






内核错误码
在调用内核api发生异常时通常会返回一个负值,不同的错误情况,负数值也不同,这些数值就是内核中预定义的错误码(errno),了解这些错误码的含义可以让我们推测出错的原因,从而提高开发效率。
errno-base.h中定义了内核中常见的错误码:include/uapi/asm-generic/errno-base.h
#ifndef _ASM_GENERIC_ERRNO_BASE_H
#define _ASM_GENERIC_ERRNO_BASE_H
#define EPERM 1 /* Operation not permitted */
#define ENOENT 2 /* No such file or directory */
#define ESRCH 3 /* No such process */
#define EINTR 4 /* Interrupted system call */
#define EIO 5 /* I/O error */
#define ENXIO 6 /* No such device or address */
#define E2BIG 7 /* Argument list too long */
#define ENOEXEC 8 /* Exec format error */
#define EBADF 9 /* Bad file number */
#define ECHILD 10 /* No child processes */
#define EAGAIN 11 /* Try again */
#define ENOMEM 12 /* Out of memory */
#define EACCES 13 /* Permission denied */
#define EFAULT 14 /* Bad address */
#define ENOTBLK 15 /* Block device required */
#define EBUSY 16 /* Device or resource busy */
#define EEXIST 17 /* File exists */
#define EXDEV 18 /* Cross-device link */
#define ENODEV 19 /* No such device */
#define ENOTDIR 20 /* Not a directory */
#define EISDIR 21 /* Is a directory */
#define EINVAL 22 /* Invalid argument */
#define ENFILE 23 /* File table overflow */
#define EMFILE 24 /* Too many open files */
#define ENOTTY 25 /* Not a typewriter */
#define ETXTBSY 26 /* Text file busy */
#define EFBIG 27 /* File too large */
#define ENOSPC 28 /* No space left on device */
#define ESPIPE 29 /* Illegal seek */
#define EROFS 30 /* Read-only file system */
#define EMLINK 31 /* Too many links */
#define EPIPE 32 /* Broken pipe */
#define EDOM 33 /* Math argument out of domain of func */
#define ERANGE 34 /* Math result not representable */
#endif内核错误指针
通常如果一个函数返回值是指针类型,在调用出错的情况下会返回NULL指针,但是Linux 内核对指针返回操作了更精妙的处理,使其与错误码关联,从而让出错能通过返回的指针体现出来。在内核中,有以下三种指针:
- 有效指针
- 空指针(NULL)
- 错误指针
其中错误指针为指向内核空间的保留区域(addr:0xfffff000 ~ 0xffffffff,size:4K)的指针。
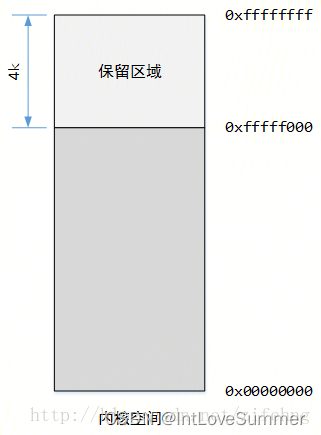
Linux内核用最后4K空间保存指针的错误码,64K系统地址为( 0xffff ffff ffff f000~0xffff ffff ffff ffff )。
如果是错误指针,配合PTR_ERR()判断错误代码。
在有限的内核空间内,最后一页4K大小的地址被保留,并和内核定义的系列错误码相关联,指明了对应的出错情况,如果一个指针指向了该页的地址范围被定义为错误指针。内核提供了错误指针相关的api。
#define MAX_ERRNO 4095
#ifndef __ASSEMBLY__
#define IS_ERR_VALUE(x) unlikely((x) >= (unsigned long)-MAX_ERRNO)
/* 将错误码转为错误指针 */
/* common function attributes 中提供的warn_unused_result 可以保证函数的返回值在没有被使用的时候提示warning,如果在编译选项添加-Werror, 则在编译时就会提示编译错误。*/
static inline void * __must_check ERR_PTR(long error)
{
return (void *) error;
}
/* 将错误指针转为错误码 */
static inline long __must_check PTR_ERR(const void *ptr)
{
return (long) ptr;
}
/* 判断指针是否为错误指针 */
static inline long __must_check IS_ERR(const void *ptr)
{
return IS_ERR_VALUE((unsigned long)ptr);
}
static inline long __must_check IS_ERR_OR_NULL(const void *ptr)
{
return !ptr || IS_ERR_VALUE((unsigned long)ptr);
}说明
- inline:内联函数。内联函数的代码会直接嵌入到调用它的位置,调用几次,嵌入几次。
- __must_check:指调用函数一定要处理函数的返回值,否则编译器会给出警告。
- __force:变量可进行强制转换
- (unsigned long)-MAX_ERRNO):用补码的方式表示-4096,64位系统为0xffff ffff ffff f001
likely() 和 unlikely()
文件include/include/complier.h,定义如下:
#ifdef __GNUC__
#include <linux/compiler-gcc.h>
#endif
...
# define likely(x) __builtin_expect(!!(x), 1)
# define unlikely(x) __builtin_expect(!!(x), 0)首先明确:
if(likely(value)). 等价于 if(value)
if(unlikely(value)) 也等价于if(value)
也就是说likely和unlikely从阅读和理解代码的角度来看,是一样的!!!
__builtin_expect()是gcc 提供给程序员的,目的是将“分支转移“的信息提供给编译器,这样编译器可以对代码进行优化,以减少指令跳转带来的性能优化。
__builtin_expect((x),1) 表示x的值为真的可能性更大。
__builtin_expect((x),0) 表示x的值为假的可能性更大。
也就是说,使用likely() 执行if 后面的语句的机会更大,使用unlikely(),执行else后面的语句的机会更大。
例如:下面这段代码,就认为prev 不等于 next的可能性更大。
if(likely(prev != next)) {
next->timestamp = now;
...
} else {
...
}通过这种方式,编译器在编译过程中,会将可能性更大的代码紧跟着前面的代码,从而减少指令跳转带来性能上的下降















 1728
1728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









