 HDFS HA机制解析
HDFS HA机制解析







参考文献:
HDFS HA 原理
HDFS HA: 高可靠性分布式存储系统解决方案的历史演进
由来
虽然namenode的联盟机制可以减小访问压力,同时当有namenode节点挂掉了之后,也能减小一部分的损失,但是依然无法解决单点故障问题。
所以就有了HA机制。简单说就是一个namenode节点有几个替身,他们的edit日志文件相同,当一个节点挂掉了,另一个立马就能顶上去,继续执行集群任务。
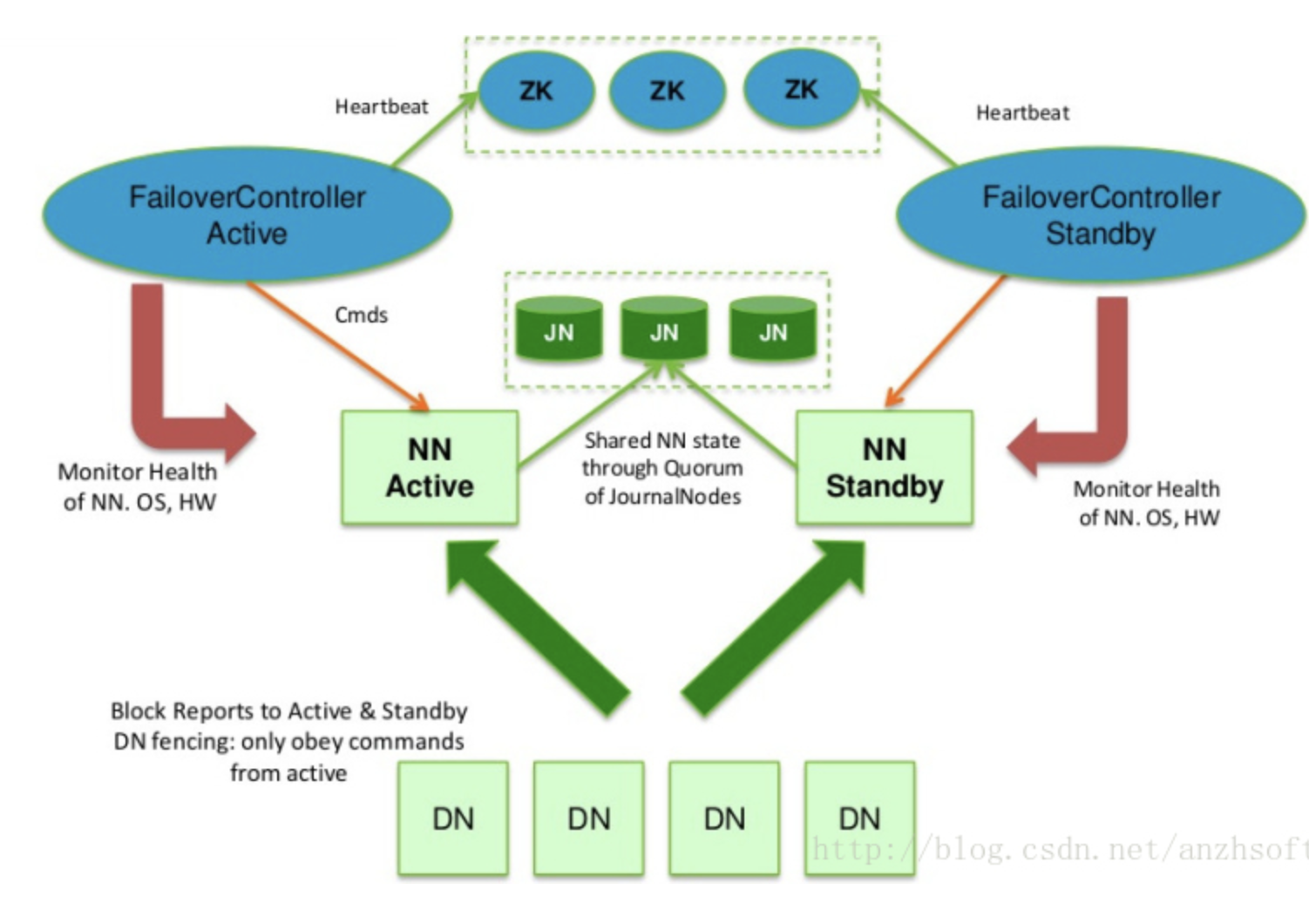
共享存储系统
节点的最新状态是存储在edit日志文件中的,edit日志文件是分段存储的,称为segment。HDFS默认使用QJM技术来保证多个节点的edit日志文件同步的。
所谓QJM技术,来源于paxos算法,只有过半成功写入,才算写入成功。由多个称为journal node的节点构成。
active namenode在完成了对HDFS的更新操作后,会同时将这次操作写入本地和QJM中的edit文件里。standby namenode定期从QJM中读取edit文件,达到维持集群状态同步的效果。
同时,standby namenode会定期对内存中的文件系统镜像做checkpoint,生成新的fsimage文件,并将其发送给activate namenode,用来更新本地的fsimage文件。
当发生主备切换的时候,QJM中的数据可能是不同步的,当standby namenode切换为active状态后,首先需要对QJM中的数据进行同步。
简单说就是所有的journal node将自己最新的起始事务id发送给active namenode,由它选出最大值,并发送回去,然后QJM根据返回的最大id事务对所有journal状态进行更新。
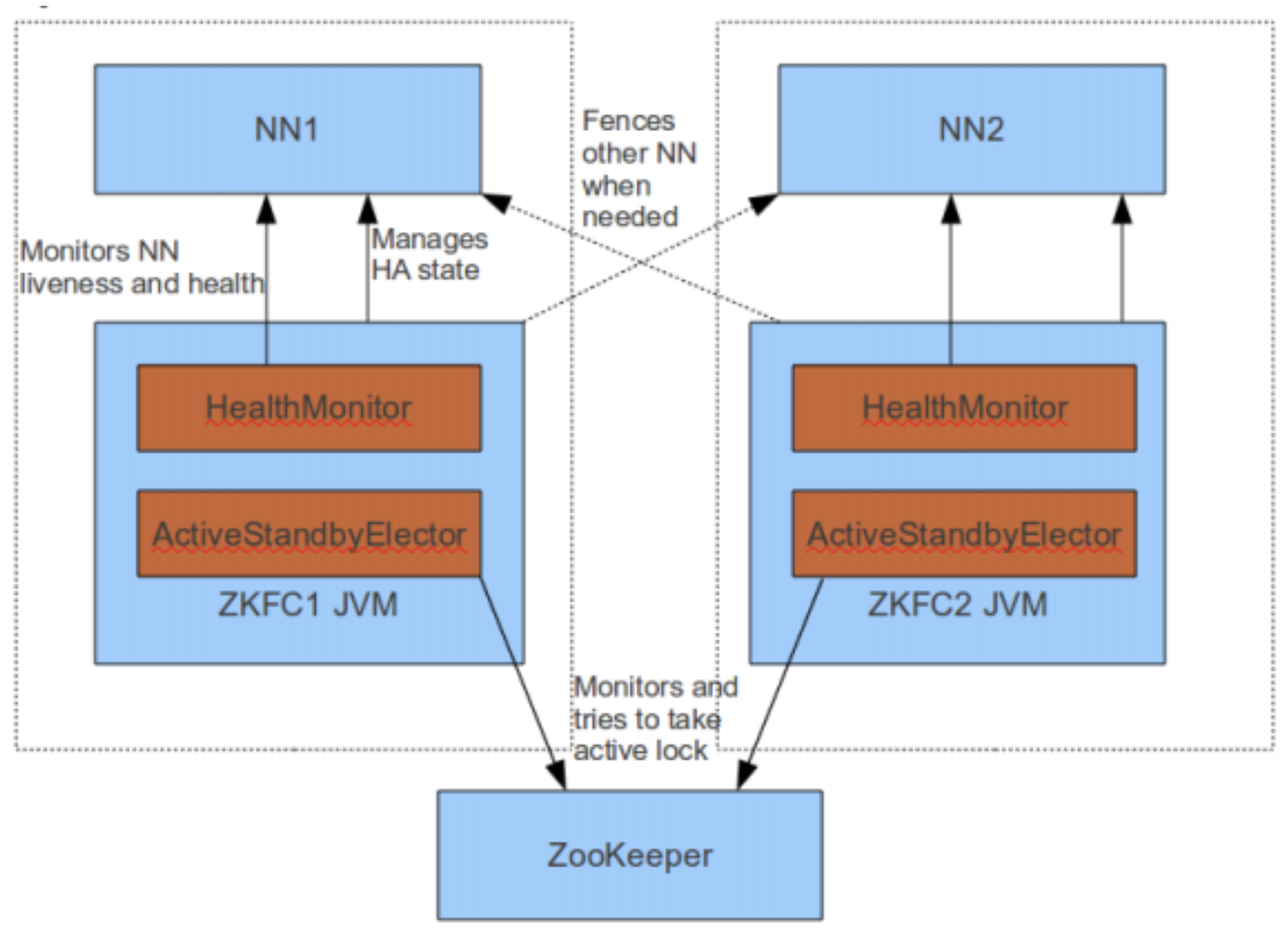
主备切换的过程:
- ZKFC启动,创建HealthMonitor和ActivateStandbyElector两个组件。
- HealthMonitor周期调用namenode的HAServiceProtocal RPC接口,判断namenode当前的状态。
- 如果发现namenode的健康状态发生了变化,调用ZKFC的回调方法。
- 如果ZKFC判断需要进行主备选举,则通知ActiviteStandbyElector进行主备选举。
- ActiviteStandbyElector配合ZK完成选举后,通知ZKFC当前节点是主节点还是从节点。
- ZKFC调用namenode的HAServiceProtocal RPC接口,完成节点的状态转换。
脑裂问题
脑裂问题的解决办法是,当datanode向新选举出的namenode发送心跳信息时,新选举出的namenode返回自己的状态和序列号。此时如果老的namenode恢复了,再向datanode发送自己的状态序列号时,就会匹配不上,datanode就会拒绝听从这个namenode的命令,从而达到防止脑裂的效果。
可以通过ssh登陆到老的namenode上,直接通过kill命令结束它。

















 396
396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









