







文章目录
一、项目介绍
整个项目的是爬取网易云音乐的歌曲的歌词,可以做成歌词本,或其他用途,做到了人性化选择,可以选择网易云音乐所有的音乐种类与音乐人,按照不同的需求拼接url获取内容。但是整个项目我个人认为有些复杂,通过分析网易云音乐网站的源代码发现,里面有很多坑,具体我会在下面展开,提醒大家,我也会用到一些新的方法,并且需要分析的内容也比较多,多提一嘴,我写的这些教程面向有编程基础的读者,因为有些内容我没有详细讲解,篇幅也不够,如果有新入门的朋友,可以私信我,我会提供技术支持,好技术一起分享。
二、所需技术
- import urllib.request
- import urllib.parse
- import lxml import etree (xpath用于获取内容)
- from selenium import webdriver (这是浏览器的自动化库,可以控制浏览器)
- import re (正则表达式,用于提取内容)
- import requests (用于正常的解析内容)
- import os (保存数据时会用到)
- import json (用于txt和json格式的转换)
- chromedriver.exe (这是一个工具,配合selenium使用,注意要下载对应浏览器的对应版本)
三、网页分析
3.1 分析一级页面响应内容
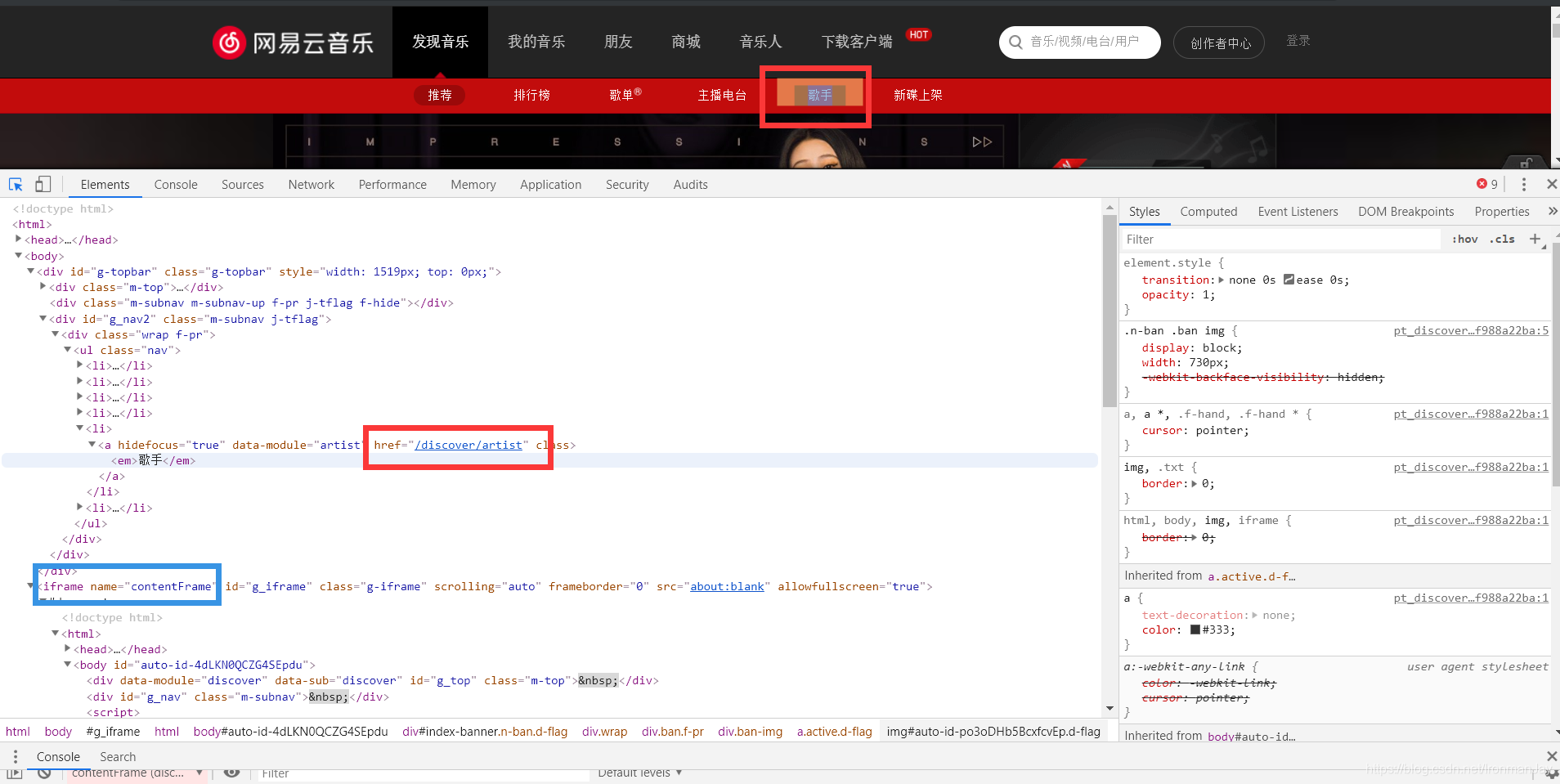
还是老规矩我们来看网站首页能反馈给我们什么内容,我们可以看到,我们应该从首页进入歌手界面,所以需要获取到他的href,这样我们才能拼接url,跳转到歌手界面,但是这里是第一个坑,可见下图,红色是我们需要获取的内容,但是,这些内容都在蓝色的iframe标签中,因为当时(半年前)我还没学前端,所以我在这里踩了第一个坑,根本获取不到内容,解析的html什么都没有,要知道,iframe就是为了无法解析浏览器,所以我们这里就用到的selenium自动化控制浏览器,使用控制软件,打开浏览器,这样就能自动获取到我们想要的内容,也就是href,虽然这样需要打开浏览器,但是我们可以设置关闭,所以并无大碍。
3.2 分析二级页面响应内容
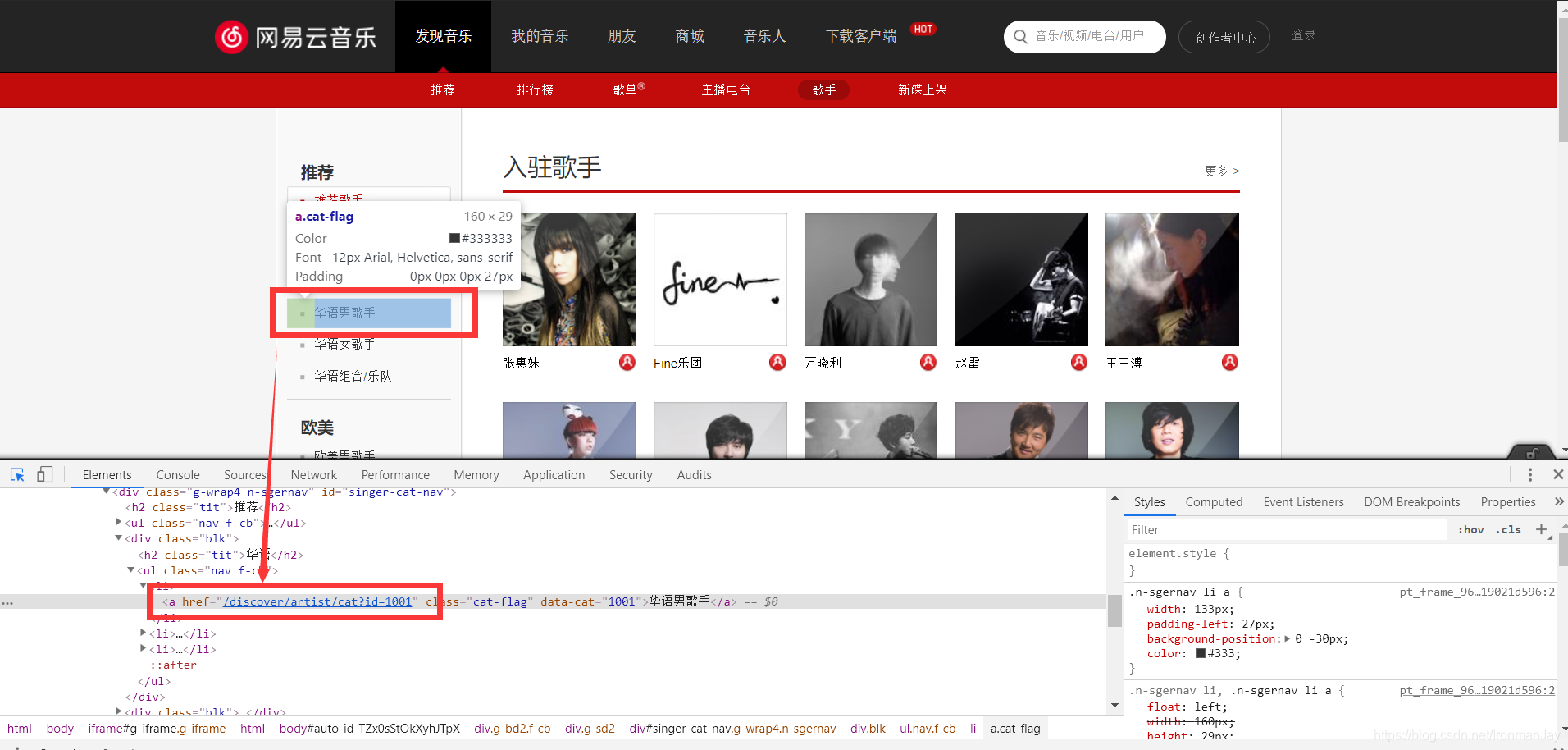
我们在上面已经获取到了二级页面的相关href,我们就已经来到了二级页面,二级页面我们需要获取到每个歌手的分类,我们就能进入到具体的歌手界面,所以我们还需要获取到每个分类的id,获取到之后就能拼接每个歌手具体的url,同样还是包在iframe标签中,所以还需要selenium自动化测试,会在下面的代码中展示。看下图,我们找到了对应分类的url,这里需要说明,我们后续为了让用户更好的体验能够选择,所以我们需要用到正则获取到大分类的id,这样我们就能来到分类页面,这样我们就来到了三级页面。
3.3 分析三级页面响应内容
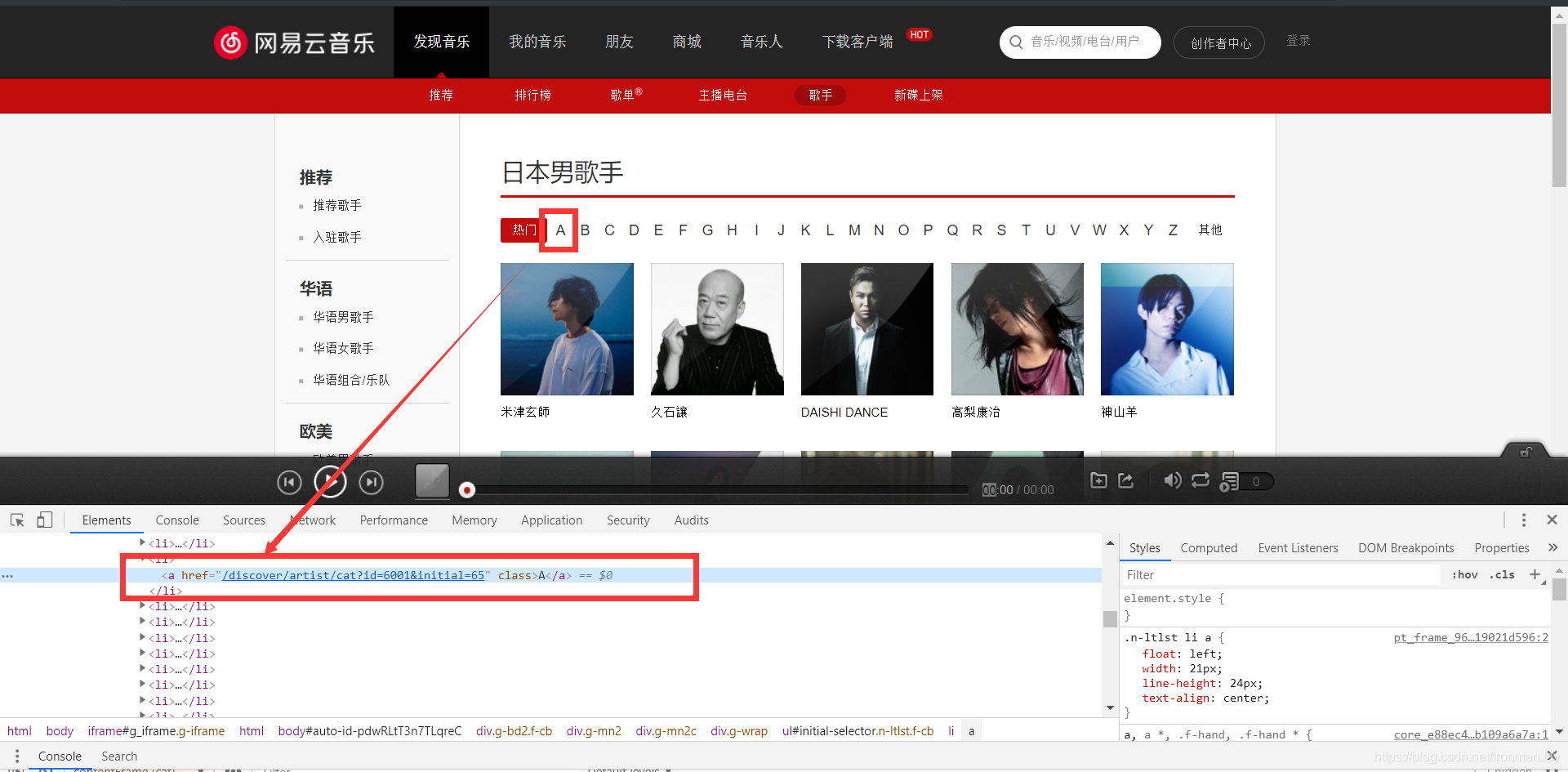
来到三级页面之后,我们可以看到这个分类的所有歌手都展示出来了,这就到了小分类,根据这个大分类中的首字母进行小分类,我们还是需要获取到href,可见包裹在li标签中,这样我们就可以使用xpath提取,同样我们还是会使用字典进行保存,通过用户输入内容进行拼接url,在这里我们就能进入下级页面。
3.4 分析四级页面响应内容
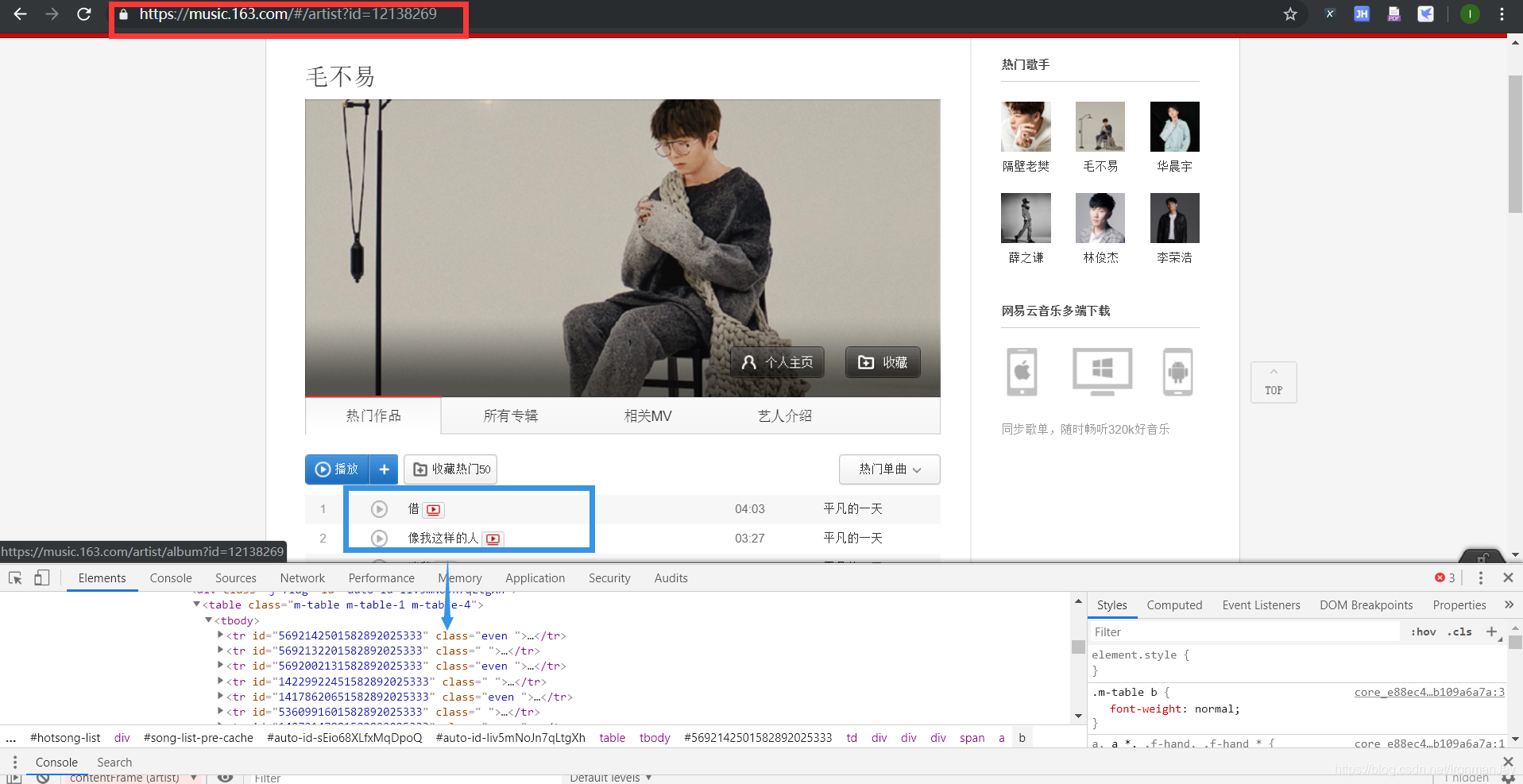
来到四级页面后,红框就是我们最终根据用户输入拼接的url,而蓝色部分为我们需要爬取的内容,我们可以看到,都保存在tr中,方便我们使用xpath提取,当然,还需要selenium自动化测试,具体方法我都在下面的代码中标明。
四、分析小结
通过上述分析,我们可以发现,整体技术并不太过复杂,主要是比较麻烦,推荐各位使用selenium,如果有更好的方法,欢迎私信我,这是我半年前写的代码,还是比较青涩,其实就是发送请求,获取响应数据,解析内容,保存数据,短短几个字虽然能概括,但是其中需要大家付出很多努力。
五、代码实现
import urllib.request
import urllib.parse
from lxml import etree
from selenium import webdriver
import re
import requests
import os
import json
class WangYiYunYinYue:
# 初始化方法
def __init__(self):
# 歌手页url,待拼接
self.info_url = "https://music.163.com/#"
# 具体歌手内部页url,待拼接
self.start_url = "https://music.163.com/#/discover/artist/cat?"
# 具体歌曲url,待拼接
self.prot_url = "https://music.163.com/#/artist?"
# 请求头
self.headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36"}
def dafenlei(self,dafenlei_name):
# 使用字典键值对的方式,根据用户输入内容进行拼接url
item = {
'华语男歌手' : 1001, '华语女歌手' : 1002, '华语组合/乐队' : 1003, '欧美男歌手' : 2001, '欧美女歌手' : 2002, '欧美组合/乐队' : 2003, '日本男歌手' : 6001, '日本女歌手' : 6002,
'日本组合/乐队' : 6003, '韩国男歌手' : 7001, '韩国女歌手' : 7002, '韩国组合/乐队' : 7003, '其他男歌手' : 4001, '其他女歌手' : 4002, '其他组合/乐队' : 4003,}
return item[dafenlei_name]
def geshoufenlei(self,geshou):
# 使用字典键值对的方式,根据用户输入内容进行拼接url
item = {
'热门' : -1, 'A' : 65, 'B' : 66, 'C' : 67, 'D' : 68, 'E' : 69, 'F' : 70, 'G' : 71, 'H' : 72, 'I' : 73, 'J' : 74, 'K' : 75, 'L' : 76, 'M' : 77, 'N' : 78,
'O': 79,'P' : 80, 'Q' : 81, 'R' : 82, 'S' : 83, 'T' : 84, 'U' : 85, 'V' : 86, 'W' : 87, 'X' : 88, 'Y' : 89, 'Z' : 90, '其他' : 0, }
return item[geshou]
# 根据上面的用户输入内容,拼接url
def get_url(self,fenlei_id,geshou_initial):
data = {
"id" : fenlei_id,
"initial" : geshou_initial
}
# 解码
data_final = urllib.parse.urlencode(data)
return self.start_url + data_final
def get_gesou_info(self,html):
# 使用xpath获取内容
geshou_html = etree.HTML(html)
geshou = geshou_html.xpath("//ul[@class='m-cvrlst m-cvrlst-5 f-cb']/li")
for list in geshou:
item= {}
item["歌手名称:"] = list.xpath("./a/text()") + list.xpath("./div/a/text()") + list.xpath("./p/a/text()")
href = list.xpath("./a[1]/@href") + list.xpath("./div/a/@href")
# 获取二级页面url
self.get_erji_info(href)
# 整个项目的请求方法,可以获得响应内容
def parse_url(self,url):
response = requests.get(url=url,headers=self.headers)
return response.content.decode()
# 根据get_gesou_info中获取到的二级页面url,使用正则表达式提取待拼接的内容,继续发送请求
# 这里使用selenium控制浏览器
def get_erji_info(self,href):
src = href[0]
id = re.findall(r"\d*\d",src,re.S)[0]
data = {
"id" : id,
}
finaldata = urllib.parse.urlencode(data)
url = self.prot_url + finaldata
driver = webdriver.Chrome()
driver.get(url)
driver.switch_to.frame(driver.find_element_by_name("contentFrame"))
html = driver.page_source
info_html = etree.HTML(html)
next_href_list = info_html.xpath("//table[@class='m-table m-table-1 m-table-4']/tbody")
# 获取到三级页面的url
for next_href in next_href_list:
next_url = next_href.xpath("./tr/td[2]/div/div/div/span/a/@href")
self.make_sanji_url(next_url)
# 解析三级页面的响应
def make_sanji_url(self,next_url):
for src in next_url:
url = self.info_url + src
self.get_sanji_info(url)
# 继续获取内容,这才是核心,提取到歌词
def get_sanji_info(self,url):
driver_html = webdriver.Chrome()
driver_html.get(url)
driver_html.switch_to.frame(driver_html.find_element_by_name("contentFrame"))
html = driver_html.page_source
info_html = etree.HTML(html)
all = {}
all["歌曲名称:"] = info_html.xpath("//div[@class='cnt']/div[@class='hd']/div//text()")
all["歌手:"] = info_html.xpath("//div[@class='cnt']/p/span/a/text()")
all["所属专辑:"] = info_html.xpath("//div[@class='cnt']/p/a/text()")
all["歌词:"] = info_html.xpath("//div[@class='cnt']/div[@id='lyric-content']//text()")
self.save(all)
# 保存方法
def save(self,all):
name = all["歌手:"][0]
if not os.path.exists(name):
os.mkdir(name)
filename = name + ".txt"
filepath = name + "/" + filename
with open(filepath,"a",encoding="utf-8") as tf:
tf.write(json.dumps(all,ensure_ascii=False,indent=2))
tf.write("\n")
# 主方法
def run(self):
dafenlei_name = input("请输入歌手分类:")
fenlei_id = self.dafenlei(dafenlei_name)
geshou = input("请输入歌手首字母/热门/其他:")
geshou_initial = self.geshoufenlei(geshou)
url = self.get_url(fenlei_id,geshou_initial)
driver = webdriver.Chrome()
driver.get(url)
driver.switch_to.frame(driver.find_element_by_name("contentFrame"))
html = driver.page_source
self.get_gesou_info(html)
driver.quit()
if __name__ == '__main__':
wangyiyunyinyue = WangYiYunYinYue()
# 调用方法
wangyiyunyinyue.run()
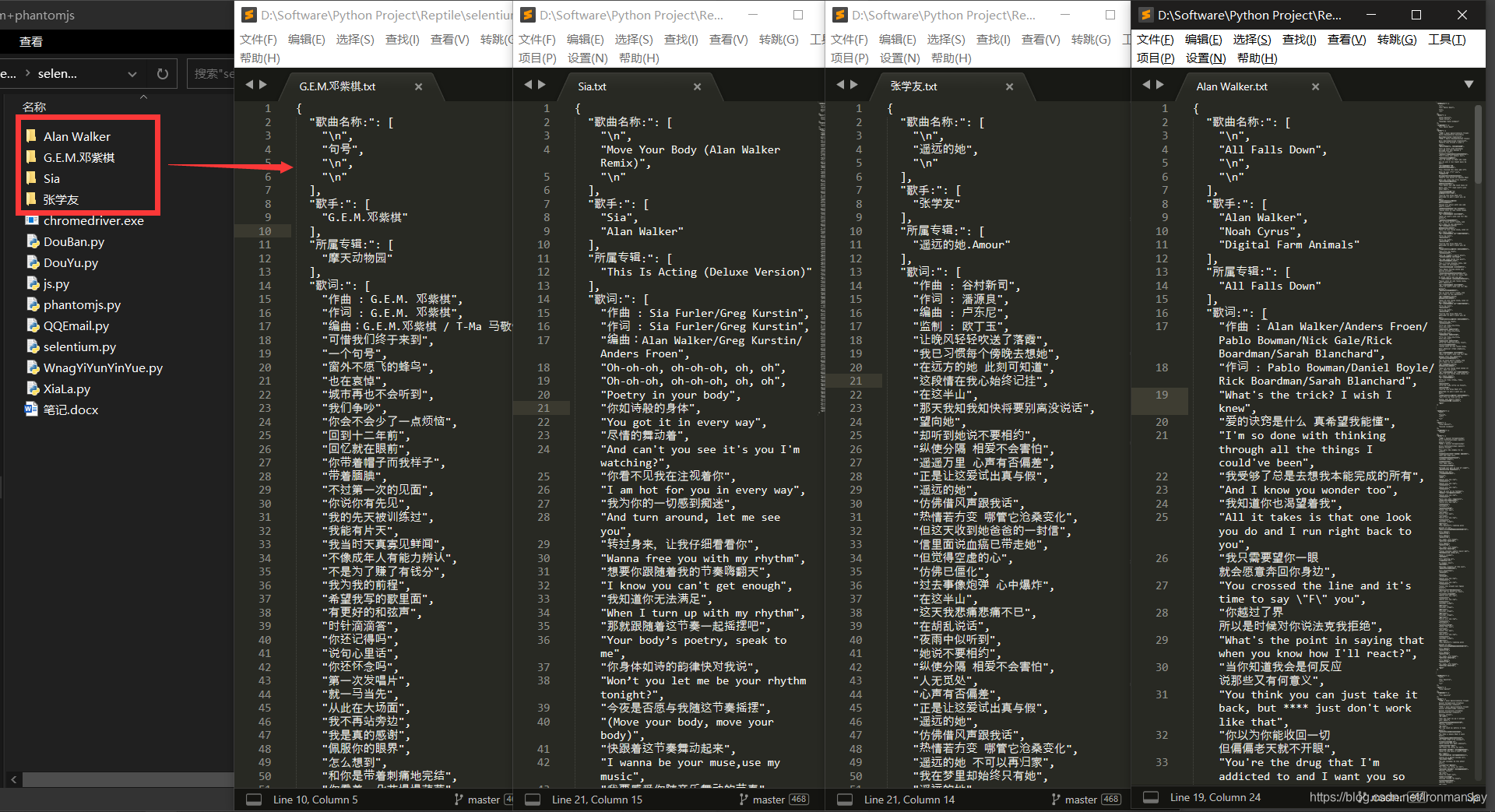
六、爬取结果
简单四个示例,您想爬取多少都可以
六、总结
总体来说,爬取一些大公司难度还是有的,可见上图,代码完美运行,能获取到所有的歌词信息,方便我们使用。这类的我不在解析,后面会带来分布式爬取,验证码破解等进阶内容。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











