






 本文以机器学习入门级视角,详细介绍了Stable Diffusion的建模思想、训练预测方式。Stable Diffusion是基于Latent Diffusion Model的AI绘画工具,能根据文本描述生成图像。文章涵盖了模型结构、关键组件和训练预测方法,适合有一定机器学习基础的读者快速了解。
本文以机器学习入门级视角,详细介绍了Stable Diffusion的建模思想、训练预测方式。Stable Diffusion是基于Latent Diffusion Model的AI绘画工具,能根据文本描述生成图像。文章涵盖了模型结构、关键组件和训练预测方法,适合有一定机器学习基础的读者快速了解。
手把手教你入门绘图超强的AI绘画程序,用户只需要输入一段图片的文字描述,即可生成精美的绘画。给大家带来了全新保姆级教程资料包(文末可获取)
【AIGC】Stable Diffusion的建模思想、训练预测方式快速
在这篇博客中,将会用机器学习入门级描述,来介绍Stable Diffusion的关键原理。目前,网络上的使用教程非常多,本篇中不会介绍如何部署、使用或者微调SD模型。也会尽量精简语言,无公式推导,旨在理解思想。让有机器学习基础的朋友,可以快速了解SD模型的重要部分。如有理解错误,请不吝指正。
大纲
- 关键概念
- 模型结构及关键组件
- 训练和预测方式
关键概念
名词解释
Stable Diffusion
之所以叫Stable,是因为金主公司叫StabilityAI。
其基础模型是Latent Diffusion Model(LDM),也是本文主要介绍的部分。
模型任务
- text-2-img:输入文本描述、输出图像
- img-2-img:输入图片及其他文本描述,输出图像
总的来说,不论是输入是文字还是图片,都可以称为是“condition”,用于指引图像生成的“方向”。因此,SD模型的任务,可以统称为是cond-2-img任务。

模型结构与关键组件
模型结构
LDM论文结构图,初看时会有点懵,但稍微理解后还是非常清晰准确的。先初步介绍几个大的模块。建议把这张图截图固定在屏幕上,再继续浏览下面的内容。
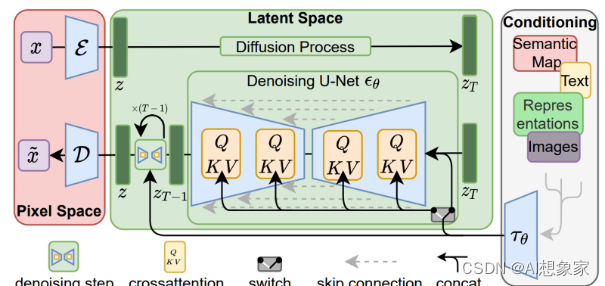
整体输入输出
上图中最左侧的x xx和x ~ \widetilde{x}
是模型的输入与输出,形如[ W , H , C ] [W, H, C][W,H,C]的三维张量,代表一张图像的宽、高和通道数。
需要注意,这里的输入x xx,并不是模型img-2-img中的输入图像,而是模型训练时的原始图像输入。img-2-img的输入图像,是上图中最右侧的Conditioning模块中的images。
像素空间与隐空间
所谓空间,可以理解为数据的表示形式,通常有着不同的坐标轴。
- 像素空间(Pixel Space),上图左侧,红框部分。通常是人眼可以识别的图像内容。
- 隐空间(Latent Space),上图中央,绿框部分。通常是人眼无法识别的内容,但包含的信息量与像素空间相近。
像素空间到隐空间
输入的图像x xx,经过Encoder(图中蓝色的E \mathcal{E}E),转换为另一种shape的张量z zz,即称为隐空间。
从压缩角度理解:图像经过转换后,产生的新张量是人眼无法识别的。但其包含的信息量相差不大,数据尺寸却大幅缩小,因此可以看做是一种图像数据压缩方式。
隐空间到像素空间
经过模型处理后的隐向量输出z zz(特指绿框左下角的z zz),经过Decoder(图中蓝色的D \mathcal{D}D),转换回像素空间。
隐空间Diffusion操作
对应图中绿色Latent Space框的上半部分,包括以下三步:
- 图像经过Encoder压缩后,得到隐向量表示z = E ( x ) z=\mathcal{E}(x)z=E(x)隐向量
- 从1~1000的均匀分布中,随机采样一个整数T TT,称为扩散步数
- 对向量z zz加T TT次高斯噪声,满足分布N ( 0 , β t ) N(0, \beta_t)N(0,β t ),得到z T
z_Tz T 向量
在这个操作中,有一些有趣的特性:
噪声收敛
加噪声次数足够多时,理论上会得到一组符合高斯分布的噪声。利用这个特性,在预测阶段我们就不需要执行Diffusion操作,只需要采样一组高斯分布的噪声,即代表了z T z_Tz T 。
高斯噪声可加性
当我们需要得到任意时刻的z T· 时,可以直接从z 0 以及一系列β t \beta_tβ
计算得到,只需要采样一次噪声。这部分的具体公式推导,可以参考由浅入深了解Diffusion Model - 知乎 (zhihu.com)。
条件Conditioning
对应图中最右边灰白色框,输入类型包括text、images等。在Conditioning模块中,会执行以下步骤:
- 这些“附加信息”会通过对应的编码器τ θ \tau_\thetaτ θ ,转换成向量表示
- 转换后的向量,会输入给U-Net,作为其中Attention模块的K、V输入,辅助噪声的预测
在这个模块中,有几个有趣的问题:
为什么需要Conditioning
由于“噪声收敛”特性,当噪声加得比较多时,z T z_Tz
T 已经趋近于一个“纯噪声”了,但训练过程需要比对输入图像x xx和输出图像x ~ \widetilde{x}
的相似度。如何从一个“纯噪声”,还原回与输入图像相似的图像,就必须要给模型提供额外的信息指引,这就是Conditioning的作用。
关键组件
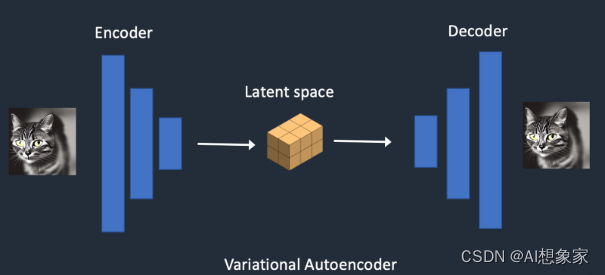
VAE(Variational Auto Encoders)
在LDM中,如何将原始图片“压缩”转换至隐空间,经过处理再转换回来,即使用VAE的Encoder和Decoder。这个模块是预训练好的,在LDM训练时固定住参数。
原理
- 原始张量输入,经过非常简单的网络结构,转换成较小的张量
- 在Latent张量上,加一点点噪声扰动
- 用对称的简单网络结构,还原回原始大小
- 对比输入前后的张量是否相似
特点
- 网络计算复杂度比较低
- Encoder和Decoder可以分开使用
- 无监督训练,不需要标注输入的label
- 有了噪声扰动之后,Latent Space的距离具有实际物理含义,可以实现例如“(满杯水+空杯子)/ 2 = 半杯水”的操作
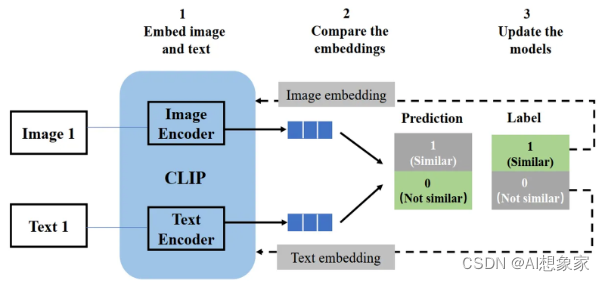
CLIP
文本信息如何转换成张量,靠的是CLIP模块。这个模块是预训练好的,在LDM训练时固定住参数。
训练方式
图像以及它的描述文本,经过各自的Encoder转换为向量表示,希望转换后的向量距离相近。经过训练后,文本描述可以映射到向量空间的一个点,其代表的物理含义与原始图像相近。
假设无预训练
开个脑洞,假如没有这个模块,直接将文本token化后,去Embedding Table中查表作为文本张量,理论上也是可以训练的,只不过收敛速度会慢很多。
因此,这里使用一个预训练text-2-embedding模块,主要目的是加速训练。CLIP的训练数据集,也选择了和LDM的数据集的同一个(LAION-5B的子集),语义更一致。
模型标识解释
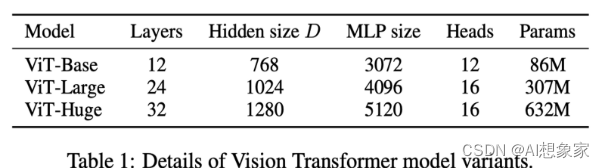
我们经常会看到类似“ViT-L/14”的模型名,表示一种CLIP的结构。具体的,ViT表示Vision Transformer,L表示Large(此外还有Base、Huge),14表示训练时把图像划分成14*14个子图序列输入给Transformer。
U-Net
作为LDM的核心组件,U-Net是模型训练过程中,唯一需要参数更新的部分。在这个结构中,输入是带有噪声的隐向量z t 、当前的时间戳t tt,文本等Conditioning的张量表示E EE,输出是z t中的噪声预测。
模型结构
U-Net大致上可以分为三块:降采样层、中间层、上采样层。之所以叫U-Net,是因为它的模型结构类似字母U。
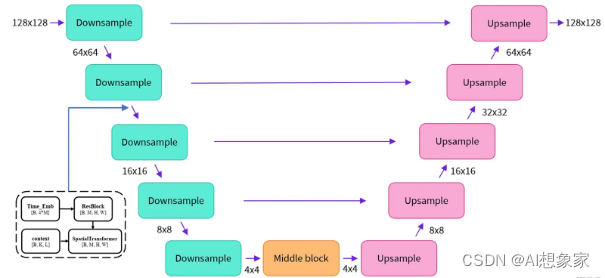
降采样层
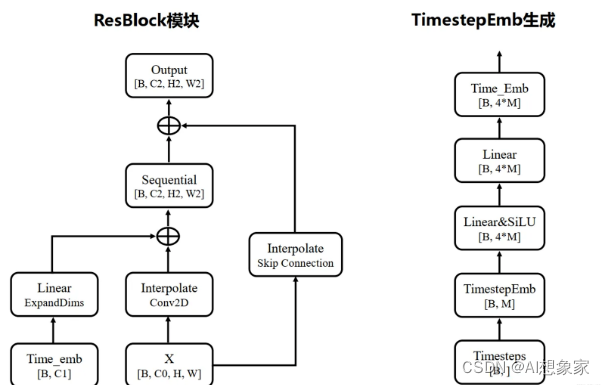
- 时间戳t tt转换为向量形式。用的是“Attention is All you
Need”论文的Transformer方法,通过sin和cos函数再经过两个Linear进行变换 - 初始化输入X = c o n v ( c o n c a t ( z t , E ) ) X = conv(concat(z_t,
E))X=conv(concat(z t ,E)),其中c o n v convconv是卷积,E EE是Conditioning - 重复以下步骤(a~c)多次,将输入尺寸降至目标尺寸(如上图的4 × 4 4\times44×4)
- 重复以下两步多次,训练多个ResBlock和SpatialTransformer层,输入值X XX的尺寸不变
- 输入上一层的输出X XX和时间戳向量,给ResBlock
- ResBlock的输出,与E EE一起输入给SpatialTransformer,在这里考虑到text等信息 重复多次3~4步,
- 通过卷积或Avg-Pooling进行降采样,缩小X XX的尺寸
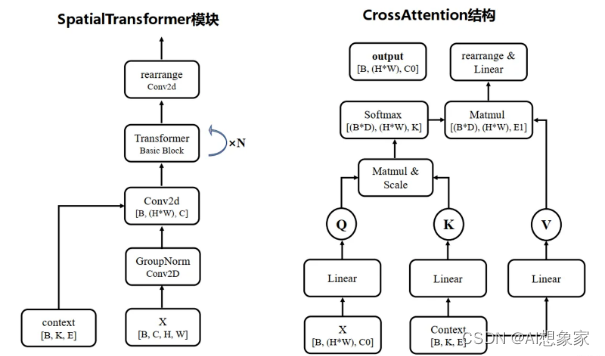
中间层
很简单,ResBlock + SpatialTransformer + ResBlock,输入X XX尺寸不变。
上采样层
大部分步骤与降采样层一致,只有以下两点不同
- 输入X XX需要拼上对应降采样层的输出,称为skip connection,对应U-Net结构图中横向的箭头
把降采样步骤,换成使用卷积或插值(interpolate)方式来上采样,使得X XX的尺寸增大 输出 - 上采样层的输出,会经过normalization + SiLU + conv,得到U-Net的最终
输出
即噪声的预测值,尺寸保持与输入zt 一致。
训练方式
模型更新方式
LDM模型需要训练的部分,只有U-Net的参数。训练的方式,可以简单总结为:
- 输入一张图片x xx,以及它的文本描述等Conditioning,一个随机的整数T TT步
- 经过Encoder压缩、Diffusion加噪声,得到z T 隐向量
- 结合Conditioning,使用U-Net,进行T TT次去噪,得到预测值z 0 向量
- 使用Decoder还原回x ~ ,计算x 与x ~ 之间的差距(KL散度),得到模型更新的loss
模型预测方式
- 随机一个高斯噪声,作为z T 向量
- 输入text等Conditioning,使用U-Net进行指定次数T TT的去噪操作
- 使用Decoder还原回x ~ ,得到图像输出
训练、预测过程,在论文中的伪代码为下图所示。

AI绘画所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
👉stable diffusion新手0基础入门PDF👈

👉AI绘画必备工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉12000+AI关键词大合集👈



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









