






目录
一、一维数组的创建和初始化
1.1数组的创建
数组是一组元素的集合。
数组的创建方式:
type_t arr_name [const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小实例:
//代码1
int arr1[10];
//代码2
int n=10;
int arr2[n];//数组是否可以正常创建
很明显代码2中[]中是一个变量。
注:数组创建,在C99标准之前, [] 中要给一个常量才可以,不能使用变量。在C99标准支持了变长数 组的概念,数组的大小可以使用变量指定,但是数组不能初始化。
1.2数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。
实例:
int main()
{
//创建的同时给数组一些值,这叫初始化
int arr1[5] = { 1,2,3,4,5 };//完全初始化
int arr2[5] = { 1,2,3 };//不完全初始化,剩余元素默认初始化为0
int arr3[] = { 1,2,3,4,5 };
//数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确定
return 0;
}数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确定。
但是对于下面代码要注意区分:
char arr1[]="abc";//其中这个数组最后还有\0的元素
char arr2[]={'a','b','c'}
要注意的是第一个数组末尾还有\0这个元素
1.3一维数组的使用
数组是有下标的,下标是从0开始的。 对于数组的使用我们之前介绍了一个操作符:[ ],下标引用操作符。它其实就数组访问的操作符。 我们来看代码:
//按顺序打印数组
#include<stdio.h>
int main()
{
//创建数组
int arr[5] = {0};//数组的不完全初始化
//计算数组的元素个数
int sz = sizeof(arr) / sizeof(arr[0]);//用数组元素的总字节长度除以首元素的字节长度
//输入 - 数组下标是使用下标来访问的,下标从0开始。所以
int i = 0;//作为下标
for (i = 0; i < sz; i++)
{
scanf("%d", &arr[i]);
}
//输出数组的内容
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}结合上面的代码我们可以看出:
- 数组是使用下标来访问的,下标是从0开始的.
- 数组的大小可以通过计算得到
int arr[5] = {0};//数组的不完全初始化
//计算数组的元素个数
int sz = sizeof(arr) / sizeof(arr[0]);//用数组元素的总字节长度除以首元素的字节长度1.4一维数组在内存中的存储
我们要研究一维数组在内存中的存储,我们可以先来观察,数组中的元素在内存中是怎么存放的。
#include<stdio.h>
int main()
{
int arr[10] = { 0 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0;
}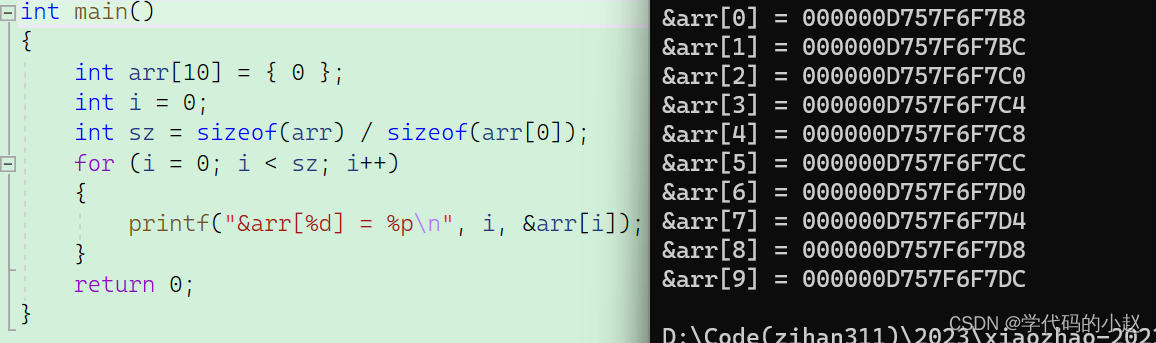
我们仔细观察数组中每个元素的存放,可以看出,随着数组下标的增长,元素的地址也在有规律的递增,由此可以得出结论:数组在内存中是连续存放的。
二、二维数组的创建和初始化
2.1二维数组的创建
数组的创建
int arr1[行][列];
int arr2[3][3];
char arr3[3][3]2.2二维数组的初始化
数组的初始化
int arr[2][2]={1,2,3,4};
int arr[2][2]={{1,2},{3,4}};
int arr[][2]={{1,2},{3,4};注:二维数组初始化,行可以省略,列不能省略。
2.3二维数组的使用
二维数组的使用也是通过下标的方式
代码:
#include<stdio.h>
int main()
{
int arr[2][2] = { 0 };
int row = 0;
for (row = 0; row < 2; row++)
{
int col = 0;
for (col = 0; col < 2; col++)
{
scanf("%d", &arr[row][col]);
}
}
for (row = 0; row < 2; row++)
{
int col = 0;
for (col = 0; col < 2; col++)
{
printf("%d", &arr[row][col]);
}
}
return 0;
}2.4二维数组在内存中的存储
我们尝试使用上面的方法来打印二维数组的每个元素。
#include<stdio.h>
int main()
{
int arr[3][4];
int row= 0;
for (row = 0; row < 3; row++)
{
int col = 0;
for (col = 0; col < 4; col++)
{
printf("&arr[%d][%d] = %p\n", row, col, &arr[row][col]);
}
}
return 0;
}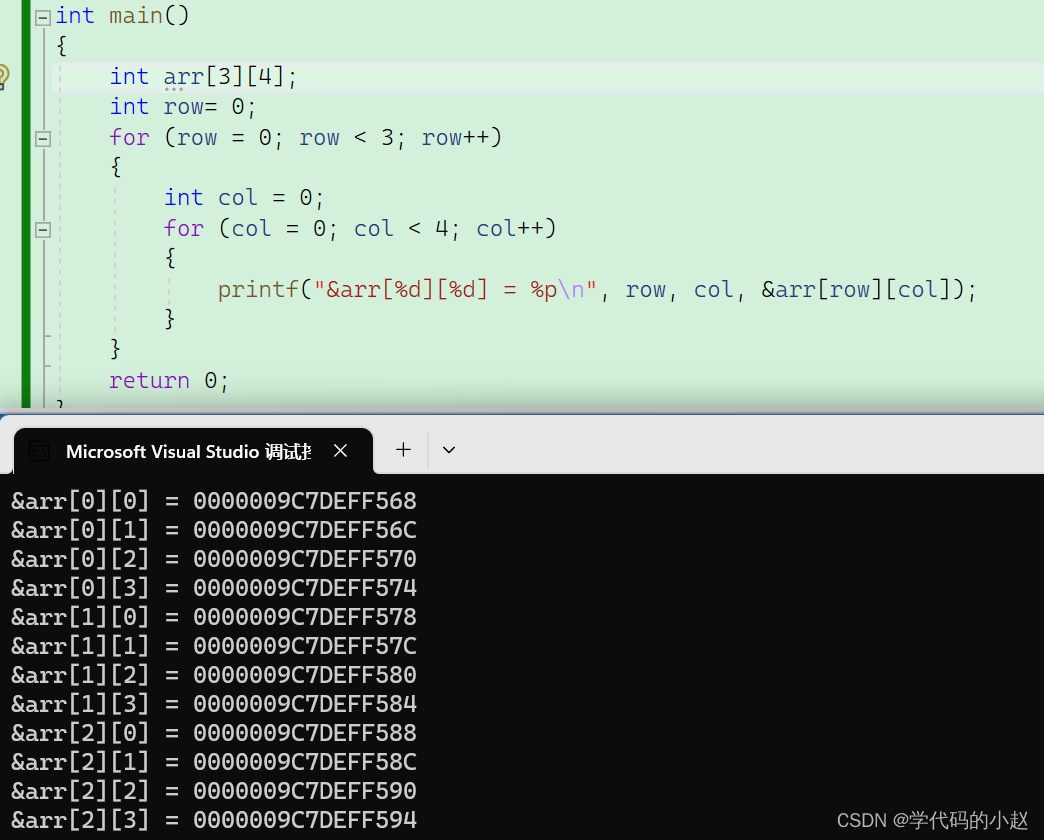
通过结果我们不难看出,二维数组和一维数组相同在内存中也是连续存储的。
三、数组越界
数组的下标是有范围限制的。数组的下标规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1.所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出数组合法空间的访问。这类错误也是C语言程序中最常见的错误之一。在C语言中,数组必须是静态的,数组的大小必须是程序运行前就确定下来的。由于C语言并不具有类似Java等语言中现有的静态分析工具的功能,可以对程序中数组下标取值范围进行严查,一旦发现数组上溢或下溢,都会因抛出异常而终止程序。也就是说,C语言并不检验数组边界,数组的两端都有可能越界,从而是其他变量的数据甚至程序代码被破坏。因此数组下标的取值范围只能预先推断一个值来确定数组的维数,而检验数组的边界是程序员的责任。所以程序员写代码时,最好自己做越界的检查。
要避免数组越界,除了上面所阐述的显示指定数组的边界之外,还可以在数组使用之前进行越界检查,检查数组的界限和字符串(也是数组的方式存放)的结束,以保证数组索引值位于合法的范围之内。
四、数组作为函数参数
首先我们要明白 数组名是什么?
我们来通过一段代码观察一下。
#include <stdio.h>
int main()
{
int arr[5] = {1,2,3,4,5};
printf("%p\n", arr);
printf("%p\n", &arr[0]);
printf("%d\n", *arr);
//输出结果
return 0;
}
我们可以看出arr和arr[0]的地址是一样的,所以我们得出结论:
数组名是数组首元素的地址。
补充:
- sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数 组。
- &数组名,取出的是数组的地址。&数组名,数组名表示整个数组。 除此1,2两种情况之外,所有的数组名都表示数组首元素的地址。
除了以上两种情况,所有数组名都代表数组首元素的地址。
当数组传参的时候,实际上只是把数组的首元素的地址传递过去了。
所以即使在函数参数部分写成数组的形式: int arr[] 表示的依然是一个指针: int *arr 。
往往我们在写代码的时候,会将数组作为参数传个函数,比如:我们实现一个冒泡排序函数。
#include <stdio.h>
void bubble_sort(int arr[],int sz)
{
int i = 0;
for (i = 0; i < sz - 1; i++)
{
int j = 0;
for (j = 0; j < sz - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int i = 0;
int arr[] = { 3,1,7,5,8,9,0,2,4,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("%d ", arr[i]);
}
return 0;
}















 5872
5872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











