










介绍
树也是基于结点的数据结构,但树里面的每个结点,可以含有多个链分别指向其他多个结点。
基于树的数据结构有很多种,但本章只关注其中一种——二叉树。二叉树是一种遵守以下规则的树。
- 每个结点的子结点数量可为 0、1、2。
- 如果有两个子结点,则其中一个子结点的值必须小于父结点,另一个子结点的值必须大于父结点。
以下是一个二叉树的例子,其中结点的值是数字。
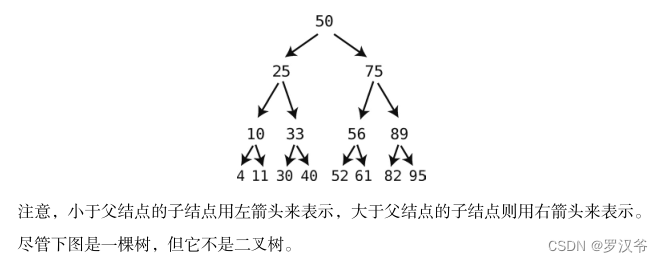
二叉树在查找、插入和删除上引以为傲的 O(log N)效率,使其成为了存储和修改有序数据的一大利器。它尤其适用于需要经常改动的数据,虽然在查找上它跟有序数组不相伯仲,但在插入和删除方面,它迅速得多。
定义
class TreeNode:
"""
二叉树节点的定义。
该类用于构建二叉树的节点结构,每个节点包含一个值(val)、左子节点(left)和右子节点(right)。
Attributes:
val: 节点的值,默认为0。
left: 左子节点,默认为None。
right: 右子节点,默认为None。
"""
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
操作
查找
二叉树的查找算法先从根结点开始:
(1) 检视该结点的值。
(2) 如果正是所要找的值,太好了!
(3) 如果要找的值小于当前结点的值,则在该结点的左子树查找。
(4) 如果要找的值大于当前结点的值,则在该结点的右子树查找。
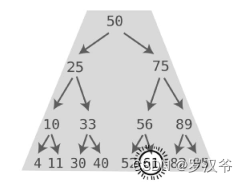
推广开来,我们会说二叉树查找的时间复杂度是 O(log N)。因为每行进一步,我们就把剩余的结点排除了一半(不过很快就能看到,只在最好情况下,即理想的平衡二叉树才有这样的效率)。再与二分查找比较,它也是每次尝试会排除一半可能性的 O(log N)算法,可见二叉树查找跟有序数组的二分查找拥有同样的效率。
要说二叉树哪里比有序数组更亮眼,那应该是插入操作。
插入
假设要插入一个45节点,最终找到的位置是在40的右侧插入。
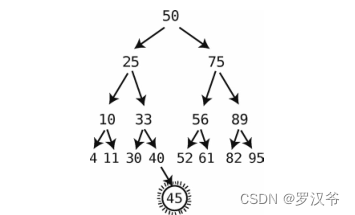
这个例子里,插入花了 5 步,包括 4 步查找和 1 步插入。入这 1 步总是发生在查找之后,所以总共 log N + 1 步。按照忽略常数的大 O 来说,就是 O(log N)步。
这就是二叉树的高效之处。有序数组查找需要 O(log N),插入需要 O(N),而二叉树都是只要O(log N)。
删除
两种情况:
- 如果要删除的结点没有子结点,那直接删掉它就好。
- 如果要删除的结点有一个子结点,那删掉它之后,还要将子结点填到被删除结点的位
置上。
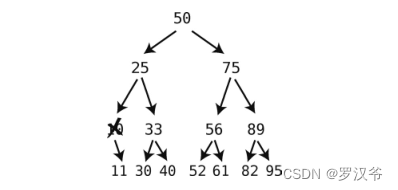
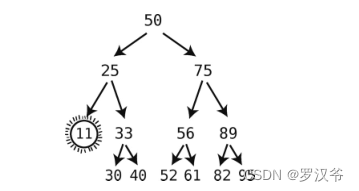
- 如果要删除的结点有两个子结点,则将该结点替换成其后继结点。一个结点的后继结点,就是所有比被删除结点大的子结点中,最小的那个。
- 如果后继结点带有右子结点,则在后继结点填补被删除结点以后,用此右子结点替代后继结点的父节点的左子结点。
class Node:
def __init__(self, key):
self.key = key
self.left = None
self.right = None
def delete_node(root, key):
if not root:
return root
# 深度优先搜索,找到要删除的节点
if key < root.key:
root.left = delete_node(root.left, key)
elif key > root.key:
root.right = delete_node(root.right, key)
else:
# 找到要删除的节点
if not root.left:
temp = root.right
root = None
return temp
elif not root.right:
temp = root.left
root = None
return temp
# 找到右子树的最小节点来替换
temp = find_min(root.right)
root.key = temp.key
root.right = delete_node(root.right, temp.key)
return root
def find_min(node):
# 找到右子树的最小节点
current = node
while current.left is not None:
current = current.left
return current
# 示例
root = Node(50)
root.left = Node(30)
root.right = Node(70)
root.left.left = Node(20)
root.left.right = Node(40)
root.right.left = Node(60)
root.right.right = Node(80)
# 打印树的中序遍历
def in_order_traversal(node):
if node:
in_order_traversal(node.left)
print(f"{node.key} ", end="")
in_order_traversal(node.right)
print("Original tree:")
in_order_traversal(root)
root = delete_node(root, 50)
print("\nAfter deleting 50:")
in_order_traversal(root)
跟查找和插入一样,平均情况下二叉树的删除效率也是 O(log N)。因为删除包括一次查找,以及少量额外的步骤去处理悬空的子结点。有序数组的删除则由于需要左移元素去填补被删除元素产生的空隙,最终导致 O(N)的时间复杂度。
案例
比如说你正在做一个书目维护的应用,它需要具备以下功能。
- 该应用可以将书名依照字母序打印。
- 该应用可以持续更新书目。
- 该应用可以让用户从书目中搜索书名。
使用python语言,利用二叉树作为数据结构实现以上功能。
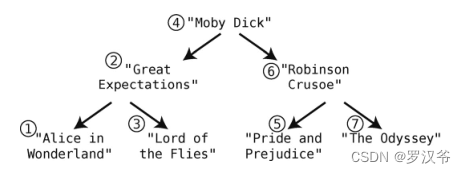
class BookNode:
def __init__(self, title):
self.title = title
self.left = None
self.right = None
class BST:
def __init__(self):
self.root = None
def insert(self, title):
if not self.root:
self.root = BookNode(title)
else:
self._insert(self.root, title)
def _insert(self, node, title):
if title < node.title:
if not node.left:
node.left = BookNode(title)
else:
self._insert(node.left, title)
else:
if not node.right:
node.right = BookNode(title)
else:
self._insert(node.right, title)
def inorder_traversal(self):
if self.root:
self._inorder_traversal(self.root)
def _inorder_traversal(self, node):
if node:
self._inorder_traversal(node.left)
print(node.title, end="==>")
self._inorder_traversal(node.right)
def search(self, title):
if not self.root:
return False
return self._search(self.root, title)
def _search(self, node, title):
if not node or node.title == title:
return node is not None
return self._search(node.left, title) if title < node.title else self._search(node.right, title)
# 使用示例
bst = BST()
books = ["Alice in Wonderland", "Pride and Prejudice", "The Great Gatsby", "To Kill a Mockingbird", "War and Peace"]
for book in books:
bst.insert(book)
print("Books in alphabetical order:")
bst.inorder_traversal()
print("\nSearching for 'Pride and Prejudice':", bst.search("Pride and Prejudice"))
print("Searching for 'Moby Dick':", bst.search("Moby Dick")) # 不存在的书名
总结
二叉树是一种强大的基于结点的数据结构,它既能维持元素的顺序,又能快速地查找、插入和删除。尽管比它的近亲链表更为复杂,但它更有用。
值得一提的是,树形的数据结构除了二叉树以外还有很多种,包括堆、B 树、红黑树、2-3-4树等。它们也各有自己适用的场景。
下一章,我们还会遇见另一种基于结点的数据结构——图。图是社交网络和地图软件等复杂
应用的核心组成部分,强大且灵活。















 8366
8366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









