







Drawbacks of PMF
- Matrix factorization only uses information from other users, it cannot generalize to completely unrated items.(They cannot be used for recommending new products which have yet to receive rating information from any user)
- The prediction accuracy often drops significantly when the ratings are very sparse.
- The learnt latent space is not easy to interpret.(CTR Model can do this)
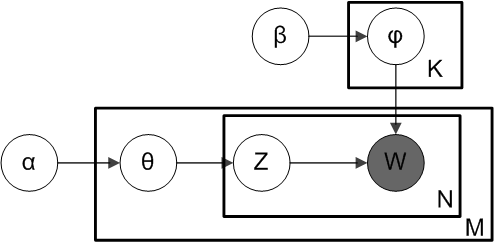
Use LDA to Enhance PMF
LDA
Documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words. LDA assumes the following generative process for a corpus 


1. Choose 



2. Choose

3. For each of the word positions 

(Note that the Multinomial distribution here refers to the Multinomial with only one trial. It is formally equivalent to the categorical distribution.)
4. Plate notation are as follows:
Categorical Distribution
K-dimensional categorical distribution is the most general distribution over a K-way event; any other discrete distribution over a size-K sample space is a special case. The parameters specifying the probabilities of each possible outcome are constrained only by the fact that each must be in the range 0 to 1, and all must sum to 1.
| pmf |
|---|
 |
![p(x)=p_{1}^{[x=1]}\cdots p_{k}^{[x=k]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eeddb64d5678bd3e0296ccc25f4d3d84432920e3) |
![p(x)=[x=1]\cdot p_{1},+\dots +,[x=k]\cdot p_{k}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a0f3abb31a826ecb05c779f80dc490d3075b3e9b) |
![[x=i]](https://wikimedia.org/api/rest_v1/media/math/render/svg/747094cb4b84a3d9ede55bd7667e9da65c8cf6a8)
Multinomial Distribution
| pmf |
|---|
 |
When n is 1 and k is 2 the multinomial distribution is the Bernoulli distribution.
When k is 2 and number of trials are more than 1 it is the Binomial distribution.
When n is 1 it is the categorical distribution.
Combine LDA into PMF: CTR
For each item j,
(a) Draw topic proportions θj ∼ Dirichlet(α).
(b) Draw item latent offset j∼N(0;λ−1IK) and set the item latent vector as vj = ϵj + θj .
(c) For each word wjn ,
i. Draw topic assignment zjn ∼ Mult(θ).
ii. Draw word wjn ∼ Mult( βzjn ).For each user-item pair (i;j) , draw the rating
rij∼N(uTivj;c−1ij)
The key property in CTR lies in how the item latent vector
vj
is generated. Note that
vj=j+θj
, where
j∼N(0;λ−1vIk)
, is equivalent to
vj∼N(θj;λ−1vIK)
, where we assume the item latent vector vj is close to topic proportions θj, but could diverge from it if it has to. Note that the expectation of
rij
is a linear function of
θj
,
This is why we call the model collaborative topic regression
- Plate Notation are as follows:
,
Next: Use SDAE to enhance PMF //TODO
the latent representation learned by CTR may not be very effective when the auxiliary information is very sparse.
references
- C. Wang and D. M. Blei. Collaborative topic modeling for recommending scientific articles. In KDD, pages 448-456, 2011.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









