






之前也有说过缓存的三大问题及解决方案:可以 跳转 到这儿看一下
结合网上查阅的博文,整体说一下缓存的概念
缓存出现的原因
缓存出现的目的只有一个:缓冲不同介质IO速度,从而加快访问速度
对于不同介质之间的数据传输,速度快和速度慢的不匹配,会导致速度快的长时间处于等待状态,造成资源的浪费,最典型的例子就是CPU和磁盘之间的不匹配。
至于我们为什么选择磁盘而不选择速度更快的内存等进行大量存储。因为内存的不可靠性(断电不保存)以及受体积、价格因素的影响。既然不能在存储介质上做文章,那么聪明的人类又引入了缓存这个概念,来尽量匹配磁盘和CPU的工作效率。
缓存的概念就是:我们提前将可能将要使用的数据,从速度慢的介质里面放到速度快的介质里面。这样下次用到某个数据时,CPU就可以直接从速度快的介质中获取。其中,提前准备的数据就是缓存
可以说,缓存的技术无处不在。在操作系统、计算机网络、数据库中均有体现。
缓存模型
对于整个计算机而言:
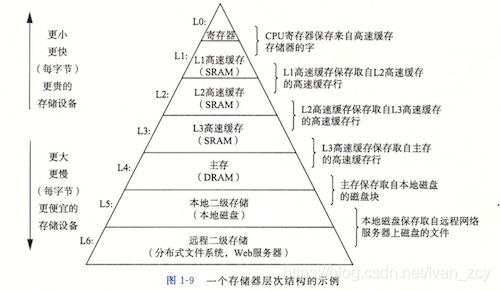
对于整个网络而言:
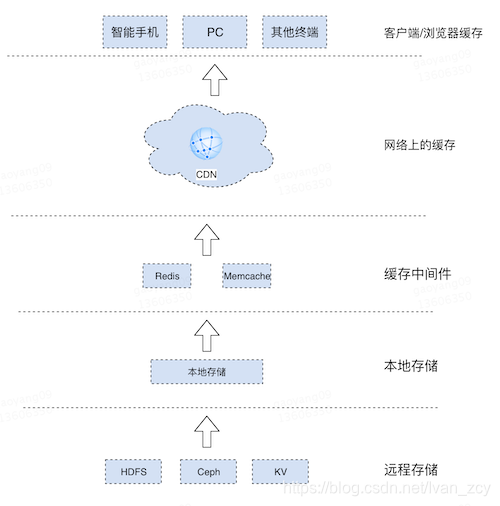
缓存数据的方法
局部性原理缓存
局部性原理的核心在于赌用到某些数据,也会马上用到该数据相邻的数据。比如我们获取一个乒乓球拍信息,可能还会有很大概率获取乒乓球信息。我们获取一个用户的个人信息,可能还会有很大概率获取他的动态。于是,我们获取一个信息时,会一次性把与之相关的信息全部从磁盘读出来放到内存。
运用局部性原理,CPU会把相邻的指令一起从L1缓存读到寄存器。从磁盘读取数据时,也会一次性把所在磁盘扇区的数据全部读进来(前提是程序设计者在存储数据时把相关数据存在一起)
缓存淘汰算法
当缓存满时需要对已经缓存的数据进行替换,这时候就需要进行缓存数据的替换。常见的有先进先出(FIFO),LRU(最近最少使用,Java的LinkedHashMap,Redis,MySQL的BufferPool的缓存都是基于LRU实现的),OPT(最优置换,无法实现)
对于mysql来说,系统上线后会先把常用的数据筛选一遍,找到热点数据放入MySQL的BufferPool中。除此之外还做了优化,把缓存划分成两部分,一部分用来存热点数据(永远不被淘汰),另一部分用来存可以被淘汰的冷数据,对冷数据部分进行LRU。当一些数据被频繁访问时,可以作为热数据存到第一部分中
如果有写的不对或者不全面的地方 可通过主页的联系方式进行指正,谢谢














 1756
1756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









