






CRDT Survey Series翻译
- CRDT 调研, 第一部分:介绍
- CRDT 调研, 第二部分:语义技术
- CRDT Survey, Part 3: Algorithmic Techniques
- Part 4: Further Topics
CRDT 调研, 第一部分:介绍
CRDT Survey, Part 1: Introduction
CRDT 是一种分布式算法,它根据协作应用程序操作的历史记录计算其状态。
什么是CRDT?
假设你正在实现一个协作应用程序,你一定会了解到 无冲突复制数据模型(Conflict-free Replicated Data Types(CRDTs))很适合,并且你想了解更多相关信息。
如果你查找 CRDT 的定义,你会找到主要的两类 基于操作的CRDT(Operation-based) 和 基于状态的CRDT(state-based),使用 例如 『交换性』、『半格』等 专业的数学术语 定义。这可能比 你的协作应用程序的 思维模型 更复杂,我觉得它会让你畏惧。
让我们稍微回顾一下,并思考你想要实现的目标。
在协作应用中,用户不想等待中央处理器的响应,能够立即看到自己的操作。在本地优先应用中尤其如此,用户可以离线编辑 或者 在没有中央处理器的情况下编辑。
即时本地编辑使用户能够并发执行操作:逻辑上同时执行,无需就操作顺序达成一致。这些用户将暂时看到不同的状态。不过,它们最终将彼此同步、操作合并。
即 最终一致性
在这一点上,协作应用程序必须决定:这些并发操作的最终状态是什么?由于这些操作在逻辑上是同时发生的,我们不能假设它们以某种顺序发生。相反,我们需要以一种符合用户期望的方式来合并它们。
举例:成分列表
这是个简单的例子。这个应用是一个 协作食谱编辑器,包含一份配料清单:
- 西兰花头 1克拉
- 油 15毫升
- 盐 2毫升
假设:
- 一位用户删除第一行的成分(西兰花头)
- 同时,第二个用户将 『油』 前面添加一个词语 『橄榄』,意为『橄榄油』。
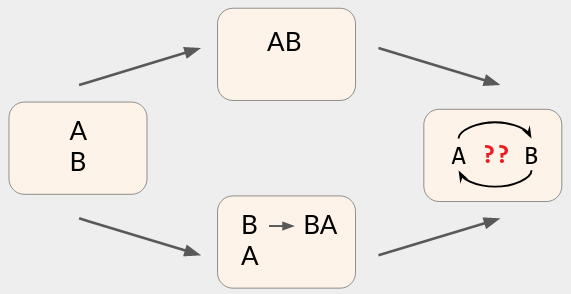
我们可以尝试广播这些操作的非协作版本:删除成分 1;在成分 2 修改为“橄榄油”。但如果另一个用户按照该顺序执行这些操作,他们最终会得到:
- 油 15毫升
- 橄榄盐 2毫升
先删除了 成分1,然后 其他成分的编号 都发生了 更改,在修改成分2 就会不符合期望。
实际上,你需要以并发感知的方式去理解这些并发操作,无论当前索引如何,而是修改适用的成分行。
- 橄榄油 15毫升
- 盐 2毫升
语义
在上面的例子中,用户想要的结果很明显。你大概也能预料到如何实现这种行为:用唯一的 ID 而不是索引来 标识 每种成分。
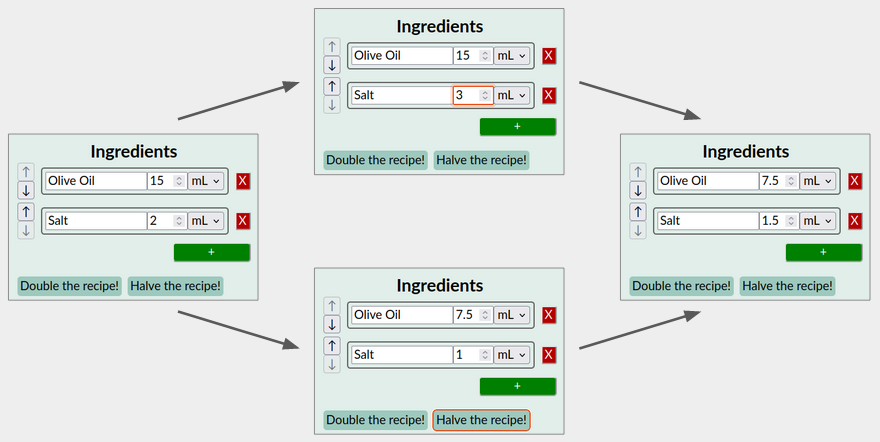
其他情况可能更有趣。例如,从上面的最后一个配方开始,假设两个用户执行另外两个操作:
- 第一个用户将盐的量增加到 3 毫升。
- 同时 第二个用户点击 “将食谱减半” 按钮,将所有的量减半。
我们希望保留两位用户的编辑。此外,由于这是一个食谱,所以数量的比例比绝对值更重要。因此,您应该追求以下结果:
一般来说,协作应用程序的语义是根据用户执行的操作,对应用程序状态的抽象描述。该状态必须在用户之间保持一致:知道相同操作的两个用户必须处于相同的状态。
选择应用程序的语义比听起来更困难,因为它们必须在任意复杂的情况下得到明确的定义。例如,如果第三个用户与上述四个操作同时执行一堆操作,则协作方编辑器最终仍必须处于某种一致的状态 - 希望对用户有意义。
算法
一旦选择了 协作应用程序的语义,您就需要在每个用户 设备 上使用 算法 来实现它们。
例如,假设列车各个门口的乘务员统计登车乘客人数。当列车乘务员看到乘客上车时,他们会增加 协作计数。由于互联网不稳定,增量并不总是立即同步;只要所有列车乘务员最终汇总到正确的总数,这就可以了。
该应用程序的语义很明显:它的状态应该是到 目前为止增量操作的数量,无论并发性如何。具体来说,单个售票员的应用程序将显示它的 增量数量。
基于操作的 CRDT
这是实现这些语义的一种算法:
- 每用户状态:当前计数,最初为 0。
- 操作 inc() :向所有设备广播消息 +1 。收到此消息后,每个用户都会增加自己的状态。(发起者也立即处理该消息。)
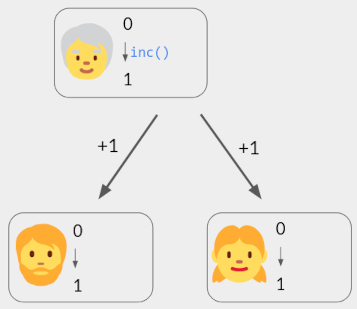
假设当用户广播消息时,它最终被所有协作者接收,没有重复(即,恰好一次)。例如,每个用户可以将他们的消息发送到服务器;服务器存储这些消息并将它们转发给其他用户,其他用户会过滤掉重复的消息。
这种方式的算法称为 Operation-Based CRDTs 。即使 网络有无限的延迟 或 以不同的顺序 向不同的用户传递消息,它们也能工作。事实上,即使在这些条件下,上述算法也符合我们选择的语义。
基于状态的 CRDT
基于 Op 的 CRDT 也可以在没有任何服务器的对等网络中使用。然而,通常每个用户都需要存储完整的消息历史记录,以防其他用户请求旧消息。 (让用户转发彼此的消息,而不仅仅是他们自己的消息,这是一个好主意。)这会产生很高的存储成本:在我们的示例应用程序中为 O(total count) 。
基于状态的 CRDT 是一种 不同类型 的算法,有时可以降低存储成本。它包括:
- 每个用户的状态。隐式地,该状态对用户知道的操作集进行编码,但允许是有损编码。
- 对于每个操作(例如 inc() ),更新本地状态以反映该操作的函数。
- 合并函数,输入第二个状态并更新本地状态以反映操作集的并集:
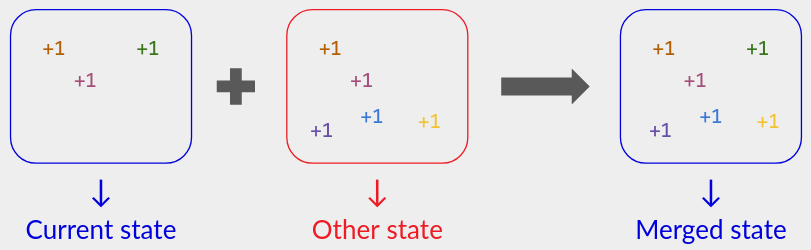
我们将在本博客系列的后面部分看到优化的基于状态的计数器 CRDT。但简单地说,您不是存储完整的消息历史记录,而是存储从每个设备到该设备执行的 inc() 操作数量的映射。这以允许合并(entrywise max)的方式对操作历史记录进行编码,但具有存储成本 O(# devices) 而不是 O(total count) 。
除非您需要基于状态的合并,否则计数应用程序实际上并不需要专业知识 - 它只是以明显的方式进行计数。但如果你想听起来更花哨,你仍然可以谈论“基于操作的计数器 CRDT”。
定义 CRDT
定义 CRDT 的一种方法是“基于操作的 CRDT 或基于状态的 CRDT”。在实际操作中,我们可以更加灵活。例如,CRDT 库通常实现基于操作/基于状态的混合 CRDT,这样就可以在同一应用程序中使用基于操作的消息传递和基于状态的合并。
我喜欢这个更广泛、非正式的定义:CRDT 是一种分布式算法,它根据协作应用程序操作的历史记录计算其状态。 此状态必须仅取决于用户执行的操作:对于了解相同操作的所有用户来说,它必须是相同的,并且它必须是可计算的,无需额外的协调或来自单一事实来源的帮助。 (消息转发服务器是可以的,但是你不能像传统的网络应用程序那样让中央服务器负责状态。)
当然,即使您有中央服务器,您也可以使用 CRDT 技术。例如,协作文本编辑器 可以使用 CRDT 来管理文本,而使用 服务器数据库 来管理权限。
本次调查大纲
在本博客系列中,我将调查协作应用程序的 CRDT 技术。我的目标是揭开并总结我所知道的技术,以便您无需花费博士的努力也可以学习它们。
这些技术分为两个“主题”,对应于上面的部分:
- 语义技术可以帮助您决定协作应用程序的状态应该是什么。
- 算法技术告诉您如何有效地计算该状态。
第 2 部分(下一篇文章)涵盖语义技术;我将在第 3 部分介绍算法技术。
由于我是 Collabs CRDT 库的首席开发人员,因此我还将提及 Collabs 中出现的各种技术。您可以在协作文档中找到摘要。
CRDT 调研, 第二部分:语义技术
CRDT Survey, Part 2: Semantic Techniques
语义技术
在第 1 部分中,我将协作应用程序的语义定义为: 在给定用户执行操作的情况下,应用程序的状态应该是什么 的抽象定义。
您对语义的选择应该根据用户的意图和期望来确定:如果一个用户执行 X,而另一个离线用户同时执行 Y,那么用户同步时希望发生什么?然而,即使在弄清楚具体场景之后,设计一个在每种情况下都定义良好的策略(多路并发、大量离线工作等)也是很棘手的。
CRDT 语义技术 可以帮助您实现这一目标。就像您在编写 单用户应用程序 时了解的 数据结构和设计模式 一样,这些技术提供了有价值的指导,但它们 并不能替代您决定应用程序 实际应该做什么。
这些技术有多种形式:
- 特定的构建块 - 例如,列出 CRDT 位置。 (单用户应用程序类比:特定的数据结构,如哈希映射。)
- 必须明智应用的通用想法 - 例如,唯一 ID。 (单用户类比:面向对象的编程技术。)
- 协作应用程序特定部分的示例语义 - 例如,具有移动操作的列表。 (单用户类比:从现有应用程序的架构中学习。)
如果您阅读过《为协作应用程序设计数据结构》,那么其中一些技术将会很熟悉,但我保证这里也会有新的技术。
目录 [内容忽略] 这篇文章旨在作为参考。然而,一些技术建立在现有技术的基础上。我建议线性阅读,直到到达组合示例,然后跳到您感兴趣的内容。
语义描述
我将通过指定 操作历史记录 的 纯函数 来描述 CRDT 的语义:输入 用户已执行的 操作历史的记录,输出 应用程序 当前应处于的可见状态。
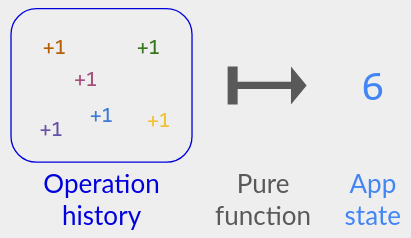
请注意,我并不期望您实现字面上的“操作历史+纯函数”;那将是低效的。相反,您应该实现一个给出相同结果的算法。例如,基于 op 的 CRDT 满足:每当用户收到与操作 S 对应的消息时,用户的状态与应用于 S 的纯函数相匹配。我将在下面给出其中一些算法,并在第 3 部分中提供更多内容。
更准确地说,我将 CRDT 的语义描述为:
- 允许用户对 CRDT 执行的一系列操作。示例:调用 inc() 来递增计数器。
- 对于每个操作,都有一个存储在(抽象)操作历史记录中的翻译版本。例如:当用户删除成分列表中索引 0 处的成分时,我们可能会存储一个操作 Delete the ingredient with unique ID 。
- 一个纯函数,输入一组翻译的操作和一些排序元数据(下一段),并输出了解这些操作的用户的预期状态。示例:计数器的语义函数输入 inc() 操作集并输出其大小,忽略元数据的排序。
“排序元数据”是指示那些操作相互之间需要存在感知的箭头的集合。例如,下面是表示第 1 部分中的操作历史记录的图表:
(一系列操作集合,操作之间存在先后顺序)
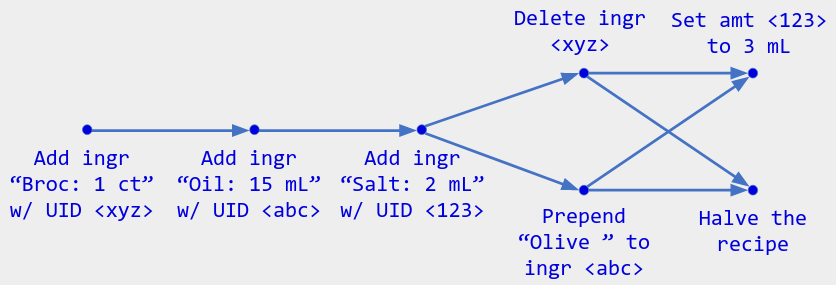
- 一个用户执行一系列操作来创建初始配方。
- 在这些操作后,两个用户同时执行 Delete ingredient 和 Prepend "Olive " to ingredient 。
- 两个用户看到对方的操作后,又进行了两个并发操作。
我将在整篇文章中使用这样的图表来表示操作历史。您可以将它们视为 git 提交图,只不过每个点都标有其操作而不是其状态/哈希,并且并行“头”(最右边的点)被隐式合并。
示例:收到上述操作历史记录的用户已经看到 Set amt <123> to 3 mL 和 头的结果,即使没有“合并提交”。如果该用户执行另一个操作,它将从两个头上获得箭头,就像显式合并提交一样:
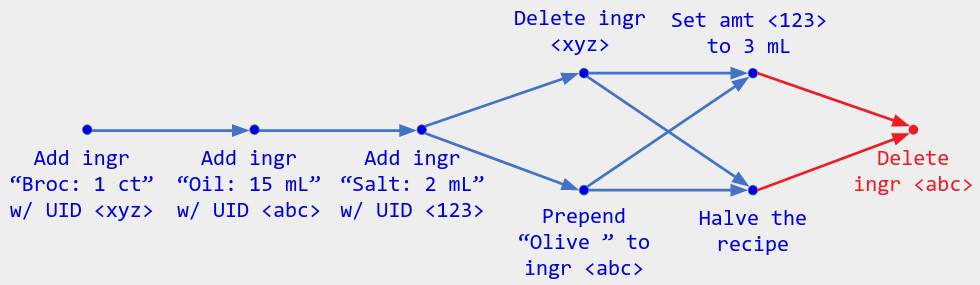
用操作历史的纯函数来描述语义可以让我们避开常见的 CRDT 规则,例如“并发消息必须交换”和“合并函数必须是幂等的”。事实上,这些规则的目的是保证给定的 CRDT 算法对应于操作历史的某个纯函数(参见第 1 部分的 CRDT 定义)。相反,我们直接说出我们想要什么纯函数,然后定义 CRDT 来匹配(或相信您会这样做)。
- 强收敛性是指 CRDT 的状态是操作历史的纯函数,即接收到相同操作集的用户处于等效状态。
- 强最终一致性(SEC)还要求停止执行操作的两个用户最终将处于相同的状态;它源于用户最终交换操作的任何网络的强融合(Shapiro 等人,2011b)。
这些属性对于协作应用程序来说是必要的,但它们还不够:您仍然需要检查 CRDT 的特定语义对于您的应用程序是否合理。如果你陷入困境,很容易忘记这一点。并发消息可交换的证明。
事件发生的因果顺序
正式地说,我们的操作历史图中的箭头表示操作之间的“因果顺序”。我们将使用 因果顺序 来定义 多值寄存器 和 一些后续技术,因此如果你想要一个 正式的定义,请先阅读本节(否则你可以继续往下读)。
因果顺序是定义在成对操作上的偏序关系 <,具体由以下方式定义:
- 如果用户在执行自己的操作 p 之前接收到操作 o ,则 o < p 。这表示他们按顺序执行 o 和 p 的情况。
- (传递性)如果 o < p 和 p < q ,则 o < q 。
我们的操作历史通过从 o 到 p 绘制箭头来指示 o < p 。除此之外,我们省略了由传递性暗示的箭头 - 等效地,通过遵循一系列其他箭头。
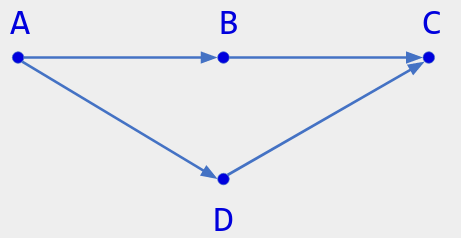
如图. 一名用户按顺序执行操作 A、B、C。
另一个用户收到A但未收到B后,执行D;
第一个用户在执行 D 之前收到该消息。
事件顺序为 A < B、A < C、A < D、B < C、D < C。在图中,隐含了 A < C 的箭头。
衍生术语:
- 当 o < p 时, o 因果先于 p 或 o 是 p 的因果前身,并且 p 因果大于 o 。
- 既没有 o < p 也没有 p < o 时, o 和 p 是并发的。
- 当 o < p 时,您还可能会看到短语“ o 发生在 p 之前”或“ p 因果地意识到 o ”。
- 如果 o < p ,并且不存在 r 使得 o < r < p ,则 o 是 p 的直接因果前驱。
- 操作历史中 通过箭头连接的对 (o, p) :所有 非直接因果前身 都由传递性暗示。
上图中,B 因果大于 A,因果先于 C,与 D 并发。C 的直接因果前驱是 B 和 D; A 是因果前驱,但不是直接前驱。
在 CRDT 设置中 跟踪因果顺序 很容易:通过其 直接因果前驱 (其传入箭头的尾部 )的 ID 来标记每个操作。
因此,当选择 “操作历史的纯函数”时,确保该函数查询因果顺序就可以了。我们将在多值寄存器中看到一个这样的例子。
通常,基于 CRDT 的应用程序会选择 强制执行因果 顺序传递:用户的应用程序在处理 任何因果上优先的操作之前,都不会处理下一个操作(更新应用程序的状态)。(相对于并发操作,一个操作可以以任何顺序被处理。)
换句话说,操作是按照因果顺序来处理的。这简化了编程,并通过提供 强因果一致性 的保证来让用户觉得合理。
例如,它确保如果一个用户向食谱中添加了一个配料,然后为这个配料编写了说明,那么所有用户都会在看到配料之后看到说明。
然而,有时你可能会选择放弃因果顺序传递——例如,当有撤销的操作时。(更多示例见第4部分)。
基本技术
我们从基本的语义技术开始。其中大多数并不是为 CRDT 发明的;
相反,它们是数据库技术或编程领域的传统知识。通常,你可以很容易地自己实现这些技术,或者在传统的CRDT框架之外使用它们。
Unique IDs (UIDs) 唯一ID(UID)
在引用一块内容时,为该内容分配一个不可变的唯一标识符(UID)。在涉及该内容的操作中,使用此UID,而不是使用可变的描述符(如列表中的索引)。
例如:在食谱编辑器中,为每个配料成分分配一个UID。当用户编辑某个配料的数量时,使用其UID来指示哪个配料。这解决了第一部分中的示例问题。
这里的“内容片段”指的是用户视为独立“事物”的任何文本,具有其长期的身份标识:如配料、电子表格单元格、文档等。请注意,内容可能在内部是可变的。其他类比包括:
- 在单用户应用程序中,任何将成为其自己对象的东西。其UID是该对象“指针”的分布式版本。
- 任何可以在 规范化数据库表 中获得 自己行的内容。它的 UID 充当主键。
为了确保 所有用户 对一个内容片段的 UID 达成一致,内容的创建者 应该在 创建时 分配 UID 并广播它。
例如,在相应的“添加配料”操作中包括新配料的 UID。即使多个用户同时创建 UID ,分配的 UID 也必须是唯一的;你可以通过使用UUID或第三部分中的dot IDs来确保这一点。
Append-Only Log 仅追加日志
使用 Append-Only Log 来 无限地 记录事件。这是一个只有 add(x) 操作 的 CRDT,其中 x 是与 事件一起存储 的不可变值。在内部,add(x) 被转换为操作 add(id, x),其中 id 是一个新的UID ( Unique ID );这能区分具有相同值的事件.
add(id, x) 事件组成 操作历史,所有 (id, x) 集合的键值对 就是 当前状态。
示例:在 配送追踪系统 中,每个包裹的 历史记录 都是一个 Append-Only 日志。 每个事件的值描述了 发生了什么(扫描、送达等)以及 时间。
该应用程序按 时间顺序 直接将 事件 展示给用户。
冲突的并发操作 表明 存在现实冲突,只能手动解决。
我通常认为仅追加日志是无序的,就像一个集合(尽管有“追加”这个词)。如果您确实希望以一致的顺序显示事件,则可以在值中包含时间戳并按该时间戳进行排序,或者使用列表 CRDT(如下)而不是仅附加日志。考虑使用 LWW 即 最后写入的最终一致性 中的逻辑时间戳,以便顺序与因果顺序兼容: o < p 意味着 o 出现在 p 之前。
关于 事件发生顺序内容 的 个人补充:
***物理时钟:***
- 基本概念: 计算机的系统时钟是一个频率精确和稳定的脉冲信号发生器,也称为"物理时钟"。对于传统的单机数据库,物理时钟的大小可以用来准确描述事件在当前物理机发生的先后关系。
- 存在问题: 在分布式系统中,各个节点分布在不同的物理位置,每个节点都有自己的物理时钟,即使采用 NTP 对各个设备的物理时钟进行同步,也有可能发生毫秒级的偏移。所以物理时钟 不能作为 分布式系统内 在不同节点上 并发执行的事务 的 排序依据。
***逻辑时钟:***
- 基本概念: 通过 happened-before 关系确定事件的 逻辑时钟,从而确定 事件的 偏序关系。
- 逻辑时钟 关键点 在于 定义事件 的先后关系,将 事件a 发生在 b 之前定义为 a→b。以下三种情况都满足 a→b:
- a和b是同一个进程内的事件,a发生在b之前,则a→b。
- a和b在不同的进程中,a是发送进程内的 发送事件,b是同一消息接收进程内的 接收事件,则a→b (先发送,再接收)。
- 如果a→b且b→c,则a→c (逻辑推导)。
- 如果a和b没有先后关系,则两个事件是并发的,记作a||b。
- 存在问题: 逻辑时钟算法 不能完全解决 两个事件 真正的 先后关系,只能对进程间的事件赋予逻辑意义的顺序。在分布式场景下,不同机器的时间可能存在不一致,没办法对跨节点的事件确定的先后关系。
***混合逻辑时钟 HLC :***
- 基本概念: 解决逻辑时钟和物理时钟之间的差距,支持因果关系,同时又有物理时钟直观的特点。HLC是将物理时钟和逻辑时钟结合起来的一种算法。HLC 由两部分值组成,即 物理时钟值 和 逻辑时钟值,可以表示为一个二元组 [l,c],其中l代表物理时钟值,c代表逻辑时钟值,例如[10,1]。
- 作用功能:
- 满足逻辑时钟的因果一致性 happened-before。
- 尽可能接近物理时钟PT,当物理时钟推进时,逻辑时钟部分被置零。
- (个人结合雪花算法理解,当millisecond重复时递增序列位, 推进时序列位归 0)。
- 记录时间的因果关系,保证和物理时钟的偏差是 bounded (范围内的) 。
- 消除中心节点,用本地的物理时间加上逻辑时间,为具备数据库定义的因果关系的事务排序。
- 可以替代 wall time使用。
Unique Set 唯一集
唯一集 类似于 仅附加日志,但它也允许删除。这是所有 动态增长和缩减的集合 的基础:集合、列表、某些映射等。
其操作是:
- add(x): 将操作 add(id, x) 添加到历史记录中,其中 id 是新的 UID。 (这与仅追加日志的 add(x) 相同,只是我们将条目称为元素而不是事件。)
- delete(id) ,其中 id 是要删除的元素的 UID。
给定操作历史,唯一 集的状态是 (id, x) 对的集合,这样存在 add(id, x) 操作但没有 delete(id) 操作。
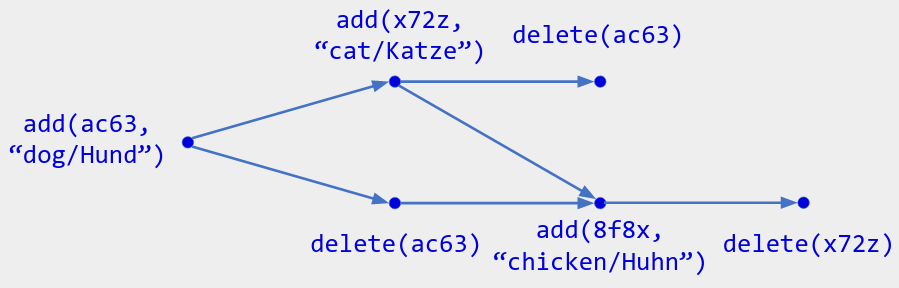
如图. 在一个协作式闪卡应用中,你可以将一组卡片表示为一个唯一的集合,使用 x 来存储闪卡的值(即其正面和背面的字符串)。用户可以通过 添加新卡 或 删除现有卡 来编辑牌组,并且允许 重复卡。根据上面的操作历史,当前状态是 { (8f8x, “chicken/Huhn”) } 。
您可以将 唯一集 视为处理 UID 标记内容 的直观方式。它类似于具有 插入 和 删除行 操作 的数据库表,使用 UID(=主键)来标识行。
或者,将 UID 视为分布式指针,add 和 delete 是 new 和 free 的分布式版本。
将 唯一集 的语义转换为 基于操作的 CRDT 很容易。
- 每个用户状态:文字状态,它是一组 (id, x) 对。(即 id+操作 键值对)。
- 操作 add(x) :生成新的 UID id ,然后广播 add(id, x) 。收到此消息后,每个用户(包括发起者)都会将 (id, x) 对添加到其本地状态。
- 操作 delete(id) :广播 delete(id) 。收到此消息后,每个用户都会删除具有给定 id 的对(如果它仍然存在)。注意:这是在假设因果顺序传递的前提上 - 否则,您可能会在 add(id, x) 之前收到 delete(id) ,然后忘记该元素已被删除。
基于状态的 CRDT 更加困难;第 3 部分将给出一个不平凡的优化算法。
Lists and Text Editing 列表和文本编辑
在 可协作文本编辑 中,用户可以在 有序列表 中插入(键入)和删除字符。 插入或删除一个字符会 改变 后面字符的索引,就像 JavaScript Array.splice 的风格一样。
CRDT 处理此问题的方法是:在键入每个字符时为其分配一个唯一的不可变列表 CRDT 位置。这些位置是一种特殊的 UID,是有序的:给定两个位置 p 和 q ,您可以询问是 p < q 还是 q < p 。那么文本的状态由下式给出:
- 按 position 对所有列表元素 (position, char) 进行排序。
- 按该顺序显示字符。
经典列表 CRDT 具有 insert 和 delete 操作,它们类似于唯一集的 add 和 delete 操作,只不过使用位置而不是通用 UID。文本 CRDT 是相同的,但具有单独的文本字符作为值。有关详细信息,请参阅之前的博客文章。
但真正的语义技术是 位置本身。抽象地说,它们是“不可变且有序的不透明事物”。为了满足用户的期望,列出 CRDT 位置必须满足一些规则(Attiya et al. 2016):
但真正的语义技术是这些位置本身。抽象来说,它们是“不可变且有序的不透明事物”。为了符合用户的期望,列表 CRDT 位置必须满足一些规则(Attiya等人,2016):
- 顺序是 整体 的:如果 p 和 q 是不同的位置,那么要么 p < q,要么 q < p,即使 p 和 q 是由不同用户并发创建的。
- 如果在一个用户的设备上存在一次 p < q,则所有用户的设备上 始终是 p < q 。例如:协作文本文档中的字符不会颠倒顺序,无论其周围的字符发生什么情况。
- 如果 p < q 且 q < r ,则 p < r 。即使 q 当前 不是 应用程序状态 的一部分,这一点也成立。
这个定义仍然给了我们一些选择 < 的自由。Fugue paper (我自己和 Martin Kleppmann,2023 年)给出了 < 的特定选择,并解释了么我们为什认为您应该更喜欢它而不是其他的。 Seph Gentle 的 Diamond Types 和 Braid 小组的 Sync9 各自独立地选择了几乎相同的语义(感谢 Michael Toomim 和 Greg Little 让我们注意到后者)。
List CRDT positions 是我们第一个 “真正的” CRDT 技术 - 它们不是来自 数据库技术 或 编程领域的传统知识,而且如何实现它们并不清楚。他们的算法以困难著称,但你通常只需要理解“唯一不可变位置”抽象,这很简单。您甚至可以在传统 CRDT 框架之外使用列表 CRDT 位置,例如使用我的 list-positions库。
Last Writer Wins (LWW 最后写入者获胜)
如果多个用户同时设置一个值,并且没有更好的方法来解决此冲突,只需选择“最后一个”值作为 结果。这就是 最后写入的最终一致性 LWW。
示例:两个用户同时更改共享白板中像素的颜色。使用 LWW 选择最终颜色。
传统上,“last” 意味着“最后到达中央数据库的值”。相反,在 CRDT 设置中,当用户执行操作时,他们自己的设备会为该操作分配时间戳。具有最大指定时间戳(时间戳越大表示操作越靠后)的操作获胜:其值显示给用户。
正式地说,LWW 寄存器是表示单个变量的 CRDT,是单一的操作 set(value, timestamp) 集合。
当给定这些 由 set 操作组成的操作历史记录,那么当前状态是具有最大 timestamp 的 value 。
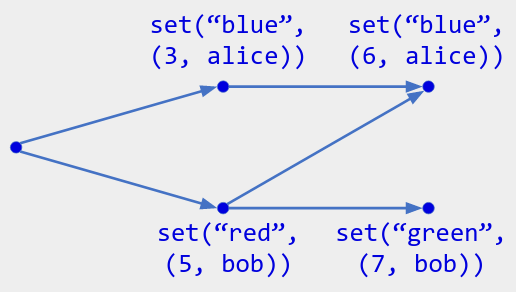
如图,使用 逻辑时间戳( (3, “alice”) 键值对)的 LWW 寄存器 的可能操作历史记录。
分配的最大时间戳是 (7, bob) ,因此当前状态为“绿色”。
时间戳通常应该是 逻辑时间戳,而不是文字挂钟时间(物理时间)(例如 Lamport 时间戳)。否则,时钟偏差 可能会导致令人困惑的情况:您尝试用 新值 覆盖 当前 本地值,但您的时钟 落后了,因此当前值仍然是获胜者。Lamport 时间戳也构建在决胜局中,以便获胜者永远不会模糊。
我们通过 将他们转换为 基于操作+基于状态的 混合 CRDT 来使 语义具体化,具体来说,我们将使用 T类型值的LWW 寄存器。
- 每个用户状态: state = { value: T, time: LogicalTimestamp } 。
操作 set(newValue) :广播 基于操作 的 CRDT 消息 { newValue, newTime } ,其中 newTime 是当前逻辑时间。收到此消息后,每个用户(包括发起者)都会:
- 如果 newTime > state.time ,则设置 state = { value: newValue, time: newTime } 。
- 基于状态的合并:要合并另一个用户的状态 other = { value, time } ,请将其视为 基于操作 的消息:if other.time > state.time ,set state = other 。
您可以检查state.value始终来自接收到的具有最大指定时间戳的操作,与我们上面的语义相匹配。
使用 LWW 时,要注意写入的粒度。例如,在幻灯片编辑器中,假设一个用户移动图像,而另一用户同时调整图像大小。如果您将这两个操作实现为写入单个 LWW Register <{ x, y, width, height }> ,那么一个操作将覆盖另一个操作 - 可能不是您想要的。
相反,使用两个不同的 LWW 寄存器,一个用于{ x, y } ,另一个用于{ width, height } ,以便这两个操作都能生效。
LWW Map LWW 映射
LWW 映射将最后写入者获胜规则应用于映射中的每个值。形式上,它的操作是 set(key, value, timestamp) 和 delete(key, timestamp) 。 当前映射内容由下式给出:
- 对于每个key ,找到 具有最大时间戳的key的操作。
- 如果操作是set(key, value, timestamp) ,则key处的值为value 。
- 否则(即操作是delete(key, timestamp)或没有对key进行操作), key 不存在于映射中。
请注意, delete操作的行为就像具有特殊值的set操作一样。特别是,在实现 LWW 映射时,忘记已删除的键是不安全的:您必须像往常一样记住它们的最新时间戳,以便将来进行 LWW 比较。否则,正如 Kleppmann (2022)所指出的,您的语义可能定义不明确(不是操作历史的纯函数)。
在下一节中,我们将看到另一种语义,它确实可以让您忘记已删除的键:多值映射。
Multi-Value Register 多值寄存器
这是另一种“真正的”CRDT 技术,也是我们第一个显式引用操作历史中的箭头的技术(正式地,因果顺序)。
当多个用户同时设置一个值时,有时您希望保留所有冲突的值,而不是仅仅应用 LWW。
示例:一名用户在电子表格单元格中输入一个复杂而强大的公式。同时,另一位用户手动计算出预期值并输入该值。如果第二个用户的写入抹掉了他们的辛勤工作,第一个用户会很恼火。
多值寄存器通过遵循以下规则来实现此目的:其当前值是尚未被覆盖的所有值的集合。具体来说,它有一个操作set(x) 。它的当前状态是其操作位于操作历史记录头部的所有值的集合(正式地,按因果顺序的最大操作)。例如,这里当前状态是{ “gray”, “blue” } :
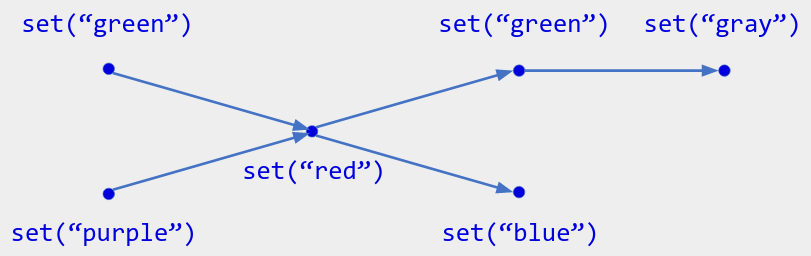
多值(也称为冲突)很难显示,因此您应该默认显示一个值。该显示值可以任意选择(例如LWW),或者通过某种语义规则选择。例如:
- 在错误跟踪系统中,如果错误有多个相互冲突的优先级,则显示最高的优先级(Zawirski et al. 2016) 。
- 对于布尔值,如果任意多个值为 true,则显示 true。这会产生启用获胜标志CRDT。或者,如果任何多值为 false,则显示 false( disable-wins 标志)。
其他多值可以根据需要显示,例如在Pixelpusher中,或者只是隐藏。
与LWW一样,要注意写入的粒度。
多值寄存器听起来很难实现,因为它引用了因果顺序。但实际上,如果您的应用程序强制执行因果顺序传递,那么您可以轻松地在唯一集之上实现多值寄存器。
- 每用户状态:一组唯一的uSet对(id, x) 。多值都是x。
- 操作set(x) :在本地循环uSet ,对每个现有元素调用uSet.delete(id) 。然后调用uSet.add(x) 。
说服自己这给出了与上面相同的语义。
Multi-Value Map 多值映射
与 LWW 映射 一样,多值映射将多值寄存器语义应用于映射中的每个值。形式上,它的操作是 set(key, value) 和 delete(key) 。当前状态由下式给出:
- 对于每个key ,请考虑仅限于 set(key, value) 和 delete(key) 操作的操作历史记录。
- 其中,仅限于操作历史记录的头部。同样,这些是未被另一个key操作覆盖的操作。形式上,它们是因果顺序中的最大运算。
- key 处的值是头set操作中出现的所有值的集合。如果该集合为空,则映射中不存在key 。
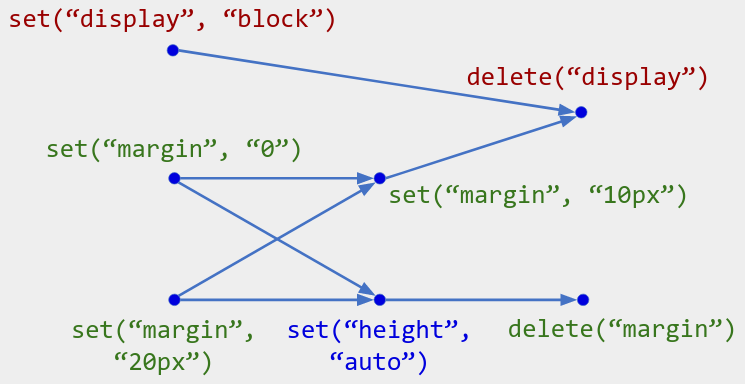
上图中 CSS 类上的多值映射操作。显然,键 “height” 映射到单个值 “auto” ,而键 “display” 不存在于地图中。对于键 “margin”,观察限制其操作时,只有 set(“margin”, “10px”) 和 delete(“margin”) 是操作历史的头部(即不被覆盖);因此 “margin” 映射到单个值“10px”。
与多值寄存器一样,每个当前键都可以有一个默认显示的显示值。例如,您可以将 LWW 应用于多值。这提供了类似于 LWW 映射的语义,但是当您将其实现为基于操作的 CRDT 时,您可以忘记已删除的值。 (提示:在如上所述的唯一集之上实现多值映射。)
Composition Techniques 组合技巧
接下来我们继续讨论构图技巧。这些从现有的 CRDT 中创建新的 CRDT。
与从头开始制作 CRDT 相比,组合有几个好处:
- 从语义上讲,可以保证组合输出实际上是 CRDT:它的状态始终是操作历史记录的纯函数(即,接收到相同操作集的用户处于等效状态)。
- 从算法上来说,您可以从组件中“免费”获得基于操作和基于状态的 CRDT 算法。这些组件可能已经经过优化和测试。
- 向一些基本的 CRDT 和组合技术添加新的系统功能(例如,撤消/重做)比直接将其添加到应用程序的顶级状态要容易得多。
特别是,使用在您关心的情况(例如,所有并发操作对)中表现良好的组合算法是安全的,即使您不确定它在任意复杂的场景中会做什么。您可以保证它至少满足强收敛性,并具有等效的基于操作与基于状态的行为。
与我们的大多数基本技术一样,这些组合技术并不是真正特定于 CRDT 的,您可以在传统 CRDT 框架之外轻松使用它们。 Figma 的协作系统就是一个很好的例子。
Views 视图
并非所有应用程序状态都有良好的 CRDT 表示。但通常您可以将某些底层状态存储为 CRDT,然后将应用程序的状态计算为该 CRDT 状态的视图(纯函数)。
示例:假设 协作文本编辑器 将其状态表示为 字符链接列表 。将链表直接存储为 CRDT 会带来麻烦:并发操作很容易导致断链、分区和循环。相反,存储传统的列表 CRDT,然后 构建 链表表示形式 作为 运行时的视图。
Objects 对象
将 CRDT 包装在特定于应用程序的 API 中是很自然的:当用户在应用程序中执行操作时,调用相应的 CRDT 操作;在 GUI 中,呈现 CRDT 状态的特定于应用程序的视图。
更一般而言,您可以通过将多个 CRDT 包装在单个 API 中来创建新的 CRDT。我称此为对象组合。各个 CRDT(组件)只是并排使用;它们不会影响彼此的操作或状态。
示例:我们在第 1 部分中看到的成分(如下所示)可以建模为三个 CRDT 的对象组合:一个用于文本的文本 CRDT 、一个用于数量的LWW 寄存器以及另一个用于单位的 LWW 寄存器。

为了区分组件 CRDT 的操作,请为每个组件分配一个不同的名称。然后用名称标记每个组件的操作:
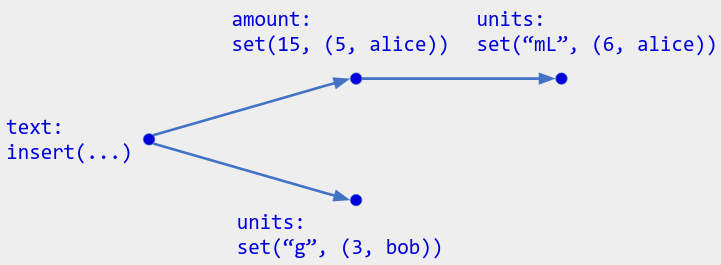
将组合 CRDT 视为一个字面CRDT 对象- 一个类,其实例字段是组件 CRDT:
class IngredientCRDT extends CRDTObject {
text: TextCRDT;
amount: LWWRegister<number>;
units: LWWRegister<Unit>;
setAmount(newAmount: number) {
this.amount.set(newAmount);
}
...
}
考虑组合状态的另一种方法是将名称映射到组件状态的 JSON 对象:
{
text: {<text CRDT state...>},
amount: { value: number, time: LogicalTimestamp },
units: { value: Unit, time: LogicalTimestamp }
}
感觉有点类似 时序数据库 的概念,每个metric(度量)中 field(域) 均包含一个时间戳。
Nested Objects 嵌套对象
你可以任意嵌套对象,实现分层的面向对象架构
class SlideImageCRDT extends CRDTObject {
dimensions: DimensionCRDT;
contents: ImageContentsCRDT;
}
class DimensionCRDT extends CRDTObject {
position: LWWRegister<{ x: number, y: number }>;
size: LWWRegister<{ width: number, height: number }>;
}
class ImageContentsCRDT ...
{
dimensions: {
height: { value: number, time: LogicalTimestamp },
width: { value: number, time: LogicalTimestamp }
},
contents: {
...
}
}
无论哪种方式,都使用通向其叶子 CRDT 的树路径来标记每个操作。例如,要将宽度设置为 75 像素: { path: “dimensions/width”, op: “set(‘75px’, (11, alice))” } 。
Map-Like Object 类映射对象
您可以允许从某个大集合(可能是无限的)中提取名称,而不是使用固定数量的具有固定名称的组件 CRDT。这为您提供了一种 CRDT 值映射的形式,我将其称为类映射对象。每个映射键用作其自身值 CRDT的名称。
示例:地理应用程序允许用户为地球上的任何地址添加描述。您可以将其建模为从地址到文本 CRDT 的映射。该映射的行为与每个地址都有一个文本 CRDT 实例字段的对象相同。
与 CRDT 对象的区别在于,在类似映射的对象中,您不必显式存储每个值 CRDT。相反,每个值 CRDT 在某种默认状态下隐式存在,直到使用为止。在 JSON 表示中,这会导致类似 Firebase RTDB 的行为,其中
{ foo: {/* Empty text CRDT */}, bar: {<text CRDT state...>} }
和
{ bar: {<text CRDT state...>} }
请注意,与普通 map 不同,类 map 对象没有 设置/删除 key 的操作;每个键 隐式地 始终存在,并具有预设值 CRDT。稍后我们将看到带有设置/删除操作的更传统的映射。
类似 Map 的对象 和 类似的 CRDT 通常被称为 “映射 CRDT” 或 “CRDT 值 映射”(我自己就是这样做的)。为了避免混淆,在本博客系列中,我将为具有设置/删除操作的地图保留这些术语。
Unique Set of CRDTs 唯一CRDT集
另一种组合技术使用 UID 作为值 CRDT 的名称。这给出了唯一的 CRDT 集。
其业务是:
- add(initialState) :将操作 add(id, initialState) 添加到历史记录中,其中 id 是新的 UID。这将创建一个具有 给定初始状态 的新值 CRDT。
- 值 CRDT 操作:任何用户都可以对任何值 CRDT 执行操作,并用值的 UID 标记。 UID 与对象组合的组件名称具有相同的功能。
- delete(id) ,其中 id 是要删除的值 CRDT 的 UID。
给定一个操作历史记录,CRDT 当前状态的唯一集合 由所有 添加值 CRDT 减去 已删除的 CRDT 组成,这些 CRDT 处于其当前状态(根据值 CRDT 操作)。正式:
for each add(id, initialState) operation:
if there are no delete(id) operations:
valueOps = all value CRDT operations tagged with id
currentState = result of value CRDT's semantics applied to valueOps and initialState
Add (id, currentState) to the set's current state
示例:在协作闪存卡应用程序中,您可以将一副卡片表示为一组独特的“闪存卡 CRDT”。每个闪存卡 CRDT 都是一个包含正面和背面文本 CRDT 的对象。用户可以通过添加新卡片(带有初始文本)、删除现有卡片或编辑卡片的正面/背面文本来编辑卡片组。这扩展了我们之前的闪存卡示例。
请注意,一旦删除了值 CRDT,它就会被永久删除。即使另一个用户同时对 CRDT 值进行操作,它仍会被删除。这允许实现在收到delete操作后回收内存 - 它只需要存储当前存在值的状态。但它并不总是最好的语义,因此我们将在下面讨论替代方案。
与唯一的(不可变)值集一样,您可以将唯一的 CRDT 集视为在 JSON 树中使用 UID 的明显方式。事实上, Firebase RTDB 的 Push 方法的工作原理与add类似。
// JSON representation of the flash card example:
{
"uid838x": {
front: {<text CRDT state...>},
back: {<text CRDT state...>}
},
"uid7b9J": {
front: {<text CRDT state...>},
back: {<text CRDT state...>}
},
...
}
唯一的一组 CRDT 还与您从规范化数据库表中获得的语义相匹配:一个表中的 UID;以 UID 作为外键在另一个表中进行 value CRDT 操作。 delete操作对应于外键级联删除。
Firebase RTDB 与唯一的 CRDT 集不同,因为它的删除操作不是永久性的 - 不会忽略对已删除值的并发操作,尽管该值的其余部分仍然被删除(留下一个尴尬的部分对象)。您可以通过与实际值分开跟踪尚未删除的 UID 集来解决此问题。显示状态时,循环遍历尚未删除的UID并显示相应的值(仅)。出于性能原因,Firebase 已经推荐这样做。
List of CRDTs CRDT 列表
通过修改唯一的 CRDT 集以使用列表 CRDT 位置而不是 UID,我们得到了CRDT 列表。它的值 CRDT 是有序的。
示例:您可以将第 1 部分中的成分列表建模为 CRDT 列表,其中每个值 CRDT 都是上面的成分对象。请注意,对特定成分的操作是用其位置(一种 UID)而不是其索引来标记的,正如我们在第 1 部分中预期的那样。
Composed Examples 组合示例
我们现在回过头来看 可以组合描述的 语义技术。
原则上,如果您的应用程序需要其中一种行为,您可以自己解决:考虑您想要的行为,然后使用上述技术来实现。在实践中,很高兴看到例子。
Add-Wins Set 新增胜利集
add-wins 集表示一组(非唯一)值。它的操作是add(x)和remove(x) ,其中x是T类型的不可变值。非正式地,它的语义是:
- 顺序add(x)和remove(x)操作的行为与集合的通常方式相同(例如Java 的HashSet )。
- 如果存在并发操作add(x)和remove(x) ,则 add “wins”: x在集合中。
示例:绘图应用程序包含自定义颜色调色板,用户可以添加或删除。您可以将其建模为一组附加的颜色。
非正式语义实际上并没有涵盖所有情况。这是使用组合的正式描述:
- 对于每个可能的值x ,存储一个多值寄存器,指示x当前是否在集合中。使用类似地图的对象来执行此操作,其键为值x 。在伪代码中: MapLikeObject<T, MultiValueRegister> 。
- add(x) 转换为操作“将x的多值寄存器设置为 true”。
- remove(x) 转换为操作“将x的多值寄存器设置为 false”。
- 如果x的任何多值为 true,则x位于集合中( enable-wins 标志语义)。这就是我们得到“add-wins”规则的方式。
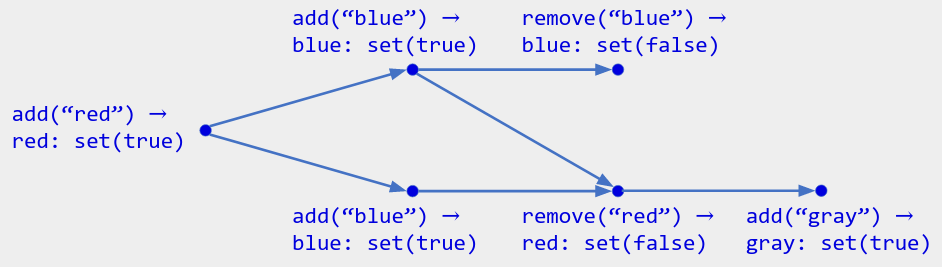
上图 调色板的 add-wins 颜色集的操作历史记录,显示(original op) -> (translated op) 。当前状态是 { “blue”, “gray” }:底部的 add(“blue”) 操作胜过并发的 remove(“blue”) 操作。
还有第二种方法可以使用组合来描述 add-wins 集的语义,但您必须假设因果顺序传递:
- 状态是一组唯一的条目(id, x) 。当前状态是至少出现在一个条目中的一组值x 。
- add(x)转换为 唯一集 add(x) 操作。
- remove(x)翻译为:本地循环遍历条目 (id, x) ;对于每一个,在唯一的集合上发出 delete(id) 。
名称 observed-remove set (add-wins set 的同义词)反映了此remove(x)操作的工作原理:它删除本地用户“观察到”的所有条目(id, x) 。
List-with-Move 可移动列表
上面的列表,固定每个元素在插入时的位置。这对于文本编辑来说很好,但对于其他协作列表,就需要频繁移动元素。而移动元素的过程,不应干扰该元素上的其它并发操作。
示例:在 协作菜谱 编辑器 中,用户应该能够使用 拖放操作 重新排列成分的顺序。 如果一个用户编辑一种成分的文本,而其他人同时移动它,这些编辑应该显示在移动的成分上,例如此处的拼写错误修复“Bredd”->“Bread”:
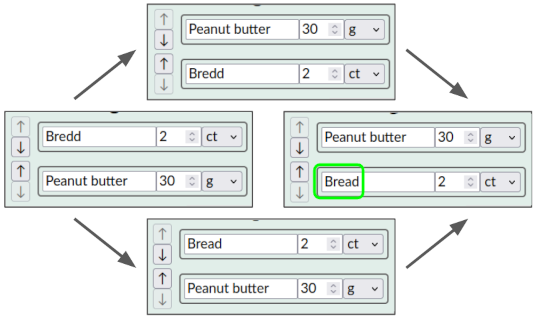
在这个例子中,直观地说,每种成分都有自己的身份。该身份与成分当前的位置无关;相反,位置是成分的可变属性。
这是实现这些语义的通用方法,即 list-with-move :
- 为每个列表元素分配一个UID ,与其位置无关。 (例如,将元素存储在唯一的 CRDT 集合中,而不是CRDT 列表中。)
- 为每个元素添加一个position属性,其中包含其在列表中的当前位置。
- 通过将元素的position设置到预期位置的新列表 CRDT 位置来移动元素。如果有并发移动操作,请将LWW应用于它们的位置。
// 伪代码
class IngredientCRDT extends CRDTObject {
position: LWWRegister<Position>; // List CRDT position
text: TextCRDT;
...
}
class IngredientListCRDT {
ingredients: UniqueSetOfCRDTs<IngredientCRDT>;
move(ingr: IngredientCRDT, newIndex: number) {
const newPos = /* new list CRDT position at newIndex */;
ingr.position.set(newPos);
}
}
Internally-Mutable Register 内部可变寄存器
上面的寄存器( LWW寄存器,多值寄存器)每个都代表一个不可变的值。但有时,您想要一个内部可变的值,但仍然可以像寄存器一样盲目设置 - 覆盖并发突变。
示例:公告板有一个“本月最佳员工”部分,其中显示员工的姓名、照片和文本框。同事可以编辑文本框表示祝贺;它使用 文本 CRDT 来允许同时编辑。经理可以更改当月的当前员工,覆盖所有三个字段。
如果经理更改了当前员工,而同事同时祝贺前任员工,则应忽略后者的编辑。
内部可变寄存器支持set操作和内部突变。它的状态包括:
- uSet ,一组唯一的 CRDT ,用于创建值 CRDT。
- reg ,一个单独的 LWW 或多值寄存器,其值为uSet中的 UID。
寄存器的可见状态是 reg 指示的值 CRDT 。您可以通过对该值 CRDT 执行操作来在内 部改变该值。要将值盲目设置为 initialState (覆盖并发突变),请使用uSet.add(initialState)创建一个新值 CRDT,然后将 reg 设置为其 UID。
创建新值 CRDT 是我们确保忽略并发突变的方法:它们适用于不再显示的旧值 CRDT。甚至可以从uSet中删除旧值 CRDT 以节省内存。
CRDT 值 map(next) 与应用于 map 中每个值的想法相同。
CRDT-Valued Map CRDT-Value映射
上面的 map-like object 没有设置/删除键的操作 - 它更像是一个对象而不是哈希映射。
这是一个CRDT 值映射,其行为更像是哈希映射。它的状态包括:
映射的可见状态是: key映射到 UID lwwMap[key]的值 CRDT。 (如果key不存在于lwwMap中,那么它也不存在于 CRDT 值映射中。)
操作:
- set(key, initialState)转换为{ uSet.add(initialState); lwwMap.set(key, (UID from previous op)); } 。也就是说,本地用户创建一个新值 CRDT,然后将key设置为其 UID。
- delete(key)转换为lwwMap.delete(key) 。通常,实现还会对key所有现有值 CRDT 调用uSet.delete ,因为它们不再可访问。
请注意,如果两个用户同时设置一个键,那么他们的set操作之一将“获胜”,并且 map 将仅显示该用户的值 CRDT。 (另一个值 CRDT 仍然存在于uSet中。)如果两个用户打算对“相同”值 CRDT 执行操作,合并他们的编辑,这可能会令人困惑。
示例:地理应用程序 允许用户向地球上的任何地址添加照片和描述。假设您将应用程序建模为从每个地址到 CRDT 对象的 CRDT 值映射{ photo: LWWRegister, desc: TextCRDT } 。
如果一个用户将照片添加到未使用的地址(必须先调用map.set ),而另一个用户同时添加描述(也调用map.set ),则一个CRDT对象将覆盖另一个:
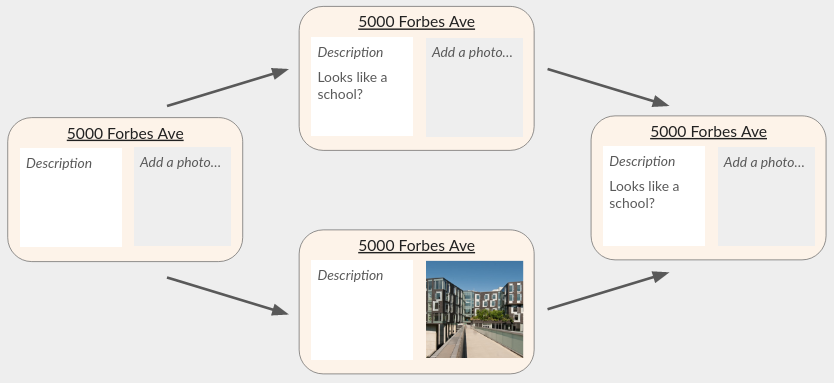
为了避免这种情况,请考虑使用map-like object,就像前面的地理应用程序示例一样。
与 CRDT 值映射类似 的 更多组合的结构:
- 相同,只是您不从 uSet 中删除值 CRDT。相反,它们被保存在档案中。您可以稍后通过再次调用 set(key, id) 来“恢复”值 CRDT,可能是在不同的 key 下。
- unique set of CRDTs ,其中每个值 CRDT 都有一个由 LWW 控制的可变 key 属性。这样,您可以更改 CRDT 的键值 - 例如,重命名文档。请注意,您的显示必须处理多个值 CRDT 具有相同键的情况。
Archiving Collections 存档集合
上面的 CRDT 值集合( unique set 、 list 、 map )都有一个delete操作,可以永久删除值 CRDT。
出于性能原因,使用此选项很好,但您通常需要 archive 操作,该操作仅 隐藏元素 直到其恢复。
(您可以通过将存档值交换到磁盘/云来恢复delete的大部分性能优势。)
示例:在具有跨设备同步功能的笔记应用程序中,用户应该能够查看和恢复已删除的笔记。这样,他们就不会意外丢失一个笔记。
要实现 存档/恢复,请向每个值添加 isPresent 字段。值以 isPresent = true 开头。操作 archive(id) 将其设置为 false, restore(id) 将其设置为 true。在 并发归档/恢复 操作的情况下,您可以应用 LWW ,或使用 多值寄存器 的显示值。
替代实现:使用单独的add-wins set来指示当前存在哪些值。
Update-Wins Collections 更新胜利集合
如果一个用户 归档了 另一个用户 仍在使用的值,您可以选择“自动恢复”该值。
示例:在电子表格中,一个用户删除一列,而另一用户同时编辑该列的某些单元格。第二个用户可能希望保留该列,如果该列自动恢复会更容易(Yanakieva、Bird 和 Bieniusa 2023)。
要在归档集合之上实现此功能,只需在本地用户每次编辑 id 的 CRDT 时调用 restore(id) 即可。因此每个本地操作都会转换为历史记录中的两个操作:原始(value CRDT)操作和 restore(id) 。
为了确保这些“keep”操作胜过并发归档操作,请使用 enable-wins 标志来控制 isPresent 字段。 (即,如果任何多值为 true,则多值寄存器的显示值为 true。)或者,使用最后一节的替代实现:一组 add-wins 当前值。
Spreadsheet Grid 电子表格网格
在电子表格中,用户可以 插入、删除 以及 移动行和列。也就是说,行集合的行为类似于列表,列集合也是如此。因此,单元格网格 是 列表的 二维模拟。
将网格建模为列表的列表是很迷人的。但是在某些情况下,这具有错误的语义。特别是,如果一个用户创建一个新行,而另一个用户同时创建一个新列,则交集处不会有单元格。
相反,您应该将状态视为:
- A list of rows. 行列表
- A list of columns. 列列表
- 对于每一对(行、列),一个单元格由该对(row id, column id)唯一标识。 row id 和 column id 是唯一的ID 。
单元格不是显式创建的;相反,只要行和列存在,状态就隐式包含这样的单元格。当然,在单元格被实际使用之前,它保持默认状态(空白)并且不需要存储在内存中。一旦用户的应用程序得知行或列已被删除,它就可以忘记单元格的状态,而无需显式的“删除单元格”操作 - 就像外键级联删除一样。
就上面的组合技术而言(objects, list-with-move, map-like object):
class CellCRDT extends CRDTObject {
formula: LWWRegister<string>;
...
}
rows: ListWithMoveCRDT<Row>;
columns: ListWithMoveCRDT<Column>;
cells: MapLikeObject<(rowID: UID, columnID: UID), CellCRDT>;
// Note: if you use this compositional construction in an implementation,
// you must do extra work to forget deleted cells' states.
Advanced Techniques 高级技术
本节中的技术更为先进。这实际上意味着它们来自较新的论文,而我对它们不太满意;他们的现有实现(如果有的话)也较少。
除了撤消/重做之外,您可以将这些视为附加的composed examples。它们的views 视图比前面的组合示例更复杂。
Formatting Marks (Rich Text) 格式标记富文本
富文本由纯文本加上内联格式组成:粗体、字体大小、超链接等。(本节不考虑块格式,如块引用或项目符号列表,稍后讨论。)
传统上,内联格式不适用于单个字符,而是适用于文本范围:从索引i到j所有字符。例如, atJSON (不是 CRDT)使用以下内容来表示影响字符 5 到 11 的粗体范围:
{
type: "-offset-bold",
start: 5,
end: 11,
attributes: {}
}
插入到跨度中间的未来字符应具有相同的格式。对于某些格式,对于在跨度末尾插入的字符也是如此。您可以通过在顶部应用新的格式范围来覆盖(部分)范围。
内联格式化 CRDT (inline formatting CRDT)允许您在 CRDT 设置中使用格式化跨度。 (我将此名称用于 Peritext CRDT 的特定部分(Litt et al. 2021) 。)它包括:
每个标记具有以下形式:
{
key: string;
value: any;
timestamp: LogicalTimestamp;
start: { pos: Position, type: "before" | "after" }; // anchor
end: { pos: Position, type: "before" | "after" }; // anchor
}
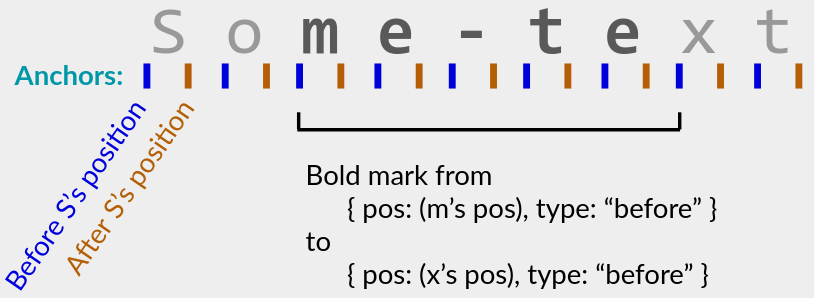
这里的timestamp是LWW的逻辑时间戳,而每个Position是一个列表CRDT位置。此标记将start和end之间的所有字符设置key value (例如"bold": true )。端点是存在于其pos之前或之后的锚点:
当多个标记影响同一个字符并具有相同的key时,LWW 生效: timestamp 最大的标记获 胜。特别是,新标记(通常是)覆盖旧标记。请注意,新标记可能仅覆盖旧标记范围的一部分。
形式上,标记日志的视图由下式给出:对于每个字符c ,对于每个格式键key ,找到满足最大时间戳的标记:
- mark.key = key ,并且
- 间隔(mark.start, mark.end)包含c的位置。
那么c在key处的格式值为 mark.value 。
注解:
- 要取消格式,请应用带有null的格式标记,例如{ key: “bold”, value: null, … } 。这与 LWW 中的其他“bold”标记竞争。
- 格式标记不仅(因果地)影响其范围内的未来字符,而且还影响同时插入的字符:

- 锚点允许您选择标记是否“扩展”以影响其范围开头或结尾的未来和并发字符。例如,上图所示的粗体标记在末尾扩展:在e和x之间键入的字符仍将在标记的范围内,因为标记的末尾附加到x 。
- 标记日志的视图很难有效地计算和存储。第 3 部分将描述一个优化视图,该视图可以增量维护,并且不会存储每个角色的元数据。
- 有时,根据本地规则,新字符应为粗体(等),但现有格式标记不会使其变为粗体。例如,在 MSWord 中段落开头插入的字符会继承后续字符的格式,但内联格式 CRDT 不会自动执行此操作。
为了解决这个问题,当用户键入新字符时,请根据本地规则计算其格式。 (大多数富文本编辑器库已经这样做了。)如果内联格式 CRDT 当前为该字符分配了不同的格式,请通过向日志添加新标记来修复它。
对 (5) 的花哨扩展:通常本地规则是在某个方向“扩展”格式标记 - 例如,从段落的前一个起始字符向后“扩展”。您可以找出正在扩展的标记,然后重用其timestamp而不是创建新的时间戳。这样,LWW 对于您的新标记和它所扩展的标记的行为是相同的。
Spreadsheet Formatting 电子表格格式
您还可以将内联格式应用于非文本列表。例如,Google 表格允许您将一系列行加粗,其行为与一系列粗体文本类似:该范围中间或末尾的新行也是粗体。粗体行中的单元格呈现为粗体,除非您覆盖该单元格的格式。
更详细地说,这是电子表格格式的一个想法:
使用两种内联格式化 CRDT,一种用于行,一种用于列。此外,对于每个单元格,存储格式键值对的LWW map;当用户格式化单个单元格时改变映射。要计算单元格当前的粗体格式,请考虑:
- 单元格行的当前(最大时间戳)粗体标记。
- 其列的当前粗体标记。
- 单元格自己的 LWW map 中键“bold”处的值。
这个想法允许您分别设置行、列和单元格的格式。顺序格式化操作以预期的方式交互:例如,如果用户将行加粗,然后取消列的粗体,则相交的单元格不会加粗,因为列操作具有较大的时间戳。
Global Modifiers 全局修饰符
通常,您希望一个操作 “为集合的每个” 元素执行某些操作,包括同时添加的元素。
示例:内联格式标记会影响其范围内的每个字符,包括同时插入的字符(参见上文)。
示例:假设食谱编辑器有一个“将食谱减半”按钮,可将每种成分的数量减半。这应该具有语义:对于每种成分的量,包括同时设置的量,将其减半。如果你不将并发设置操作减半,配方可能会不成比例:
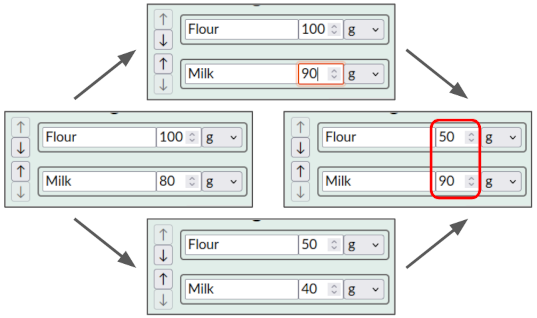
我之前讨论过这些 for-each 操作,并与人合着了一篇论文,将它们形式化(Weidner et al. 2023) 。然而,到目前为止的描述询问了因果顺序(如下),使得它们难以实现。
相反,我目前建议使用 global modifiers 来实现这些示例。我所说的 “global modifiers” 是指影响集合/范围的所有元素的状态:因果地先验、并发和(因果地)未来。
上面的内联格式标记具有以下形式:标记影响其范围内的每个字符,无论其何时插入。如果用户决定未来的字符不应受到影响,则该用户可以用新的字符覆盖格式标记。
要实现“将食谱减半”示例:
- 将 global scale 与食谱一起存储。这是由 LWW 控制的数字,您可以将其视为份数。
- 将每种成分的数量存储为与比例无关的数字。您可以将其视为每份的量。
- 该应用程序显示每种成分含量的产品 ingrAmount.value * globalScale.value 。
- 要将配方减半,只需将全局比例设置为其当前值的一半: globalScale.set(0.5 * globalScale.value) 。这会将所有显示的量减半,包括同时设置的量和同时添加的成分。
- 当用户设置金额时,本地计算相应的与比例无关的金额,然后进行设置。例如,如果他们将面粉从 50 克更改为 55 克,但全局比例为 0.5,请改为调用ingrAmount.set(110) 。
在菜谱编辑器中,您甚至可以使全局规模变得非协作:每个用户选择在自己的设备上显示多少份量。但所有协作编辑都会在内部影响相同的单份菜谱。
Forests and Trees 森林和树
许多应用程序都包含 tree 或 forest 结构。森林是的树的集合,树是断开连接的森林节点
典型的操作是创建新节点、删除节点和移动节点(更改其父节点)。
示例:文件系统是一棵树,其叶子是文件,内部节点是文件夹。 Figma 文档是渲染对象的树。
CRDT 表示树或森林的方式是:每个节点都有一个父节点,通过LWW设置。父节点可以是另一个节点、特殊的“根”节点(在树中)或“无”节点(在森林中)。您以明显的方式将树/森林计算为这些子->父关系(边)的视图。
当用户删除节点时(隐式删除其整个子树),实际上并不循环遍历子树删除节点。如果另一个用户同时将某些节点移入或移出子树,则会产生奇怪的结果。相反,仅删除顶部节点(或将其存档 - 例如,将其父节点设置为特殊的“垃圾”节点)。让用户查看已删除的子树并将节点移出其中是一个好主意。
到目前为止我所说的一切都只是基本技术的应用。循环使森林和树木变得先进:一个用户可能设置B.parent = A ,而同时另一个用户设置A.parent = B 。那么计算出的视图应该是什么就不清楚了。
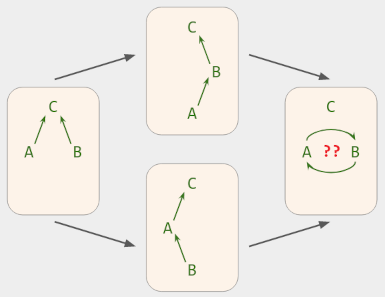
如上图 并发的树移动操作(每个操作各自有效)可能会创建一个循环。发生这种情况时,考虑到森林/树中不允许循环,应用程序应显示什么状态?
关于如何处理循环的一些想法:
- 错误。一些桌面文件同步应用程序在实践中会这样做( Kleppmann 等人(2022)给出了一个例子)。
- 在特殊的“超时”区域中渲染循环节点(及其后代)。它们将一直留在那里,直到某些用户手动修复循环。
- 使用服务器来处理移动操作。当服务器收到一个操作时,如果它会在服务器自己的状态下创建一个循环,服务器会拒绝它并告诉用户也这样做。这就是Figma 所做的。用户仍然可以乐观地处理移动操作,但在得到服务器确认之前,它们是暂时的。 (乐观更新可能会给用户带来暂时的循环;在这种情况下,Figma 使用策略(2):隐藏循环节点。)
- 类似,但使用拓扑排序(如下)而不是服务器的接收顺序。按排序顺序处理操作时,如果操作会创建循环,请跳过它(Kleppmann 等人,2022) 。
- 对于森林:在每个循环中,令B.parent = A为其set操作具有最大 LWW 时间戳的边。在渲染时,“隐藏”该边缘,而不是渲染B.parent = “none” ,但不更改实际的 CRDT 状态。这隐藏了创建循环的并发边之一。
- 为了防止未来发生意外,用户的应用程序应遵循以下规则:在执行任何会创建或销毁涉及隐藏边的循环的操作之前,首先通过执行设置B.parent = "none"操作来“确认”该隐藏边。
- 对于树:类似,只不过不是渲染B.parent = “none” ,而是渲染B的前一个父级 - 就好像不良操作从未发生过一样。更一般地说,您可能必须回溯多个操作。霍尔等人。 (2018)和奈尔等人。 (2022)描述了类似的策略。
Undo/Redo 撤消/重做
在大多数应用程序中,用户应该能够使用 Ctrl+Z / Ctrl+Shift+Z 在堆栈中撤消和重做自己的操作。您还可以允许选择性撤消(撤消历史记录中任何位置的操作)或组撤消(用户可以撤消彼此的操作) - 例如,用于恢复更改。
撤消操作的一种简单方法是:执行一个新操作,其效果在本地撤消目标操作。例如,要撤消键入某个字符,请执行删除该字符的新操作。
然而,这种“局部撤消”的语义并不理想。例如,假设一个用户发布了一张图像,撤消了它,然后重做了;在撤消/重做的同时,另一个用户对图像进行评论。如果您将重做实现为“创建一个具有相同内容的新帖子”,那么评论将会丢失:它附加到原始帖子,而不是重做的帖子。
相反,精确撤消使用以下语义:
- 除了正常的应用程序操作之外,还有操作 undo(opID) 和 redo(opID) ,其中 opID 标识正常操作。
- 对于每个 opID ,请考虑 undo(opID) 和 redo(opID) 操作的历史记录。 将一些布尔值 CRDT 应用于该操作历史记录来决定opID当前是(重新)完成还是撤消。
- 当前状态是将应用程序的语义仅应用于(重新)完成的操作的结果。
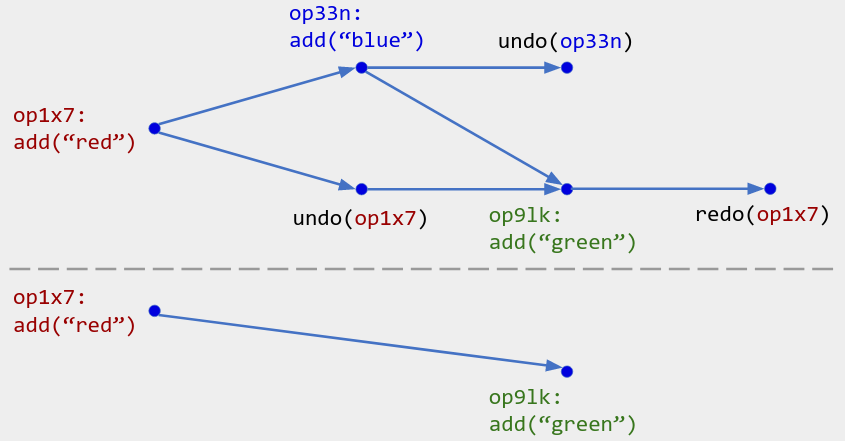
如上图上半部分:具有精确撤消功能的附加胜利集的操作历史记录。目前,op1x7 已重做,op33n 已撤消,op91k 已完成。
上图底部:我们仅过滤已(重新)完成的操作,并将过滤后的操作历史记录传递给 add-wins 集的语义,产生状态 { “red”, “green” }。
对于布尔值 CRDT,您可以使用LWW或多值寄存器的显示值(例如 redo-wins)。或者,您可以使用最大因果长度:第一个撤消操作是 undo(opID, 1) ;重做是 redo(opID, 2) ;再次撤消它是 undo(opID, 3)等;获胜者是数量最多的操作。 (相当于,最长的因果顺序操作链的头部 - 因此得名。)
最大因果长度作为一般布尔值 CRDT 是有意义的,但我只看到它用于撤消/重做。
第 3 步听起来更困难。您的应用程序可能会假设因果顺序传递,然后在撤消的操作违反它时给出奇怪的结果。 (例如,我们上面的多值寄存器算法将与撤消后的预期语义不匹配。)此外,大多数算法不支持从历史记录中删除过去的操作。但请参阅Brattli 和 Yu (2021),了解与精确撤消兼容的多值寄存器。
其他技术
本节提到了我个人认为不太有用的其他技术。有些是为分布式数据存储而不是协作应用程序而设计的;有些给出了合理的语义,但很难有效地实现;有些似乎很有用,但我还没有找到一个好的示例应用程序。
Remove-Wins Set 删除胜利集合
remove-wins 集与 add-wins 集类似,但如果存在并发操作 add(x) 和 remove(x) ,则 remove-wins: x不在集合中。
您可以使用类似于 add-wins 集的方式来实现此功能,使用 disable-wins 标志而不是 enable-wins 标志。 (请注意该集合以空开始,而不是包含所有可能的值。)或者,您可以使用以下方法实现删除获胜集:
- 已添加的所有值的 append-only log,以及
- 一个add-wins set,指示当前删除了哪些值。
一般来说,任何实现都必须存储所有已添加的值;这是更喜欢 add-wins 的实际原因。我也不知道有哪个示例应用程序让我更喜欢 remove-wins set 的语义。例外的是已经将所有值存储在其他地方的应用程序,例如archiving collection:我认为一组删除获胜的当前值将给出合理的语义。这相当于使用一组 add-wins 存档值,或者对每个值的isPresent字段使用一个 disable-wins 标志。
PN-Set 正负集合
PN set(Positive-Negative Set 正负集)是add-wins set的另一种替代方案。
其语义是:对于每个值x ,计算操作历史中 add(x) 操作的数量,减去 remove(x) 操作的数量;如果为正, x在集合中。
正如Shapiro 等人所描述的(2011a) ,这种语义在 面对并发操作 时 会给出奇怪的结果。 。例如,如果两个用户同时调用 add(x) 时,要想集合中删除 x ,必须调用 remove(x) 两次。如果两个用户同时执行此操作,它将与进一步的 add(x) 操作等进行奇怪的交互。
与 maximum causal length语义一样,PN-Set 最初是为 撤消/重做 而提出的。
Observed-Reset Operations观察复位操作
观察到的重置操作会取消所有先前的因果操作。也就是说,在查看操作历史记录时,您会忽略所有在任何 reset 操作之前有因果关系的操作,然后根据其余操作计算状态。
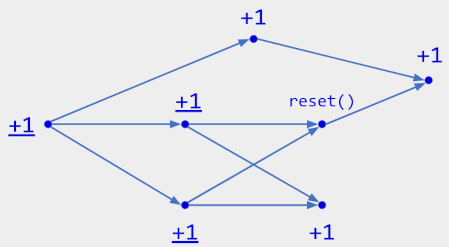
如上图:具有 +1 和 观察到的复位操作 的计数器的 操作历史记录。复位操作 取消了 下划线的+1 操作,因此当前状态为3。
观察重置操作是将 delete(key) 操作添加到 map-like object的一种诱人的方法:使 delete(key) 成为对 key 处的值 CRDT 的观察重置操作。因此, delete(key) 将值 CRDT 恢复到其原始的、未使用的状态,您可以将其视为“键不存在”状态。然而,如果一个用户调用 delete(key) 而另一个用户同时对 CRDT 值进行操作,你将以一种尴尬的部分状态结束:
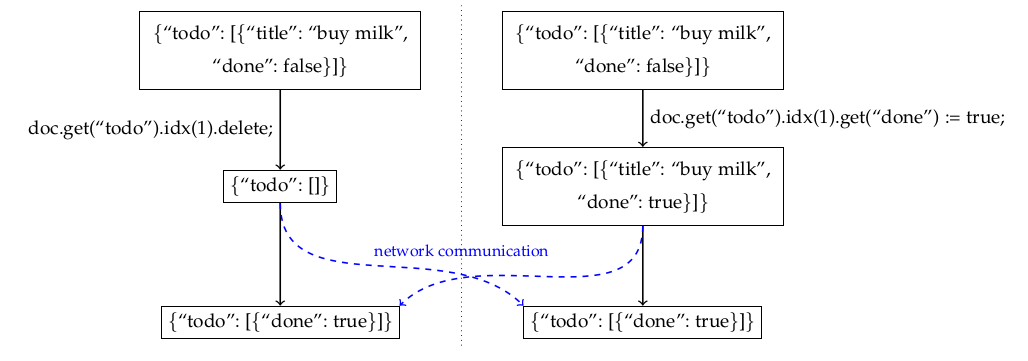
上图来源 Kleppmann 和 Beresford 。该论文描述了理论上的 JSON CRDT,但 Firebase RTDB 具有相同的行为。
相反,我更喜欢从类似地图的对象中完全省略delete(key) 。如果您需要删除,请改用CRDT-valued map或类似的映射。这些最终将 delete(key) 视为永久删除(从unique-set of CRDTs)或archive操作。
Querying the Causal Order 查询因果顺序
到目前为止,我们的大多数技术都不使用操作的 Causal Order(操作历史中的箭头)。然而,multi-value register 可以:它查询因果最大操作集,并显示它们的值。 Observed-reset operations 也会查询因果顺序,并且 add-wins set / remove-wins set 会间接引用它。
人们可以想象 CRDT 以多种方式查询因果顺序。然而,我发现这些对于实际使用来说太复杂了:
- 跟踪所有成对操作的因果顺序的成本很高。
- 询问“是否有与此并发的操作?”的语义。一般需要永久存储操作,以防以后出现并发操作。
- 创建语义规则很容易,但并非在所有情况下都表现良好。
(多值寄存器和add-wins集合占据了避免(1)和(2)的特殊情况。)
作为 条目(3) 的示例,很容易通过以下方式定义 add-wins: add(x)操作推翻任何并发的remove(x)操作,以便 add 获胜。但在图 9 的操作历史记录中,两个remove(x)操作都被并发的add(x)操作所否决。这使得x在不应该存在的情况下出现在集合中。
如上图 add-wins 集的操作历史记录。一位用户调用 add(x),然后调用 remove(x) ;同时,另一个用户也这样做。正确的当前状态是空集:x 上的因果最大操作都是 remove(x)。
作为另一个例子,您可能会尝试通过以下方式定义 add-wins 设置:如果存在并发的 add(x) 和 remove(x) 操作,则“首先”应用 remove(x) ,以便 add(x) 获胜;否则按因果顺序应用操作。但在上面的操作历史中,预期的操作顺序包含一个循环:
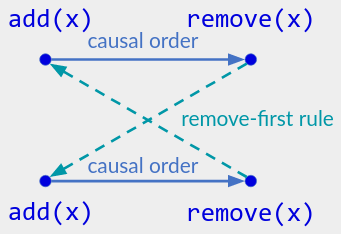
当一篇论文声称以新的方式 重现/理解 add-wins set 时,我总是尝试这个操作历史。
Topological Sort 拓扑排序
拓扑排序是从普通数据结构 “导出” CRDT 语义的通用方法。给定由普通数据结构操作组成的操作历史记录,当前状态定义为:
- 将操作排序为与因果顺序兼容的一致线性顺序( o < p意味着o出现在p之前)。例如,按 Lamport timestamp对它们进行排序。
- 按顺序将这些操作应用于起始状态,返回最终状态。如果某个操作无效(例如,它将在树中创建一个循环),请跳过它。
这些语义的问题是您不知道会得到什么结果 - 它取决于排序顺序,这是相当任意的。
然而,拓扑排序在复杂情况下可以作为后备,例如 tree cycles 或 群聊权限。您可以将其视为向中央服务器寻求帮助:排序顺序代表“操作到达服务器的顺序”。 (如果您有服务器,则可以使用它。)
Capstones 顶点
最后,我们为两个实用但复杂的协作应用程序设计新颖的语义。
Recipe Editor 食谱编辑器
我在几个例子中提到了协作菜谱编辑器。它以协作演示的形式实现:现场演示、演讲幻灯片、演讲视频、源代码。
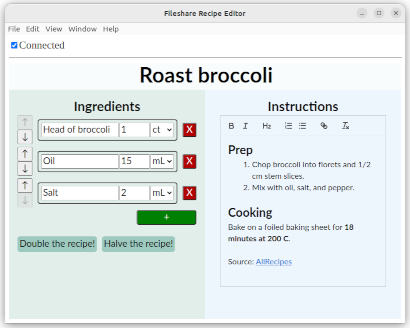
应用程序的语义可以使用nested objects进行组合描述。这是一个示意图:
{
ingredients: UniqueSetOfCRDTs<{
text: TextCRDT,
amount: LWWRegister<number>, // Scale-independent amount
units: LWWRegister<Unit>,
position: LWWRegister<Position>, // List CRDT position, for list-with-move
isPresent: EnableWinsFlag // For update-wins semantics
}>,
globalScale: LWWRegister<number>, // For scale ops
description: {
text: TextCRDT,
formatting: InlineFormattingCRDT
}
}
(按类名链接: UniqueSetOfCRDTs 、 TextCRDT 、 LWWRegister 、 EnableWinsFlag 、 InlineFormattingCRDT 。)
大多数 GUI 操作直接转换为此状态上的操作,但也有一些边缘情况。
- 成分列表是一个 list-with-move:移动操作(箭头按钮)设置position 。
- 删除操作(红色 X 的)使用 update-wins 语义:删除将isPresent设置为 false,而对成分的每个操作(例如,设置其数量)另外将isPresent设置为 true。
- 成分量,以及“双倍食谱!” /“把食谱减半!”按钮,将比例视为 global modifier。
Block-Based Rich Text 基于块的富文本
我们在上面描述了内联富文本格式,例如粗体和斜体。真正的富文本编辑器还支持块格式:标题、列表、块引用等。像Notion这样的精美应用程序甚至可以让您使用拖放来重新排列块的顺序:

让我们看看是否可以设计一个具有所有这些功能的 CRDT 语义:内联格式化、块格式化和可移动块。与 list-with-move 一样,移动块不应影响该块内的并发编辑。我们还希望在棘手的情况下有良好的行为 - 例如,一个用户移动一个块,而另一个并发用户将其分成两个块。
本部分是实验性的;如果我了解改进,我会在将来更新它(欢迎提出建议)。
CRDT 状态
CRDT 状态是一个具有多个组件的对象:
- text :text CRDT 。它存储纯文本字符以及两种不可见字符:块标记和钩子。每个块标记指示块的开始,而钩子用于放置已拆分或合并的块。
- format : text顶部的 inline formatting CRDT 。它控制文本字符的内联格式(粗体、斜体、链接等)。它对隐形角色没有影响。
- blockList :一个单独的列表 CRDT,我们将使用它来对块进行排序。它实际上没有内容;它只是作为 list CRDT positions 的来源。
- 对于每个块标记(由其列表 CRDT 位置作为键),一个块 CRDT对象具有以下组件:
- blockType :LWW 寄存器,其值为块的类型。这可以是“标题 2”、“块引用”、“无序列表项”、“有序列表项”等。
- indent :LWW 寄存器,其值是块的缩进级别(非负整数)。
- placement :我们稍后将解释的 LWW 寄存器。其值为以下之一:
- { case: “pos”, target: }
- { case: “origin”, target: <a hook’s list CRDT position> }
- { case: “parent”, target: <a hook’s list CRDT position>, prevPlacement: <a “pos” or “origin” placement value> }
Rendering the App State 渲染应用程序状态
现在让我们忽略blockCRDT.placement 。然后渲染由 CRDT 状态产生的富文本状态就很简单了:
-
每个块标记定义一个块。
-
该块的内容是text中紧随该块标记之后的文本,以下一个块标记结束。
-
该块根据其blockType和indent显示。
对于有序列表项,前导数字(例如“3”)是在渲染时根据有多少个前面的块是有序列表项来计算的。与 HTML 不同,CRDT 状态不存储显式的“列表开始”或“列表结束”。 -
块内的文本根据format进行内联格式。请注意,格式化标记可能会跨越块边界;这很好。如下图示例状态和渲染文本,省略blockList、钩子和blockCRDT.placement 。

现在我们需要解释blockCRDT.placement 。它告诉您如何相对于其他块对一个块进行排序,以及是否将其合并到另一个块中。
- 如果case为"pos" :该块独立存在。它相对于其他"pos"块的顺序由target在blockList中的位置给出。
- 如果case为"origin" :该块再次独立存在,但它跟随另一个块(其origin )而不是拥有自己的位置。具体来说,让块 A 为包含target的块(即, text中target之前的最后一个块标记)。在块 A 之后立即渲染此块。
- 如果case为"parent" :该块已合并到另一个块(其父块)中。具体来说,令块 A 为包含target块。将我们的文本渲染为块 A 的一部分,紧接在块 A 自己的文本之后。 (我们的blockType和indent被忽略。)

如上图 显示blockList 、钩子和blockCRDT.placement 。请注意,“Okay”是两个块“Ok”和“ay”的合并。
您可能会注意到这里有一些危险的边缘情况!我们很快就会解决这些问题。
移动、拆分和合并
现在我们可以实现三个有趣的块级操作:
-
Move。要移动块 B 使其紧跟在块 A 之后,首先在blockList中创建一个紧接在 A 位置(或其原点 (origin’s…) 位置)之后的新位置。然后将块 B 的placement设置为{ case: “pos”, target: } 。
- 如果有任何原点为 B 的块您不想与 B 一起移动,请执行额外的移动操作以将它们保留在当前显示的位置。
- 如果有任何原点为 A 的块,请执行额外的移动操作将它们移动到 B 之后,以便它们不会在 A 和 B 之间渲染。
- 边缘情况:要将块 B 移动到开头,请在blockList的开头创建位置。
-
Split。要将块分成两部分,请在拆分位置插入新的钩子和块标记(按顺序)。将新块的placement为{ case: “origin”, target: <new hook’s position> } ,并根据需要设置其blockType和indent 。
为什么我们指向一个钩子而不是前一个块的块头?基本上,我们希望遵循分割之前的文本,这可能有一天会出现在不同的块中。 (考虑前一个块再次分裂的情况,然后一半移动而另一块没有移动。)
-
Merge。要将块 B 合并到前一个块中,首先要找到当前渲染状态下的前一个块 A。 (这可能不是text中的前一个块标记。)在 A 渲染文本的末尾插入一个新钩子,然后将块 B 的placement为{ case: “parent”, target: <new hook’s position>, prevPlacement: <block B’s previous placement value> } .
“A 渲染文本的结尾”可能位于合并到 A 中的块中。
Edge Cases 边缘情况
它仍然需要解决渲染过程中的一些危险的边缘情况。
首先,两个块B和C有可能具有相同的起源块A。因此根据上述规则,它们都应该在块A之后立即渲染,这是不可能的。相反,按照它们的钩子在渲染文本中出现的顺序依次渲染它们。 (这可能与text中的钩子顺序不同。)
更一般地说,“块 B 具有源 A”的关系形成了一个森林。 (我相信永远不会有循环,所以我们不需要上面的先进技术。)对于森林中的每棵树,以深度优先的前序遍历顺序连续渲染该树的块。
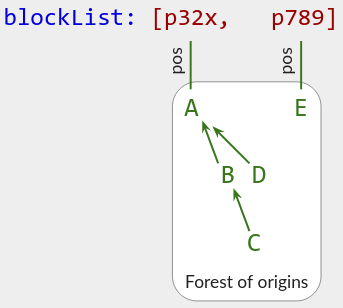
如上图 原始关系森林。这呈现为块顺序A, B, C, D, E 。请注意,树根A, E按它们在blockList中的位置排序。
其次,两个块 B 和 C 也可能具有相同的父块 A。 在这种情况下,将两个块的文本渲染为块 A 的一部分,同样按其钩子的顺序排列。
更一般地说,我们希望“块 B 有父 A”的关系形成一个森林。然而,这个时间循环是可能的!
如上图 一个用户将块 B 合并到 A 中。同时,另一个用户将 B 移动到 A 上方,然后将 A 合并到 B 中。现在他们的父关系形成一个循环。
为了解决这个问题,请使用 forests and trees t 的任何想法来避免/隐藏循环。我推荐想法 5的变体:在每个周期内,“隐藏”具有最大 LWW 时间戳的边,而不是渲染其prevPlacement 。 ( prevPlacement总是有 case “pos"或"origin” ,所以这不会创建任何新的循环。另外,我相信你可以忽略想法 5 关于“确认”隐藏边的句子。)
第三,为了确保始终至少有一个块,应用程序的初始状态应该是: blockList包含单个位置; text包含一个块标记,其placement = { case: “pos”, target: } 。
为什么移动块将其placement.target设置为blockList中的位置,而不是像Split/Merge这样的钩子?这让我们避免了另一种循环情况:如果块 B 移动到块 A 之后,同时块 A 移动到块 B 之后,则blockList会为它们提供明确的顺序,而无需任何花哨的循环破坏规则。
Validation 验证
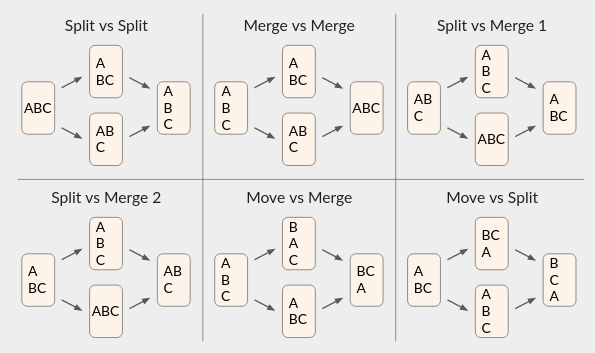
我不能保证这些语义在每种情况下都会给出合理的结果。但是按照组合技术中的建议,我们可以检查所有有趣的并发操作对,然后相信一般情况至少满足强收敛性(通过组合)。
下图显示了我认为在各种并发情况下会发生的情况。在每种情况下,它都符合我的首选行为。线条表示块,而 A/B/C 表示文本块。
Conclusion 结论
基于 CRDT 的应用程序的语义描述了在给定协作操作历史的情况下应用程序的状态应该是什么。选择语义最终是每个应用程序的问题,但 CRDT 文献提供了许多想法和示例。
这篇博文很长,因为确实有很多技巧。然而,我们看到它们大多只是一些基本概念( UIDs, list CRDT positions, LWW, multi-value register)加上组合示例。
仍然需要描述实现这些语义的算法。尽管我们提供了一些基本的内联 CRDT 算法,但还有其他细微差别和优化。这些将是下一篇文章第 3 部分:算法技术的主题。
CRDT Survey, Part 3: Algorithmic Techniques
Algorithmic Techniques 算法技巧
假设您已经按照第2部分的风格选择了协作应用程序的语义。也就是说,您选择了一个纯函数,它输入 操作历史记录 并输出 了解这些操作的用户的 预期状态。
这是一个简单的协议,可将这些语义转化为实际的协作应用程序:
- 每个用户的状态是一个文字操作历史记录,即一组操作,每个操作都由唯一ID (UID) 标记。
- 当用户执行操作时,他们会生成一个新的 UID,然后将(id, op)对添加到本地操作历史记录中。
- 为了同步他们的状态,用户可以按照他们喜欢的方式共享(id, op) 。例如,用户可以在创建对后立即广播对,定期点对点共享整个历史记录,或者运行巧妙的协议仅向对等方发送其丢失的对。收件人始终忽略冗余对(重复的 UID)。
- 每当用户的本地操作历史记录更新时(无论是通过本地操作还是远程消息),他们都会将语义(纯函数)应用于新历史记录,以产生当前应用程序可见的状态。
技术细节:
这篇文章描述了CRDT 算法技术,可帮助您实现上述简单协议的更高效版本。我们从一些在一般分布式系统中也有用的先决条件开始。然后同步策略描述了 CRDT 的传统“类型”——基于操作、基于状态等——以及它们与简单协议的关系。
其余部分描述具体算法。这些算法在很大程度上彼此独立,因此您可以跳到您感兴趣的任何内容。其他技术填补了第 2 部分中的一些空白,例如,如何生成逻辑时间戳。优化的 CRDT描述了重要的优化算法,包括经典的基于状态的 CRDT。
Prerequisites 先决条件
Replicas and Replica IDs 副本和副本 ID
副本是协作应用程序状态的单个副本,位于单个设备上的单个线程中。对于基于 Web 的应用程序,每个浏览器选项卡通常有一个副本;当用户(重新)加载选项卡时,会创建一个新副本。
您还可以将副本称为client、session、actor等。但是,副本并不等同于设备或用户。事实上,一个用户可以拥有多个设备,一个设备可以有多个独立更新的副本——例如,用户可以在多个浏览器选项卡中打开同一个协作文档。
在以前的帖子中,我经常出于懒惰而说“用户” - 例如,“两个用户同时执行 X 和 Y”。但从技术上讲,我总是指上述意义上的“复制品”。事实上,单个用户可以跨不同设备执行并发操作。
副本的重要性在于副本内的所有内容都按顺序发生,其自身操作之间没有任何并发性。这是接下来两种技术背后的基本原理。
通过在创建副本时生成随机字符串,通常可以方便地为每个副本分配一个唯一的副本 ID (客户端ID、会话ID、参与者ID)。副本ID在同一协作状态的所有副本中必须是唯一的,包括同时创建的副本,这就是为什么它们通常是随机的,而不是“迄今为止最高的副本ID加1”。随机UUID(v4)是一个安全的选择。如果您愿意容忍更高的意外非唯一性可能性(参见[生日问题(https://en.wikipedia.org/wiki/Birthday_problem#Simple_exponentiation)),则可以使用更少的随机位(更短的副本ID)。
作为参考,UUID v4 是 122 个随机位,Collabs replicaID是 60 个随机位(10 个 Base64 字符), Yjs clientID是 32 个随机位(uint32)。
避免在同一设备上的多个副本之间重复使用副本 ID,例如将其存储在 window.localStorage中。如果用户打开多个选项卡,或者发生崩溃故障并且旧副本未将其所有操作记录到磁盘,这可能会导致问题。
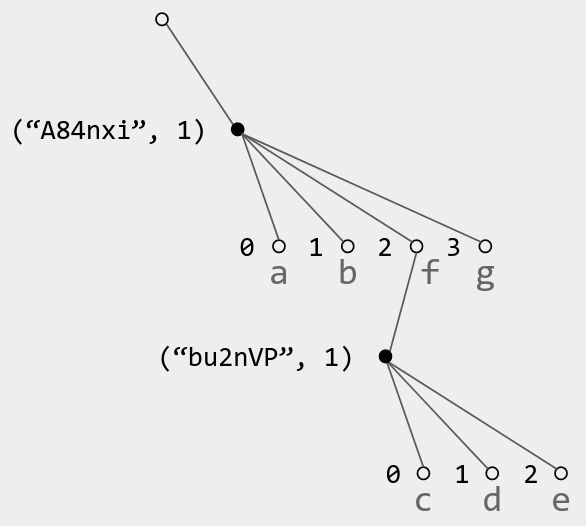
Unique IDs: Dots 唯一ID:点
回想第2部分,要引用一段内容,您应该为其分配一个不可变的唯一 ID (UID)。 UUID 可以工作,但它们很长(32 个字符)并且压缩效果不佳。
相反,您可以使用 dot IDs : (replicaID,counter)形式的对,其中 counter 是每次都会递增的局部变量。因此 ID 为"n48BHnsi"的副本使用点 ID (“n48BHnsi”, 1) , (“n48BHnsi”, 2) , (“n48BHnsi”, 3) , …
在伪代码中:
// Local replica ID.
const replicaID = <sufficiently long random string>;
// Local counter value (specific to this replica). Integer.
let counter = 0;
function newUID() {
counter++;
return (replicaID, counter);
}
dot ID 的优点是它们可以很好地压缩在一起,无论是使用普通的 GZIP 还是 dot-aware 编码。例如,矢量时钟表示一系列点 (“n48BHnsi”, 1), (“n48BHnsi”, 2), …, (“n48BHnsi”, 17) 作为单个映射条目{ “n48BHnsi”: 17 } 。
您可以灵活地分配计数器值。例如,您可以使用逻辑时钟值而不是计数器,以便您的 UID 也是LWW的逻辑时间戳。或者,您可以为组合结构中的每个组件 CRDT 使用单独的counter ,而不是为整个副本使用单独的计数器。重要的是永远不要在同一上下文中重复使用 UID,否则两种用途可能会混淆。
示例:仅 Append-OnlyLog在分配事件的 dot ID 时可以选择使用自己的 counter 。这样它可以将其状态存储为Map<ReplicaID, T[]> ,将每个副本 ID 映射到由(counter - 1)索引的该副本事件的数组。如果您使用由所有组件 CRDT 共享的 counter ,则数组可能会有间隙,从而导致 Map<ReplicaID, Map<number, T>> 更可取。
在之前的博客文章中,我将这些称为“因果点”,但我找不到其他地方使用过这个名称;相反,CRDT 论文只使用“点”。
Tracking Operations: Vector Clocks 1 跟踪操作:矢量时钟 1
矢量时钟是一种具有多种用途的理论技术。在本节中,我将重点关注最简单的一个:跟踪一组操作。(矢量时钟2稍后发布。)
假设副本知道以下操作 - 即,这是操作历史记录的当前本地视图:

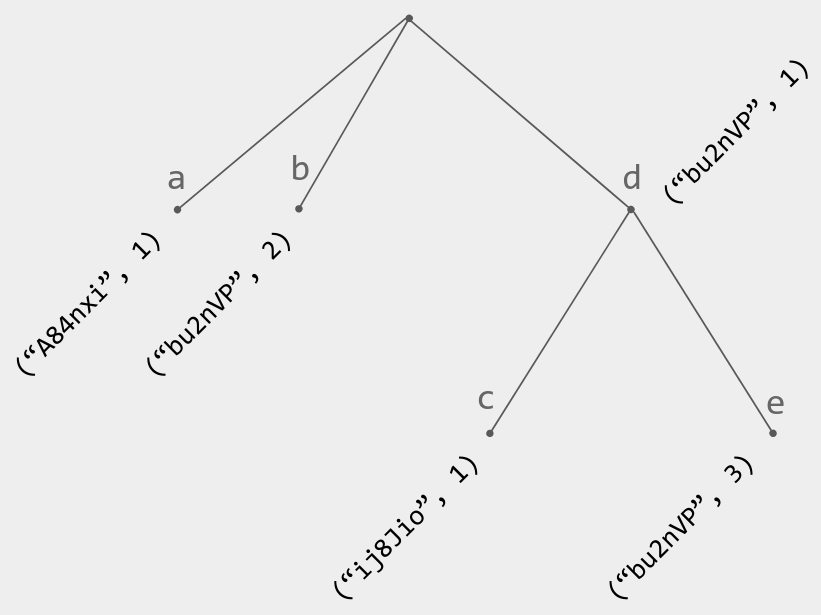
我用 dot ID 标记每个操作,例如(“A84nxi”, 2) 。
将来,副本可能想知道它已经知道哪些操作。例如:
- 当副本接收到网络消息中的新操作时,它将查找是否已经接收到该操作,如果是,则忽略它。
- 当副本与另一个协作者(或存储服务器)同步时,它可能首先发送它已经知道的操作的描述,以便协作者可以跳过发送冗余操作。
跟踪操作历史记录的一种方法是将操作的唯一 ID 作为一组存储: { (“A84nxi”, 1), (“A84nxi”, 2), (“A84nxi”, 3), (“A84nxi”, 4), (“bu2nVP”, 1), (“bu2nVP”, 2)} 。但存储“压缩”表示更便宜
{
"A84nxi": 4,
"bu2nVP": 2
}
这种表示形式称为矢量时钟。形式上,矢量时钟是一个 Map<ReplicaID,number>, 它将副本 ID 发送到从该副本接收到的最大计数器值,其中每个副本按从 1 开始的顺序将计数器分配给自己的操作(如dot ID)。丢失的副本 ID 隐式映射为 0:我们尚未收到来自这些副本的任何操作。上面的例子表明,矢量时钟有效地总结了一组操作ID。
上一段隐式假设您按顺序处理来自每个其他副本的操作:首先(“A84nxi”, 1) ,然后(“A84nxi”, 2)等。当您强制执行因果顺序传递时,这始终成立。如果不这样做,那么副本的计数器值可能会有间隙( 1, 2, 4, 7, … );您仍然可以使用游程长度编码或矢量时钟加上一组“额外” dot ID(称为 点矢量时钟)对它们进行有效编码。
与点 ID 一样,矢量时钟也很灵活。例如,您可以存储从每个副本接收到的最新逻辑时间戳,而不是每个副本计数器。如果每个操作已经包含LWW的逻辑时间戳,那么这是一个合理的选择。
Sync Strategies 同步策略
我们现在转向同步策略:使协作者彼此保持同步的方法,以便他们最终看到相同的状态。
Op-Based CRDTs 基于操作的 CRDT
基于操作(op-based)的 CRDT 通过在操作发生时广播操作来使协作者保持同步。 这种同步策略对于实时协作特别有用,因为用户希望快速查看彼此的操作。
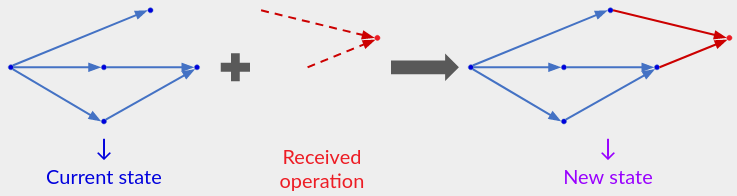
在本文顶部的简单协议中,用户通过将单个操作添加到其操作历史记录中来处理单个操作,然后重新运行语义函数以更新其应用程序可见状态。基于操作的 CRDT 存储的状态(通常)小于完整的操作历史记录,但它仍然包含足够的信息来呈现应用程序可见的状态,并且可以响应接收到的操作而增量更新。
示例:[第1部分])(https://mattweidner.com/2023/09/26/crdt-survey-1.html#op-based-crdts)中基于操作的计数器 CRDT 的内部状态仅仅是当前计数。 当用户接收(或执行) inc() 操作时,他们会增加计数。
形式上,基于 op 的 CRDT包括:
- 一组允许的 CRDT 声明副本可以位于其中。
- 返回应用程序可见状态的查询。
(CRDT 状态通常包含应用程序其余部分不可见的额外元数据,例如 LWW 时间戳。) - 对于每个操作( insert 、 set等):
- prepare函数,用于输入 操作的参数 并输出 描述该操作的消息。 外部协议承诺将此消息广播给所有协作者。 (通常此消息只是操作的翻译形式。允许 prepare 读取当前状态,但不能改变它。)
- 处理消息、更新本地状态的effect函数。外部协议承诺调用effect :
- 立即针对每个本地准备的消息,以便本地操作立即更新状态。
- 最终,对于每条远程准备的消息,恰好一次并且(可选)in causal order。
除了更新其内部状态之外,CRDT 库的 effect 函数通常还会发出 描述状态如何更改的事件。如第2部分中的Views。
要声明基于操作的 CRDT 实现给定的 CRDT 语义,您必须证明 应用程序可见状态 始终 等于应用于迄今为止生效的操作集 的语义。
作为示例,让我们重复第2部分中基于操作的唯一集 CRDT。
- 每用户 CRDT 状态:一组对(id, x) 。
- 查询:直接返回CRDT状态,因为在这种情况下,它与应用程序可见状态一致。
- 操作add :
- prepare(x) :生成一个新的 UID id ,然后返回消息(“add”, (id, x)) 。
- effect(“add”, (id, x)) :将(id, x)添加到您的本地状态。
- 操作delete :
- prepare(id) :返回消息(“delete”, id) 。
- effect(“delete”, id):从本地状态删除具有给定id的对(如果它仍然存在)。
很容易检查这个基于操作的 CRDT 是否具有所需的语义: 在任何时候查询都会返回 (id, x) 的集合,这样您就可以执行 add(id, x) 操作,但没有delete(id)操作。
请注意,CRDT 状态是 操作历史记录 的有损表示:我们不存储有关 delete 操作或 删除的 add 操作的任何信息。
“外部协议”(即应用程序的其余部分)如何保证消息最多执行一次并按因果顺序执行?使用历史跟踪矢量时钟:
- 在每个副本上,存储一个矢量时钟,跟踪迄今为止已生效的操作。
- 当副本请求发送准备好的消息时,请在广播该消息之前将新的 dot ID 附加到该消息。还要附上其 直接因果前身 的 dot ID。
- 当副本收到消息时:
- 根据本地矢量时钟检查其 dot ID 是否冗余。如果是这样,请停止。
- 根据本地矢量时钟检查直接因果 dot ID 是否已受到影响。如果没有,则阻止直到它们为止。
- 下发消息effect并更新本地矢量时钟。对任何新解锁的消息执行相同的操作。
为了确保消息最终至少传递到每个副本一次(恰好一次的另一半),通常需要网络的一些帮助。例如,让服务器存储所有消息并重试传递,直到每个客户端都确认收到。
最后一点,假设两个用户同时执行 操作o和p 。 您可以以任一顺序传递基于操作的消息以 effect , 而不会违反因果顺序传递保证。从语义上讲,两个交货订单必须产生相同的内部状态:两个结果对应于相同的操作历史记录,包含o和p 。因此,对于基于 op 的 CRDT,并发消息是可以交换的。
反过来,您可以证明,如果一个算法具有 基于操作的 CRDT 的 API 并且并发消息交换,那么它的行为对应于某些 CRDT 语义(即操作历史的某些纯函数)。这导致了基于操作的 CRDT 的传统定义是通勤并发操作。当然,如果你只证明交换性,并不能保证相应的语义在你的用户眼中是合理的。
State-Based CRDTs 基于状态的 CRDT
基于状态的 CRDT 通过 偶尔交换 整个状态、“合并” 他们的 操作历史 来保持 用户同步。这种 同步策略 在对等网络(对等体 偶尔 会交换状态 以使彼此 保持最新状态)以及 客户端和服务器之间的初始同步(客户端将其本地状态与服务器的状态合并)中非常有用。最新状态,反之亦然)。
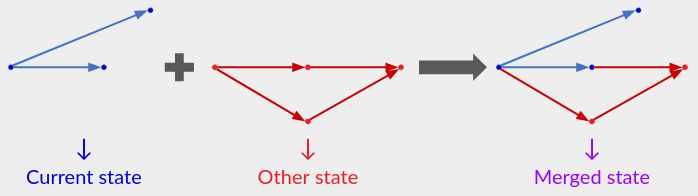
在本文顶部的简单协议中,“整个状态”是文字操作历史记录,合并只是操作的集合并(使用 UID 来过滤重复项)。基于状态的 CRDT 存储的状态(通常)小于完整的操作历史记录,但它仍然包含足够的信息来呈现应用程序可见的状态,并且它可以与另一个状态“合并”。
形式上,基于状态的 CRDT包括:
- 一组允许的CRDT 声明副本可以位于其中。
- 返回应用程序可见状态的查询。 (CRDT 状态通常包含应用程序其余部分不可见的额外元数据,例如 LWW 时间戳。)
- 对于每个操作,都有一个更新本地状态的状态变更器。
- 输入两个状态并输出“合并”状态的合并函数。使用 CRDT 的应用程序可以设置 local state = merge(local state, other state) 任何时候, other state通常来自远程协作者或存储。
要声明基于状态的 CRDT 实现给定的 CRDT 语义,您必须证明 应用程序可见的状态 始终等于 应用于 促成当前状态的操作集 的语义。这里,一个操作 “贡献”其状态 变异器的输出,加上 该状态产生的未来状态(例如,该状态与另一个状态的合并)。
作为示例,让我们重复第2部分中 LWW 寄存器的基于状态的部分。
- 每用户状态: state = { value, time } ,其中time是逻辑时间戳。
- 查询:返回state.value 。
- 操作set(newValue) :设置 state = { value: newValue, time: newTime } ,其中newTime是当前逻辑时间。
- 在其他状态合并:选择具有最大逻辑时间戳的状态。也就是说,如果 other.time > state.time ,则设置 state = other 。
很容易检查这个基于状态的 CRDT 是否具有所需的语义: 在任何时候,查询都会返回与对当前状态有最大逻辑时间戳的set操作相对应的值。
最后一点,请注意,对于任何 CRDT 状态s, t, u ,以下代数规则都成立,因为同一组运算对每个方程的两边都有贡献:
- (幂等性) merge(s, s) = s 。
- (交换性) merge(s, t) = merge(t, s) 。
- (结合性) merge(s, (merge(t, u))) = merge(merge(s, t), u) 。
因此,对于基于状态的 CRDT,合并函数是关联函数、交换函数和幂等函数 (ACI) 。
反过来,您可以证明,如果一个算法具有基于状态的 CRDT 的 API 并且满足 ACI,那么它的行为对应于某些CRDT 语义(即操作历史的某些纯函数)。这导致基于 ACI 合并功能的基于状态的 CRDT 的传统定义。当然,如果你只证明这些代数规则,并不能保证相应的语义在你的用户眼中是合理的。
Other Sync Strategies 其他同步策略
在真正的 协作应用程序 中,选择 基于操作 或 基于状态 的同步是不方便的。 最好在同一个会话中同时使用两者。
示例:当用户启动您的应用程序时,首先与存储服务器进行基于状态的同步以实现同步。然后使用 TCP 上基于 op 的消息来保持同步,直到连接断开。
因此,支持两种同步策略的 基于操作/基于状态的混合 CRDT 在实践中很受欢迎。
它们要么是基于状态的 CRDT,附加了基于操作的消息(Yjs、Collabs),
要么它们使用 基于操作的 CRDT 以及完整的操作历史记录(自动合并)。
要在后一种方法中执行 基于状态的合并,您需要查看接收到的 状态历史记录 以查找历史记录中尚未存在的操作,并将这些操作传递给基于操作的 CRDT。这种方法很简单,并且带有内置的版本历史记录,但需要付出更多努力才能提高效率(正如 Automerge 一直追求的那样)。
其他同步策略使用优化的点对点同步。传统上,对等同步使用基于状态的 CRDT:每个对等点将其自身状态的副本发送给另一个对等点,然后合并到接收到的状态。如果状态重叠很多,这是低效的 - 例如,两个对等点刚刚在一分钟前同步,并且此后仅稍微更新了其状态。像Yjs 的同步 Potocol 或 拜占庭因果广播 这样的优化协议使用来回消息来确定另一个对等点丢失了哪些信息并发送该信息。
有关混合或优化同步策略的学术工作,请查找基于 delta 状态的 CRDT (也称为delta CRDT )。它们就像混合 CRDT,增加了技术要求,即基于 op 的消息本身就是状态(特别是,它们被输入到基于状态的合并函数而不是单独的effect函数)。请注意,一些论文关注新颖的同步策略,而另一些论文则关注如何容忍非因果顺序消息的正交问题。
Misc Techniques 杂项技术
本文的其余部分描述了具体的算法。我们从实现 第 2 部分 中的一些语义所需的各种技术开始:LWW 的两种逻辑时间戳,以及查询因果顺序的方法。
这些都是传统的分布式系统技术,并非特定于 CRDT。
LWW: Lamport Timestamps LWW:兰波特时间戳
回想一下,对于最后写入者获胜 (LWW)值,您应该使用 逻辑时间戳而不是挂钟时间。 Lamport 时间戳是一个简单且常见的逻辑时间戳,定义为:
- 每个副本都存储一个时钟值time ,它是一个初始为 0 的整数。
- 每当执行 LWW set 操作时,都会增加 time 并将其新值作为 (time, replicaID) 对 的一部分附加到该操作。这对称为 Lamport 时间戳。
- 每当您在操作中从另一个副本收到 Lamport 时间戳时,请设置 time = max(time, received time) 。
- Lamport 时间戳的总顺序由下式给出: (t1, replica1) < (t2, replica2) 如果t1 < t2或( t1 = t2且replica1 < replica2 )。也就是说,时间较长的操作“获胜”,使用副本 ID 上的任意顺序打破平局。

如上图 操作历史记录,其中每个操作都标有 Lamport 时间戳。
Lamport 时间戳有两个重要的属性(第 2 部分中提到):
- 如果 o < p 按因果顺序,则 (o’s Lamport timestamp) < (p’s Lamport timestamp) 。因此,新的 LWW set总是胜过所有因果先验set 。
- 请注意,相反的情况不成立:有可能 (q’s Lamport timestamp) < (r’s Lamport timestamp) 但q和r是并发的。
- 由不同用户创建的 Lamport 时间戳始终是不同的(因为replicaID决定因素)。因此,胜利者从来都不是含糊的。
LWW: Hybrid Logical Clocks LWW:混合逻辑时钟
混合逻辑时钟是另一种逻辑时间戳,结合了 Lamport 时间戳 和 挂钟时间 的特征。我没有资格写这些,但 Jared Forsyth 在这里给出了可读的描述: https://jaredforsyth.com/posts/hybrid-logic-clocks/ 。
哈?
Querying the Causal Order: Vector Clocks 2 查询因果顺序:矢量时钟2
第 2 部分的“其他技术”之一是查询因果顺序。例如,访问控制 CRDT 可以包含类似“如果 Alice 执行某项操作但管理员同时禁止她,则将 Alice 的操作视为未发生”之类的规则。
我在第 2 部分中提到,除了某些特殊情况外,我发现这种技术对于实际使用来说太复杂了。尽管如此,这里还是有一些实现因果顺序查询的方法。
形式上,我们的目标是:给定两个操作o和p ,回答查询“ o < p是否按因果顺序排列?”。更狭义地说,CRDT 可能会查询o和p是否并发,即既不是o < p也不是p < o 。
回想一下上面的内容,矢量时钟 是一个映射,它将副本 ID 发送到从该副本接收到的最大计数器值,其中每个副本按从 1 开始的顺序将计数器分配给自己的操作(如点 ID)。除了在每个副本上存储一个矢量时钟之外,我们还可以为每个操作附加一个矢量时钟:即发送时发送者的矢量时钟。 (发送者自己的条目会递增以说明操作本身。)

如上图 操作历史记录,其中每个操作均由其点 ID(蓝色斜体)和 矢量时钟(红色普通文本)标记。
通过以下方式定义向量时钟的偏序:
v < w 如果对于每个副本 ID r , v[r] <= w[r] ,
并且对于至少一个副本 ID, v[r] < w[r] 。
(如果映射中不存在r ,则将其值视为 0。)
然后,操作的因果顺序与其矢量时钟的部分顺序相匹配是一个经典结果。
因此,存储每个操作的矢量时钟可以让您稍后查询因果顺序。
示例:在上图中, { A84nxi: 1, bu2nVP: 1 } < { A84nxi: 4, bu2nVP: 2 } ,
匹配其操作的因果顺序。同时, { A84nxi: 1, bu2nVP: 1 }和{ A84nxi: 2 }没有可比性,这符合它们的操作是并发的事实。
通常您只需要查询新操作的因果顺序。即您刚刚收到操作 p ,并且想要将其与现有操作 o 进行比较。为此,知道 o 的 dot ID (replicaID, counter)就足够了:
如果 counter <= p.vc[replicaID] ,则 o < p ,否则它们是并发的。 因此,在这种情况下,您不需要存储每个操作的矢量时钟,只需存储它们的 dot ID(尽管您仍然必须通过网络发送矢量时钟)。
如果您不假设因果订单交付,则上述讨论会略有变化。参见维基百科的更新规则。
我们有一个性能问题:矢量时钟的大小与过去的副本数量成正比。在协作应用程序中,这个数字往往会无限增长:每个浏览器选项卡都会创建一个新的副本,包括刷新。因此,如果您将矢量时钟附加到每个基于操作的消息,您的网络使用量也会无限增长。
一些解决方法:
- 无需将整个矢量时钟附加到每个基于操作的消息,只需附加操作的直接因果前身的 UID。 (无论如何,您可能会附加这些以进行因果顺序传递。)然后在接收方,在您存储的状态中查找前任的矢量时钟,获取它们的条目最大值,将 1 添加到发送方的条目,并将其存储为操作的矢量时钟。
- 与 1 相同,但不是存储每个操作的整个矢量时钟,而是仅存储其直接因果前驱 - 操作历史中的箭头。这使用更少的空间,并且它仍然包含足够的信息来回答因果顺序查询: o < p当且仅当存在从o到p的箭头路径。但是,我不知道如何快速执行这些查询。
- 发送者可以仅列出“相关” o < p作为p的基于 op 的消息的一部分,而不是直接引用因果顺序。例如,当您设置多值寄存器的值时,无需使用矢量时钟来指示哪些set(x)操作是因果优先的,只需列出当前多值的 UID(参见多值在唯一的集合之上注册)。
Optimized CRDTs 优化的 CRDT
我们现在转向优化。我专注于改变你存储的状态以及访问它的方式的算法优化,而不是低级代码技巧。通常,优化会减少需要存储在内存和磁盘上的元数据量,至少在常见情况下是这样。
这些优化是该博客系列中技术性最强的部分。您可能希望暂时跳过它们,仅在实现它们时才回来,或者信任其他人在库中实现它们。
List CRDTs CRDT列表
我假设您已经了解第 2 部分中的列表和文本编辑。
CRDT 算法和优化的列表太多,这里无法一一列举,但我想简单介绍一个关键问题和解决方案。
当您使用文本 CRDT 表示协作文本文档时,表示状态的简单方法是使用有序映射 (list CRDT position) -> (text character) 。具体来说,这个映射可以是一棵树,每个列表 CRDT 位置有一个节点,就像Fugue: A Basic List CRDT中一样。
如上图 有相应文本“abcde”的赋格树示例。每个节点的 UID 都是一个点。
在这样的树中,每个树节点至少包含 (1) UID 和 (2) 指向其父节点的指针。对于单个文本字符来说,这是很多元数据!另外,您经常需要存储这些元数据,即使是已删除的字符(墓碑)。
这是一种优化,可以在实践中显着减少元数据开销:
- 当副本从左到右插入字符序列(常见情况)时,不会为每个字符创建新的 UID,而是仅为最左边的字符创建 UID。
- 将整个序列存储为单个对象 (id, parentId etc, [char0, char1, …, charN]) 。因此,您的状态不是每个字符一个树节点,而是每个序列一个树节点,存储字符数组。
- 要寻址单个字符,请使用(id, 0) 、 (id, 1) 、 …, (id, N)形式的列表 CRDT 位置。
稍后可以在序列中间插入字符,例如,在char1和char2之间。没关系;新字符只需要指示相应的列表 CRDT 位置(例如“我是(id, 2)的左孩子”)。
将这种优化应用于 Fugue 会得到像这样的树,其中仅显式存储填充的节点(与其子角色一起):
Formatting Marks (Rich Text) 格式化标记(富文本)
回想一下第 2 部分中的内联格式化 CRDT。其内部 CRDT 状态是格式化标记的仅附加日志
type Mark = {
key: string;
value: any;
timestamp: LogicalTimestamp;
start: { pos: Position, type: "before" | "after" }; // type Anchor
end: { pos: Position, type: "before" | "after" }; // type Anchor
}
它的应用程序可见状态是该日志的视图,给出如下:对于每个字符c ,对于每个格式键key ,找到满足最大时间戳的标记
- mark.key = key ,并且
- 间隔(mark.start, mark.end)包含c的位置。
那么c在key处的格式值为mark.value 。
对于实际使用,我们希望有一个表示相同状态但使用更少内存的视图。特别是,它应该看起来更像Quill delta ,而不是存储每个字符的格式信息。例如,代表“Quick Brown n Fox ”的 Quill Delta 是
{
ops: [
{ insert: "Quick " },
{ insert: "brow", attributes: { bold: true, italic: true } },
{ insert: "n fox", attributes: { italic: true } }
]
}
这是这样的一个观点。它的状态是一个map: Map<Anchor, Mark[]> ,由下式给出:
- 对于日志中显示为任何标记的start或end每个anchor ,
- anchor处的值包含指向所有从锚点开始或严格包含锚点的标记的指针。那是, { mark in log | mark.start <= anchor < mark.end } 。
有了这个视图,就可以很容易地查找任何特定字符的格式。您只需要向左走,直到到达map中的anchor ,然后以通常的方式解释map.get(anchor) :对于每个key ,找到key处的 LWW 获胜者并使用其值。 (如果到达列表的开头,则该字符没有格式。)
我声称,只要付出足够的编码努力,您还可以高效地完成以下任务:
- 将整个视图转换为 Quill delta 或类似的富文本编辑器状态。
- 更新视图以反映添加到日志中的新标记。
- 更新视图后,以类似于 Collabs 的 RichTextFormatEvent 的形式发出描述更改内容的事件:
type RichTextFormatEvent = { // The formatted range is [startIndex, endIndex). startIndex: number; endIndex: number; key: string; value: any; // null if unformatted previousValue: any; // The range's complete new format. format: { [key: string]: any }; }
让我们简单讨论一下任务 2;Peritext essay 中有更多详细信息。当日志中添加新的mark mark时:
- 如果map中不存在mark.start ,则转到它的左侧,直到到达map中的锚点prev ,然后执行以下操作 map.set(mark.start, copy of map.get(prev)) 。 (如果到达列表的开头,请执行map.set(mark.start, []) 。)
- 如果map中不存在mark.end ,则执行同样的操作。
- 对于map中的每个条目(anchor, array)使得 mark.start <= anchor < mark.end ,将mark附加到array中。
本节的一些变化:
- Collabs 代表Map<Anchor, Mark[]>字面上使用LocalList - 一种本地数据结构,可让您在单独的列表 CRDT 位置之上构建有序映射。或者,您可以将每个Mark[]与列表 CRDT 内联存储在其锚点位置; Peritext 论文就是这样做的。
- 将状态保存到磁盘时,您可以选择是否保存视图,或者忘记它并在下次加载时从标记日志重新计算。同样,对于基于状态的合并:您可以尝试直接合并视图,或者一次只处理一个非冗余标记。
- 在每个map值( Mark[] )中,您可以安全地忘记 LWW 丢失到同一数组中另一个标记的标记。从每个map值中删除标记后,您可以安全地从日志中忘记它。
State-Based Counter 基于状态的计数器
在协作应用程序中对事件进行计数的简单方法是将事件存储在 append-only log 或 unique set 中。这比单独的计数使用更多的空间,但无论如何您通常都需要额外的信息 - 例如,除了点赞计数之外,还显示谁喜欢某个帖子。
尽管如此,优化的基于状态的计数器 CRDT 既有趣又传统,所以让我们看看它。
计数器的语义如第 1 部分的 乘客计数示例 中所示:其值是历史记录中+1操作的数量,与并发性无关。
显然,您可以通过存储+1操作的仅附加日志来实现此语义。要合并两个状态,请合并日志条目,跳过重复的 UID。
换句话说,存储整个操作历史记录,遵循本文顶部的简单协议。
假设仅追加日志使用 dot IDs 作为其 UID。那么日志的状态将始终如下所示:
[
((a6X7fx, 1), "+1"), ((a6X7fx, 2), "+1"), ((a6X7fx, 3), "+1"), ((a6X7fx, 4), "+1"),
((bu91nD, 1), "+1"), ((bu91nD, 2), "+1"), ((bu91nD, 3), "+1"),
((yyn898, 1), "+1"), ((yyn898, 2), "+1")
]
您可以通过为每个 replicaID 仅存储从该副本接收的 dot ID 范围来压缩此状态。
例如,上面的日志压缩为
{
a6X7fx: 4,
bu91nD: 3,
yyn898: 2
}
这与我们在矢量时钟 1中使用的技巧相同。
以这种方式压缩日志会产生以下算法,即基于状态的计数器 CRDT 。
- 每个用户状态: Map<ReplicaID, number> ,将每个replicaID映射到从该副本接收到的+1操作的数量。 (传统上,这种状态称为向量而不是映射。)
- 应用程序可见状态(计数):地图值的总和。
- +1操作:将1添加到您自己的地图条目中,将缺少的条目视为0。
- 在其他状态下合并:取每个条目的最大值,将缺失的条目视为 0。也就是说,对于所有r ,设置 this.state[r] = max(this.state[r] ?? 0, other.state[r] ?? 0) 。
例如:
// Starting local state:
{
a6X7fx: 2, // Implies ops ((a6X7fx, 1), "+1"), ((a6X7fx, 2), "+1")
bu91nD: 3,
}
// Other state:
{
a6X7fx: 4, // Implies ops ((a6X7fx, 1), "+1"), ..., ((a6X7fx, 4), "+1")
bu91nD: 1,
yyn898: 2
}
// Merged result:
{
a6X7fx: 4, // Implies ops ((a6X7fx, 1), "+1"), ..., ((a6X7fx, 4), "+1"): union of inputs
bu91nD: 3,
yyn898: 2
}
您可以推广基于状态的计数器来处理任意正值x的+x操作。但是,要处理正加法和负加法,您需要使用两个计数器: P表示正加法, N表示负加法。实际值为(P’s value) - (N’s value) 。这是基于状态的 PN 计数器。
Delta-State Based Counter 基于 Delta 状态的计数器
您可以修改基于状态的计数器 CRDT 以支持基于操作的消息:
- 当用户执行+1操作时,广播其点 ID (r, c) 。
- 收件人通过设置map[r] = max(map[r], c)将此点添加到其压缩日志map 。
这种基于操作/基于状态的混合 CRDT 称为基于增量状态的计数器 CRDT 。
从技术上讲,基于增量状态的计数器 CRDT 假定基于操作的消息按因果顺序传递。如果没有这个假设,副本的未压缩日志可能包含诸如
[
((a6X7fx, 1), "+1"), ((a6X7fx, 2), "+1"), ((a6X7fx, 3), "+1"), ((a6X7fx, 6), "+1")
]
我们不能将其表示为Map<ReplicaID, number> 。
您可能会说操作((a6X7fx, 6), “+1”)让您“推断”先前的操作((a6X7fx, 4), “+1”)和((a6X7fx, 5), “+1”) ,因此您只需将映射条目设置为{ a6X7fx: 6 } 。然而,如果那些先前的操作被故意撤消,或者如果它们与某些其他无法推断的更改相关(例如,评论计数与实际评论列表),这将给出意外的计数器值。
幸运的是,您仍然可以压缩收到的点 ID 内的范围。例如,您可以使用游程编码:
{
a6X7fx: [1 through 3, 6 through 6]
}
或一张地图加上一组“额外”点 ID:
{
map: { a6X7fx: 3 },
dots: [[ "a6X7fx", 6 ]]
}
这个想法导致了第二个基于 Delta 状态的计数器 CRDT。它的基于状态的合并算法有些复杂,但它有一个简单的规范:解压缩两个输入,取并集,然后重新压缩。
State-Based Unique Set 基于状态的唯一集
这是一个针对唯一集的简单的基于状态的 CRDT:
- 每个用户状态:
- 一组元素(id, x) ,这是该集合的文字(应用程序可见)状态。
- 一组墓碑id ,它们是所有 已删除元素的 UID。
- 应用程序可见状态:返回elements 。
- 操作add(x) :生成一个新的UID id ,然后将(id, x)添加到elements中。
- 操作delete(id) :从elements中删除具有给定id对,并将id添加到tombstones 。
- 基于状态的合并:合并到另一个用户的状态 other = { elements, tombstones } ,
- 对于other.elements中的每个(id, x) ,如果它尚未存在于this.elements中并且id不在this.tombstones中,请将(id, x)添加到this.elements 。
- 对于other.tombstones中的每个id ,如果this.tombstones中尚不存在,请将id添加到this.tombstones并从this.elements中删除具有给定id对(如果存在)。
例如:
// Starting local state:
{
elements: [ (("A84nxi", 1), "milk"), (("A84nxi", 3), "eggs") ],
tombstones: [ ("A84nxi", 2), ("bu2nVP", 1), ("bu2nVP", 2) ]
}
// Other state:
{
elements: [
(("A84nxi", 3), "eggs"), (("bu2nVP", 1), "bread"), (("bu2nVP", 2), "butter"),
(("bu2nVP", 3), "cereal")
],
tombstones: [ ("A84nxi", 1), ("A84nxi", 2) ]
}
// Merged result:
{
elements: [ (("A84nxi", 3), "eggs"), (("bu2nVP", 3), "cereal") ],
tombstones: [ ("A84nxi", 1), ("A84nxi", 2), ("bu2nVP", 1), ("bu2nVP", 2) ]
}
这种简单算法的问题在于 逻辑删除集:它为每个已删除元素存储一个 UID,这可能会使 CRDT 状态比应用程序可见状态大得多。
幸运的是,当您的 UID 是 dot ID 时,您可以使用类似于基于状态的计数器 CRDT 的“压缩”技巧:存储从每个副本(删除或未删除)接收到的点 ID 的范围来代替逻辑删除集,如下所示Map<ReplicaID, number> 。也就是说,存储仅对add运算进行计数的修改后的矢量时钟。任何在此范围内但不存在于elements中的点 ID 都必须已被删除。
例如,上面的三种状态压缩为:
// Starting local state:
{
elements: [ (("A84nxi", 1), "milk"), (("A84nxi", 3), "eggs") ],
vc: { A84nxi: 3, bu2nVP: 2 }
}
// Other state:
{
elements: [
(("A84nxi", 3), "eggs"), (("bu2nVP", 1), "bread"), (("bu2nVP", 2), "butter"),
(("bu2nVP", 3), "cereal")
],
vc: { A84nxi: 3, bu2nVP: 3 }
}
// Merged result:
{
elements: [ (("A84nxi", 3), "eggs"), (("bu2nVP", 3), "cereal") ],
vc: { A84nxi: 3, bu2nVP: 3 }
}
以这种方式压缩逻辑删除集会产生以下算法,即优化的基于状态的唯一集:
- 每个用户状态:
- 一组元素(id, x) = ((r, c), x) 。
- 矢量时钟vc: Map<ReplicaID, number> 。
- 本地计数器counter ,用于 dot ID。
- 应用程序可见状态:返回elements 。
- 操作add(x) :生成一个新点 id = (local replicaID, ++counter) ,然后将(id, x)添加到elements 。同时增加vc[local replicaID] 。
- 操作 delete(id) :仅从 elements 中删除具有给定id对。
- 基于状态的合并:合并到另一个用户的状态other = { elements, vc } ,
- 对于 other.elements 中的每个((r, c), x) ,如果它尚未存在于 this.elements 和 c > this.vc[r]中,请将 ((r, c), x) 添加到 this.elements 。 (这是新的,本地尚未删除。)
- 对于 other.vc 中的每个条目(r, c) ,对于this.elements中的每对((r, c’), x) ,如果c >= c’并且该对不存在于other.elements中,则删除它来自this.elements 。 (它必须已从其他状态删除。)
- 将 this.vc 设置为 this.vc 和 other.vc 的条目最大值,将缺失条目视为 0。也就是说,对于所有 r ,设置 this.vc[r] = max(this.vc[r] ?? 0, other.vc[r] ?? 0) 。
如果您的唯一集的 dot ID 使用相同的计数器,则可以重复使用用于跟踪操作的相同矢量时钟。注意:
- 您的唯一集可能会跳过一些点 ID,因为它们用于其他操作;没关系。
- 如果单个操作可以一次添加多个元素,请考虑使用以下形式的 UID (dot ID, within-op counter) = (replicaID, per-op counter, within-op counter) 。
优化的 唯一集 尤其重要,因为您可以在顶部实现许多其他 CRDT,然后它们也会被优化(它们避免了逻辑删除)。特别是,第 2 部分描述了 多值寄存器、多值映射 和 add-wins 集 的 独特集合算法(全部假设因果顺序传递)
您还可以调整优化的唯一集来管理唯一 CRDT 集中的删除。
Delta-State Based Unique Set 基于 Delta 状态的唯一集
与第二个基于增量状态的计数器 CRDT类似,您可以创建一个基于增量状态的唯一集,它是基于操作/基于状态的混合 CRDT,并允许非因果顺序消息传递。我会把它留作练习。
Conclusion 结论
最后两篇文章调查了第 1 部分中的两个“主题”:
- 语义:根据并发感知操作历史记录,对协作应用程序状态的抽象描述。
- 算法:在特定的实际情况下有效计算应用程序状态的算法。
它们共同涵盖了我所了解和使用的大部分 CRDT 理论。我希望你现在也知道了!
然而,在我的关注领域之外还有其他 CRDT 想法。我将在下一篇也是最后一篇文章第 4 部分:进一步主题中提供参考书目。
Part 4: Further Topics
Further Topics 更多主题
这篇文章通过描述我关注领域之外的其他主题来结束我的 CRDT 调查。它不是对这些主题的适当调查,而是一个轻量级的参考书目,其中包含一两个相关资源的链接。要查找有关给定主题的更多论文,请参阅crdt.tech/papers.html 。
我之前的帖子做了几个隐含的假设,我认为它们是“传统”CRDT 模型的一部分:
- 所有操作都只以最终一致性为目标。没有协调/强一致性的机制(例如中央服务器),即使只是操作的子集。
- 用户总是希望尽快同步所有数据和所有操作。不存在对文档的部分访问或故意省略操作的同步策略的概念。
- 所有设备都是值得信赖的并遵循给定的协议。
下面的进一步主题涉及至少违反这些假设之一的协作应用程序。我将以 CRDT 设计的一些替代方案和后记作为结束。
Incorporating Strong Consistency 结合强一致性
强一致性(大致)保证所有副本以相同的顺序查看所有操作。这与 CRDT 的 最终一致性 保证形成鲜明对比,CRDT 允许 不同的副本 以不同的顺序 查看并发操作。现有的工作探索了混合 CRDT 和 强一致性的系统。
“非事务性分布式存储系统的一致性”, Viotti 和 Vukolić (2016) 。提供各种一致性保证的概述。
Mixed Consistency 混合一致性
某些应用程序需要某些操作的强一致性,但允许其他操作进行 CRDT 式的乐观更新。例如,日历应用程序在预订房间时可能会使用强一致性,以防止重复预订。有几篇论文描述了专为此类应用程序设计的混合一致性系统或语言。
“使地理复制系统尽可能快,必要时保持一致”, Li 等人。 (2012) 。描述了一个提供“红蓝一致性”的系统,其中操作可以被标记为需要强一致性(红色)或仅需要最终一致性(蓝色)。
Server-Assisted CRDTs 服务器辅助的 CRDT
除了为 某些操作提供 强一致性之外,中央服务器 还可以为 部分协议 提供 强一致性,而 客户端 则使用 CRDT 进行 乐观本地更新。例如服务器可以决定 哪些操作有效或无效,为操作分配最终的总顺序,或者协调仅在没有并发操作的情况下才可能进行的“垃圾收集”操作(例如,删除逻辑删除)。
- “副本”, Rocicorp (2024) 。客户端同步框架,使用服务器为操作分配最终总顺序,但允许客户端使用“rebase”技术执行乐观的本地更新。
- “让基于操作的 CRDT 成为基于操作的”, Baquero、Almeida 和 Shoker (2014) 。
定义因果稳定性:不能有与给定操作并发的其他操作的条件。因果稳定性对于垃圾收集操作通常是必要的,但要确保协作应用程序中副本的出现和消失却很棘手。
Incomplete Synchronization 不完全同步
Undo 撤消
第 2 部分描述了 精确撤消,其中您将正常语义应用于操作历史记录中较少撤消的操作。同样的原则也适用于您故意省略操作的其他情况:拒绝/恢复更改、部分复制、跨分支“挑选”等。
然而,将正常语义应用于“操作历史记录减去未完成的操作”听起来更困难,因为许多语义和算法都假设因果顺序传递。例如:
- 有两种常见的方法来描述Add-Wins Set 的语义,这在假设因果顺序传递的情况下是等效的,但在没有因果顺序传递的情况下是不等价的。
- 为了比较列表CRDT位置,您通常需要一些元数据(例如,底层 Fugue 树),如果您缺少先前的操作,则不能保证这些元数据存在。
制定各种 CRDT 的撤消容忍变体是一个悬而未决的问题。
- “支持协作应用程序中复制寄存器的撤消和重做”, Brattli 和 Yu (2021) 。描述多值寄存器的撤消容忍变体。
Partial Replication 部分复制
之前的文章假设所有协作者始终加载整个文档并同步该文档的所有操作。在部分复制中,副本仅存储和同步文档的部分内容。部分复制可用作访问控制的一部分,或作为大型文档的优化 - 客户端可以将大部分文档保留在磁盘或存储服务器上。
现有的 CRDT 库(Yjs、Automerge 等)没有内置的部分复制,而是鼓励您在需要时将协作状态拆分为多个文档,以便您可以单独共享或加载每个文档。但是,您就会失去不同文档中的操作之间的因果一致性保证。设计执行实际复制的系统也具有挑战性,例如,智能地决定从存储服务器获取哪些文档。
- “无冲突部分复制数据类型”, Briquemont 等人。 2015年。描述一个明确支持 CRDT 部分复制的系统。
- “Automerge Repo”, Automerge 贡献者 (2024) 。 “Automerge Repo 是 Automerge CRDT 库的包装器,它提供了支持同时处理多个文档的设施”。
Versions and Branches 版本和分支
在传统的协作应用程序中,所有用户都希望看到相同的状态,尽管他们可能由于网络延迟而暂时出现分歧。相反,版本控制系统支持独立发展的多个分支,除非在显式合并期间。 CRDT 非常适合版本控制,因为它们的并发感知语义可能会带来更好的合并结果(并行分支中的操作被视为并发)。
最初的local-first essay已经讨论了 CRDT 之上的版本和分支。最近的工作已经开始在实践中探索这些想法。
- “Upwelling:将实时协作与作家的版本控制相结合”, McKelvey 等人。 (2023) 。一个 Google Docs 风格的编辑器,添加了使用 CRDT 的版本控制功能。
- “提案:版本化协作文档”, Weidner (2023) 。在一篇研讨会论文中,我提出了一种结合了 git 和 Google Docs 功能的架构。
Security 安全
Byzantine Fault Tolerance 拜占庭容错
传统的 CRDT 假设所有设备都是值得信赖的并遵循给定的协议。恶意或有缺陷的设备很容易偏离协议,从而使其他用户感到困惑。
特别是,恶意设备可以将相同的 UID 分配给操作的两个版本,然后将每个版本广播给不同的协作者子集。协作者可能只会处理他们收到的第一个版本,然后拒绝第二个版本,因为这是多余的。因此,该组最终将处于永久不一致的状态。
有几篇论文探讨了如何使 CRDT具有拜占庭容错能力,以便即使面对恶意合作者的任意行为,这些不一致的状态也不会发生。
- “拜占庭最终一致性和点对点数据库的基本限制”, Kleppmann 和 Howard (2020) 。
- “使 CRDT 具有拜占庭容错能力”, Kleppmann (2022) 。
Access Control 访问控制
在纯粹本地优先的设置中,访问控制(控制谁可以读写协作文档)很难实现甚至定义。例如:
- 如果用户无法访问协作文档,他们的本地副本会发生什么情况?
- 我们应该如何处理棘手的并发情况,例如用户同时执行操作而失去访问权限,或者两个管理员同时互相降级?
一些系统实现了处理这些情况的协议。
- “矩阵分解:基于事务的 DAG 的访问控制方法分析(无最终性)”, Jacob 等人。 (2020) 。描述Matrix聊天网络使用的访问控制协议。
- “@localfirst/auth”, Caudill 等人。 (2024) 。 “@localfirst/auth 是一个 TypeScript 库,使用安全的加密签名链,为团队协作提供去中心化身份验证和授权。”
Alternatives to CRDT Design CRDT 设计的替代方案
Operational Transformation 运营转型
在协作文本文档中,当用户插入或删除文本时,他们会移动后面的字符的索引。如果您按字面解释其他用户的原始索引,这会给其他用户的并发编辑操作带来麻烦:

Alice 在索引 17 处输入了“the”,但与此同时,Bob 在她面前输入了“gray”。从 Bob 的角度来看,Alice 的插入应该发生在索引 22 处。
CRDT 解决此问题的方法是使用 不可变列表 CRDT 位置而不是索引。另一类算法称为操作转换 (OT) ,它会“转换”您通过网络收到的索引以考虑并发操作。因此,在上图中,Bob 将从 Alice 处收到“索引 17”,但在处理插入之前为其添加 5,以说明他同时在其前面插入的 5 个字符。
我个人认为列出 CRDT 位置 是更简单的心理模型,因为它们随着时间的推移保持不变。它们还可以在任意网络中工作。 (大多数部署的 OT 算法需要中央服务器;分散的 OT 存在,但非常复杂。)尽管如此,OT 算法早于 CRDT,并且部署更广泛 - 特别是 Google Docs。
- “组编辑器中并发控制和撤消的集成、面向转换的方法”, Ressel、Nitsche-Ruhland 和 Gunzenhäuser (1996) 。经典的OT论文。
- “通过实时协作增强丰富的内容 wiki”, Ignat、André 和 Oster (2017) 。描述基于块的富文本的中央服务器 OT 算法。
Program Synthesis 程序综合
传统的CRDT论文是手工设计CRDT并用笔和纸证明最终一致性的算法论文。相反,一些最近的论文尝试根据 CRDT 的某些行为规范自动合成CRDT - 例如,顺序(单线程)数据结构加上一些即使面对并发也应该保留的不变量。
请注意,虽然综合可能比从头开始设计 CRDT 更容易,但无法保证综合语义在用户眼中是合理的。事实上,一些现有的论文选择了相当不寻常的语义。
“Katara:通过验证提升合成 CRDT”, Laddad 等人。 2022 年。通过搜索组合的基于状态的 CRDT 空间,直到找到一个有效的,从规范合成 CRDT。
Afterword: Why Learn CRDT Theory? 后记:为什么要学习CRDT理论?
我希望您喜欢阅读这个博客系列。不过,除了满足您的好奇心之外,您可能会想:为什么首先要学习这个?
事实上,CRDT 的一种方法是让专家在库中实现它们,然后使用这些实现,而无需过多考虑它们是如何工作的。这就是我们对普通本地数据结构(例如 Java 集合)采取的方法。当您使用 CRDT 库来完成其构建的任务时,它会很好地工作 - 例如, Yjs可以轻松地将中央服务器实时协作添加到各种富文本编辑器。
然而,根据我迄今为止的经验 - 使用和实现 CRDT 库 - 很难以库创建者没有预料到的任何方式使用 CRDT 库。因此,如果您的应用程序最终需要上面的一些进一步主题,或者如果您需要调整协作语义,您可能被迫开发一个自定义系统。为此,CRDT 理论将派上用场。 (尽管仍然考虑在可能的情况下使用已建立的工具 - 特别是对于诸如列出 CRDT 位置之类的棘手部分。)
即使您使用现有的 CRDT 库,您也可能会遇到一些实际问题,例如:
- 我可以期望保持哪些不变量?
- 如果 <…> 失败会发生什么?
- 在不同的工作负载下,它的表现如何?















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









