






一、数仓及其维度
1、什么是数仓?
数据仓储,简称数仓(Data WareHouse)。从逻辑上理解,数据库和数仓没有区别,都是通过数据库软件实现存放数据的地方,只不过从数量来说,数据仓库要比数据库更庞大。
数仓主要是为企业制定决策,提供数据支持的。当业务简单,可以用数据库来存储,分析,制表。但当数据量几何式增长,需要跨机器整合时,数仓就非常必要了。
2、数仓的特点
(1)集成性
数仓中存储的数据来源于多个数据源,原始数据在不同数据源中的存储方式各不相同。要整合成为最终的数据集合,需要从数据源经过一些列抽取、清洗、转换的过程。
(2)稳定性
数仓中保存的数据时历史记录,不允许被修改。用户只能通过分析工具进行查询和分析。
(3)动态性
数仓的数据会随时建变化而定期更新,这里的定期更新不是指修改数据,一般是将业务系统发送变化的数据定期同步到数仓,和稳定性不冲突。不可更新是针对应用而言,即用户分析处理时不更新数据。
(4)主题性
传统数据库对应的业务不同,数仓需要根据需求,将不同数据源的数据进行整合,即数据一般都是围绕某一业务主题进行建模。例如“贷款”主题、“存款”主题等。
(5)扩展性
之所以有的大型数据仓库系统架构设计复杂,是因为考虑到了未来3-5年的扩展性,这样的话,未来不用太快花钱去重建数据仓库系统,就能很稳定运行。主要体现在数据建模的合理性,数据仓库方案中多出一些中间层,使海量数据流有足够的缓冲,不至于数据量大很多,就运行不起来了。
3、数仓的数据哪里来的
(1)业务数据
就是各行业在处理事务过程中产生的数据。比如用户在电商网站中登录、下单、支付等过程中,需要和网站后台数据库进行增删改查交互,产生的数据就是业务数据。业务数据通常存储在MySQL、Oracle等数据库中。
(2)用户行为数据
用户在使用产品过程中,通过埋点收集与客户段产品交互过程中产生的数据,并发往日志服务器进行保存。比如页面浏览、点击、停留、评论、点赞、收藏等。用户行为数据通常存储在日志文件中。
(3)爬虫数据
通常是通过技术手段获取其他公司网站的数据。
4、什么是数仓的维度,为何要分层(分层的问题)
(1)减少重复开发,在数据开发过程中可以产生中间层,将公共逻辑下沉,减少重复计算;
(2)清晰数据结构,每个分层分工明确,方便开发人员理解;
(3)方便定位问题,通过分层了解数据血缘关系,在出问题的时候通过回溯定位问题。
(4)简单化复杂问题,,和分治法思想类似,分而治之,将复杂的问题简单化,还能解耦
5、数仓的维度建模和关系型建模的区别?
数仓的关系型建模严格遵守三范式理论(第一范式:属性不可分割,第二范式:不能有部分函数型依赖,第三范式:不能有传递性函数依赖),数据冗余度低,但在大数据的场景下,查询效率低。
维度模型相对清晰、简洁。以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。维度模型面向业务,将业务用事实表和维度表呈现出来,表结构简单,故查询简单,查询效率较高。
二、典型维度建模
1、一般分几层?
不同的企业不同的业务类型服务不同的用户,没有定论说分3、4层还是5层,只有最合适的分层。一般的数仓包含:离线数仓、准实时、实时数仓;我们这里是采用T+1离线数仓,分为五层架构。
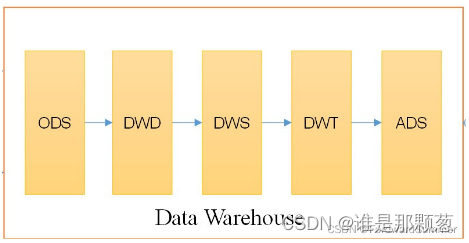
2、典型分层及其大致介绍(简单理解和总结)
(1)ODS(Operation Data Store)
原始数据,此层保存最原始数据,并且备份,备份可以压缩。
(2)DWD(Data Warehouse Detail)
数据清洗,脱敏,维度退化。
(3)DWS(Data Warehouse Summary)
DWS层就是关于各个主题的加工和使用,是宽表聚合值。
(4)DWT(Data Waterhouse Topic)
和DWS相同,不过DWS层单位是日,而DWT是对截止到当日、或者近7日、近30日的汇总。
(5)ADS(Application Data Store)
ADS层是面向业务定制的应用数据层。
三、每层具体介绍
1、ODS
ODS主要完成
(1)保持数据原貌不做任何修改,保留历史数据,存储起到备份数据的作用;
(2)数据一般采用lzo、Snappy、parquet等压缩格式;
(3)创建分区表,防止后续的全表扫描,减少集群资源访问数仓的压力,一般按天存储在数仓中。
数据来源
(1)前端埋点日志信息
有Kafka和flume采集到HDFS上;前端埋点日志以JSON格式形式存在,又分为两部分:启动日志和事件日志。
(2)业务系统数据
有mysql数据库数据通过sqoop这种数据同步工具,采集到HDFS上。
2、DWD
DWD层是对事实表的处理,代表的是业务的最小粒度层。任何数据的记录都可以从这一层获取,为后续的DWS和DWT层层做准备。还有对日志行为进行解析,以及对业务数据采用维度模型的方式重新建模(维度退化)。
DWD主要完成:
1、数据清洗
(1)空值去除
(2)过滤核心字段无意义的数据,比如订单表中订单id为null,支付表中支付id为空。
(3)将用户行为宽表和业务表进行数据一致性处理。
清洗的手段包括Sql、mr、rdd、kettlt、Python等等。清洗掉数据不能太多也不能很少。合理范围:1万条数据清洗掉1条。
2、脱敏
对手机号、身份证号等敏感数据脱敏
3、维度退化
对业务数据传过来的表进行维度退化和降维。(商品一级二级三级、省市县、年月日
4、压缩
LZO,列式存储parquet
3、DWS
DWS层就是关于各个主题的加工和使用,这层是宽表聚合值,是各个事实表的聚合值。这里做轻度的汇总会让以后的计算更加高效,如:统计各个主题对象计算7天、30天、90天的行为,应对特殊需求(例如,购买行为,统计商品复购率)会快很多,不必走ODS层反复拿数据做加工。
这层会把每个用户单日的行为聚合起来组成一张多列宽表,以便之后关联用户维度信息后进行,不同角度的统计分析。
涉及的主题包括:访客主题、用户主题、商品主题、优惠券主题、活动主题、地区主题等
4、DWT
这层涉及的主题和DWS层一样包括:访客主题、用户主题、商品主题、优惠券主题、活动主题、地区主题等。只不过DWS层的粒度是对当日用户汇总信息,而DWT层是对截止到当日、或者近7日、近30日等的汇总信息。
以用户主题这个来举例:
*DWS层:用户主题层是记录某一个用户在某一天的汇总行为。
*DWT层:用户主题层是记录某一个用户介质在当日的汇总行为。
5、ADS
ADS层数据是专门给业务使用的数据层,这层是面向业务定制的应用数据层。
ADS主要完成:
(1)提供为数据产品使用的结果数据、指标等。
(2)提供给数据产品和数据分析使用的数据,一般会存在ES、MySQL等系统中供线上系统使用,也可能会存在Hive或者Druid中供数据分析和数据挖掘使用。如报表数据,或者说那种大宽表。
这个项目中ADS层也是包含有多个主题:设备主题、会员主题、商品主题、营销主题、地区主题、访客主题、用户主题、订单主题、优惠券主题等等。每个主题都包含多个指标的计算。















 7857
7857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









