度,如果使用不当,会对程序造成性能上的明显负面影响,所以我在第二条的时候说过vector存边只是理论上速度快,实际上由于vector容器的效率比较低,vector存边的理论速度和STL的低下效率折中之后与链式前向星和邻接表的速度其实差不了多少。
所以在使用STL的时候一定要正确使用,不要胡乱一通。
广告模块:下期预告
下期我们依然要从代码优化方面入手,下一期我们主要会为大家讲解包括但不限于多重背包的二进制优化、快速幂、位运算、状压dp、倍增优化、二分这些和二进制息息相关的优化方案。
还有,欢迎大家关注我的你谷账号,博客园账号,有洛谷账号的朋友也欢迎加入我的你谷团队哦!
By ImNot6Dora
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









