






0x01 说明
本次用到的平台是:Projectdiscovery.io | Chaos,该平台收集国外各大漏洞赏金平台,目前拥有资产规模大概在1600 0000~1800 0000,很可怕的数量 ,并且每小时都在增加或减少,对接非常多的第三方自建赏金平台,这比我们自己去收集某个平台会来的多,挖到的概率也更大。
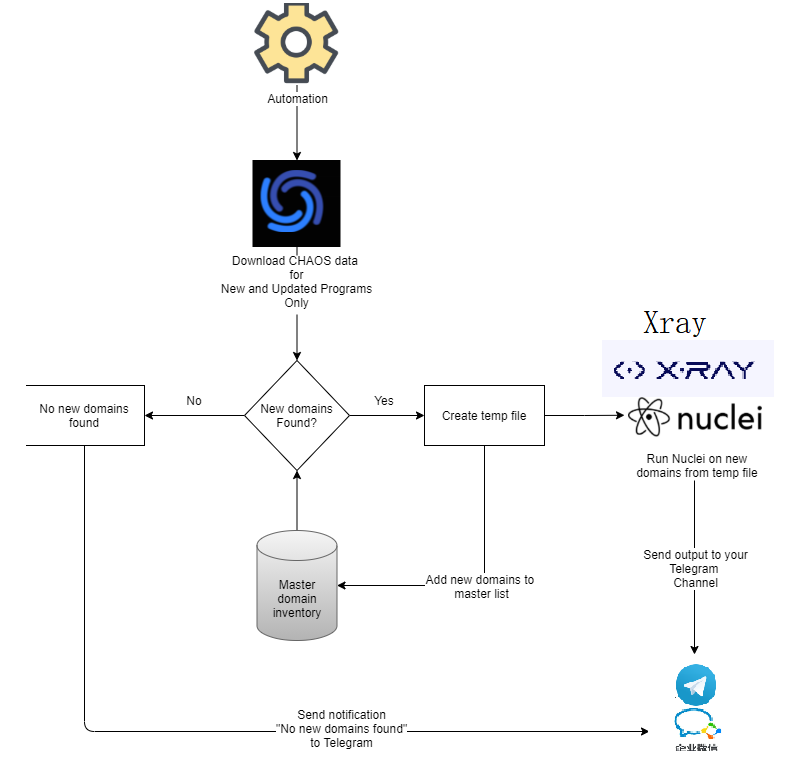
0x02 自动化方案流程
- 使用脚本去获取projectdiscovery平台的所有资产,资产侦察与收集就交给projectdiscovery了
- 把下载的资产对比上次Master domain数据,判断当前是否有新增资产出现,如果没有就结束 ,就等待下一次循环
- 如果有,就把新增的资产提取出来,创建临时文件,并把新资产加入到Masterdomain
- 把新增资产使用naabu 进行端口扫描,把开放的端口使用httpx来验证,提取http存活资产
- 把http存活资产送往nuclei进行漏洞扫描,同时也送往Xray,默认使用Xray的基础爬虫功能扫描常见漏洞
- Xray的扫描结果保存成xray-new-$(date +%F-%T).html,也可以同时添加webhook模式推送
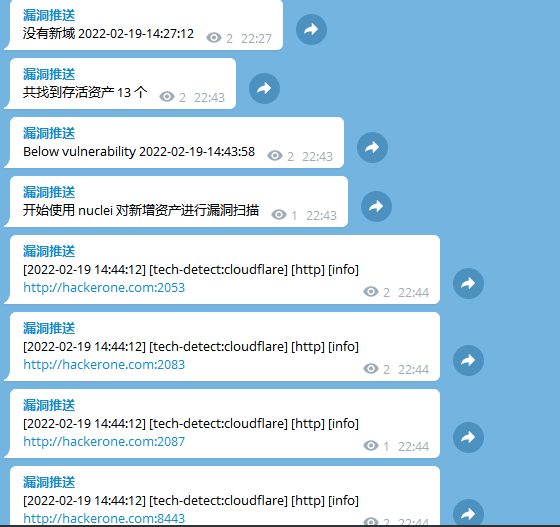
- nuclei漏洞扫描结果用notify实时推送、 nuclei与xray都扫描结束后 ,等待下一次循环,这一切都是自动去执行
0x03 准备工作
先安装这些工具,并设置好软链接,能全局使用,这些工具安装很简单,不再阐述,github也有 安装教程
- Centos7+ 64 位 配置 4H 4G起 【服务器一台】
- chaospy【资产侦查、资产下载】 GitHub - PhotonBolt/chaospy: Small Tool written based on chaos from projectdiscovery.io
- unzip 【解压】
- anew 【过滤重复】 https://github.com/tomnomnom/anew
- naabu【端口扫描】 https://github.com/projectdiscovery/naabu
- httpx 【存活检测】 https://github.com/projectdiscovery/httpx
- nuclei 【漏洞扫描】 https://nuclei.projectdiscovery.io/
- Xray 【漏洞扫描】 https://download.xray.cool/
- python 【微信通知】
- notify 【漏洞通知】 notify比较成熟的推送方案
服务器推荐vultr,可以用我的推荐链接:https://www.vultr.com/?ref=9059107-8H
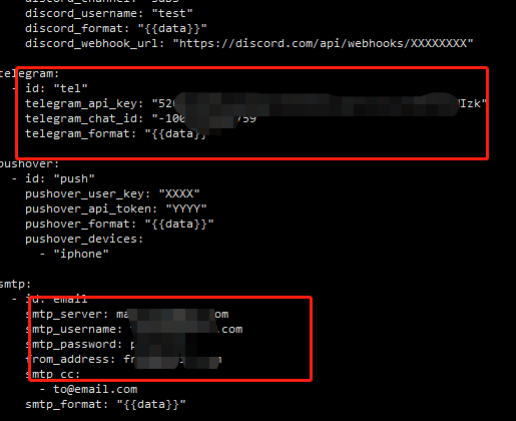
0x04 关于notify通知相关配置
配置文件(没有就创建这个文件):/root/.config/notify/provider-config.yaml
修改通知配置 即可,比如我使用的通知是电报 和 邮件(配置任意一个即可)
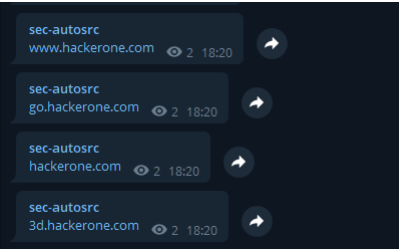
测试效果
subfinder -d hackerone.com | notify -provider telegram
我这是设置是电报通知,执行结束后,如果能收到结果,那通知这块就没问题,可以下一步了
0x05 部署过程
请确保上面提到的工具都已安装好,现在我们来构造一个sh脚本文件,这个脚本就把上面说的流 程都做了一遍
命名为: wadong.sh , 添加执行权限: chmod +x wadong.sh
wadong.sh 脚本主要 完成 资产侦察资产收集、端口扫描,去重检测,存活探测,漏洞扫描,结果通知的功能
脚本:
#!/bin/bash
# 使用chaospy,只下载有赏金资产数据
#python3 chaospy.py --download-hackerone
#python3 chaospy.py --download-rewards #下载所有赏金资产
#./chaospy.py --download-bugcrowd 下载 BugCrowd 资产
#./chaospy.py --download-hackerone 下载 Hackerone 资产
#./chaospy.py --download-intigriti 下载 Intigriti 资产
#./chaospy.py --download-external 下载自托管资产
#./chaospy.py --download-swags 下载程序 Swags 资产
#./chaospy.py --download-rewards 下载有奖励的资产
#./chaospy.py --download-norewards 下载没有奖励的资产
#对下载的进行解压,使用awk把结果与上次的做对比,检测是否有新增
if ls | grep “.zip” &> /dev/null; then
unzip ‘*.zip’ &> /dev/null
cat *.txt >> newdomains.md
rm -f *.txt
awk ‘NR==FNR{lines[$0];next} !($0 in lines)’ alltargets.txtls newdomains.md >> domains.txtls
rm -f newdomains.md
################################################################################## 发送新增资产手机通知
echo “资产侦察结束 $(date +%F-%T)” | notify -silent -provider telegram
echo “找到新域 $(wc -l < domains.txtls) 个” | notify -silent -provider telegram
################################################################################## 更新nuclei漏洞扫描模板
nuclei -silent -update
nuclei -silent -ut
rm -f *.zip
else
echo “没有找到新程序” | notify -silent -provider telegram
fi
if [ -s domains.txtls ];then
echo “开始使用 naabu 对新增资产端口扫描” | notify -silent -provider telegram
fine_line=$(cat domains.txtls | wc -l )
num=1
K=10000
j=true
F=0
while $j
do
echo $fine_line
if [ $num -lt $fine_line ];then
m= ( ( (( ((num+$K))
sed -n '‘ n u m ′ , ′ num',' num′,′m’p’ domains.txtls >> domaint.txtls
((num=num+$m))
naabu -stats -l domaint.txtls -p 80,443,8080,2053,2087,2096,8443,2083,2086,2095,8880,2052,2082,3443,8791,8887,8888,444,9443,2443,10000,10001,8082,8444,20000,8081,8445,8446,8447 -silent -o open-domain.txtls &> /dev/null | echo “端口扫描”
echo “端口扫描结束,开始使用httpx探测存活” | notify -silent -provider telegram
httpx -silent -stats -l open-domain.txtls -fl 0 -mc 200,302,403,404,204,303,400,401 -o newurls.txtls &> /dev/null
echo “httpx共找到存活资产 $(wc -l < newurls.txtls) 个” | notify -silent -provider telegram
cat newurls.txtls >new-active-$(date +%F-%T).txt #保存新增资产记录
cat domaint.txtls >> alltargets.txtls
echo “已将存活资产存在加入到历史缓存 $(date +%F-%T)” | notify -silent -provider telegram
echo “开始使用 nuclei 对新增资产进行漏洞扫描” | notify -silent -provider telegram
cat newurls.txtls | nuclei -rl 300 -bs 35 -c 30 -mhe 10 -ni -o res-all-vulnerability-results.txt -stats -silent -severity critical,medium,high,low | notify -silent -provider telegram
echo “nuclei 漏洞扫描结束” | notify -silent -provider telegram
#使用xray扫描,记得配好webhook,不配就删掉这项,保存成文件也可以
#echo “开始使用 xray 对新增资产进行漏洞扫描” | notify -silent -provider telegram
#xray_linux_amd64 webscan --url-file newurls.txtls --webhook-output http://www.qq.com/webhook --html-output xray-new-$(date +%F-%T).html
#echo “xray 漏洞扫描结束,xray漏洞报告请上服务器查看” | notify -silent -provider telegram
rm -f open-domain.txtls
rm -f domaint.txtls
rm -f newurls.txtls
else
echo “ssss”
j = false
sed -n '‘ n u m ′ , ′ num',' num′,′find_line’p’ domains.txtls domaint.txtls
naabu -stats -l domaint.txtls -p 80,443,8080,2053,2087,2096,8443,2083,2086,2095,8880,2052,2082,3443,8791,8887,8888,444,9443,2443,10000,10001,8082,8444,20000,8081,8445,8446,8447 -silent -o open-domain.txtls &> /dev/null | echo “端口扫描”
echo “端口扫描结束,开始使用httpx探测存活” | notify -silent -provider telegram
httpx -silent -stats -l open-domain.txtls -fl 0 -mc 200,302,403,404,204,303,400,401 -o newurls.txtls &> /dev/null
echo “httpx共找到存活资产 $(wc -l < newurls.txtls) 个” | notify -silent -provider telegram
cat newurls.txtls >new-active-$(date +%F-%T).txt #保存新增资产记录
cat domaint.txtls >> alltargets.txtls
echo “已将存活资产存在加入到历史缓存 $(date +%F-%T)” | notify -silent -provider telegram
echo “开始使用 nuclei 对新增资产进行漏洞扫描” | notify -silent -provider telegram
cat newurls.txtls | nuclei -rl 300 -bs 35 -c 30 -mhe 10 -ni -o res-all-vulnerability-results.txt -stats -silent -severity critical,medium,high,low | notify -silent -provider telegram
echo “nuclei 漏洞扫描结束” | notify -silent -provider telegram
#使用xray扫描,记得配好webhook,不配就删掉这项,保存成文件也可以
#echo “开始使用 xray 对新增资产进行漏洞扫描” | notify -silent -provider telegram
#xray_linux_amd64 webscan --url-file newurls.txtls --webhook-output http://www.qq.com/webhook --html-output xray-new-$(date +%F-%T).html
#echo “xray 漏洞扫描结束,xray漏洞报告请上服务器查看” | notify -silent -provider telegram
rm -f open-domain.txtls
rm -f domaint.txtls
rm -f newurls.txtls
fi
done
rm -f domains.txtls
else
################################################################################## Send result to notify if no new domains found
echo “没有新域 $(date +%F-%T)” | notify -silent -provider telegram
fi
再构建一个first.sh文件,这个脚本只执行一次就行,后续也就用不到了, 主要用于第一次产生历 史缓存域,标记为旧资产
添加执行权限: chmod +x first.sh
#!/bin/bash # 使用chaospy,只下载有赏金资产数据 ./chaospy.py --download-new ./chaospy.py --download-rewards #对下载的进行解压, if ls | grep “.zip” &> /dev/null; then unzip ‘*.zip’ &> /dev/null rm -f alltargets.txtls cat *.txt >> alltargets.txtls rm -f *.txt rm -f *.zip echo “找到域 $(wc -l < alltargets.txtls) 个,已保存成缓存文件alltargets.txt” fi
0x06 开始赏金自动化
在确保以上工具都安装好的情况下
1、执行 first.sh 脚本,让本地产生足够多的缓存域名,标记为旧资产
./first.sh
2、循环执行bbautomation.sh脚本,sleep 3600秒 就是每小时一次,也就是脚本
xunhuan.sh:
#!/bin/bash
while true; do ./wadong.sh;sleep 3600; done
3.chaospy脚本已做了大概修改,优化延迟扫描时间和报错
#!/usr/bin/python3
import requests
import time,os,argparse
#Colors
Black = “\033[30m”
Red = “\033[31m”
Green = “\033[32m”
Yellow = “\033[33m”
Blue = “\033[34m”
Magenta = “\033[35m”
Cyan = “\033[36m”
LightGray = “\033[37m”
DarkGray = “\033[90m”
LightRed = “\033[91m”
LightGreen = “\033[92m”
LightYellow = “\033[93m”
LightBlue = “\033[94m”
LightMagenta = “\033[95m”
LightCyan = “\033[96m”
White = “\033[97m”
Default = ‘\033[0m’
banner= “”"
%s \_\_\_\_\_\_\_\_ \_\_\_\_
/ \_\_\_\_/ /\_ \_\_\_\_ \_\_\_\_\_ \_\_\_\_\_/ \_\_ \\\_\_ \_\_
/ / / \_\_ \\/ \_\_ \`/ \_\_ \\/ \_\_\_/ /\_/ / / / /
/ /\_\_\_/ / / / /\_/ / /\_/ (\_\_ ) \_\_\_\_/ /\_/ /
\\\_\_\_\_/\_/ /\_/\\\_\_,\_/\\\_\_\_\_/\_\_\_\_/\_/ \\\_\_, /
/\_\_\_\_/
%s Small Tool written based on chaos from projectdiscovery.io
%s https://chaos.projectdiscovery.io/
%s \*Author -> Moaaz (https://twitter.com/photonbo1t)\*
%s \n “”"%(LightGreen,Yellow,DarkGray,DarkGray,Default)
parser = argparse.ArgumentParser(description=‘ChaosPY Tool’)
parser.add_argument(‘-list’,dest=‘list’,help=‘List all programs’,action=‘store_true’)
parser.add_argument(‘–list-bugcrowd’,dest=‘list_bugcrowd’,help=‘List BugCrowd programs’,action=‘store_true’)
parser.add_argument(‘–list-hackerone’,dest=‘list_hackerone’,help=‘List Hackerone programs’,action=‘store_true’)
parser.add_argument(‘–list-intigriti’,dest=‘list_intigriti’,help=‘List Intigriti programs’,action=‘store_true’)
parser.add_argument(‘–list-external’,dest=‘list_external’,help=‘List Self Hosted programs’,action=‘store_true’)
parser.add_argument(‘–list-swags’,dest=‘list_swags’,help=‘List programs Swags Offers’,action=‘store_true’)
parser.add_argument(‘–list-rewards’,dest=‘list_rewards’,help=‘List programs with rewards’,action=‘store_true’)
parser.add_argument(‘–list-norewards’,dest=‘list_norewards’,help=‘List programs with no rewards’,action=‘store_true’)
parser.add_argument(‘–list-new’,dest=‘list_new’,help=‘List new programs’,action=‘store_true’)
parser.add_argument(‘–list-updated’,dest=‘list_updated’,help=‘List updated programs’,action=‘store_true’)
parser.add_argument(‘-download’,dest=‘download’,help=‘Download Specific Program’)
parser.add_argument(‘–download-all’,dest=‘download_all’,help=‘Download all programs’,action=‘store_true’)
parser.add_argument(‘–download-bugcrowd’,dest=‘download_bugcrowd’,help=‘Download BugCrowd programs’,action=‘store_true’)
parser.add_argument(‘–download-hackerone’,dest=‘download_hackerone’,help=‘Download Hackerone programs’,action=‘store_true’)
parser.add_argument(‘–download-intigriti’,dest=‘download_intigriti’,help=‘Download intigriti programs’,action=‘store_true’)
parser.add_argument(‘–download-external’,dest=‘download_external’,help=‘Download external programs’,action=‘store_true’)
parser.add_argument(‘–download-swags’,dest=‘download_swags’,help=‘Download programs Swags Offers’,action=‘store_true’)
parser.add_argument(‘–download-rewards’,dest=‘download_rewards’,help=‘Download programs with rewards’,action=‘store_true’)
parser.add_argument(‘–download-norewards’,dest=‘download_norewards’,help=‘Download programs with no rewards’,action=‘store_true’)
parser.add_argument(‘–download-new’,dest=‘download_new’,help=‘Download new programs’,action=‘store_true’)
parser.add_argument(‘–download-updated’,dest=‘download_updated’,help=‘Download updated programs’,action=‘store_true’)
args = parser.parse_args()
os.system(‘clear’)
ls = args.list
list_bugcrowd = args.list_bugcrowd
list_hackerone=args.list_hackerone
list_intigriti=args.list_intigriti
list_external=args.list_external
list_swags=args.list_swags
list_rewards=args.list_rewards
list_norewards=args.list_norewards
list_new=args.list_new
list_updated=args.list_updated
download = args.download
download_all= args.download_all
download_bugcrowd = args.download_bugcrowd
download_hackerone=args.download_hackerone
download_intigriti=args.download_intigriti
download_external=args.download_external
download_swags=args.download_swags
download_rewards=args.download_rewards
download_norewards=args.download_norewards
download_new=args.download_new
download_updated=args.download_updated
print (banner)
def getdata():
url = "https://chaos-data.projectdiscovery.io/index.json"
insuer = True
while insuer:
try:
source= requests.get(url)
print("爬取完毕!")
insuer = False
except:
print("存在延迟!")
time.sleep(10)
return source.json()
def info():
new = 0
hackerone = 0
bugcrowd= 0
intigriti = 0
external = 0
changed = 0
subdomains = 0
rewards= 0
norewards= 0
swags= 0
for item in getdata():
if item\['is\_new'\] is True:
new += 1
if item\['platform'\] == "hackerone":
hackerone +=1
if item\['platform'\] == "bugcrowd":
bugcrowd += 1
if item\['platform'\] == "intigriti":
intigriti += 1
else:
external += 1
if item\['change'\] != 0:
changed +=1
subdomains = subdomains +item\['count'\]
if item\['bounty'\] is True:
rewards += 1
else:
norewards += 1
if 'swag' in item:
swags +=1
print(White+"\[!\] Programs Last Updated {}".format(item\['last\_updated'\]\[:10\]))
print(LightGreen+"\[!\] {} Subdomains.".format(subdomains))
print(Green+"\[!\] {} Programs.".format(len(getdata()))+Default)
print(LightCyan+"\[!\] {} Programs changed.".format(changed)+Default)
print(Blue+"\[!\] {} New programs.".format(new)+Default)
print(LightGray+"\[!\] {} HackerOne programs.".format(hackerone)+Default)
print(Magenta+"\[!\] {} Intigriti programs.".format(intigriti)+Default)
print(Yellow+"\[!\] {} BugCrowd programs.".format(bugcrowd)+Default)
print(LightGreen+"\[!\] {} Self hosted programs.".format(external)+Default)
print(Cyan+"\[!\] {} Programs With Rewards.".format(rewards)+Default)
print(Yellow+"\[!\] {} Programs Offers Swags.".format(swags)+Default)
print(LightRed+"\[!\] {} No Rewards programs.".format(norewards)+Default)
def down():
print(download)
for item in getdata():
if item\['name'\] == download:
print(LightGreen+"\[!\] Program Found."+Default)
print(Cyan+"\[!\] Downloading",download, "..."+Default)
url = item\['URL'\]
resp = requests.get(url)
zname= download+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] {} File successfully downloaded.".format(zname)+Default)
def list_all():
print(White+"\[!\] Listing all Programs. \\n"+Default)
for item in getdata():
print (Blue+item\['name'\]+Default)
def bugcrowd():
print(Yellow+"\[!\] Listing Bugcrowd Programs."+Default)
for item in getdata():
if item\['platform'\] == "bugcrowd":
print (Yellow+item\['name'\]+Default)
def hackerone():
print(White+"\[!\] Listing HackerOne Programs."+Default)
for item in getdata():
if item\['platform'\] == "hackerone":
print (White+item\['name'\]+Default)
def intigriti():
print(Magenta+"\[!\] Listing intigriti Programs."+Default)
for item in getdata():
if item\['platform'\] == "hackerone":
print (Magenta+item\['name'\]+Default)
def external():
print(Cyan+"\[!\] Listing External Programs."+Default)
for item in getdata():
if item\['platform'\] == "":
print (Cyan+item\['name'\]+Default)
def swags():
print(LightGreen+"\[!\] Listing Swag Programs."+Default)
for item in getdata():
if 'swag' in item:
print (LightGreen+item\['name'\]+Default)
def rewards():
print(Cyan+"\[!\] Listing Rewards Programs."+Default)
for item in getdata():
if item\['bounty'\] == True:
print (Cyan+item\['name'\]+Default)
def norewards():
print(Red+"\[!\] Listing NORewards Programs."+Default)
for item in getdata():
if item\['bounty'\] == False:
print (Red+item\['name'\]+Default)
def new():
print(LightGreen+"\[!\] Listing New Programs."+Default)
for item in getdata():
if item\['is\_new'\] == True:
print (LightGreen+item\['name'\]+Default)
def changed():
print(Cyan+"\[!\] Listing Updated Programs."+Default)
for item in getdata():
if item\['change'\] != 0:
print (Cyan+item\['name'\]+Default)
def all_down():
for item in getdata():
print(Blue+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
resp = requests.get(item\['URL'\])
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All Programs successfully downloaded."+Default)
def bc_down():
for item in getdata():
if item\['platform'\] == "bugcrowd":
print(Yellow+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
resp = requests.get(item\['URL'\])
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All BugCrowd programs successfully downloaded."+Default)
def h1_down():
for item in getdata():
if item\['platform'\] == "hackerone":
print(White+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
resp = requests.get(item\['URL'\])
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All HackerOne programs successfully downloaded."+Default)
def intigriti_down():
for item in getdata():
if item\['platform'\] == "intigriti":
print(Magenta+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
resp = requests.get(item\['URL'\])
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All intigriti programs successfully downloaded."+Default)
def external_down():
for item in getdata():
if item\['platform'\] == "":
print(White+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
resp = requests.get(item\['URL'\])
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All External programs successfully downloaded."+Default)
def new_down():
for item in getdata():
if item\['is\_new'\] is True:
print(Cyan+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
insuer = True
while insuer:
try:
resp = requests.get(item\['URL'\])
print("爬取完毕")
insuer = False
except:
print("存在延时!")
time.sleep(5)
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All New programs successfully downloaded."+Default)
def updated_down():
for item in getdata():
if item\['change'\] != 0:
print(Blue+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
resp = requests.get(item\['URL'\])
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All Updated programs successfully downloaded."+Default)
def swags_down():
for item in getdata():
if 'swag' in item:
print(LightYellow+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
resp = requests.get(item\['URL'\])
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All Swags programs successfully downloaded."+Default)
def rewards_down():
for item in getdata():
if item\['bounty'\] is True:
print(Cyan+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
insuer = True
while insuer:
try:
resp = requests.get(item\['URL'\])
print("爬取完毕")
insuer = False
except:
print("存在延时!")
time.sleep(5)
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All Bounty programs successfully downloaded."+Default)
def norewards_down():
for item in getdata():
if item\['bounty'\] is False:
print(LightRed+"\[!\] Downloading {} ".format(item\['name'\]),end="\\r"+Default)
resp = requests.get(item\['URL'\])
zname= item\['name'\]+".zip"
zfile = open(zname, 'wb')
zfile.write(resp.content)
zfile.close()
print(LightGreen+"\[!\] All Norewards programs successfully downloaded."+Default)
def main():
info()
if download is not None:
down()
if download\_all :
all\_down()
if ls :
list\_all()
if list\_bugcrowd:
bugcrowd()
if list\_hackerone:
hackerone()
if list\_external:
external()
if list\_swags:
swags()
if list\_rewards:
rewards()
if list\_norewards:
norewards()
if list\_new:
new()
if list\_updated:
changed()
if download\_bugcrowd:
bc\_down()
if download\_hackerone:
h1\_down()
if download\_intigriti:
intigriti\_down()
if download\_external:
external\_down()
if download\_swags:
swags\_down()
if download\_rewards:
rewards\_down()
if download\_norewards:
norewards\_down()
if download\_new:
new\_down()
if download\_updated:
updated\_down()
if __name__ == ‘__main__’:
main()
0x07 最后
建议在 Digital Ocean 或 vultr 等 VPS 系统上运行这些程序,启一个后台线程即可,建议使用tmux的后台功能
这样扫描到重复漏洞会非常少的,也会更加容易获取赏金,将更多的关注新资产漏洞
资产侦察 资产收集、端口扫描,去重检测,存活探测,漏洞扫描,全自动化,结果通知,全部自动化了,即使睡觉也在挖洞
接下来我将给各位同学划分一张学习计划表!
学习计划
那么问题又来了,作为萌新小白,我应该先学什么,再学什么?
既然你都问的这么直白了,我就告诉你,零基础应该从什么开始学起:
阶段一:初级网络安全工程师
接下来我将给大家安排一个为期1个月的网络安全初级计划,当你学完后,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web渗透、安全服务、安全分析等岗位;其中,如果你等保模块学的好,还可以从事等保工程师。
综合薪资区间6k~15k
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(1周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(1周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(1周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)

那么,到此为止,已经耗时1个月左右。你已经成功成为了一名“脚本小子”。那么你还想接着往下探索吗?
阶段二:中级or高级网络安全工程师(看自己能力)
综合薪资区间15k~30k
7、脚本编程学习(4周)
在网络安全领域。是否具备编程能力是“脚本小子”和真正网络安全工程师的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力。
零基础入门的同学,我建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习
搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP,IDE强烈推荐Sublime;
Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,没必要看完
用Python编写漏洞的exp,然后写一个简单的网络爬虫
PHP基本语法学习并书写一个简单的博客系统
熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选)
了解Bootstrap的布局或者CSS。
阶段三:顶级网络安全工程师
如果你对网络安全入门感兴趣,那么你需要的话可以点击这里👉网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!

学习资料分享
当然,只给予计划不给予学习资料的行为无异于耍流氓,这里给大家整理了一份【282G】的网络安全工程师从入门到精通的学习资料包,可点击下方二维码链接领取哦。
















 2744
2744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









